Command Palette
Search for a command to run...
Selektives Training großer visueller Sprachmodelle mittels visueller Informationsgewinn
Selektives Training großer visueller Sprachmodelle mittels visueller Informationsgewinn
Seulbi Lee Sangheum Hwang
Zusammenfassung
Große visuelle Sprachmodelle (LVLMs) haben beachtliche Fortschritte erzielt, leiden jedoch häufig unter sprachlicher Bias, indem sie Antworten generieren, die nicht auf visuellen Hinweisen beruhen. Während vorangegangene Arbeiten versuchen, dieses Problem durch Dekodierstrategien, architektonische Modifikationen oder sorgfältig kuratierte Anweisungsdaten zu mildern, fehlt ihnen typischerweise eine quantitative Messgröße dafür, wie stark einzelne Trainingsbeispiele oder Tokens tatsächlich von der Bildinformation profitieren. In dieser Arbeit führen wir Visual Information Gain (VIG) ein, eine auf der Perplexität basierende Metrik, die die Reduktion der Vorhersageunsicherheit durch visuelle Eingaben misst. VIG ermöglicht eine fein granulare Analyse auf Ebene von Beispielen und Tokens und hebt visuell fundierte Elemente wie Farben, räumliche Beziehungen und Attribute effektiv hervor. Ausgehend davon schlagen wir ein VIG-gesteuertes selektives Trainingsverfahren vor, das Beispiele und Tokens mit hohem VIG-Vorteil priorisiert. Dieser Ansatz verbessert die visuelle Grundierung und verringert die sprachliche Bias, erreicht dabei eine überlegene Leistung und reduziert den Supervisionsaufwand signifikant, indem ausschließlich visuell informative Beispiele und Tokens berücksichtigt werden.
One-sentence Summary
Seulbi Lee and Sangheum Hwang of Seoul National University of Science and Technology propose Visual Information Gain (VIG), a perplexity-based metric that quantifies image contribution per token, enabling selective training to reduce language bias and enhance visual grounding in LVLMs with less supervision.
Key Contributions
- We introduce Visual Information Gain (VIG), a perplexity-based metric that quantifies how much visual input reduces prediction uncertainty, enabling fine-grained analysis of visual dependency at both sample and token levels across multimodal datasets.
- VIG reliably identifies visually grounded elements such as colors, spatial relations, and attributes, distinguishing them from tokens driven by textual priors, and aligns with benchmark-level modality dependencies to validate its effectiveness as a grounding indicator.
- Leveraging VIG, we design a selective training scheme that prioritizes high-VIG samples and tokens, improving visual grounding and reducing language bias while achieving superior performance with significantly less supervision compared to full-data training.
Introduction
The authors leverage a new metric called Visual Information Gain (VIG) to quantify how much visual input reduces prediction uncertainty in Large Vision Language Models (LVLMs), addressing the persistent problem of language bias—where models ignore images and rely on textual priors. Prior work mitigates this through architectural tweaks or decoding tricks, but none measure visual dependency at the sample or token level, leaving models prone to hallucinations and weak grounding. Their main contribution is VIG-guided selective training, which prioritizes visually informative samples and tokens, improving grounding and reducing supervision needs while maintaining performance—offering a data-centric, model-agnostic solution that complements existing methods.

Dataset
The authors use a curated mix of benchmarks and instruction-tuning datasets to evaluate and train their model. Here’s how the data is structured and applied:
-
Evaluation Benchmarks (Visual Understanding):
- LLaVA-W (LLaVA-Bench In-the-Wild): 24 images, 60 questions covering diverse visuals like memes, paintings, and sketches. Evaluated via GPT-4 (gpt-4o-2024-11-20).
- MMVet: 200 images, 218 questions with ground-truth references. Assesses conversational reasoning using GPT-4 (gpt-4-0613) for precision and utility scoring.
- MMBench (English subset): ~3,000 multiple-choice questions spanning 20 skills. Uses GPT-3.5 (gpt-3.5-turbo-0613) to extract answer choices (A–D). Reported on dev split.
- DocVQA: Focuses on document image understanding (forms, invoices, reports). Evaluated on official validation split; accuracy is reported.
-
Hallucination Evaluation Benchmarks:
- POPE: Built from MSCOCO, A-OKVQA, and GQA. 27,000 QA pairs from 500 images each. Tests object hallucination with 50:50 existent/non-existent object queries. Uses three negative sampling strategies (random, popular, adversarial); six questions per image. Metrics: Accuracy and F1 averaged across strategies.
