Command Palette
Search for a command to run...
Von statischen Vorlagen zu dynamischen Laufzeitgraphen: Eine Übersicht zur Workflow-Optimierung für LLM Agents
Von statischen Vorlagen zu dynamischen Laufzeitgraphen: Eine Übersicht zur Workflow-Optimierung für LLM Agents
Ling Yue Kushal Raj Bhandari Ching-Yun Ko Dhaval Patel Shuxin Lin Nianjun Zhou Jianxi Gao Pin-Yu Chen Shaowu Pan
Zusammenfassung
LLM-basierte Systeme gewinnen zunehmend an Bedeutung, um Aufgaben durch die Konstruktion ausführbarer Workflows zu lösen, die Aufrufe von LLMs, Informationsabruf, Werkzeugnutzung, Codeausführung, Speicheraktualisierungen und Verifikation miteinander verknüpfen. Dieser Survey stellt aktuelle Methoden zur Gestaltung und Optimierung solcher Workflows vor, die wir als agentic computation graphs (ACGs) betrachten. Wir strukturieren die Fachliteratur danach, wann die Workflow-Struktur festgelegt wird; unter „Struktur" verstehen wir, welche Komponenten oder Agenten vorhanden sind, wie sie voneinander abhängen und wie Informationen zwischen ihnen fließen. Diese Perspektive unterscheidet statische Methoden, die vor dem Deployment einen wiederverwendbaren Workflow-Scaffold festlegen, von dynamischen Methoden, die vor oder während der Ausführung den Workflow für einen spezifischen Lauf auswählen, generieren oder revidieren. Darüber hinaus gliedern wir die bisherigen Arbeiten entlang dreier Dimensionen: Zeitpunkt der Strukturbestimmung, welcher Teil des Workflows optimiert wird und welche Evaluierungssignale die Optimierung steuern (z. B. Aufgabenmetriken, Verifiziersignale, Präferenzen oder aus Traces abgeleitete Rückmeldungen). Wir trennen zudem wiederverwendbare Workflow-Templates, laufspezifisch realisierte Graphen und Ausführungs-Traces, um wiederverwendbare Designentscheidungen von den in einem konkreten Lauf tatsächlich eingesetzten Strukturen sowie vom realisierten Laufzeitverhalten abzugrenzen. Abschließend skizzieren wir eine strukturbewusste Evaluierungsperspektive, die nachgelagerte Aufgabenmetriken durch Graphen-Eigenschaften, Ausführungskosten, Robustheit und strukturelle Variation über verschiedene Eingaben hinweg ergänzt. Unser Ziel ist es, ein klares Vokabular, ein einheitliches Framework zur Einordnung neuer Methoden, eine vergleichbarere Sicht auf den bestehenden Forschungsstand sowie reproduzierbarere Evaluierungsstandards für zukünftige Arbeiten zur Workflow-Optimierung bei LLM-Agenten bereitzustellen.
One-sentence Summary
Researchers from Rensselaer Polytechnic Institute and IBM Research propose a unified framework for agentic computation graphs, distinguishing static and dynamic workflow structures to optimize LLM agent systems. This survey introduces a structure-aware evaluation perspective that enhances reproducibility and clarifies design choices for complex, tool-intelligent workflows.
Key Contributions
- The paper introduces agentic computation graphs (ACGs) as a unifying abstraction for executable LLM workflows, distinguishing between static methods that fix scaffolds before deployment and dynamic methods that generate or revise structures during execution.
- A three-dimensional taxonomy is presented to organize existing literature based on when structure is determined, which workflow components are optimized, and the specific evaluation signals that guide the optimization process.
- A structure-aware evaluation perspective is outlined that complements downstream task metrics with graph-level properties, execution cost, robustness, and structural variation to establish a more reproducible standard for future research.
Introduction
Large language model (LLM) systems are evolving from simple chatbots into complex agentic computation graphs that coordinate tools, code execution, and verification to solve tasks. The overall workflow structure, which dictates component dependencies and information flow, often determines system effectiveness and cost more than individual model capabilities alone. However, prior research and surveys have largely treated workflow design as a fixed implementation detail or focused on adjacent topics like tool selection and agent collaboration, leaving the optimization of the workflow structure itself as a first-class object largely unaddressed. To fill this gap, the authors introduce a unified framework that treats workflows as agentic computation graphs and categorizes methods based on when the structure is determined, ranging from static offline template search to dynamic runtime generation and editing. They further synthesize the literature across optimization targets, feedback signals, and update mechanisms while proposing a new evaluation protocol that separates downstream task metrics from graph-level properties and execution costs.
Dataset
The provided text does not contain a dataset description. It is an appendix section (42. A.1) that catalogs supporting materials such as tables for node-level prompt optimizers, adjacent routing methods, and background frameworks. Consequently, there is no information available regarding dataset composition, sources, subset details, training splits, or data processing strategies to include in the blog post.
Method
The authors introduce the Agentic Computation Graph (ACG) as a unifying abstraction for executable LLM-centered workflows. In this framework, nodes perform atomic actions such as LLM calls, information retrieval, or tool use, while edges encode control, data, or communication dependencies. The overall optimization process follows a cycle where a task input is mapped to an ACG, which is then instantiated as a reusable template. This template is executed to produce a trace, which is subsequently analyzed to optimize, observe, and refine the workflow before deployment.
