Command Palette
Search for a command to run...
SARAH: Raumbezogene Echtzeit-Agentenmenschen
SARAH: Raumbezogene Echtzeit-Agentenmenschen
Evonne Ng Siwei Zhang Zhang Chen Michael Zollhoefer Alexander Richard
Zusammenfassung
Da embodied Agents zunehmend eine zentrale Rolle in Anwendungen rund um VR, Telepräsenz und digitale Menschen spielen, müssen ihre Bewegungen über sprachsynchrone Gesten hinausgehen: Die Agenten sollten sich den Benutzern zuwenden, auf deren Bewegungen reagieren und natürliche Blickkontakt halten. Derzeit fehlt es den bestehenden Methoden an dieser räumlichen Wahrnehmung. Wir schließen diese Lücke mit dem ersten Echtzeitverfahren, das vollständig kausal und räumlich bewusst ist, für die Nutzung in einem streamenden VR-Headset. Gegeben die Position eines Benutzers und audiovisuelle Dialogdaten (dyadisches Audio) generiert unser Ansatz vollkörperechte Bewegungen, bei denen Gesten mit der Sprache synchronisiert sind und gleichzeitig die Orientierung des Agenten an der Position des Benutzers ausgerichtet wird. Unser Architekturkonzept kombiniert einen kausalen Transformer-basierten VAE mit abwechselnden latenten Tokens zur Echtzeitinferenz und ein Flow-Matching-Modell, das auf der Benutzertrajektorie und dem Audio bedingt ist. Um unterschiedliche Präferenzen hinsichtlich des Blickkontakts zu unterstützen, führen wir eine Blickbewertungsmechanik mit classifier-free Guidance ein, die Lernen und Steuerung voneinander entkoppelt: Das Modell erlernt aus den Daten natürliche räumliche Ausrichtung, während die Intensität des Blickkontakts zur Laufzeit vom Benutzer angepasst werden kann. Auf dem Embody 3D-Datensatz erreicht unser Verfahren Spitzenleistung in der Bewegungsqualität bei über 300 FPS – dreimal schneller als nicht-kausale Baselines – und erfasst dabei die feinen räumlichen Dynamiken natürlicher Gespräche. Wir validieren unseren Ansatz in einer Live-VR-Systemumgebung und bringen räumlich bewusste, dialogorientierte Agenten so erstmals in die Echtzeit-Implementierung. Weitere Details finden Sie unter https://evonneng.github.io/sarah/.
One-sentence Summary
Meta Reality Labs researchers propose a real-time, causal method for spatially aware conversational motion using a transformer VAE and flow matching, enabling VR agents to dynamically align gestures and gaze with users via audio and position—achieving 300+ FPS and natural interaction in live deployment.
Key Contributions
- We introduce the first real-time, fully causal method for generating spatially aware conversational motion in virtual agents, enabling them to dynamically orient toward users and align gestures with speech using only past and present user position and dyadic audio.
- Our architecture combines a causal transformer-based VAE with interleaved latent tokens for streaming inference and a flow matching model conditioned on user trajectory and audio, plus a classifier-free gaze guidance mechanism that decouples learned spatial behavior from user-adjustable eye contact intensity.
- Evaluated on the Embody 3D dataset, our method achieves state-of-the-art motion quality at over 300 FPS—three times faster than non-causal baselines—and successfully deploys on a live VR system, demonstrating real-time spatial reactivity without future frame access.
Introduction
The authors leverage real-time, causal generative modeling to enable virtual agents in VR and telepresence systems to dynamically orient toward users during conversation—turning, gazing, and gesturing naturally in response to both speech and spatial movement. Prior methods either ignore spatial context, assume static participants, or rely on non-causal models that can’t stream in real time, limiting their use in interactive systems. Their main contribution is SARAH: a streaming architecture combining a causal transformer-based VAE with interleaved latent tokens and a flow matching model conditioned on user trajectory and dyadic audio, plus a classifier-free gaze guidance mechanism that lets users adjust eye contact intensity at inference—achieving state-of-the-art motion quality at over 300 FPS.
