Command Palette
Search for a command to run...
Valet: Ein standardisiertes Testumgebungssystem für traditionelle Kartenspiele mit unvollständiger Information
Valet: Ein standardisiertes Testumgebungssystem für traditionelle Kartenspiele mit unvollständiger Information
Mark Goadrich Achille Morenville Éric Piette
Zusammenfassung
Algorithmen für Spiele mit unvollständiger Information werden üblicherweise anhand von Leistungsmetriken auf einzelnen Spielen verglichen, was eine Beurteilung der Robustheit über verschiedene Spielauswahlen hinweg erschwert. Kartenspiele stellen aufgrund verdeckter Hände und stochastischer Ziehungen ein ideales Einsatzgebiet für Spiele mit unvollständiger Information dar. Um vergleichende Forschung zu Algorithmen und Systemen für den Spielbetrieb bei unvollständiger Information zu erleichtern, stellen wir „Valet" vor: ein vielfältiges und umfassendes Testbed mit 21 traditionellen Kartenspielen mit unvollständiger Information. Diese Spiele decken ein breites Spektrum an Genres, kulturellen Traditionen, Spielerzahlen, Deckstrukturen, Spielmechaniken, Siegbedingungen sowie Methoden zur Verbergung und Aufdeckung von Informationen ab. Um die Implementierungen über verschiedene Systeme hinweg zu vereinheitlichen, kodieren wir die Regeln jedes Spiels in der Kartenspiel-Beschreibungssprache RECYCLE. Mithilfe von Zufallssimulationen charakterisieren wir empirisch die Verzweigungsfaktoren und die Spieldauer jedes Spiels und berichten über Baselin-Verteilungen der Punktzahlen eines Monte-Carlo-Baum-Suchspielspielers gegen zufällige Gegner, um die Eignung von Valet als Benchmark-Suite nachzuweisen.
One-sentence Summary
Mark Goodrich (Hendrix College) and Achille Moreville & Éric Piette (UCLouvain) introduce Valet, a standardized testbed of 21 diverse traditional card games encoded in RECYCLE, enabling fair, reproducible benchmarking of AI algorithms like MCTS across varied information structures, branching factors, and cultural origins.
Key Contributions
- Valet introduces a standardized testbed of 21 traditional imperfect-information card games, encoded in the RECYCLE language to enable consistent cross-system evaluation and address the lack of shared benchmarks in AI research.
- The testbed captures diverse game mechanics, player counts, and information structures, and includes empirical characterizations of branching factor, game duration, and baseline MCTS performance against random agents to validate its suitability for algorithm comparison.
- By enabling systematic evaluation across varied game properties, Valet reduces overreliance on narrow benchmarks and supports reproducible, generalizable insights into how algorithm performance correlates with game design features.
Introduction
The authors leverage the need for standardized, diverse benchmarks in imperfect-information game AI to introduce Valet—a testbed of 21 traditional card games encoded in the RECYCLE language. Prior frameworks like RLCard, OpenSpiel, and CardStock offer card games but lack consistent implementations across systems, making cross-framework comparisons unreliable and performance claims fragile to game selection bias. Valet addresses this by providing fixed, standardized rule sets spanning multiple genres, player counts, and information mechanics, enabling fairer, reproducible evaluation of algorithms like Monte Carlo Tree Search. Its empirical characterization of branching factors and score distributions further supports systematic analysis of how game structure influences AI performance.