- CHAIR: Measures caption hallucination via two metrics: CHAIR_I (instance-level hallucination ratio) and CHAIR_S (sentence-level hallucination rate). Formulae provided for both.
- MMHal: 96 challenging queries from OpenImages. Graded by GPT-4 (gpt-4-0613) on 0–5 scale. Reports average score and hallucination rate (score <3 = hallucinated).
-
Instruction-Tuning Data:
- For LLaVA-1.5 family: Uses instruction dataset from Liu et al. [2].
- For ShareGPT4V variant: Replaces “detailed description” samples in LLaVA with high-quality captions from ShareGPT4V [7].
- Selection thresholds τ_p (at p=70) are determined per model and listed in Table C.1.
No cropping or metadata construction is mentioned. The datasets are used as-is for evaluation, while instruction-tuning data is modified per protocol for training.
Method
The authors leverage a standard large vision-language model (LVLM) architecture comprising three core components: a pre-trained vision encoder Ev, an adapter P, and a pre-trained language model D. Training proceeds in two stages: pre-training and instruction tuning. In the pre-training phase, the adapter P is optimized on large-scale image-caption pairs formatted as single-turn instructions. For each image I and its caption, a simple question Q (e.g., “Describe this image”) is sampled, and the caption serves as the target answer A. This stage aligns the visual feature space with the language model’s semantic space while keeping Ev and D frozen. The visual feature and its projected embedding are computed as fv=Ev(I) and zv=P(fv), respectively. The model’s predictive distribution over answer tokens is denoted qθ(⋅∣a<t,Q,zv), parameterized by θ. The per-sample instruction tuning objective is defined as:
L(A∣Q,I;θ)=−T1t=1∑Tlogqθ(at∣a<t,Q,zv)where at is the t-th token in answer A and T is the sequence length. For notational convenience, the authors denote qQ(⋅)=qθ(⋅∣Q) and qI,Q(⋅)=qθ(⋅∣I,Q), representing predictions without and with visual input, respectively.
To quantify the contribution of visual information at the sample level, the authors introduce Visual Information Gain (VIG), defined as the log-ratio of perplexities (PPL) with and without visual conditioning:
VIG=log(PPL(A∣Q,I)PPL(A∣Q))PPL(A∣Q) is computed using a blurred image to simulate the absence of visual cues, following prior work. A higher VIG indicates greater reduction in model uncertainty when visual input is provided. Reformulating VIG in terms of cross-entropy loss yields:
VIG=L(A∣Q)−L(A∣Q,I).Under deterministic supervision (as in VQA and captioning datasets), where the target distribution p is a Dirac delta, VIG simplifies to the absolute difference in KL divergences:
VIG=DKL(pA∣Q∥qQ)−DKL(pA∣I,Q∥qI,Q).This formulation shows that VIG empirically measures how much visual information reduces the divergence between the model’s predictions and the ground truth. Expanding further, VIG decomposes into token-level contributions:
VIG=T1t=1∑T[−logqθ(at∣a<t,Q)]−[−logqθ(at∣a<t,Q,zv)]Each term represents the token-wise cross-entropy loss with and without visual conditioning, revealing that VIG aggregates per-token visual gains. This decomposition enables fine-grained analysis of which response tokens are most dependent on visual input.
To demonstrate VIG’s practical utility, the authors implement VIG-guided selective training. For each training sample (Ii,Qi,Ai), they compute sample-level VIG VIGi and token-level VIG VIGi,t, where:
VIGi=Ti1t=1∑TiVIGi,t.They rank samples by VIGi and select the top p%, defining the selected set Sp={i∣VIGi≥τp}, where τp is the threshold. Within this subset, they further select tokens using the same threshold: for each i∈Sp, the visually informative tokens are Ti+={t∣VIGi,t≥τp}. During instruction tuning, the loss is computed only over tokens in ⋃i∈SpTi+, ensuring gradients are updated exclusively on the most visually informative regions. This dual-level selection—sample and token—focuses optimization on data with substantial visual grounding, enhancing visual reasoning efficiency.
Experiment
- VIG effectively measures visual grounding at sample and token levels, aligning with benchmark characteristics: COCO and POPE show strong visual dependency, while GQA and SQA lean toward text reliance.
