Command Palette
Search for a command to run...
DeepVision-103K: Ein visuell vielfältiges, umfassend abgedecktes und überprüfbares mathematisches Datensatz für multimodales Schlussfolgern
DeepVision-103K: Ein visuell vielfältiges, umfassend abgedecktes und überprüfbares mathematisches Datensatz für multimodales Schlussfolgern
Haoxiang Sun Lizhen Xu Bing Zhao Wotao Yin Wei Wang Boyu Yang Rui Wang Hu Wei
Zusammenfassung
Reinforcement Learning mit verifizierbaren Belohnungen (RLVR) hat sich als wirksam erwiesen, um die visuelle Reflexions- und Schlussfolgerungsfähigkeit großer multimodaler Modelle (LMMs) zu verbessern. Allerdings stammen bestehende Datensätze überwiegend aus entweder kleinskaliger manueller Erstellung oder der Rekombination vorheriger Ressourcen, was die Datenvielfalt und -abdeckung einschränkt und somit die weiteren Leistungssteigerungen der Modelle behindert. Um diesem Problem entgegenzuwirken, stellen wir \textbf{DeepVision-103K} vor – einen umfassenden Datensatz für die RLVR-Trainingsausbildung, der eine Vielzahl von K12-mathematischen Themen, umfangreiche Wissenspunkte und reichhaltige visuelle Elemente abdeckt. Modelle, die auf DeepVision trainiert wurden, erzielen starke Ergebnisse auf multimodalen mathematischen Benchmark-Aufgaben und generalisieren effektiv auf allgemeine multimodale Schlussfolgerungsaufgaben. Eine weitere Analyse zeigt eine verbesserte visuelle Wahrnehmung, Reflexions- und Schlussfolgerungsfähigkeit der trainierten Modelle, was die Wirksamkeit von DeepVision zur Förderung multimodaler Schlussfolgerung bestätigt. Daten: \href{https://huggingface.co/datasets/skylenage/DeepVision-103K}{dieser Link}.
One-sentence Summary
Researchers from Alibaba Group and Shanghai Jiao Tong University introduce DeepVision-103K, a large-scale dataset for RLVR training that enhances multimodal models’ visual reasoning across K12 math and general tasks, overcoming prior data limitations through diverse, structured visual-mathematical content.
Key Contributions
- DeepVision-103K addresses the limited diversity of existing RLVR datasets by providing a large-scale, K12-focused resource with rich visual elements and broad mathematical coverage, enabling more effective training of multimodal reasoning models.
- Models trained on DeepVision-103K using GSPO with correctness-based rewards show consistent gains across multimodal math benchmarks (e.g., 85.11% on WeMath) and generalize to general multimodal tasks, outperforming both official thinking variants and models trained on prior open-source datasets.
- Human analysis confirms three key enhancements: improved one-shot visual perception, active visual reflection to correct errors, and more rigorous mathematical reasoning—validating that DeepVision’s structured visual logic tasks and verifiable rewards drive measurable capability improvements.
Introduction
The authors leverage Reinforcement Learning with Verifiable Rewards (RLVR) to improve visual reflection and reasoning in Large Multimodal Models (LMMs), a critical capability for solving complex, real-world tasks that blend text and imagery. Prior datasets for RLVR are limited by small scale and low diversity, often built from recycled or manually curated sources, which restricts model generalization and performance gains. Their main contribution is DeepVision-103K, a large-scale, diverse dataset covering K12 math topics with rich visual elements and logic-based tasks, which enables models to achieve strong results on multimodal math benchmarks and generalize to broader reasoning tasks while enhancing core visual perception and reasoning skills.
Dataset

The authors use DeepVision-103K—a large-scale, verifiable multimodal math dataset—to train models for reinforcement learning from verifiable rewards (RLVR). Here’s how it’s composed, processed, and applied:
-
Dataset Composition and Sources
Built from 3.3M real-world K12 math problems sourced from MM-MathInstruct-3M and MultiMath-300K. The final dataset contains 77K high-quality, verifiable QA pairs after a three-stage curation pipeline. -
Key Subset Details
- Math Subset: 77K samples filtered for unique answers, visual necessity, and moderate difficulty (pass rate between 1/8 and 7/8).
- Visual Logic Subset: 26K samples from Zebra-CoT and GameQA, covering mazes, chess, and Tetris; filtered using the same pass-rate criteria.
- Visual Categories: Covers 6 major types—geometry, analytic plots, charts, real-world items, and more—with over 400 distinct knowledge points and 200+ fine-grained topics.
- Filtering Rules:
- Stage 1: Remove proof/explanation tasks and multi-answer questions; retain only visually necessary, single-answer items.
- Stage 2: Use MiMo-VL-7B-SFT rollouts + MathVerify to keep samples with pass rates in [1/8, 7/8]; under-represented difficulty ranges are selectively sampled.
- Stage 3: Use Gemini-3-Flash to validate input completeness, image-text alignment, and answer correctness—discard any flagged as erroneous.
-
Usage in Training
- Models are trained using the 77K QA pairs as the primary RLVR signal.
