Command Palette
Search for a command to run...
PEARL: Personalisiertes Modell für das Streaming-Video-Verständnis
PEARL: Personalisiertes Modell für das Streaming-Video-Verständnis
Zusammenfassung
Die menschliche Kognition neuer Konzepte ist inhärent ein Streaming-Prozess: Wir erkennen kontinuierlich neue Objekte oder Identitäten und aktualisieren unser Gedächtnis im Laufe der Zeit. Aktuelle Methoden zur multimodalen Personalisierung sind jedoch weitgehend auf statische Bilder oder Offline-Videos beschränkt. Diese Trennung von kontinuierlichem visuellen Input und sofortigem Feedback aus der realen Welt schränkt die Fähigkeit ein, die für zukünftige KI-Assistenten essenziellen Echtzeit-Interaktionen mit personalisierten Antworten bereitzustellen. Um diese Lücke zu schließen, stellen wir zunächst die neuartige Aufgabe des Personalized Streaming Video Understanding (PSVU) vor und definieren sie formal. Um die Forschung in dieser neuen Richtung zu fördern, führen wir PEARL-Bench ein, den ersten umfassenden Benchmark, der speziell entwickelt wurde, um dieses herausfordernde Setting zu evaluieren. Der Benchmark bewertet die Fähigkeit eines Modells, zu personalisierten Konzepten zu exakten Zeitstempeln unter zwei Modi zu reagieren: (1) Frame-Level, der sich auf eine bestimmte Person oder ein Objekt in diskreten Frames konzentriert, und (2) ein neuartiger Video-Level, der personalisierte Aktionen fokussiert, die sich über kontinuierliche Frames entfalten. PEARL-Bench umfasst 132 einzigartige Videos und 2.173 fein granulierte Annotationen mit präzisen Zeitstempeln. Die Vielfalt der Konzepte und die Qualität der Annotationen werden durch eine kombinierte Pipeline aus automatisierter Generierung und manueller Verifizierung streng sichergestellt. Um dieses herausfordernde neue Setting zu bewältigen, stellen wir zudem PEARL vor, eine Plug-and-Play-Strategie ohne Training, die als starker Baseline dient. Umfassende Evaluierungen über 8 Offline- und Online-Modelle hinweg zeigen, dass PEARL State-of-the-Art-Leistung erzielt. Bemerkenswert ist, dass es bei Anwendung auf drei verschiedene Architekturen konsistente Verbesserungen im PSVU-Bereich bringt und sich somit als hochwirksame und robuste Strategie erweist. Wir hoffen, dass diese Arbeit die Personalisierung von Vision-Language-Modellen (VLM) vorantreibt und weitere Forschung zu Streaming-basierten personalisierten KI-Assistenten inspiriert. Der Code ist verfügbar unter https://github.com/Yuanhong-Zheng/PEARL.
One-sentence Summary
Researchers from Peking University and collaborators propose PEARL, a training-free framework for Personalized Streaming Video Understanding that introduces a dual-grained memory system to enable real-time, personalized responses in continuous video streams, outperforming existing offline and online models on their new PEARL-Bench.
Key Contributions
- The paper introduces the Personalized Streaming Video Understanding task and PEARL-Bench, the first comprehensive benchmark featuring 132 videos and 2,173 fine-grained annotations to evaluate frame-level and video-level personalization with precise temporal localization.
- A training-free, plug-and-play framework named PEARL is presented, which utilizes a Dual-grained Memory System to decouple concept knowledge from stream observations and a Concept-aware Retrieval Algorithm to enable real-time responses without parameter updates.
- Extensive evaluations across eight offline and online models demonstrate that the proposed method achieves state-of-the-art performance, delivering average improvements of 13.79% at the frame-level and 12.80% at the video-level across three distinct architectures.
Introduction
Current Vision-Language Models excel at personalization but remain confined to static images or offline video processing, creating a disconnect with the continuous, real-time nature of human cognition and real-world AI assistant applications. Existing methods struggle to handle streaming visual inputs, dynamically define user concepts on the fly, or provide instant interactive feedback without computationally expensive retraining. To address these gaps, the authors formally define the novel task of Personalized Streaming Video Understanding and introduce PEARL-Bench, the first comprehensive benchmark for evaluating frame-level and video-level personalization in continuous streams. They further propose PEARL, a training-free, plug-and-play framework that leverages a dual-grained memory system and concept-aware retrieval to enable off-the-shelf models to achieve state-of-the-art performance in real-time personalized video understanding.