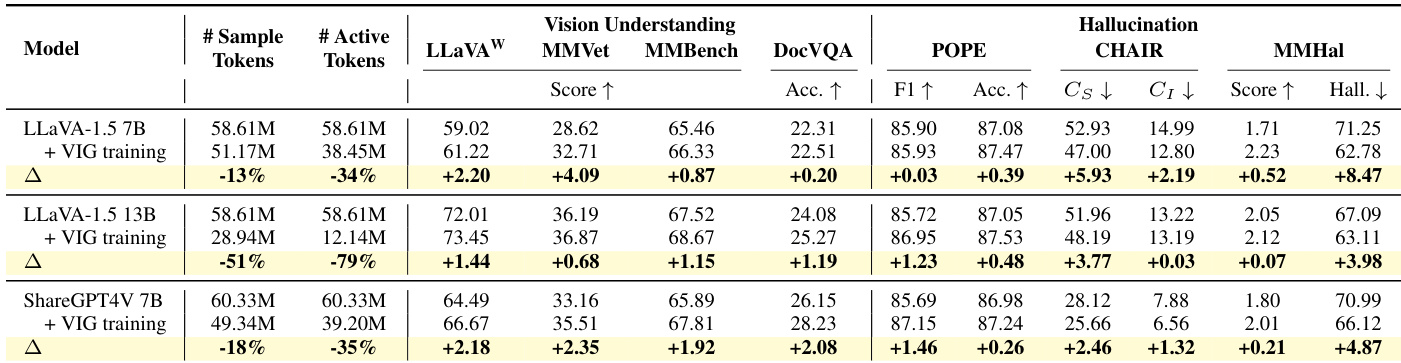
- VIG-guided selective training improves performance across vision understanding and hallucination benchmarks while reducing training data by up to 70%, with token-level filtering proving critical for gains.
- Larger models benefit more from VIG selection, achieving higher performance with fewer tokens, demonstrating improved data efficiency.
- VIG training enhances visual attention across model layers and reduces “blind faith in text,” making models more robust to misleading textual cues.
- VIG outperforms or matches existing visual grounding methods without architectural changes and combines well with them for additive gains.
- Ablation studies confirm that VIG-based selection (sample + token level) consistently outperforms random or sample-only selection, with p=70 offering the best balance of efficiency and performance.
- Qualitative results show VIG training suppresses object and attribute hallucinations, forcing models to ground responses in actual visual content rather than textual priors.
The authors use VIG-guided selective training to filter both samples and tokens based on visual information gain, achieving improved performance across vision understanding and hallucination benchmarks while reducing training data volume. Results show that models trained with this method allocate more attention to visual tokens and resist misleading textual cues, indicating stronger visual grounding. The approach consistently outperforms random data reduction and complements existing visual grounding methods without architectural changes.

The authors use VIG-guided selective training to filter both samples and tokens based on visual information gain, achieving improved performance with significantly fewer training tokens. Results show that models trained under this strategy exhibit stronger visual grounding, reduced hallucinations, and greater resistance to misleading text, even when using only 70% of the original data. The method consistently outperforms random data reduction and complements existing visual grounding techniques without requiring architectural changes.

The authors use VIG-guided selective training to prioritize visually grounded samples and tokens during instruction tuning, resulting in improved performance across vision understanding and hallucination benchmarks while reducing the number of active tokens by 34% to 79%. Results show that this data-centric approach enhances visual grounding without architectural changes, outperforming both random data reduction and existing training-free or training-based methods. The gains are consistent across model sizes and architectures, indicating that focusing supervision on visually informative content strengthens multimodal alignment and reduces reliance on spurious textual cues.
The authors use identical training configurations for both pretraining and instruction tuning stages across models, maintaining consistent hyperparameters such as learning rate, optimizer, and scheduler to ensure fair comparison. Results show that instruction tuning requires less training time than pretraining, despite using a smaller batch size, indicating computational efficiency in the fine-tuning phase.

The authors use VIG-guided selective training to prioritize visually informative samples and tokens, achieving stronger performance across vision understanding and hallucination benchmarks while using significantly fewer training tokens. Results show that even aggressive filtering (30% selection) maintains or improves performance on open-ended and hallucination tasks, though broader coverage tasks benefit from moderate filtering (70%). This approach consistently reduces reliance on spurious textual cues and enhances visual grounding without architectural changes.
