Command Palette
Search for a command to run...
EVA: Effizientes Reinforcement Learning für End-to-End Video-Agenten
EVA: Effizientes Reinforcement Learning für End-to-End Video-Agenten
Yaolun Zhang Ruohui Wang Jiahao Wang Yepeng Tang Xuanyu Zheng Haonan Duan Hao Lu Hanming Deng Lewei Lu
Zusammenfassung
Das Verständnis von Videos mittels multimodaler Large Language Models (MLLMs) bleibt aufgrund der langen Token-Sequenzen von Videos, die umfangreiche zeitliche Abhängigkeiten und redundante Frames enthalten, nach wie vor eine Herausforderung. Bestehende Ansätze behandeln MLLMs typischerweise als passive Erkennungssysteme, die entweder ganze Videos oder gleichmäßig abgetastete Frames verarbeiten, ohne adaptive Schlussfolgerungen zu ermöglichen. Neuere agentenbasierte Methoden führen zwar externe Tools ein, sind jedoch weiterhin auf manuell entworfene Workflows und Perzeptions-first-Strategien angewiesen, was zu Ineffizienzen bei langen Videos führt.Wir stellen EVA vor, einen effizienten Reinforcement-Learning-Framework für End-to-End Video Agents, der eine Planung vor der Perzeption durch ein iteratives Reasoning-Verfahren mit den Schritten Zusammenfassung, Planung, Aktion und Reflexion ermöglicht. EVA entscheidet autonom, was, wann und wie zu beobachten ist, und erreicht so eine abfragegesteuerte und effiziente Videoanalyse. Zur Schulung solcher Agenten entwerfen wir eine einfache, aber effektive dreistufige Lernpipeline, die aus Supervised Fine-Tuning (SFT), Kahneman-Tversky Optimization (KTO) und Generalized Reward Policy Optimization (GRPO) besteht und überwachtes Imitationslernen mit Reinforcement Learning verbindet. Zusätzlich stellen wir für jede Stufe hochwertige Datensätze bereit, die ein stabiles und reproduzierbares Training ermöglichen.Wir evaluieren EVA an sechs Benchmarks für das Videoverständnis und demonstrieren dessen umfassende Fähigkeiten. Im Vergleich zu bestehenden Baselines erzielt EVA eine signifikante Verbesserung von 6–12 % gegenüber allgemeinen MLLM-Baselines sowie eine weitere Steigerung von 1–3 % gegenüber früheren adaptiven Agentenmethoden. Unser Code und unser Modell sind verfügbar unter: https://github.com/wangruohui/EfficientVideoAgent.
One-sentence Summary
Researchers from SenseTime Research propose EVA, an Efficient Reinforcement Learning framework for End-to-End Video Agents that shifts from passive recognition to planning-before-perception. By utilizing a three-stage training pipeline with KTO and GRPO, EVA autonomously selects video segments for query-driven understanding, outperforming prior adaptive methods on six benchmarks.
Key Contributions
- The paper introduces EVA, an efficient reinforcement learning framework for an end-to-end video agent that enables planning-before-perception through iterative summary-plan-action-reflection reasoning to autonomously decide what, when, and how to watch.
- A three-stage training pipeline is designed to bridge supervised imitation and reinforcement learning by combining supervised fine-tuning, Kahneman-Tversky Optimization, and Generalized Reward Policy Optimization for stable and scalable policy learning.
- High-quality datasets named EVA-SFT, EVA-KTO, and EVA-RL are constructed to support each training stage, while evaluations on six benchmarks demonstrate a 6–12% improvement over general MLLM baselines and a 1–3% gain over prior adaptive agent methods.
Introduction
Video understanding with Multimodal Large Language Models (MLLMs) is critical for applications like question answering and retrieval, yet it struggles with the massive token sequences and temporal redundancy inherent in long videos. Prior approaches often treat MLLMs as passive recognizers that process uniformly sampled frames or rely on rigid, manually designed agent workflows, leading to inefficient perception and limited reasoning capabilities. To address these challenges, the authors introduce EVA, an Efficient Reinforcement Learning framework that shifts to a planning-before-perception paradigm where the agent autonomously decides what, when, and how to watch based on iterative summary-plan-action-reflection cycles. They further develop a three-stage training pipeline combining Supervised Fine-Tuning, Kahneman-Tversky Optimization, and Generalized Reward Policy Optimization to stabilize learning and achieve state-of-the-art performance across multiple benchmarks.