Dataset
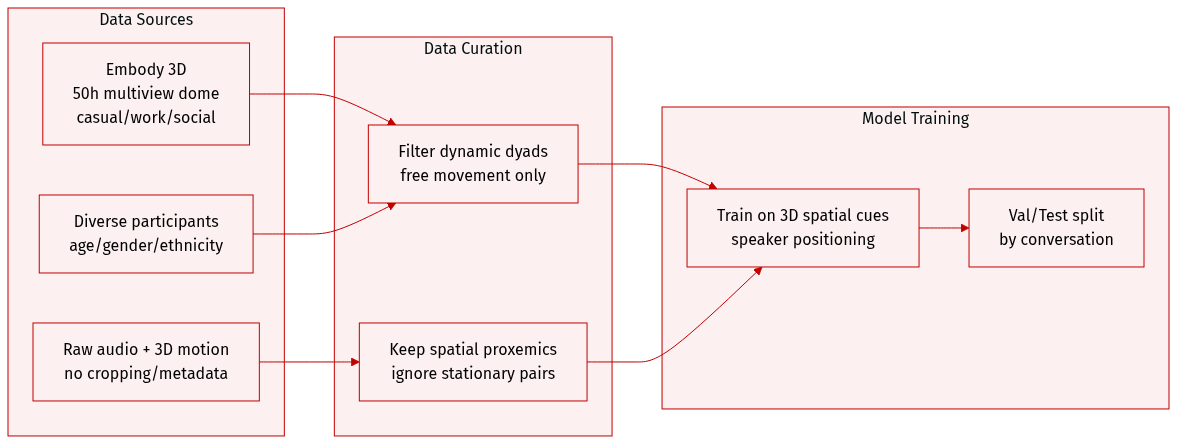
- The authors use the dyadic conversation subset from the Embody 3D dataset [McLean et al. 2025], which contains approximately 50 hours of multiview dome-captured interactions covering casual, work, and social conversations.
- Participants represent diverse age groups, genders, and ethnicities, and the dataset includes both audio and 3D motion annotations.
- Unlike prior monadic datasets (e.g., Speech2Gesture, BEAT) that capture single speakers without spatial context, or dyadic datasets (e.g., Audio2Photoreal, Panoptic Studio) where participants remain stationary and face each other, Embody 3D records natural, dynamic interactions where individuals walk freely and shift positions.
- The dataset is used to train models on 3D spatial proxemics in conversation, leveraging its unique capture of movement and spatial relationships between speakers.
- No cropping or metadata construction details are specified; processing focuses on utilizing raw audio and 3D motion annotations directly from the source.
Method
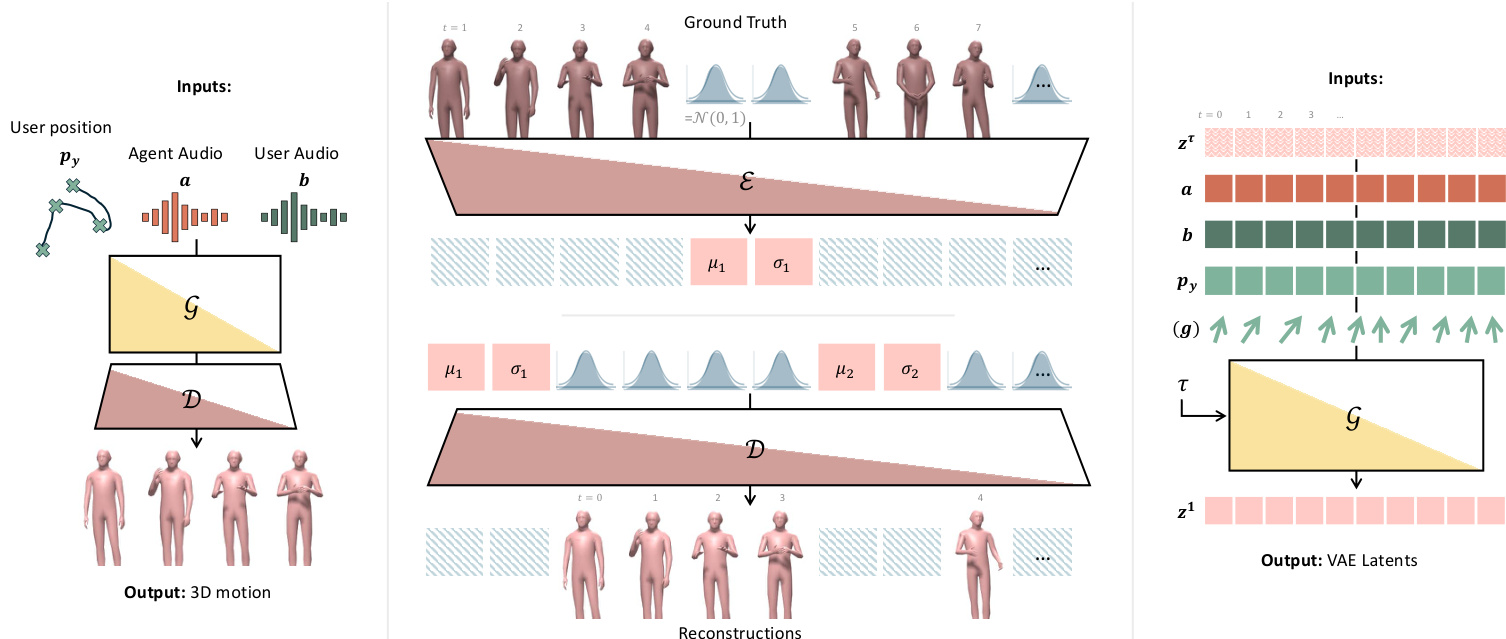
The authors leverage a real-time, autoregressive motion synthesis pipeline that conditions on dyadic conversational audio and user spatial position to generate spatially and conversationally aware 3D motion for an AI agent. The system is built around a causal transformer-based variational autoencoder (VAE) and a flow matching generator, both designed for streaming inference with strict temporal causality.
