Command Palette
Search for a command to run...
HopChain: Multi-Hop-Datensynthese für generalisierbares visuell-linguistisches Schlussfolgern
HopChain: Multi-Hop-Datensynthese für generalisierbares visuell-linguistisches Schlussfolgern
Zusammenfassung
Vision-Sprache-Modelle (VLMs) weisen zwar starke multimodale Fähigkeiten auf, stoßen jedoch weiterhin bei fein granularer visuell-sprachlicher Schlussfolgerung an Grenzen. Unsere Analyse zeigt, dass langes Chain-of-Thought (CoT)-Reasoning diverse Fehlermodi offenlegt – darunter Wahrnehmungs-, Schlussfolgerungs-, Wissens- und Halluzinationsfehler –, die sich über Zwischenschritte hinweg kumulieren können. Die meisten bestehenden visuell-sprachlichen Datensätze, die für Reinforcement Learning mit verifizierbaren Belohnungen (RLVR) verwendet werden, enthalten jedoch keine komplexen Schlussfolgerungsketten, die durchgehend auf visuellen Evidenzen basieren, sodass diese Schwächen weitgehend unentdeckt bleiben.Daher stellen wir HopChain vor, ein skalierbares Framework zur Synthese von Multi-Hop-Visuell-Sprach-Daten für das RLVR-Training von VLMs. Jede synthetisierte Multi-Hop-Abfrage bildet eine logisch abhängige Kette instanzengrundierter Hops, bei der frühere Hops die für spätere Hops erforderlichen Instanzen, Mengen oder Bedingungen etablieren, während die endgültige Antwort eine spezifische, eindeutige Zahl bleibt, die sich für verifizierbare Belohnungen eignet.Wir trainieren die Modelle Qwen3.5-35B-A3B und Qwen3.5-397B-A17B unter zwei RLVR-Szenarien: ausschließlich mit den Originaldaten sowie mit den Originaldaten kombiniert mit den Multi-Hop-Daten von HopChain. Die Leistung wird über 24 Benchmarks hinweg verglichen, die die Bereiche STEM und Puzzles, allgemeine VQA (Visual Question Answering), Texterkennung und Dokumentenverständnis sowie Videoverständnis abdecken. Obwohl diese Multi-Hop-Daten nicht für einen spezifischen Benchmark synthetisiert wurden, verbessern sie bei beiden Modellen 20 von 24 Benchmarks, was auf breite und generalisierbare Leistungssteigerungen hindeutet.Konsistent führt das Ersetzen vollständiger verketteter Abfragen durch Halb-Multi-Hop- oder Single-Hop-Varianten dazu, dass der durchschnittliche Score über fünf repräsentative Benchmarks von 70,4 auf 66,7 bzw. 64,3 sinkt. Bemerkenswert ist, dass die Gewinne durch Multi-Hop-Reasoning im Bereich des langen CoT-Visuell-Sprach-Reasonings ihren Höhepunkt erreichen; im Regime des ultra-langen CoT übersteigen sie 50 Punkte.Diese Experimente etablieren HopChain als ein effektives und skalierbares Framework zur Synthese von Multi-Hop-Daten, das die generalisierbare visuell-sprachliche Schlussfolgerung verbessert.
One-sentence Summary
The Qwen Team and Tsinghua University introduce HopChain, a scalable framework synthesizing multi-hop vision-language reasoning data to address fine-grained errors in VLMs. By generating logically dependent, instance-grounded chains with verifiable numeric answers, HopChain significantly boosts generalizable performance across diverse benchmarks, particularly excelling in long CoT reasoning scenarios.
Key Contributions
- The paper introduces HopChain, a scalable framework that synthesizes multi-hop vision-language reasoning data by constructing logically dependent chains where earlier hops establish instances or conditions required for subsequent steps, ensuring continuous visual re-grounding.
- This work demonstrates that training VLMs with HopChain's synthesized data improves performance on 20 of 24 diverse benchmarks, including STEM, General VQA, and Video Understanding, indicating broad and generalizable gains without benchmark-specific tailoring.
