Command Palette
Search for a command to run...
PackForcing: Kurze Videotraining reicht für die Langzeitvideoprobennahme und die Inferenz im Langkontext aus
PackForcing: Kurze Videotraining reicht für die Langzeitvideoprobennahme und die Inferenz im Langkontext aus
Xiaofeng Mao Shaohao Rui Kaining Ying Bo Zheng Chuanhao Li Mingmin Chi Kaipeng Zhang
Zusammenfassung
Autoregressive Videodiffusionsmodelle haben bemerkenswerte Fortschritte erzielt, stoßen jedoch bei der Generierung langer Videos nach wie vor an Grenzen, die durch ein unlösbares lineares Wachstum des KV-Caches, zeitliche Wiederholungen und sich kumulierende Fehler verursacht werden. Um diese Herausforderungen zu adressieren, stellen wir PackForcing vor: ein einheitliches Framework, das die Generierungshistorie effizient durch eine neuartige dreiteilige KV-Cache-Strategie verwaltet. Konkret kategorisieren wir den historischen Kontext in drei verschiedene Typen: (1) Sink-Tokens, die frühe Ankerbilder in voller Auflösung bewahren, um die globale Semantik zu erhalten; (2) Mid-Tokens, die eine massive raumzeitliche Kompression (32-fache Reduktion der Tokens) durch ein Dual-Branch-Netzwerk erreichen, das progressive 3D-Faltungen mit einer Neu-Kodierung mittels eines Low-Resolution-VAE kombiniert; und (3) Recent-Tokens, die in voller Auflösung gehalten werden, um die lokale zeitliche Kohärenz sicherzustellen. Um den Speicherbedarf strikt zu begrenzen, ohne die Qualität zu beeinträchtigen, führen wir einen dynamischen Top-k-Kontextauswahlmechanismus für die Mid-Tokens ein, der mit einer kontinuierlichen Temporal-RoPE-Anpassung gekoppelt ist. Diese passt Positionsunterschiede, die durch verworfene Tokens entstehen, nahtlos an, wobei der Overhead vernachlässigbar bleibt. Gestärkt durch dieses prinzipielle hierarchische Kontextkompressionsverfahren kann PackForcing kohärente 2-Minuten-Videos mit einer Auflösung von 832x480 Pixeln und 16 Bildern pro Sekunde auf einer einzigen H200-GPU generieren. Es erreicht einen begrenzten KV-Cache von lediglich 4 GB und ermöglicht eine bemerkenswerte 24-fache zeitliche Extrapolation (von 5 auf 120 Sekunden), wobei es sowohl im Zero-Shot-Modus als auch bei Training ausschließlich mit 5-Sekunden-Clips effektiv operiert. Umfassende Ergebnisse auf VBench belegen state-of-the-art zeitliche Konsistenz (26,07) und Dynamikgrad (56,25) und zeigen, dass eine Überwachung mittels Kurzvideos für die hochwertige Synthese langer Videos ausreicht. https://github.com/ShandaAI/PackForcing
One-sentence Summary
Researchers from Alaya Studio, Fudan University, and Shanghai Innovation Institute present PackForcing, a framework that enables long-video generation by compressing historical KV caches into three partitions. This approach achieves 24x temporal extrapolation from short clips while maintaining state-of-the-art coherence on a single GPU.
Key Contributions
- The paper introduces PackForcing, a unified framework that partitions generation history into sink, compressed, and recent tokens to bound per-layer attention to approximately 27,872 tokens regardless of video length.
- A hybrid compression layer fusing progressive 3D convolutions with low-resolution VAE re-encoding achieves a 128× spatiotemporal compression for intermediate history, increasing effective memory capacity by over 27×.
- The method employs a dynamic top-k context selection mechanism coupled with an incremental Temporal RoPE adjustment to seamlessly correct position gaps caused by dropped tokens without requiring full cache recomputation.
Introduction
Autoregressive video diffusion models enable long-form generation but face critical bottlenecks where linear Key-Value cache growth causes out-of-memory errors and iterative prediction leads to severe semantic drift. Prior solutions either truncate history to save memory, which destroys long-range coherence, or retain full context, which exceeds the capacity of single GPUs for minute-scale videos. The authors introduce PackForcing, a unified framework that partitions generation history into sink, compressed, and recent tokens to bound memory usage while preserving global semantics. By employing a dual-branch network for massive spatiotemporal compression and a dynamic top-k selection mechanism with incremental RoPE adjustment, the method achieves stable 2-minute video synthesis on a single H200 GPU using only 5-second training clips.