The overall framework begins with input conditioning: the user’s floor-projected head position py∈RT×2, and audio features a,b∈RT×Da extracted via HuBERT from agent and user speech streams. These are fed into a generative model G that outputs the agent’s motion sequence x∈RT×Dx. Refer to the framework diagram for a visual overview of the end-to-end pipeline, including the VAE encoder-decoder structure and the flow matching generator.
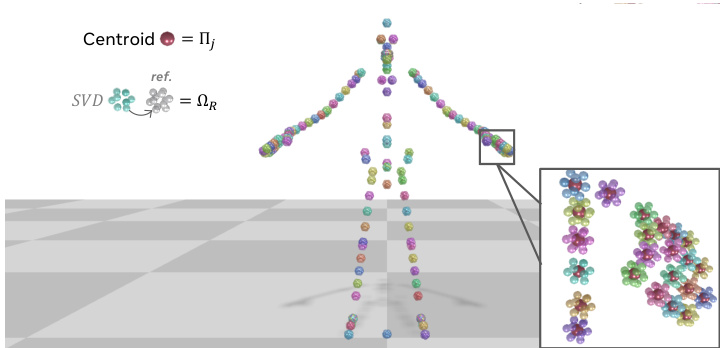
To enable efficient and stable training, the authors adopt a fully Euclidean motion representation. Instead of traditional joint-angle parameterizations, each joint j is encoded as a 3D icosahedron: the centroid of its 12 vertices yields the global position Πj, and the global orientation Ωj is recovered via SVD against a reference icosahedron. This representation avoids error propagation from local rotations and improves convergence. The full pose is thus encoded as xt∈RJ×12×3, where J is the number of joints, and is normalized relative to the first frame to prevent drift. As shown in the figure, this geometric encoding provides a robust and differentiable motion representation.
