Command Palette
Search for a command to run...
MemSifter: Auslagerung der LLM-Speicherretrieval durch ergebnisgesteuertes Proxy-Reasoning
MemSifter: Auslagerung der LLM-Speicherretrieval durch ergebnisgesteuertes Proxy-Reasoning
Jiejun Tan Zhicheng Dou Liancheng Zhang Yuyang Hu Yiruo Cheng Ji-Rong Wen
Zusammenfassung
Da Large Language Models (LLMs) zunehmend für Aufgaben mit langer Laufzeit eingesetzt werden, stellt die Aufrechterhaltung eines effektiven Langzeitgedächtnisses eine kritische Herausforderung dar. Aktuelle Methoden sehen sich häufig einem Zielkonflikt zwischen Kosten und Genauigkeit gegenüber. Einfache Speichermechanismen führen oft dazu, dass relevante Informationen nicht wiedergefunden werden, während komplexe Indexierungsmethoden (wie beispielsweise Gedächtnisgraphen) einen erheblichen Rechenaufwand erfordern und zu Informationsverlusten führen können. Darüber hinaus ist die Abhängigkeit vom primären LLM zur Verarbeitung aller gespeicherten Informationen rechenintensiv und langsam. Um diese Einschränkungen zu adressieren, stellen wir MemSifter vor, ein neuartiges Framework, das den Prozess der Gedächtniswiedergewinnung auf ein kleines Proxy-Modell auslagert. Anstatt die Belastung des primären, operierenden LLM zu erhöhen, nutzt MemSifter ein kleineres Modell, um vor der eigentlichen Informationsretrievalphase eine Schlussfolgerung bezüglich der Aufgabe zu ziehen. Dieser Ansatz erfordert während der Indexierungsphase keinen erheblichen Rechenaufwand und fügt während der Inferenz nur einen minimalen Overhead hinzu. Zur Optimierung des Proxy-Modells führen wir ein gedenktnisspezifisches Paradigma des Reinforcement Learning (RL) ein. Wir entwerfen eine belohnungsbasierte, auf das Aufgabenoutcome ausgerichtete Metrik, die auf der tatsächlichen Leistung des operierenden LLM bei der Aufgabenerfüllung basiert. Die Belohnung quantifiziert den tatsächlichen Beitrag der wiedergewonnenen Gedächtnisinhalte durch multiple Interaktionen mit dem operierenden LLM und differenziert die Rangfolgen der Retrieval-Ergebnisse anhand abgestuft abnehmender Beiträge. Zusätzlich setzen wir Trainingstechniken wie Curriculum Learning und Model Merging ein, um die Leistungsfähigkeit zu steigern. Wir haben MemSifter an acht Benchmarks für LLM-Gedächtnisfunktionen evaluiert, einschließlich Aufgaben im Bereich Deep Research. Die Ergebnisse zeigen, dass unsere Methode sowohl in Bezug auf die Retrieval-Genauigkeit als auch auf die finale Aufgabenerfüllung die Leistung bestehender State-of-the-Art-Ansätze erreicht oder übertrifft. MemSifter bietet eine effiziente und skalierbare Lösung für das Langzeitgedächtnis von LLMs. Um weitere Forschungen zu unterstützen, haben wir die Modellgewichte, den Quellcode sowie die Trainingsdaten als Open Source veröffentlicht.
One-sentence Summary
Researchers from Renmin University of China propose MemSifter, a framework that offloads memory retrieval to a small proxy model trained via outcome-driven reinforcement learning. This approach avoids heavy indexing costs while achieving state-of-the-art accuracy in long-term LLM memory tasks.
Key Contributions
- Long-duration LLM tasks face a critical trade-off where simple storage methods lack retrieval accuracy while complex indexing incurs heavy computation and information loss.
- MemSifter addresses this by offloading retrieval to a small-scale proxy model that reasons about tasks before fetching data, optimized via a novel outcome-driven Reinforcement Learning paradigm with marginal utility and rank-sensitive rewards.
- Evaluated on eight benchmarks including Deep Research tasks, the framework matches or exceeds state-of-the-art performance in retrieval accuracy and task completion while maintaining minimal inference overhead.
Introduction
As Large Language Models tackle increasingly long-duration tasks, maintaining effective long-term memory has become a critical bottleneck where existing solutions struggle to balance retrieval accuracy with computational cost. Prior approaches either rely on simple storage that misses relevant context or employ complex indexing structures like memory graphs that demand heavy computation and risk discarding vital details. Furthermore, forcing the primary working LLM to process all historical data creates a dual burden that slows down inference and increases expenses.