Dataset
-
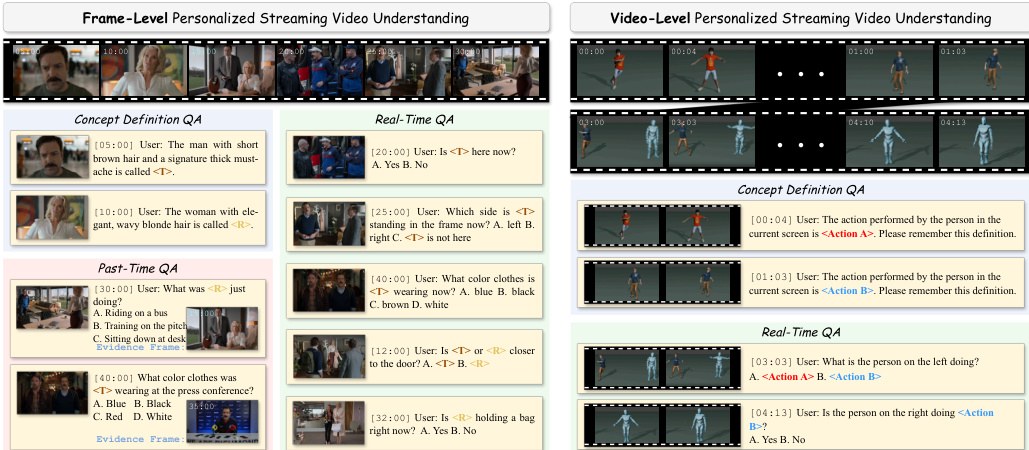
Dataset Composition and Sources: The authors introduce PEARL-Bench, a benchmark comprising 132 videos and 2,173 annotations designed for long-form streaming video personalization. The frame-level split draws from diverse public internet sources including anime, movies, and reality shows, while the video-level split utilizes digital human synthesis via Mixamo assets to ensure repeated, clean action annotations across 8 characters, 20 actions, and 20 backgrounds.
-
Key Details for Each Subset: The dataset supports two distinct concept types: Frame-level concepts (static characters) and Video-level concepts (dynamic actions). Annotations are categorized into three QA types: Concept-Definition for registering new concepts, Real-Time for querying current states, and Past-Time for retrieving historical evidence. The average video duration is 1,458 seconds, with all annotations linked to precise timestamps.
-
Model Usage and Training Strategy: The authors use Concept-Definition QA exclusively for memory registration during the interaction phase and exclude it from final evaluation metrics. Real-Time and Past-Time QA serve as the primary evaluation splits, where models must ground recognized concepts in current scenes or retrieve historical clips to answer questions. The benchmark includes fine-grained sub-categories such as Presence, Behavior, Appearance, Location, Relation, and Action to test multi-dimensional perception.
-
Processing and Metadata Construction: The curation pipeline involves manual filtering for high dynamics and resolution (480p+), followed by a rigorous quality control phase using automated ablation tests and human verification. To enhance robustness, the authors replace original names with 10,000 common names from the U.S. SSA database. They also employ specific prompting strategies to generate compact descriptions that focus on stable features for frame-level concepts and kinematic patterns for video-level concepts, ensuring generalizability across different scenes and subjects.
Method
The authors propose PEARL, a plug-and-play framework designed for Personalized Streaming Video Understanding (PSVU). Unlike prior approaches restricted to static definitions or single-turn interactions, PEARL enables dynamic concept definition and real-time responses within an online streaming video context. Refer to the framework diagram to observe the transition from static image/video understanding to the proposed dynamic, multi-turn streaming capability.
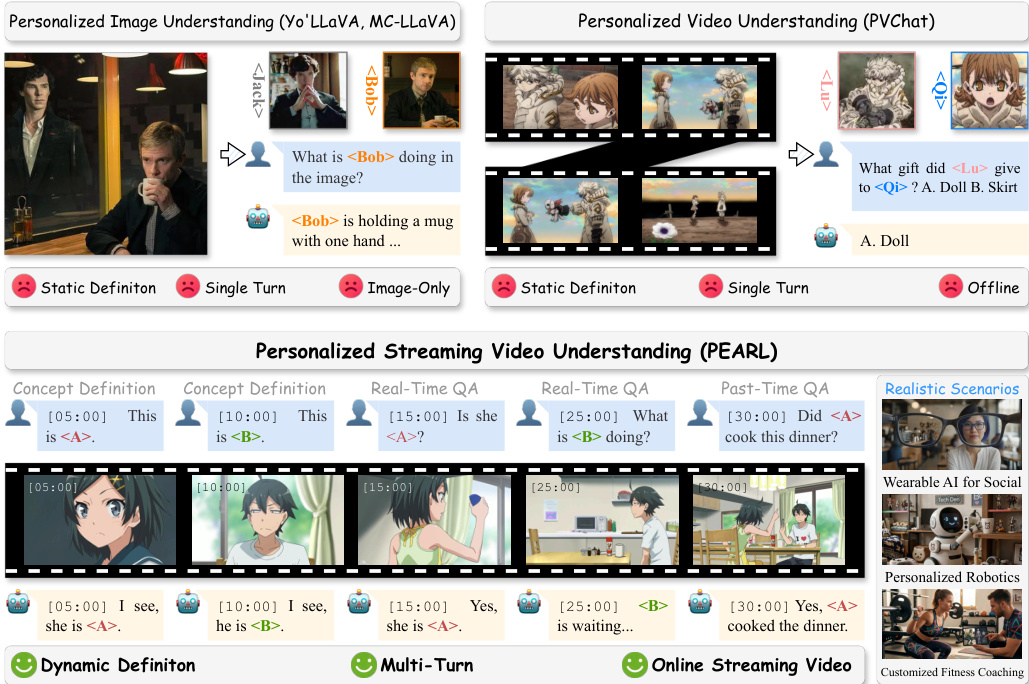
Formally, the streaming video is defined as an infinite sequence V=[X1,X2,…], where Xi represents a semantic scene. Users can dynamically introduce new concepts C at arbitrary timestamps via instructions. For a query Q issued at time tq, the model M constructs a context to generate a response A: A=M(Csub,Vcontext,Q) where Csub is the query-relevant concept subset and Vcontext is the necessary visual context.