Dataset
-
Dataset Composition and Sources The authors construct a multi-stage dataset pipeline starting with synthetic agentic video understanding data generated by the Qwen2.5-VL-72B teacher MLLM. The foundational video QA pairs are sourced from llava-video for short videos and cgbench for long videos. Later stages incorporate data from HD-VILA to ensure exposure to unseen video content.
-
Key Details for Each Subset
- SFT Subset: Instances follow a Summary + Planning + Action + Reflection format. Prompts include Past Success Experiences, Diverse Workflow Hints, and Reflective Thinking Prompts to guide the teacher model.
- KTO Subset: This set contains single-sample preference labels derived from the SFT pipeline. Rejected samples are incorrect trajectories identified by an LLM As Judge for lacking visual evidence or guessing, while chosen samples are resampled high-quality successful trajectories.
- GRPO Subset: This dynamic dataset begins with failure cases from the KTO-trained model. It is subsequently enhanced with new open-ended QA pairs generated by the teacher MLLM conditioned on these failure cases and sampled from HD-VILA.
-
Model Usage and Training Strategy The authors employ a three-phase training approach. First, the base model undergoes Supervised Fine-Tuning (SFT) to learn tool-calling formats and reasoning patterns. Second, they apply Kahneman-Tversky Optimization (KTO) to help the model distinguish between successful and failed strategies using the preference data. Finally, they implement a Data-Enhanced Multi-Stage GRPO pipeline where the model iteratively learns from its own failures, with the dataset continuously refreshed by the teacher MLLM to prevent overfitting to static queries.
-
