Command Palette
Search for a command to run...
Überbrückung semantischer und kinematischer Bedingungen mittels eines Diffusionsbasierten diskreten Motion Tokenizers
Überbrückung semantischer und kinematischer Bedingungen mittels eines Diffusionsbasierten diskreten Motion Tokenizers
Chenyang Gu Mingyuan Zhang Haozhe Xie Zhongang Cai Lei Yang Ziwei Liu
Zusammenfassung
Die bisherige Generierung von Bewegungen folgt weitgehend zwei Paradigmen: kontinuierliche Diffusionsmodelle, die sich durch ihre überlegene kinematische Steuerung auszeichnen, sowie diskrete, auf Tokens basierende Generatoren, die für semantische Konditionierung besonders effektiv sind. Um die Stärken beider Ansätze zu vereinen, schlagen wir ein dreistufiges Framework vor, das aus der Extraktion von Konditionsmerkmalen (Perception), der Generierung diskreter Tokens (Planning) und einer diffusionsbasierten Bewegungssynthese (Control) besteht. Im Zentrum dieses Frameworks steht MoTok, ein diffusionsbasierter diskreter Motion-Tokenizer, der semantische Abstraktion von der feinkörnigen Rekonstruktion entkoppelt, indem er die Bewegungswiederherstellung an einen Diffusionsdecoder delegiert. Dies ermöglicht kompakte, einlagige Tokens bei gleichzeitiger Wahrung der Bewegungsfidelität. Für kinematische Bedingungen steuern grobe Constraints die Token-Generierung während der Planungsphase, während während der Steuerungsphase feinkörnige Constraints durch diffusionsbasierte Optimierung durchgesetzt werden. Dieses Design verhindert, dass kinematische Details die semantische Token-Planung stören. Auf dem Datensatz HumanML3D übertrifft unsere Methode MaskControl hinsichtlich der Steuerbarkeit und Fidelity deutlich, verwendet dabei jedoch nur ein Sechstel der Tokens. Die Trajektorienfehler reduzieren sich von 0,72 cm auf 0,08 cm, und der FID-Wert sinkt von 0,083 auf 0,029. Im Gegensatz zu vorherigen Methoden, deren Leistung unter stärkeren kinematischen Constraints nachlässt, verbessert unsere Methode die Fidelity weiter und senkt den FID-Wert von 0,033 auf 0,014.
One-sentence Summary
Researchers from Nanyang Technological University and The Chinese University of Hong Kong propose MoTok, a diffusion-based discrete motion tokenizer that decouples semantic abstraction from kinematic reconstruction to enable compact tokenization and superior trajectory control in human motion generation.
Key Contributions
- The paper introduces a three-stage Perception-Planning-Control paradigm for controllable motion generation that unifies autoregressive and discrete diffusion planners under a single interface to separate high-level planning from low-level kinematics.
- This work presents MoTok, a diffusion-based discrete motion tokenizer that decouples semantic abstraction from fine-grained reconstruction by delegating motion recovery to a diffusion decoder, enabling compact single-layer tokens with a significantly reduced token budget.
- A coarse-to-fine conditioning scheme is developed to inject kinematic signals as coarse constraints during token planning and enforce fine-grained constraints during diffusion denoising, which experiments on HumanML3D show improves controllability and fidelity while reducing trajectory error from 0.72 cm to 0.08 cm.
Introduction
Human motion generation is critical for applications in animation, robotics, and embodied agents, yet existing methods struggle to balance high-level semantic intent with fine-grained kinematic control. Prior token-based approaches often entangle semantic abstraction with low-level motion details, requiring high token rates and causing performance degradation when strong kinematic constraints are applied. The authors propose a three-stage Perception-Planning-Control framework centered on MoTok, a diffusion-based discrete motion tokenizer that decouples semantic planning from motion reconstruction. By delegating fine-grained recovery to a diffusion decoder and applying kinematic constraints in a coarse-to-fine manner across stages, their method achieves compact single-layer tokenization while significantly improving both controllability and motion fidelity.
Method
The authors propose a unified motion generation framework that bridges the strengths of continuous diffusion models for kinematic control and discrete token-based generators for semantic conditioning. This approach follows a three-stage Perception-Planning-Control paradigm, as illustrated in the overview diagram below.
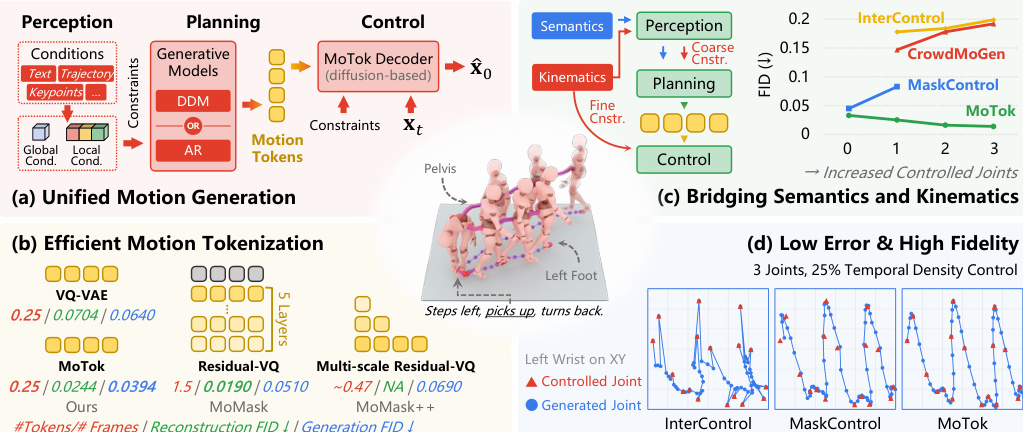
At the core of this framework is MoTok, a diffusion-based discrete motion tokenizer. Unlike conventional VQ-VAE tokenizers that directly decode continuous motion from discrete codes, MoTok factorizes the representation into a compact discrete code sequence and a diffusion decoder for fine-grained reconstruction. This design allows discrete tokens to focus on semantic structure while offloading low-level details to the diffusion process.
