Command Palette
Search for a command to run...
ProactiveBench: Benchmarking Proactiveness in Multimodal Large Language Models
ProactiveBench: Benchmarking Proactiveness in Multimodal Large Language Models
Thomas De Min Subhankar Roy Stéphane Lathuilière Elisa Ricci Massimiliano Mancini
Zusammenfassung
Effektive Zusammenarbeit beginnt mit der Fähigkeit zu erkennen, wann Hilfe angefordert werden muss. Beispielsweise würde ein Mensch, der ein verdecktes Objekt identifizieren möchte, eine andere Person bitten, das Hindernis zu entfernen. Können MLLMs ein ähnliches „proaktives" Verhalten zeigen, indem sie einfache Eingriffe durch den Nutzer anfordern? Um dies zu untersuchen, stellen wir ProactiveBench vor, einen Benchmark, der auf sieben wiederverwendeten Datensätzen basiert und Proaktivität über verschiedene Aufgaben hinweg testet, wie etwa das Erkennen verdeckter Objekte, die Verbesserung der Bildqualität und die Interpretation grober Skizzen. Wir evaluieren 22 MLLMs auf ProactiveBench und zeigen, dass (i) ihnen im Allgemeinen Proaktivität fehlt; (ii) Proaktivität nicht mit der Modellkapazität korreliert; und (iii) das „Andeuten" von Proaktivität nur marginale Verbesserungen bringt. Überraschenderweise haben wir festgestellt, dass Konversationsverläufe und In-Context-Learning negative Verzerrungen einführen, die die Leistung beeinträchtigen. Schließlich untersuchen wir eine einfache Fine-Tuning-Strategie auf Basis von Reinforcement Learning: Die Ergebnisse deuten darauf hin, dass Proaktivität erlernbar ist und sogar auf bisher nicht gesehene Szenarien verallgemeinert werden kann. Wir veröffentlichen ProactiveBench öffentlich als ersten Schritt hin zur Entwicklung proaktiver multimodaler Modelle.
One-sentence Summary
Researchers from the University of Trento and collaborating institutes introduce ProactiveBench, a benchmark revealing that current MLLMs lack proactive help-seeking behavior. Their study shows that while standard prompting fails, a simple reinforcement learning fine-tuning strategy successfully teaches models to request user interventions for tasks like handling occlusions.
Key Contributions
- The paper introduces ProactiveBench, a novel benchmark constructed from seven repurposed datasets to evaluate the ability of MLLMs to request user interventions for resolving ambiguous queries across tasks like occlusion removal and sketch interpretation.
- An extensive evaluation of 22 state-of-the-art MLLMs on this benchmark reveals that current models generally lack proactivity, showing that higher model capacity does not correlate with proactive behavior and that conversation histories often introduce negative biases.
- A simple fine-tuning strategy based on reinforcement learning is demonstrated to successfully teach models proactive behaviors, with results indicating that this approach yields substantial performance improvements and generalizes to unseen scenarios.
Introduction
Multimodal Large Language Models (MLLMs) currently operate in reactive modes where they either hallucinate or abstain when facing ambiguous visual queries, missing the human-like ability to proactively seek clarification. Existing research lacks a framework to evaluate whether these models can request additional visual cues, such as object movement or camera adjustments, to resolve uncertainty before answering. To address this gap, the authors introduce ProactiveBench, a novel benchmark comprising over 108k images that tests 19 distinct proactive behaviors across diverse tasks. Their evaluation of 22 state-of-the-art MLLMs reveals that current models struggle with proactiveness, often mistaking low abstention rates for genuine understanding, though they demonstrate that targeted post-training with GRPO can significantly improve these capabilities.
Dataset
ProactiveBench Dataset Overview
The authors introduce ProactiveBench, a novel benchmark designed to evaluate the proactiveness of Multimodal Large Language Models (MLLMs) when facing ambiguous or insufficient visual information. The dataset is constructed by repurposing seven existing datasets to create multi-turn interaction scenarios where models must request human intervention to answer queries correctly.