Processing and Metadata Construction The SFT data construction explicitly structures metadata into four stages to ground visual evidence and estimate action costs. The KTO phase filters data based on reasoning quality rather than pairwise dialogue rounds to better suit multi-turn interactions. For the GRPO phase, the authors avoid multiple-choice questions to prevent reward hacking and instead generate concise open-ended answers. The pipeline also utilizes an LLM As Judge to categorize trajectories and employs in-context learning with failure cases to guide the generation of new training examples.
Method
The authors formulate the active video understanding problem as a Markov Decision Process (MDP). At each timestep t, the agent observes a belief state st={q,ht,Ft}, where q denotes the user query, ht represents the interleaved text-frame history, and Ft corresponds to the visual evidence obtained from tool calls. The policy of the agent is parameterized as πθ(at∣st). A core philosophy distinguishing this framework is the "Plan First" paradigm, which contrasts with traditional "Perception First" approaches. As shown in the figure below:
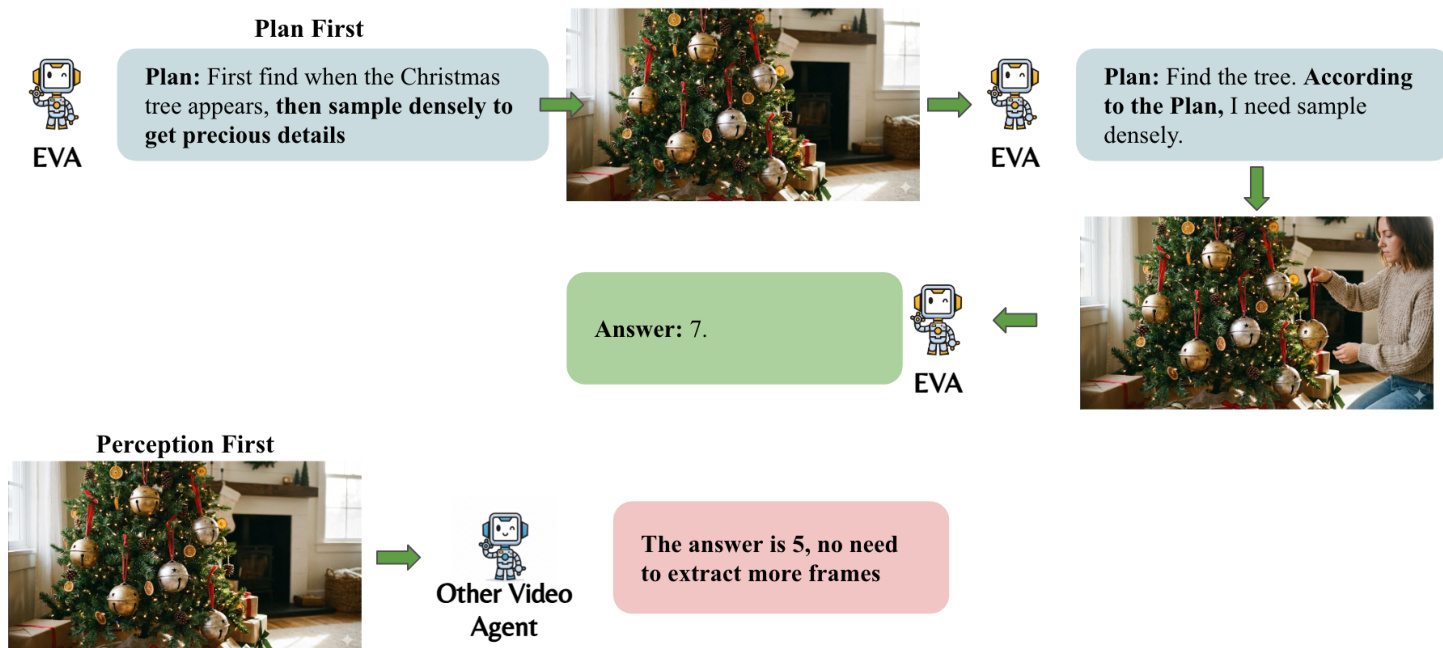 By formulating a plan before observing the video, the agent avoids visual misguidance from irrelevant frames and saves visual tokens by identifying only the necessary content.
By formulating a plan before observing the video, the agent avoids visual misguidance from irrelevant frames and saves visual tokens by identifying only the necessary content.
To enable autonomous planning of visual tokens, the authors design a flexible frame-selection tool that allows both temporal and spatial control. The tool schema includes parameters for start_time, end_time, nframes, and resize. Refer to the framework diagram:
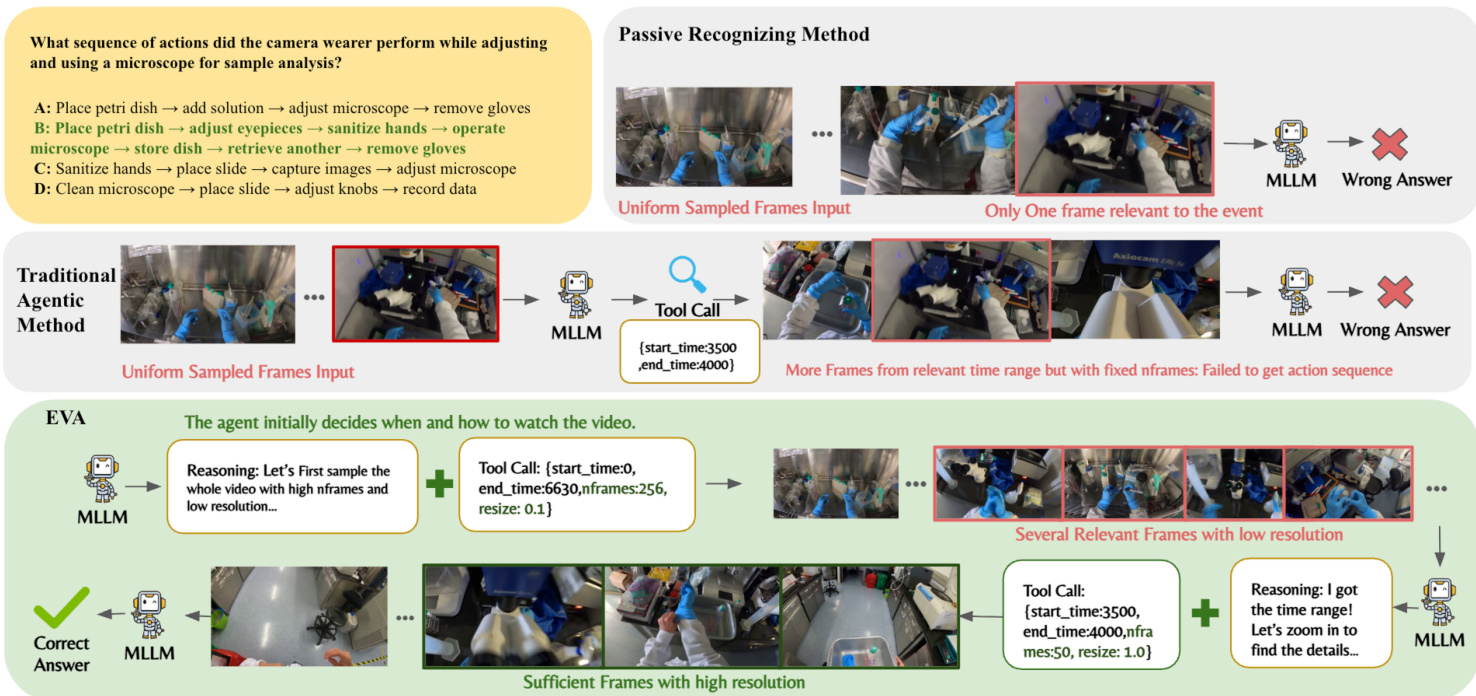 This tool provides a broad exploration space, encouraging the agent to learn how to allocate temporal and spatial information across rounds. The agent iteratively reasons and calls tools to retrieve specific frames, a process that involves an Executor and a Reflective Thinker. The data generation pipeline for this process is illustrated below:
This tool provides a broad exploration space, encouraging the agent to learn how to allocate temporal and spatial information across rounds. The agent iteratively reasons and calls tools to retrieve specific frames, a process that involves an Executor and a Reflective Thinker. The data generation pipeline for this process is illustrated below:
 Successful trajectories are archived in an Experience Bank to guide the Executor in future iterations.
Successful trajectories are archived in an Experience Bank to guide the Executor in future iterations.
The training process involves three stages: Supervised Fine-Tuning (SFT), Offline Learning, and Online Learning. As shown in the figure below:
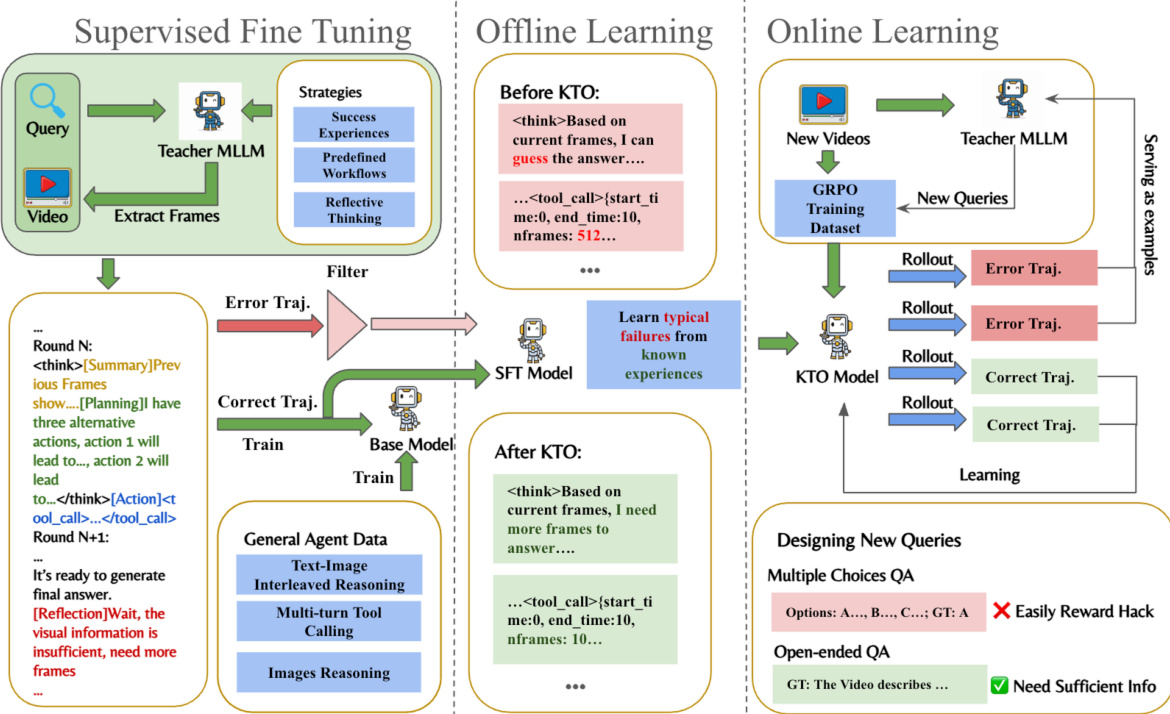 In the SFT stage, a Teacher MLLM generates strategies such as Success Experiences and Reflective Thinking. Offline learning utilizes KTO to learn from typical failures. Online learning employs Group Relative Policy Optimization (GRPO) with a composite reward function. The reward function combines accuracy rewards (CSV for multiple-choice, ROUGE for open-ended) and format rewards to prevent the model from guessing without proper reasoning.
In the SFT stage, a Teacher MLLM generates strategies such as Success Experiences and Reflective Thinking. Offline learning utilizes KTO to learn from typical failures. Online learning employs Group Relative Policy Optimization (GRPO) with a composite reward function. The reward function combines accuracy rewards (CSV for multiple-choice, ROUGE for open-ended) and format rewards to prevent the model from guessing without proper reasoning.
Examples of the agent's reasoning and tool parameter selection are shown below:
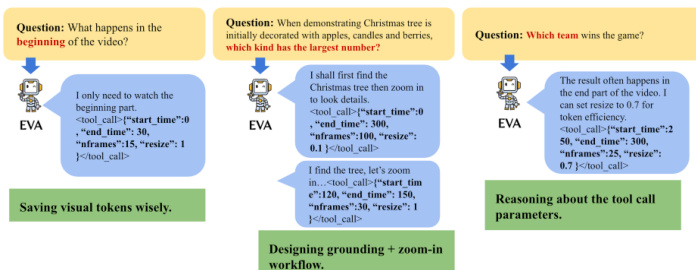 The agent demonstrates the ability to save visual tokens by only watching relevant parts, design grounding plus zoom-in workflows, and reason about tool call parameters.