Refer to the detailed architecture diagram below for the specific components of the MoTok tokenizer and the unified generation pipeline.
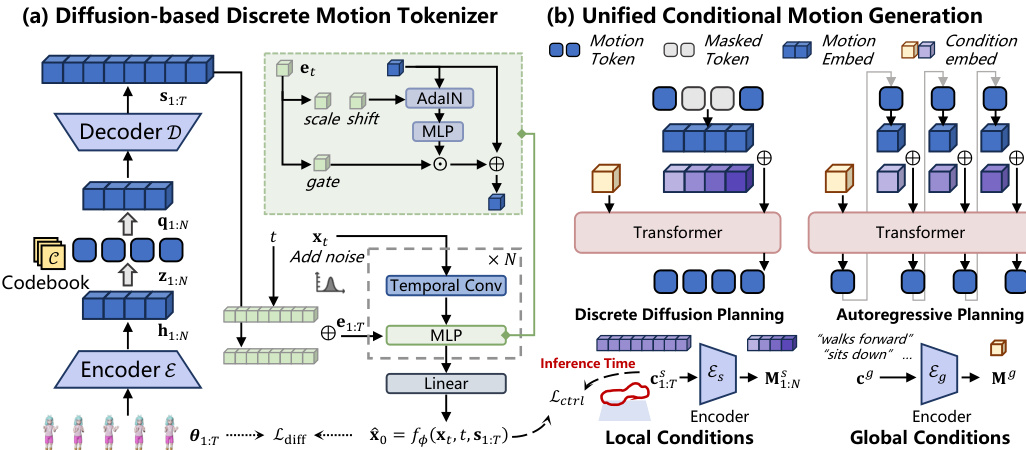
The MoTok tokenizer consists of three primary components. First, a convolutional encoder E(⋅) extracts latent features from the input motion sequence θ1:T through progressive temporal downsampling:
h1:N=E(θ1:T),h1:N∈RN×d,where N is the compressed sequence length and d is the latent dimension. Second, a vector quantizer Q(⋅) maps these latents to a discrete token sequence z1:N by finding the nearest entry in a shared codebook C:
zn=argk∈{1,...,K}min∥hn−ck∥22,qn=czn.Third, instead of direct regression, the decoder employs a conditional diffusion model. A convolutional decoder D(⋅) first upsamples the quantized latents q1:N into a per-frame conditioning signal s1:T. A neural denoiser fϕ then reconstructs the clean motion x^0 from a noisy input xt conditioned on s1:T:
x^0=fϕ(xt,t,s1:T).This diffusion-based decoding provides a natural interface for enforcing fine-grained constraints during the reconstruction phase.
The unified conditional generation pipeline supports both discrete diffusion and autoregressive planners through a shared conditioning interface. Conditions are categorized into global conditions cg (e.g., text descriptions) and local conditions c1:Ts (e.g., target trajectories). Global conditions are encoded into a sequence-level feature Mg, while local conditions are encoded into a token-aligned feature sequence M1:Ns.
During planning in discrete token space, these conditions are injected into the Transformer-based generator. For discrete diffusion planning, a token embedding sequence is constructed where the global condition occupies the first position, and local condition features are added via additive fusion to the motion token positions. For autoregressive planning, the global condition similarly occupies the first position, with local conditions aligned to preceding token positions to preserve temporal causality.
Finally, control is enforced during the diffusion decoding stage. After the discrete tokens are generated, they are decoded into the conditioning sequence s1:T. To ensure adherence to local kinematic constraints, an auxiliary control loss Lctrl is optimized during the denoising process. At each diffusion step k, the motion estimate x^k is refined via gradient descent:
x^k←x^k−η∇x^kLctrl(x^k,c1:Ts),where η controls the refinement strength. This mechanism allows the system to achieve precise low-level control without burdening the discrete planner with high-frequency details.
Experiment
- Controllable motion generation experiments on HumanML3D and KIT-ML validate that MoTok achieves superior trajectory alignment and motion realism compared to baselines, even with significantly fewer tokens.
- Text-to-motion generation tests confirm that MoTok produces higher quality motions with lower FID scores while operating under a reduced token budget, demonstrating efficient semantic planning.
- Ablation studies reveal that diffusion-based decoders outperform convolutional ones by better recovering fine-grained motion details under noisy generation conditions.
- Configuration analysis shows that moderate temporal downsampling and specific kernel sizes optimize the balance between reconstruction quality and planning stability.
- Dual-path conditioning experiments prove that injecting low-level control signals in both the generator and decoder is essential for achieving high fidelity and precise constraint adherence.
- Two-stage training evaluations demonstrate that MoTok tokens encode richer semantic information and allow for better detail recovery than standard VQ-VAE approaches.
- Efficiency comparisons highlight that MoTok generates sequences substantially faster than competing methods while maintaining high performance.