The core of the architecture is a causal transformer-based VAE. Unlike standard VAEs that place global latents at the sequence start, this model interleaves latent tokens μk,σk∈RDz at a fixed temporal stride s, enabling causal attention. The encoder E processes input in blocks: (x1:S,μ1,σ1,xs+1:2S,μ2,σ2,…), where each μk/σk token attends only to preceding frames and earlier latents. The decoder D mirrors this pattern. The model is trained with a VAE loss combining reconstruction and KL divergence:
LVAE=∥x−x^∥22+βk=1∑KKL(qϕ(zk∣x1:kS)∥N(0,I)),where K=T/s, x^ is the reconstruction, and zk∼N(μk,σk2) is the sampled latent for block k. After training, the encoder is used to extract the latent sequence z=(z1,…,zK)∈RK×Dz for generation.
The motion generator is a transformer-based flow matching model that operates on the latent space. It transports noise ϵ∼N(0,I) to data by predicting a velocity field vθ(zτ,τ,c), where τ∈[0,1] is flow time and c=[py;a;b] is the conditioning. The interpolated latent is formed as:
zτ=τz+(1−τ)ϵ,ϵ∼N(0,I).Training uses x1-prediction with loss:
Lflow=Eτ,ϵ,z[∥G(zτ,τ,c)−z∥22],where τ∼U[0,1]. Classifier-free guidance is applied by dropping each modality independently with 5% probability. For real-time streaming, causal attention masking is enforced, and temporal consistency is maintained via imputation: at each step, previously predicted latents are imputed into the noisy sequence before denoising proceeds.
To enable controllable gaze behavior, the authors introduce a tunable gaze guidance mechanism. The gaze score g is computed as the dot product between the agent’s facing direction dx and the direction toward the user dy:
dx=∥hf−hb∥hf−hb,dy=∥pu−hb∥py−hb,g=dx⋅du.This score ranges from -1 (facing away) to 1 (direct eye contact). During training, g∈RT×1 is concatenated with conditioning c, and classifier-free guidance drops g with 5% probability. At inference, a target gaze score can be specified to steer eye contact intensity while preserving natural variation. As illustrated in the figure, this allows fine-grained control over non-verbal engagement cues.
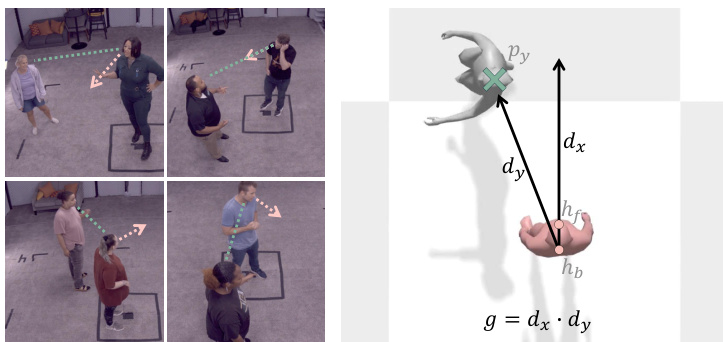
For deployment, motion is generated in chunks of s=4 frames, with the last 2 tokens retained for temporal continuity. The system uses a midpoint solver with 4 iterations per chunk, achieving 60 fps for real-time streaming. Photorealistic rendering is handled via a separate learning-based method that synthesizes geometry and texture from joint parameters and facial expressions derived from speech.