-
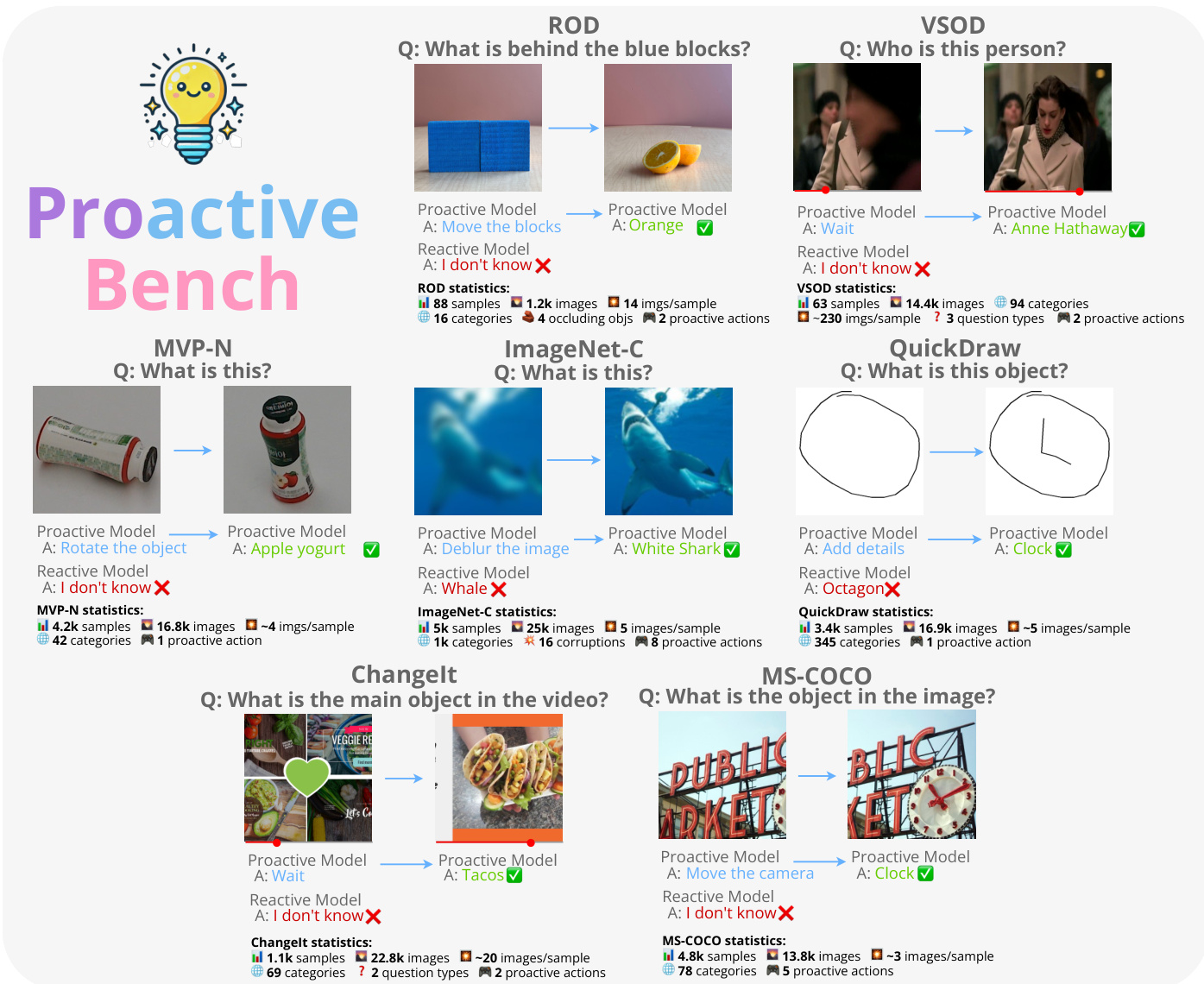
Dataset Composition and Sources The benchmark aggregates data from seven distinct sources, each mapped to a specific proactive scenario:
- ROD: Used for occluded objects, allowing models to request moving blocks to reveal concealed items.
- VSOD: Addresses temporal occlusions by suggesting inspection of frames before or after the occlusion.
- MVP-N: Handles uninformative views by proposing object rotation or camera angle changes.
- ImageNet-C: Focuses on image quality improvements to reduce uncertainty in corrupted images.
- QuickDraw: Requires models to ask for additional strokes to increase drawing detail.
- ChangeIt: Resolves temporal ambiguities by requesting past or future video frames.
- MS-COCO: Manages camera movements, such as zooming or shifting viewpoints, to understand scenes better.
-
Key Details for Each Subset The authors apply specific sampling and filtering rules to ensure data quality and task difficulty:
- Sampling: For large datasets like QuickDraw and ImageNet-C, the authors sample 10 and 5 examples per category, respectively, resulting in 3,450 and 5,000 images.
- Sequence Construction: Datasets like ROD and MVP-N provide sequences ordered from least to most recognizable frames. The authors select the least informative frame (e.g., the first user stroke or the most occluded view) as the initial input.
- Cropping and Filtering: For MS-COCO, images containing more than one object are discarded, and challenging crops with low Intersection over Union (IoU) are generated. For VSOD, frames where the target is fully occluded are manually identified, and celebrity names are annotated via Google Images if not already available.
- Action Spaces: Valid proactive suggestions are generated using rule-based procedures or ChatGPT, with options shuffled during data generation to prevent positional bias.