- Experiments show that multi-hop reasoning gains peak in long-CoT regimes with improvements exceeding 50 points, while ablation studies confirm that reducing chain complexity significantly lowers average scores, validating the necessity of full multi-hop structures for robust reasoning.
Introduction
Vision-language models (VLMs) excel at multimodal tasks but often fail during long chain-of-thought reasoning due to compounding errors like hallucination and weak visual grounding. Existing training data for reinforcement learning with verifiable rewards (RLVR) rarely requires complex, multi-step visual evidence, leaving these critical weaknesses unaddressed during model optimization. The authors introduce HopChain, a scalable framework that synthesizes multi-hop reasoning data where each step logically depends on previous visual findings to force continuous re-grounding. This approach generates queries with verifiable numerical answers that expose diverse failure modes, resulting in broad performance gains across 20 of 24 benchmarks without targeting specific downstream tasks.
Dataset
-
Dataset Composition and Sources: The authors synthesize a multi-hop vision-language reasoning dataset designed to force models to seek visual evidence at every step of long-CoT reasoning. The data originates from raw image collections that contain sufficient detectable instances, processed through a four-stage pipeline to create queries that chain multiple reasoning steps into a single task.
-
Key Details for Each Subset:
- Reasoning Levels: Queries are structured as Level 3 tasks that combine Level 1 (single-object perception like text reading or attribute identification) and Level 2 (multi-object perception like spatial or counting relations).
- Hop Types: Each query must include both Perception-level hops (switching between single and multi-object tasks) and Instance-chain hops (moving to a new object based on the previous one).
- Answer Format: All queries terminate in a specific, unambiguous numerical answer to ensure compatibility with RLVR verification.
- Dependency Rules: Substeps must form a logically dependent chain where earlier hops establish the instances or conditions required for later hops, preventing shallow shortcuts.
-
Data Usage and Processing:
- Stage 1 (Category Identification): A VLM identifies semantic categories present in an input image without localization.
- Stage 2 (Instance Segmentation): SAM3 generates segmentation masks and bounding boxes to resolve categories into concrete, spatially localized instances.
- Stage 3 (Query Generation): The system forms combinations of 3–6 instances and uses a VLM to generate multi-hop queries. The model receives the original image plus cropped patches of each instance to aid design, though these patches are not available during the actual reasoning task.
- Stage 4 (Annotation and Calibration): Four human annotators independently solve each query; only queries where all four agree on the numerical answer are retained. Difficulty calibration then removes queries where a weaker model achieves 100% accuracy, ensuring the final dataset contains verified, challenging examples.
-
Cropping and Metadata Strategy:
- Cropping: During the design phase, the pipeline extracts cropped patches for each detected instance using bounding boxes. These patches serve as reference material for the VLM to understand appearance and location but are excluded from the final training prompt to simulate real-world conditions.
- Metadata Construction: The prompt explicitly provides the coordinates of each instance in a 0–1000 range and lists the specific object instances that must be considered for the task.
- Quality Control: The pipeline filters out queries with ambiguous references during human annotation and discards those that are too easy during model-based calibration, ensuring high-quality training signals.
Method
The authors propose a comprehensive framework that integrates scalable data synthesis with advanced reinforcement learning techniques to enhance the multi-hop reasoning capabilities of Vision-Language Models (VLMs). The methodology is divided into three core components: the generation of structured multi-hop training data, the formulation of the reinforcement learning objective, and the optimization algorithm used for policy updates.
Scalable Multi-Hop Data Synthesis
To address the lack of complex reasoning chains in typical training data, the authors leverage a scalable data synthesis pipeline designed to enforce dependency-linked hops with repeated visual grounding. Refer to the framework diagram for an overview of the HopChain Framework for Multi-Hop Data Synthesis.