As shown in the figure below:
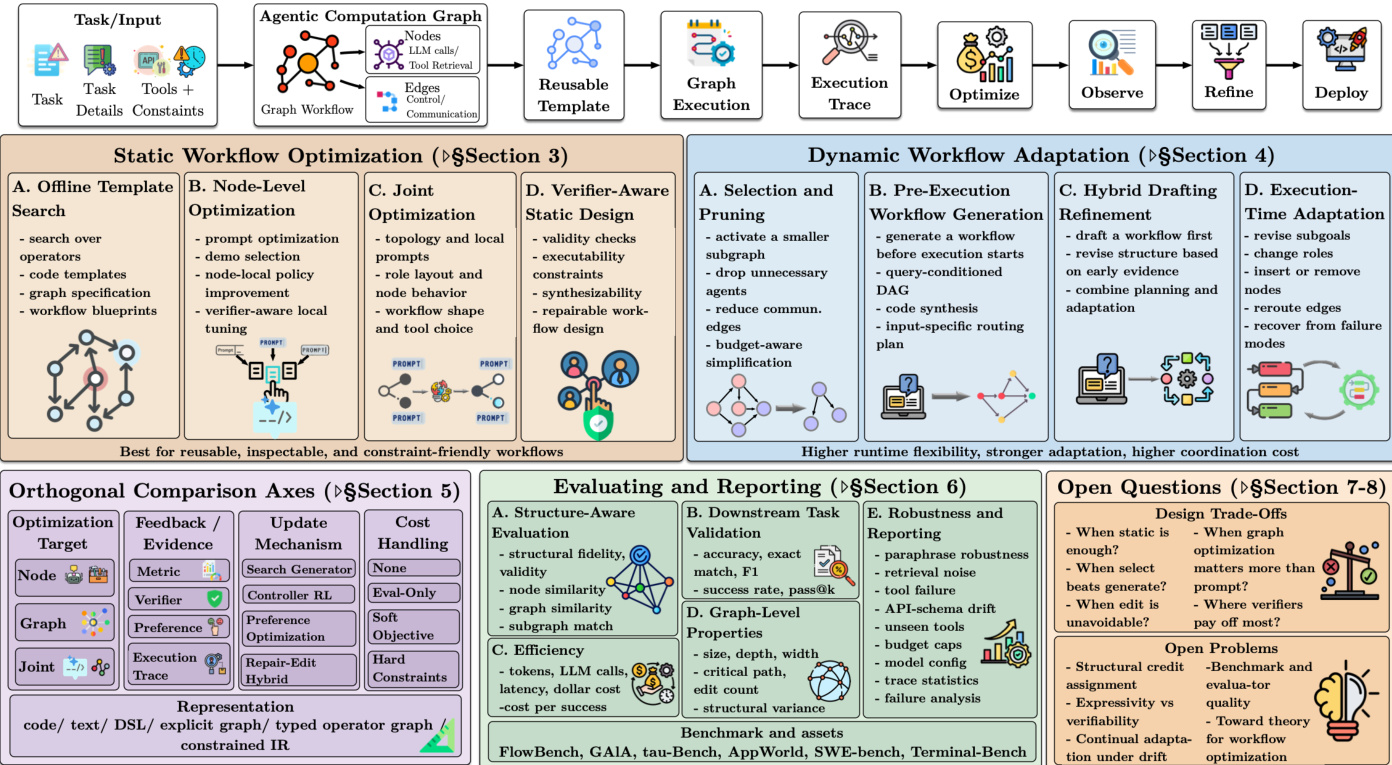
The framework distinguishes between three key objects: the ACG template, the realized graph, and the execution trace. The template is a reusable executable specification defined as Gˉ=(V,E,Φ,Σ,A), where V and E represent nodes and edges, Φ contains node parameters like prompts and tools, Σ is the scheduling policy, and A defines admissible actions. The realized graph Grun is the specific structure actually used for a particular run, which may differ from the template through selection or editing. The execution trace τ={(st,at,ot,ct)}t=1T records the sequence of states, actions, observations, and costs produced during execution.
Workflow optimization methods are categorized based on when the structure is determined. Static methods optimize a reusable template before deployment, focusing on offline template search, node-level optimization, or joint optimization of structure and local configuration. Dynamic methods determine part of the workflow at inference time, allowing for runtime adaptation. This includes selection and pruning of a fixed super-graph, pre-execution workflow generation based on query difficulty, or in-execution editing where the structure is revised during execution in response to feedback. The optimization objective generally balances task quality R(τ;x) against execution cost C(τ), formulated as maximizing E[R(τ;x)−λC(τ)].
The framework also outlines orthogonal comparison axes such as optimization target (node, graph, joint), feedback mechanisms (metric, verifier, preference), and update mechanisms (search generator, controller RL). Evaluation involves structure-aware assessment, downstream task validation, and efficiency metrics. Finally, the authors identify open questions regarding design trade-offs, such as when static optimization suffices versus when dynamic adaptation is necessary, and the role of verifiers in ensuring workflow validity.
Experiment
- A standardized classification card is used to compare methods across stable dimensions like structural settings, optimization levels, and update mechanisms, ensuring consistent evaluation rather than relying on paper-specific descriptions.
- Experiments validate that specific algorithm choices depend heavily on the available signals and evidence; for instance, search works best with trusted evaluators and discrete action spaces, while reinforcement learning suits sequential generation but requires careful reward design.
- Evaluation protocols are shown to require a separation between structure-aware assessment of workflow quality and downstream task validation to distinguish between plausible graph generation and actual task success.
- Studies demonstrate that reporting graph-level properties and robustness under perturbations, such as tool failures or schema drift, is essential to differentiate genuine structural improvements from brute-force compute or uncontrolled cost growth.