-
Usage in the Model Evaluation The benchmark is utilized to test MLLMs in both Multi-Choice Question Answering (MCQA) and open-ended generation settings:
- Training and Evaluation Split: The authors use the test or validation sets of the original datasets. No training on ProactiveBench is performed; it serves strictly as an evaluation suite.
- Interaction Flow: Models engage in multi-turn conversations where they can either predict an answer, abstain, or propose a proactive action. The environment updates the visual input based on the model's suggestion (e.g., moving an object or changing a frame).
- Performance Metrics: Success is measured by the model's ability to identify the correct proactive action and subsequently answer the query after the visual state changes.
-
Processing and Filtering Strategy To ensure the benchmark effectively measures proactiveness rather than passive recognition, the authors implement a rigorous filtering pipeline:
- Informativeness Check: Since many original datasets do not annotate frame informativeness, the authors filter out samples where MLLMs can correctly guess the answer from the first frame.
- Filtering Threshold: Samples are removed if they are correctly predicted at least 25% of the time by any evaluated MLLM during the first turn.
- Resulting Statistics: This process reduces the dataset from an original 17,909 samples to a final set of 7,557 samples. Consequently, the average first-turn accuracy drops from 32.5% to 6.4%, forcing models to rely on proactive suggestions to achieve high scores.
Method
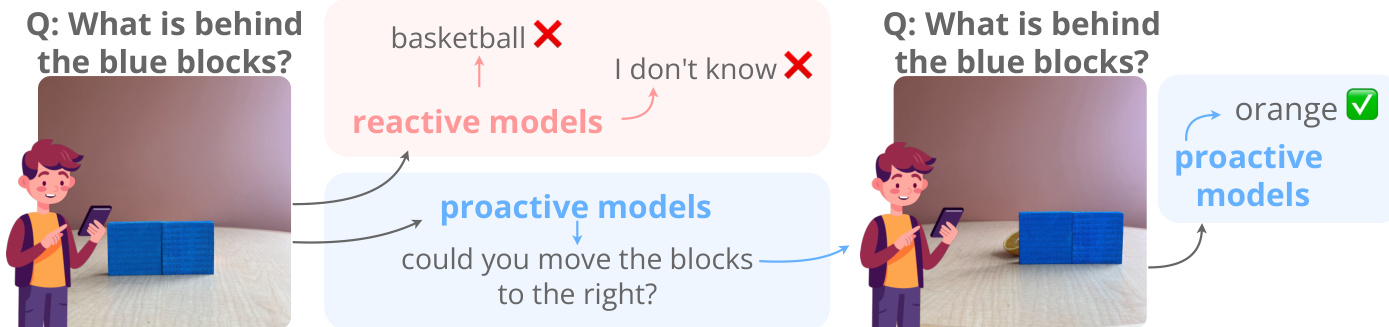
The authors introduce a proactive framework designed to overcome the limitations of passive perception by enabling models to actively interact with their environment. As shown in the figure below, reactive models often struggle with occluded or ambiguous inputs, frequently resulting in incorrect classifications or admissions of ignorance. In contrast, proactive models can issue commands to modify the scene, such as requesting to move occluding blocks, thereby revealing hidden information to answer queries accurately.
This methodology is operationalized through the Proactive Bench, a comprehensive evaluation suite covering diverse tasks. Refer to the framework diagram which outlines the specific datasets included, such as ROD, VSOD, MVP-N, ImageNet-C, QuickDraw, ChangeIt, and MS-COCO. In each scenario, the model receives an initial state and a query, then selects an action to improve the input, such as rotating an object, deblurring an image, or moving a camera. The framework provides detailed statistics for each dataset, tracking the number of samples, images, categories, and the specific proactive actions required to solve the tasks.
To rigorously assess performance, the system employs an LLM-as-a-judge mechanism. The judge evaluates the system output to determine if it contains correct proactive suggestions and accurate category predictions. The evaluation process requires the judge to output its reasoning within <thought> tags before returning a structured response. Specifically, the judge returns comma-separated values where each digit indicates the correctness of a specific answer component, ensuring both the strategic action and the final inference are validated against the ground truth.
Experiment
- ProactiveBench evaluates 22 MLLMs across multiple-choice and open-ended tasks to assess their ability to request user interventions for occluded or ambiguous inputs, revealing that current models generally lack proactivity and that this capability does not scale with model size.
- Experiments show that conversation histories and in-context learning introduce negative biases, causing models to repeatedly suggest unhelpful actions or abstain rather than solving the task, while explicit hinting yields only marginal gains in accuracy.
- A reinforcement learning fine-tuning strategy demonstrates that proactivity can be effectively learned and generalized to unseen scenarios, enabling models to balance between making correct predictions and requesting necessary help.