To manage the unbounded stream and evolving concepts, the authors design a Dual-grained Memory System that decouples concept-centric knowledge from stream-centric observations. This system comprises a Streaming Memory that incrementally archives segmented clips with compact multimodal embeddings, and a Concept Memory that stores structured representations of user-defined concepts. As shown in the figure below, the architecture explicitly separates these two memory streams to facilitate efficient retrieval.
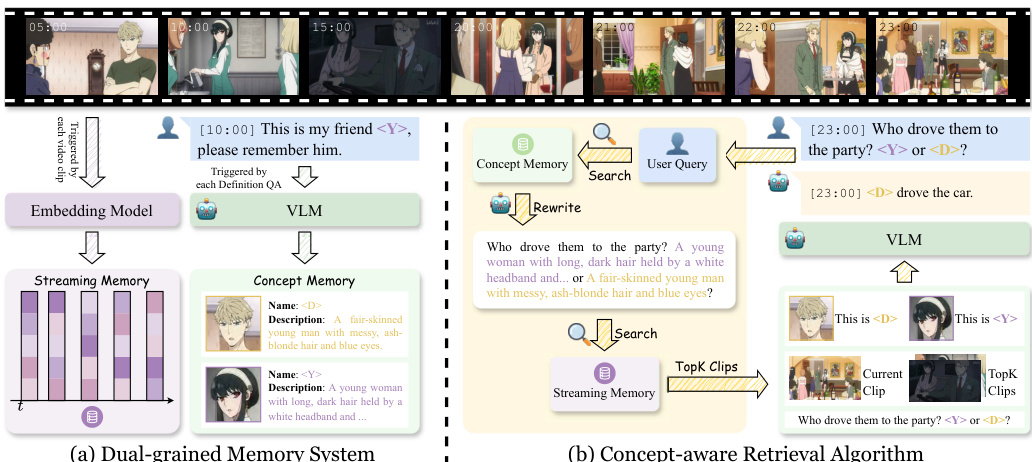
The framework supports both frame-level and video-level concepts. For frame-level concepts, the system stores the last frame of the current clip as visual evidence. For video-level concepts, the entire clip serves as evidence, focusing on core kinematics and movement patterns rather than static identity features. The figure below illustrates examples of these different concept granularities, showing how specific actions or character appearances are defined and queried.
Upon receiving a query, the Concept-aware Retrieval Algorithm is triggered to retrieve relevant information. The model first identifies concept names in the query and retrieves corresponding entries from the Concept Memory. It then rewrites the query by replacing concept names with their textual descriptions to improve retrieval accuracy. This rewritten query is encoded and compared against clip embeddings in the Streaming Memory to select the top-K most relevant historical clips. Finally, the retrieved concepts, historical clips, current clip, and original query are fed into the VLM to generate the response. The interaction flow demonstrates how the system registers video-level concepts via tool calls and subsequently recognizes these actions in real-time.

Experiment
- Baseline comparisons validate that offline models fail on streaming tasks due to limited context and lack of memory, while PEARL significantly outperforms both offline and online baselines across frame-level and video-level settings by effectively managing continuous visual streams.
- Human score and text-only experiments confirm that the benchmark requires visual grounding, as text priors alone yield poor performance while human annotators achieve high accuracy with full visual access.
- Ablation studies demonstrate that Concept Memory is indispensable for linking user-defined names to entities, Streaming Memory is essential for reasoning over historical evidence in past-time queries, and Query Rewriting improves retrieval accuracy by converting personalized names into descriptive semantics.
- Efficiency analysis shows that PEARL introduces minimal latency overhead compared to base models while maintaining real-time capabilities, with inference time dominated by the LLM rather than retrieval modules.
- Hyperparameter and scale analyses reveal that moderate retrieval suffices for accurate answers, excessive historical data can introduce noise for real-time queries, and the framework consistently boosts performance across various model sizes, whereas scaling offline models without a streaming framework yields negligible gains.