The authors introduce MemSifter, a framework that offloads the memory retrieval process to a specialized, lightweight proxy model to resolve this efficiency-accuracy trade-off. This proxy acts as an intelligent gatekeeper that reasons about task requirements before retrieving information, allowing the main LLM to focus solely on generation. To optimize this proxy without expensive annotations, the team develops a task-outcome-oriented Reinforcement Learning paradigm that uses the working LLM's final success as a reward signal. This approach combines marginal utility and rank-sensitive rewards to ensure the proxy learns to prioritize critical evidence, delivering state-of-the-art performance across multiple benchmarks while significantly reducing inference overhead.
Dataset
Dataset Overview
The authors curate a comprehensive evaluation suite comprising five personal LLM benchmarks and three deep research datasets to test long-term memory and complex reasoning capabilities.
-
Dataset Composition and Sources
- Personal LLM Benchmarks: The authors utilize LoCoMo (10 multimodal dialogues with ~300 turns), LongMemEval (continuous chatbot interactions), PersonaMem (180+ curated personas), PerM-V2 (1,000 simulated user scenarios), and ZH4O (mixed-context QA integrating semantic and episodic memory).
- Deep Research Benchmarks: The suite includes HotpotQA (multi-hop reasoning), WebWalker (systematic website traversal), and WebDancer (autonomous multi-step research).
- Custom Construction: A specialized "Deep Research" benchmark is built using search trajectories and reasoning traces sampled from the MiroVerse dataset.
-
Key Details and Filtering Rules
- Evaluation Sampling: For testing, the authors randomly sample 400 questions from the test sets of LoCoMo, PersonaMem, PersonaMem-v2, and PerLTQA.
- Specific Subset Sizing: The LongMemEval test set is reduced to a random sample of 150 questions.
- Difficulty Augmentation: The custom Deep Research benchmark applies two strict modifications to the original MiroVerse data:
- Noise Injection: Approximate search results containing semantically related but factually irrelevant details are added to force logical discrimination over keyword matching.
- Context Extension: Multiple search iterations and intermediate reasoning steps are concatenated to create significantly longer context windows.
-
Usage in Model Training and Evaluation
- The datasets serve primarily as evaluation benchmarks rather than training sources in this context.
- The authors use these subsets to stress-test retrieval-augmented generation systems, specifically evaluating their ability to sift through noisy search logs and extract precise evidence from massive context windows.
- The custom Deep Research environment is designed to differentiate advanced memory methods from standard baselines by requiring precise handling of misleading information.
-
Processing and Metadata Construction
- The custom benchmark construction involves synthesizing complex reasoning chains by merging multiple browsing trajectories.
- Metadata is enhanced by embedding semantic distractors that challenge the model's ability to maintain logical consistency.
- Case studies are generated for specific reasoning trajectories across LoCoMo, LongMemEval, and WebDancer to illustrate model performance on these complex tasks.
Method
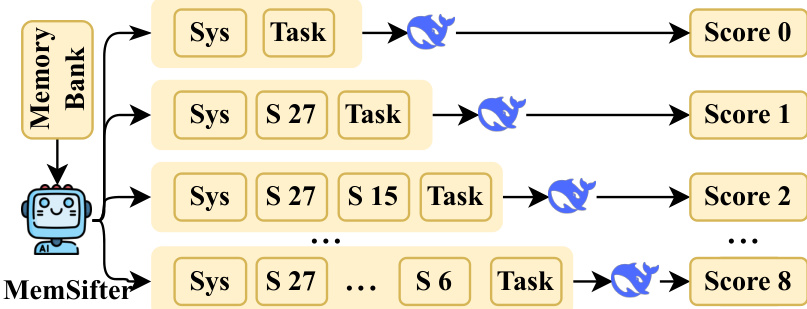
.... * Image 3 (14913bea...): Shows the reward calculation process (Marginal Utility). * MemSifter selects sessions (S 27, S 15, etc.). * Working LLM (blue whale) processes "Sys + Task" -> Score 0. * "Sys + S 27 + Task" -> Score 1. * "Sys + S 27 + S 15 + Task" -> Score 2. * This visualizes the progressive evaluation strategy described in 3.3.1.
2. Structure the Section:
- Overview: Introduce MemSifter as a memory proxy.
- Architecture/Inference: Explain the "Think-and-Rank" process (referencing Image 1 and Image 2).
- Training/Reward: Explain the Task-Outcome-Oriented Reward (referencing Image 1 and Image 3).
- Marginal Utility (Ablation).
- Rank-Sensitive (DCG-like).
- Optimization: Briefly mention the iterative training and curriculum (from text).
3. Drafting Content - Step-by-Step:
- Introduction: The authors propose MemSifter, a memory proxy designed to retrieve relevant historical sessions for a working LLM.
- Inference/Architecture:
- Refer to Image 1 (top/bottom split). The bottom part shows inference.
- Refer to Image 2 for the prompt details.