The agent demonstrates the ability to save visual tokens by only watching relevant parts, design grounding plus zoom-in workflows, and reason about tool call parameters.
Experiment
- Evaluation on the Sampling Dilemma Bench validates that the EVA agent effectively balances visual understanding and efficiency by using iterative reasoning to select frames, achieving higher accuracy with significantly fewer visual tokens compared to dense sampling baselines.
- Testing across long-form video benchmarks demonstrates that the planning-before-perception paradigm allows the model to adaptively allocate attention to relevant segments, maintaining high performance in temporally extended scenarios with minimal frame usage.
- Zero-shot assessments on the Video-Holmes benchmark confirm the model's strong generalization capabilities for multi-step reasoning and causal understanding without task-specific supervision.
- Ablation studies reveal that the sequential SFT-KTO-GRPO training scheme progressively transforms the agent from a format-following imitator into a strategic explorer, while mixing open-ended and multiple-choice data during GRPO prevents reward hacking and ensures visually grounded reasoning.
- Efficiency analysis shows that despite multi-round planning, the total computation remains competitive with uniform sampling because inference time is dominated by a compact set of adaptively selected visual tokens rather than the number of reasoning steps.
- Behavior analysis illustrates the agent's autonomous decision-making process, where it initially explores broadly and subsequently zooms in on specific segments for fine-grained information.
- Performance on the ELV-Halluc benchmark highlights the model's ability to reduce semantic aggregation hallucinations by precisely locating timestamps and enhancing frame-level perception through its agentic tool-call framework.