Experiment
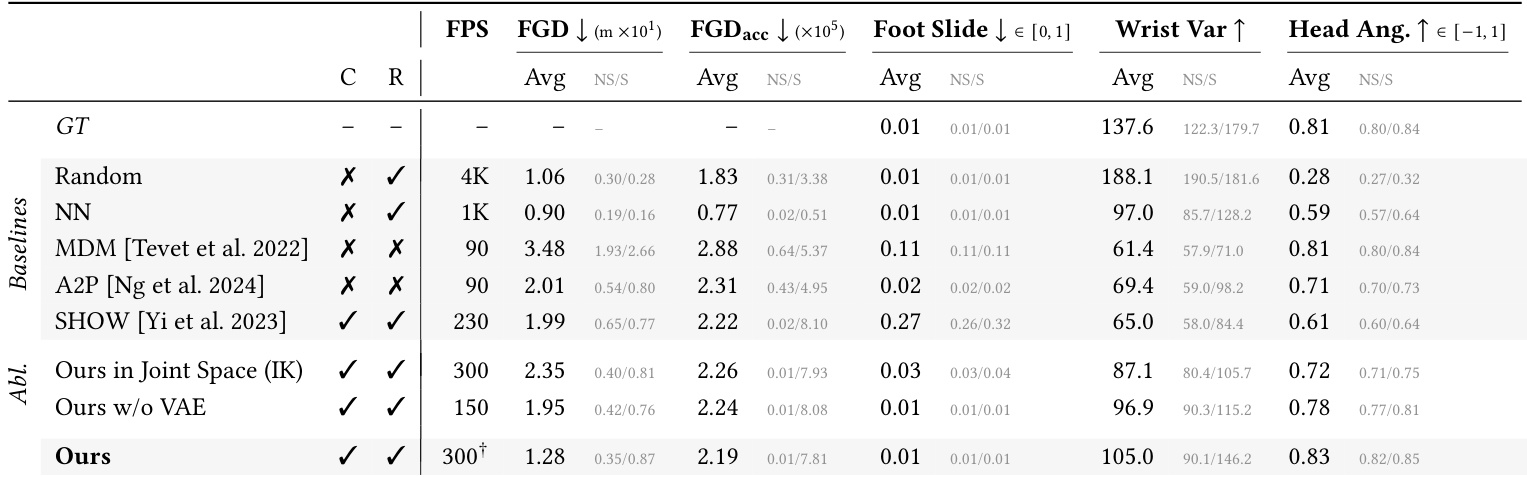
- The model generates spatially-aware conversational motion that is competitive with state-of-the-art methods, including non-causal and non-real-time approaches, while maintaining real-time, causal inference.
- It excels in gaze alignment, significantly outperforming retrieval and generative baselines by orienting the agent toward the user in natural conversational contexts.
- Unlike retrieval methods, it generates novel motion that jointly optimizes realism, expressiveness, and spatial awareness, rather than being limited to dataset examples.
- Compared to diffusion-based baselines (MDM, A2P), it achieves better motion dynamics, lower foot sliding, and higher expressiveness, while running faster and without requiring future context.
- Against audio-only models (SHOW), it demonstrates superior full-body coordination and spatial awareness by explicitly conditioning on user position.
- Ablation studies confirm the value of the Euclidean motion representation (vs. joint angles) for precise positioning and the VAE’s role in capturing motion distribution without compromising physical plausibility.
- Gaze direction is controllable at inference time via classifier-free guidance, enabling adjustable social engagement—from avoiding eye contact to fully facing the user—while preserving motion quality.
- Qualitative video results show natural transitions between speaking/listening modes, context-appropriate emotional gestures, and seamless integration with real-time VR applications using off-the-shelf LLMs and TTS.
The authors demonstrate that their model generates spatially aware conversational motion in real time while maintaining competitive realism and expressiveness compared to non-causal, non-real-time baselines. Results show that explicit gaze control during inference allows flexible adjustment of agent orientation toward the user, with moderate guidance improving both alignment and motion quality, while strict alignment introduces a trade-off with natural variation. Ablations confirm that their Euclidean motion representation and causal VAE are critical for achieving high fidelity and physical plausibility without compromising speed.
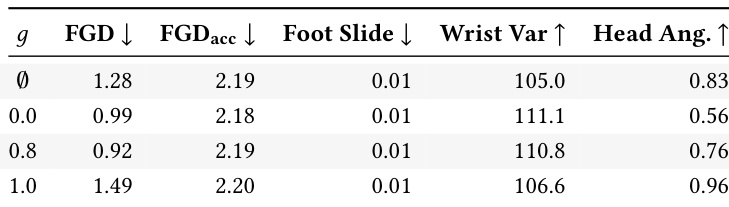
The authors use a causal, real-time model to generate spatially aware conversational motion, achieving competitive realism and diversity while explicitly aligning the agent’s gaze toward the user. Results show their method outperforms non-causal baselines in gaze alignment and physical plausibility, and surpasses retrieval methods by generating novel motion that jointly satisfies multiple criteria rather than merely sampling from existing data. Ablations confirm that their Euclidean motion representation and latent compression via VAE are critical for maintaining both spatial accuracy and expressive dynamics.