- Explain the "Think-and-Rank" mechanism. The model takes history and current task, reasons about relevance, and outputs ranked session IDs.
- Training/Reward:
- Refer to Image 1 (top part "Memory RL"). This shows the RL loop.
- Refer to Image 3 for the reward calculation visualization.
- Explain the reward function. It's not just retrieval metrics; it's task outcome.
- Explain Marginal Utility: sk−sk−1.
- Explain Rank Sensitivity: Weighting based on position (DCG).
- Optimization: Mention the iterative process and curriculum learning.
4. Refining the Text (incorporating constraints):
- Constraint Check:
- Logical and readable? Yes.
- Reference images correctly?
- Image 1: Framework diagram (Memory RL + Inference).
- Image 2: Prompt details.
- Image 3: Reward calculation (Marginal Utility).
- Image annotation format:
on a separate line. - No image numbering in text (e.g., "Figure 1"). Use "Refer to the framework diagram".
- No conclusion.
- Professional tone.
- Math format: ... and ....
- No em dashes.
5. Drafting the specific text:
- Start: The proposed framework centers on MemSifter, a specialized memory proxy that mediates between a persistent memory bank and a working LLM.
- Inference: During inference, MemSifter processes the current task query alongside the historical interaction bank. As illustrated in the lower portion of the framework diagram, the model engages in a "Think-and-Rank" process. It first generates a reasoning rationale enclosed in
<think>tags to analyze dependencies, followed by a ranked list of session identifiers within<ranking>tags. The specific prompt structure guiding this behavior is detailed in the prompt diagram, which outlines strict criteria such as topic consistency and user need continuity to ensure high-quality retrieval. - Training/Reward: The training phase employs a Reinforcement Learning (RL) approach, depicted in the upper portion of the framework diagram. Unlike standard retrieval metrics, the authors leverage a task-outcome-oriented reward signal. This mechanism evaluates the retrieved memory based on its actual impact on the working LLM's final performance.
- Reward Details: To quantify this utility, the system employs a progressive evaluation strategy visualized in the reward calculation diagram. The process begins with a baseline score s0 obtained without memory. It then incrementally adds retrieved sessions (e.g., Session 27, then Session 15) to compute scores s1,s2,…. The marginal utility of each added segment is calculated as the performance lift Δsn=skn−skn−1.
- Rank Sensitivity: To prioritize critical information, the reward function incorporates a rank-sensitive component analogous to the DCG metric. The final reward Rans is formulated as a weighted sum of accumulated scores: Rans=−s0+∑n=1Nwn⋅skn where weights wn decay logarithmically to ensure that performance gains from top-ranked memories contribute more significantly to the total reward.
- Optimization: The optimization protocol utilizes an iterative training strategy with a dynamic curriculum. To stabilize the early stages of training, a hybrid reward is used, combining the outcome-based reward with a temporary retrieval quality metric before annealing to purely outcome-oriented optimization.
6. Final Review against constraints:
- Image 1 used? Yes (framework diagram).
- Image 2 used? Yes (prompt diagram).
- Image 3 used? Yes (reward calculation diagram).
- Math correct? Yes.
- No em dashes? Checked.
- No section refs? Checked.
7. Final Polish: Ensure smooth transitions between paragraphs. Make sure the image captions are descriptive enough for the context.
- Image 1 Caption: "Overview of the Memory RL framework and MemSifter inference process."
- Image 2 Caption: "Prompt template for the memory proxy model detailing input definitions and output requirements."
- Image 3 Caption: "Visualization of the marginal utility reward calculation via progressive ablation."
Let's assemble.
Self-Correction on Image 1: The prompt asks to reference images. I need to make sure I don't number them. I will refer to them by their content description.
- Image 1: "Refer to the framework diagram"
- Image 2: "As shown in the prompt diagram"
- Image 3: "As illustrated in the reward calculation diagram"
Wait, I need to check the image paths provided in the prompt.
store/2603.03379/tex_resource/monkeyocr/images/4928b5990c954036a5532917687d42d25d2656a0d929485ab1fbf3d8832fa7af.jpg(Framework)store/2603.03379/tex_resource/monkeyocr/images/5182ab4625115af94ec63cffc278cb6c505733bf243614418a196e41cbf5315e.jpg(Prompt)store/2603.03379/tex_resource/monkeyocr/images/14913beac670fff2acddf4ded4b361b22dea4abdcee491a392c7a4efd5abd618.jpg(Reward Calc)
Okay, ready to write.
The proposed framework centers on MemSifter, a specialized memory proxy designed to mediate between a persistent memory bank and a working LLM. The system operates through a distinct inference phase and a reinforcement learning-based training loop.