Dataset
-
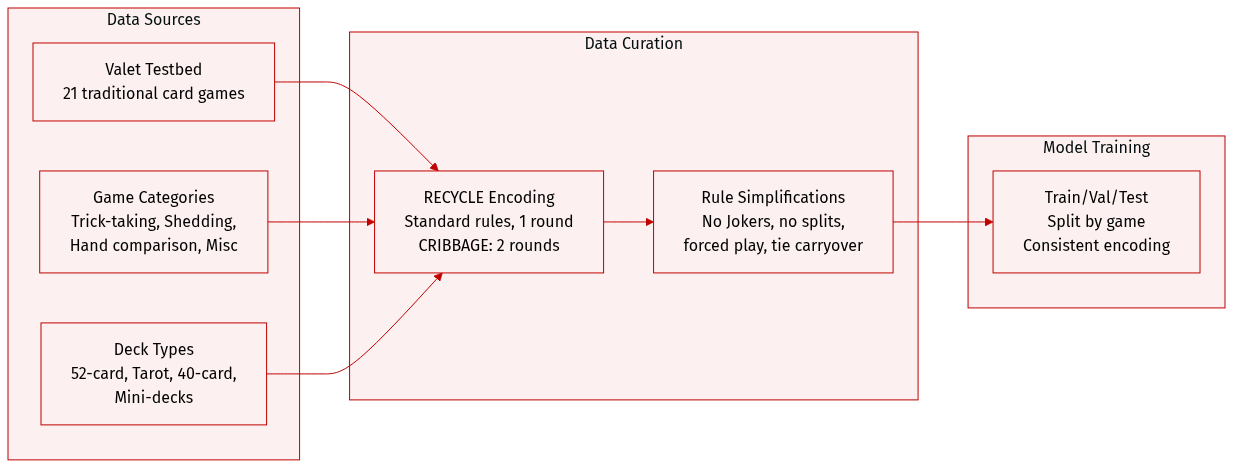
The authors use the Valet testbed, a curated collection of 21 traditional card games, selected to represent diverse genres, cultural origins, and historical development while favoring simpler rule sets. They exclude widely studied commercial or complex games like BRIDGE or TEXAS HOLD’EM in favor of foundational variants such as WHIST, KLAVERJASSEN, and LEDUC HOLD’EM.
-
The dataset spans four major game categories:
• Trick-taking (8 games): AGRAM, WHIST, EUCHRE, SUECA, HEARTS, PITCH, KLAVERJASSEN, SCARTO — varying in trump rules, scoring, and partnerships.
• Hand management/shedding (5 games): CRAZY EIGHTS, PRESIDENT, GO FISH, RUMMY, SKITGUBBE — ranging from matching to strategic planning.
• Hand comparison/exchange (4 games): BLACKJACK, LEDUC HOLD’EM, CUCKOO, SCHWIMMEN — involving betting-like decisions or hand swaps.
• Miscellaneous (4 games): GOOFSPIEL, SCOPA, GOLF-6, CRIBBAGE — introducing mechanics like simultaneous play, capture, hidden ownership, or multi-phase scoring. -
Games originate from 12 countries and use varied decks:
• Standard 52-card French deck (most common).
• 78-card Tarot deck (SCARTO).
• 40-card Spanish/Italian decks (SUECA, SCOPA).
• Reduced French-derived decks (e.g., AGRAM, EUCHRE, KLAVERJASSEN, SCHWIMMEN).
• 6-card mini-deck (LEDUC HOLD’EM). -
To ensure consistency, all games are encoded in the RECYCLE language for standardized rule implementation. Most games are limited to one round to simplify the decision space for AI; CRIBBAGE includes two rounds to balance dealer advantage. Specific rule variants are chosen for playability and clarity — e.g., American Euchre without Jokers, no card passing in HEARTS/SCARTO, simplified BLACKJACK with insurance but no splitting, Block Rummy ending when the draw deck is empty, and forced play in CRAZY EIGHTS. Ties in GOOFSPIEL carry over to the next round.
Experiment
- Experiments evaluated game diversity and decision complexity across Valet using simulations with random and MCTS agents, confirming distinct profiles in information flow, branching factor, game length, and score distribution.
- Information flow varies significantly: games differ in how public, private, and hidden information is managed, with some using multiple card backs or shared private info (e.g., crib in Cribbage), while deduction-based cues (e.g., trick-taking) remain implicit.
- Branching factor analysis reveals most games offer moderate complexity, but Go Fish, President, Skitgubbe, and Scarto show higher complexity due to game mechanics; trick-taking games share a consistent pattern with constrained later-player choices.
- Game length varies widely, with Rummy and Skitgubbe notably longer due to low-impact actions favored by random agents; most games fall between 10–100 decision points, with trick-taking games often fixed-length.
- Score distributions differ markedly: Klaaverjassen spans wide ranges, Agram and Cuckoo yield binary outcomes; MCTS outperforms random play in most games, except Cuckoo, where first-player advantage is limited, and Go Fish/Crazy Eights show minimal gain due to lack of action-history modeling.