Method
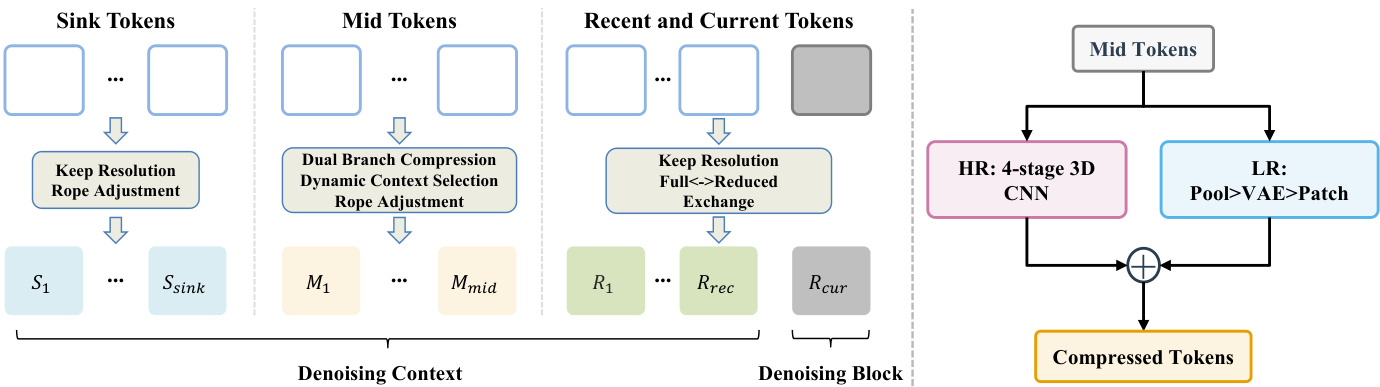
The authors propose PackForcing, a framework designed to resolve the memory bottleneck in autoregressive video generation by decoupling the generation history into three distinct functional partitions. Refer to the framework diagram for the overall architecture. The system organizes the denoising context into Sink Tokens, Mid Tokens, and Recent and Current Tokens. Sink Tokens correspond to the initial frames and are kept at full resolution to serve as semantic anchors. Recent and Current Tokens maintain high-fidelity local dynamics at full resolution. The vast majority of the history falls into the Mid Tokens partition, which undergoes aggressive compression to reduce the token count by approximately 32 times.
To achieve this compression, the authors employ a dual-branch compression module. As shown in the figure below, this module processes the Mid Tokens through two parallel pathways. The High-Resolution (HR) branch utilizes a 4-stage 3D CNN to preserve fine-grained structural details. The Low-Resolution (LR) branch decodes the latent frames to pixel space, applies pooling, and re-encodes them via a VAE to capture coarse semantics. These features are fused via element-wise addition to produce the final compressed tokens.
The specific architecture of the HR branch is detailed in the subsequent figure. It consists of a cascade of strided 3D convolutions with SiLU activations. The process begins with a temporal compression followed by three stages of spatial compression, culminating in a projection to the model's hidden dimension. This design ensures a significant volume reduction while retaining essential layout information.

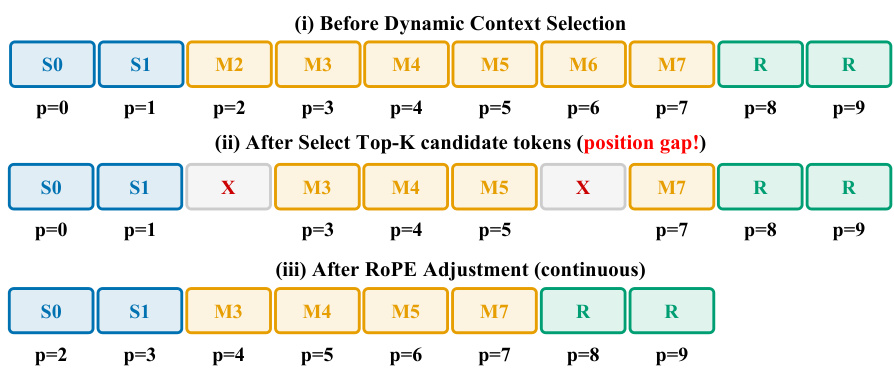
To further optimize memory usage, the system implements Dynamic Context Selection. Instead of attending to all compressed mid tokens, the model evaluates query-key affinities to route only the top-K most informative blocks. This selection process inevitably creates position gaps in the token sequence. To resolve this, the authors apply an incremental RoPE adjustment. Refer to the diagram illustrating the selection process to see how the position indices are re-aligned. Initially, the selection creates gaps where tokens are removed. The RoPE adjustment then shifts the positional embeddings of the remaining tokens to ensure continuous indices, allowing the transformer to maintain temporal coherence without full recomputation.
Finally, the training strategy involves end-to-end optimization of the HR compression layer. During the rollout phase, the compression module is integrated directly into the computational graph. This ensures that the compressed mid tokens are explicitly tailored to preserve semantic and structural cues necessary for downstream causal attention, rather than minimizing a generic reconstruction loss. This approach allows the model to generalize from short training sequences to long video generation with constant attention complexity.
Experiment
- Main experiments on 60s and 120s video generation validate that PackForcing achieves superior motion synthesis and temporal stability compared to baselines, maintaining high subject and background consistency without the severe degradation seen in other methods.
- Long-range consistency tests confirm that the sink token mechanism effectively anchors global semantics, preventing the compounding errors and semantic drift that typically occur in extended autoregressive generation.
- Ablation studies demonstrate that sink tokens are critical for balancing dynamic motion with semantic coherence, while dynamic context selection outperforms standard FIFO eviction by retaining highly attended historical blocks.
- Analysis of attention patterns reveals that information demand is distributed across the entire video history rather than being limited to recent frames, justifying the need for a compressed mid-buffer and global summary tokens.
- Qualitative evaluations show that the proposed architecture preserves fine visual details and complex continuous motion over two minutes, whereas competing methods suffer from color shifts, object duplication, or motion freezing.
- Efficiency analysis proves that the compression strategy bounds memory usage to a constant level regardless of video length, enabling long-horizon generation on single GPUs where uncompressed methods would fail.