During the inference phase, MemSifter processes the current task query alongside the historical interaction bank. As illustrated in the lower portion of the framework diagram, the model engages in a "Think-and-Rank" process. It first generates a reasoning rationale enclosed in <think> tags to analyze dependencies, followed by a ranked list of session identifiers within <ranking> tags. The specific prompt structure guiding this behavior is detailed in the prompt diagram, which outlines strict criteria such as topic consistency, user need continuity, and detail overlap to ensure high-quality retrieval. The retrieved sessions are then concatenated with the current task to form the context for the working agent.
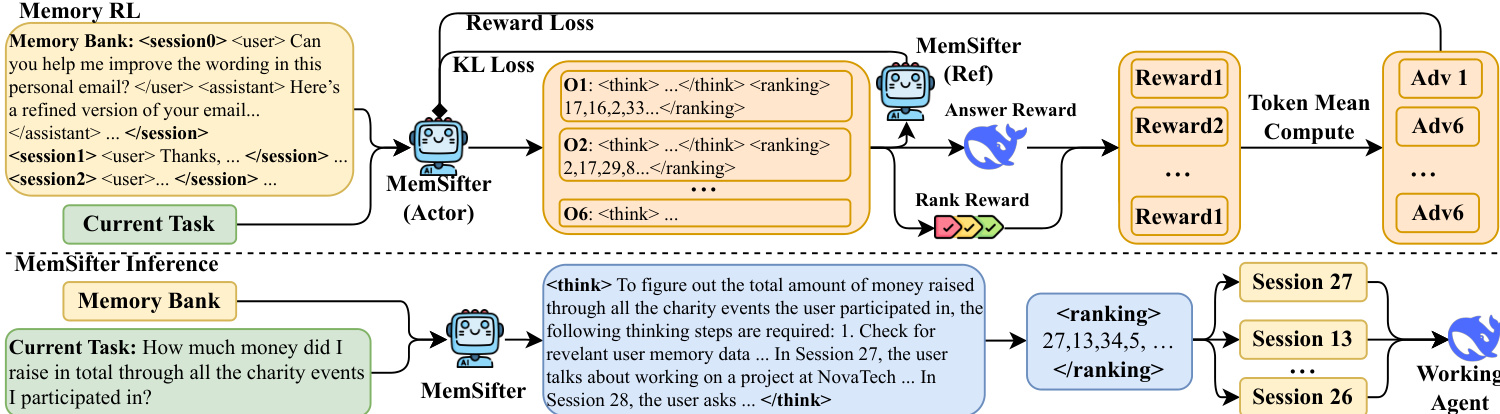

The training phase employs a Reinforcement Learning (RL) approach, depicted in the upper portion of the framework diagram. Unlike standard retrieval metrics, the authors leverage a task-outcome-oriented reward signal. This mechanism evaluates the retrieved memory based on its actual impact on the working LLM's final performance rather than intrinsic retrieval quality. To quantify this utility, the system employs a progressive evaluation strategy visualized in the reward calculation diagram. The process begins with a baseline score s0 obtained without memory. It then incrementally adds retrieved sessions (e.g., Session 27, then Session 15) to compute scores s1,s2,…. The marginal utility of each added segment is calculated as the performance lift Δsn=skn−skn−1.
To prioritize critical information, the reward function incorporates a rank-sensitive component analogous to the DCG metric. The final reward Rans is formulated as a weighted sum of accumulated scores:
Rans=−s0+∑n=1Nwn⋅skn
where weights wn decay logarithmically to ensure that performance gains from top-ranked memories contribute more significantly to the total reward. The optimization protocol utilizes an iterative training strategy with a dynamic curriculum. To stabilize the early stages of training, a hybrid reward is used, combining the outcome-based reward with a temporary retrieval quality metric before annealing to purely outcome-oriented optimization.
Experiment
- MemSifter is evaluated against diverse baselines including embedding retrieval, memory frameworks, graph-based reasoning, generative rerankers, and native long-context LLMs, demonstrating superior task success rates by filtering noise and prioritizing information with high task utility rather than just semantic similarity.
- The method proves more efficient than complex graph-based pipelines and long-context models, achieving state-of-the-art performance with a lightweight architecture that mitigates the "lost-in-the-middle" phenomenon while significantly reducing computational costs.
- Ablation studies confirm that the task-outcome reward mechanism is critical for downstream utility, as optimizing solely for static relevance fails to capture logically crucial memories, while rank-sensitive weighting and marginal utility metrics are essential for accurate credit assignment and training stability.
- Further analysis reveals that MemSifter achieves higher recall and ranking precision than reasoning-heavy baselines, converges faster through outcome-oriented rewards, and avoids performance plateaus via curriculum learning that adapts to the model's evolving capabilities.
- Case studies illustrate the model's ability to explicitly reason about task dependencies to filter distractions and pinpoint critical memory segments, validating its effectiveness in real-world scenarios.