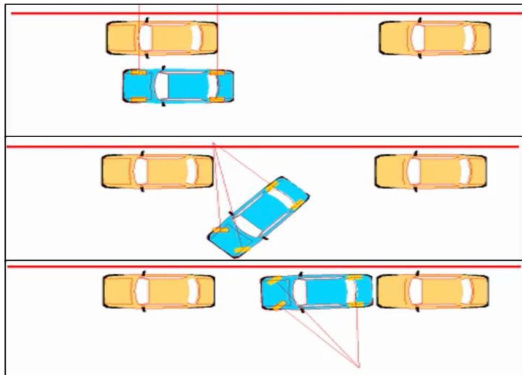
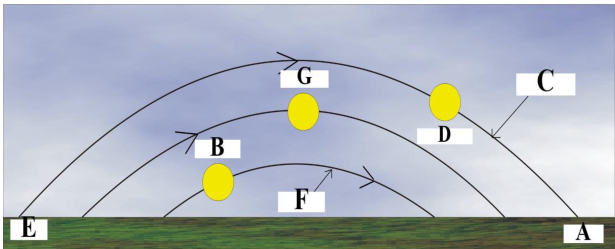
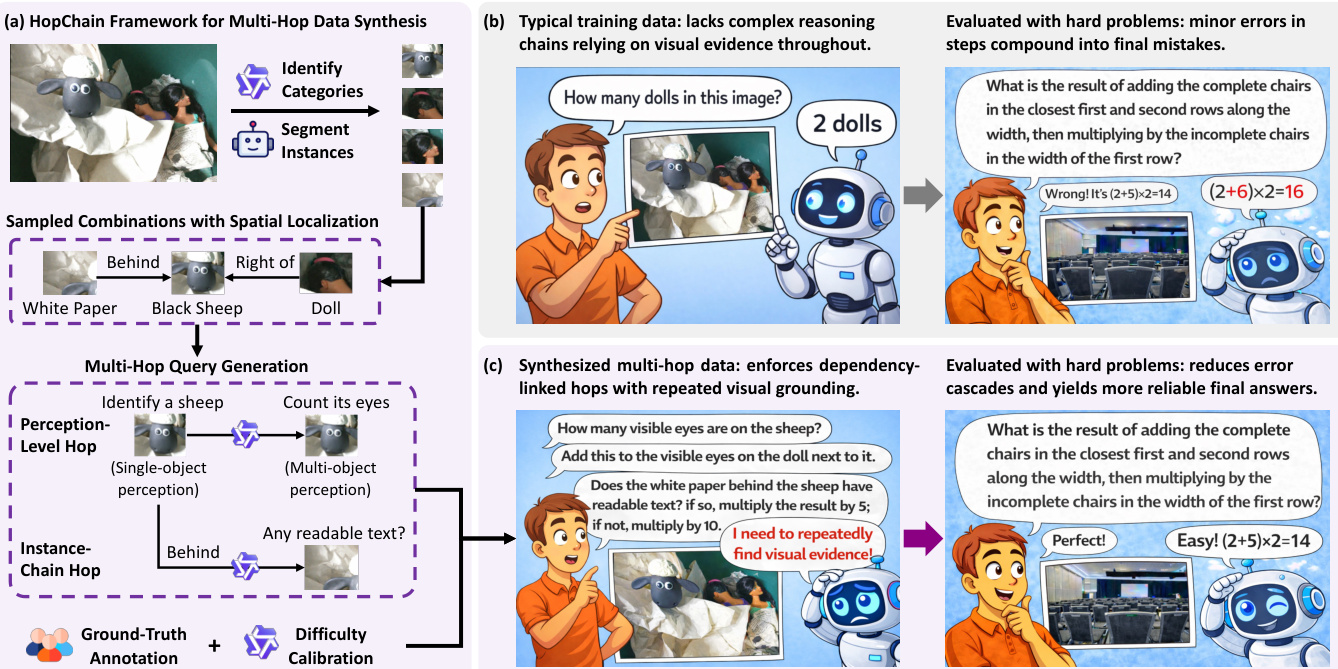 This pipeline utilizes strong foundation models, including VLMs for object detection and SAM for instance segmentation, to construct structured queries from raw images. The synthesis process imposes strict constraints to ensure high quality and generalizability. Each generated query must involve a genuine multi-hop reasoning structure where the instance required at the current hop can only be identified from instances established in earlier hops. Furthermore, the queries are designed to maximize instance coverage, ensuring that every object in a selected combination plays a meaningful role in the reasoning chain. The authors also enforce unambiguous phrasing and deterministic solutions, prohibiting the use of low-level visual features like bounding box colors to locate information. This approach forces the model to recover and retain intermediate visual evidence rather than relying on language-only heuristics. Examples of the visual complexity handled by this synthesis process include spatial reasoning tasks involving vehicle positions and logical reasoning tasks involving trajectory analysis.
This pipeline utilizes strong foundation models, including VLMs for object detection and SAM for instance segmentation, to construct structured queries from raw images. The synthesis process imposes strict constraints to ensure high quality and generalizability. Each generated query must involve a genuine multi-hop reasoning structure where the instance required at the current hop can only be identified from instances established in earlier hops. Furthermore, the queries are designed to maximize instance coverage, ensuring that every object in a selected combination plays a meaningful role in the reasoning chain. The authors also enforce unambiguous phrasing and deterministic solutions, prohibiting the use of low-level visual features like bounding box colors to locate information. This approach forces the model to recover and retain intermediate visual evidence rather than relying on language-only heuristics. Examples of the visual complexity handled by this synthesis process include spatial reasoning tasks involving vehicle positions and logical reasoning tasks involving trajectory analysis.
Reinforcement Learning with Verifiable Rewards The training process employs Reinforcement Learning with Verifiable Rewards (RLVR) for VLMs. This framework closely parallels RLVR for Large Language Models but processes both an image and a text query as input to generate a textual chain-of-thought culminating in a verifiable answer prediction. The primary objective is to maximize the expected reward, defined as:
J(π)=E(I,q,a)∼D,o∼π(⋅∣I,q)[R(o,a)],whereR(o,a)={1.00.0if is_equivalent(o,a),otherwise.Here, I, q, and a denote the image, text query, and ground-truth answer, respectively, sampled from dataset D, and o represents the response generated by policy π conditioned on I and q. The reward function provides a binary signal based on whether the generated output is equivalent to the ground truth.
Soft Adaptive Policy Optimization To mitigate potential instability and inefficiency caused by hard clipping in prior RLVR algorithms, the authors introduce Soft Adaptive Policy Optimization (SAPO). This method substitutes hard clipping with a temperature-controlled soft gate. The optimization objective for VLMs is formulated as:
J(θ)=E(I,q,a)∼D,{oi}i=1G∼πold(⋅∣I,q)G1i=1∑G∣oi∣1t=1∑∣oi∣fi,t(ri,t(θ))A^i,t,where the probability ratio ri,t(θ) is defined as the ratio of the current policy to the old rollout policy. The advantage term A^i,t is computed by normalizing the reward Ri across a group of samples. The function fi,t(x) acts as a soft gate controlled by temperatures τpos and τneg for positive and negative tokens, respectively. This adaptive mechanism allows for smoother policy updates and improved training stability compared to traditional clipping methods.
Experiment
- Analysis of diverse failure modes in long Chain-of-Thought reasoning reveals that errors are not isolated but compounding, with perception mistakes often triggering downstream reasoning, knowledge, and hallucination failures across various visual scenarios.
- Main benchmark evaluations demonstrate that augmenting standard RLVR training with HopChain-synthesized multi-hop data yields broad, generalizable improvements across 20 out of 24 benchmarks for both small and large model scales, covering STEM, general VQA, document understanding, and video tasks.
- Ablation studies confirm that preserving the full multi-hop structure during training is essential, as models trained on shortened or single-hop variants show significantly lower performance, validating the necessity of maintaining long cross-hop dependencies.
- Further analysis indicates that the proposed method effectively strengthens robustness in ultra-long reasoning chains, covers a wide spectrum of query difficulties, and corrects a diverse range of error types rather than addressing only a narrow subset of failure modes.