- The math and visual logic subsets are mixed during training to jointly enhance mathematical and visual reasoning.
- No cropping is applied; images are used as-is. Metadata includes visual element types (annotated via GPT-5 mini) and hierarchical topic labels.
-
Processing and Metadata
- Visual elements are categorized using a taxonomy based on prior work (Mo et al., 2018; Rosin, 2008).
- Each sample includes image, question, and answer—structured for multimodal QA and step-by-step reasoning.
- All data is filtered for safety and verifiability; no personal identifiers or corrupted content is retained.
Experiment
- Training on DeepVision consistently improves multimodal mathematical reasoning across benchmarks, outperforming both official thinking variants and closed-source models on key tasks like WeMath and LogicVista.
- DeepVision models generalize effectively to general multimodal tasks, surpassing foundation models and thinking variants, indicating broad reasoning enhancement beyond math.
- RL training on DeepVision enhances three core capabilities: visual perception (accurate one-shot identification), visual reflection (active re-examination of errors), and mathematical reasoning (more rigorous logical chains).
- Ablation studies confirm that combining multimodal math with visual logic data yields superior performance compared to math-only training, as visual logic strengthens spatial reasoning and pattern recognition applicable across domains.
- Query correctness verification is essential—unverified training data leads to significantly lower performance, underscoring the need for accurate reward signals in RL training.
- Training dynamics show increasing response length, rising rewards, and stable entropy, reflecting progressive model improvement during RL fine-tuning.
Training on DeepVision consistently improves both mathematical and general multimodal reasoning across multiple benchmarks, outperforming baseline models and rivaling or exceeding closed-source and official thinking variants. The gains stem from enhanced visual perception, reflection, and mathematical reasoning, with ablation studies confirming that combining multimodal math and visual logic data yields better results than either domain alone. Verification of query correctness during training is also shown to be essential for achieving optimal performance.
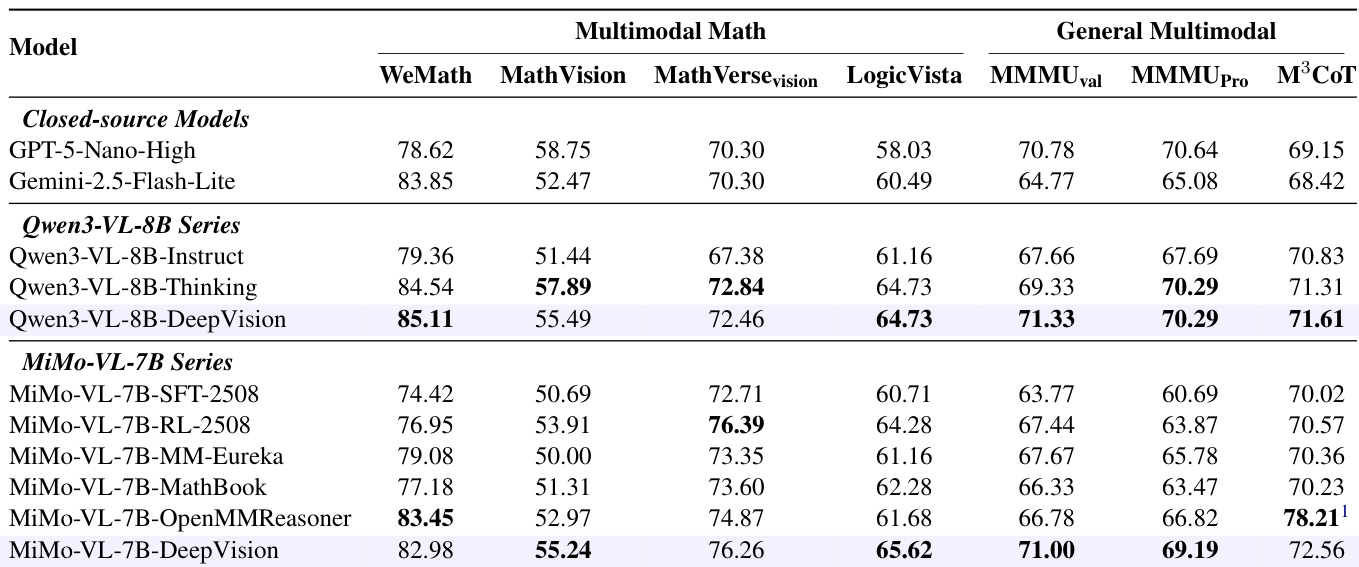
The authors use GSPO for RL training with rule-based rewards and evaluate models on multimodal math and general reasoning benchmarks. Results show that training on DeepVision consistently improves performance over base and thinking variants, with gains attributed to enhanced visual perception, reflection, and mathematical reasoning. The inclusion of visual logic data and verified query correctness further boosts generalization and model reliability.
The authors use retrieval-augmented training to enhance model performance across geometric knowledge domains, observing consistent gains when retrieval is enabled. Results show that incorporating external knowledge significantly boosts accuracy, particularly in complex transitions like circle to inscribed/circumscribed relationships. The magnitude of improvement varies by domain, indicating that retrieval is most impactful where conceptual bridging is required.
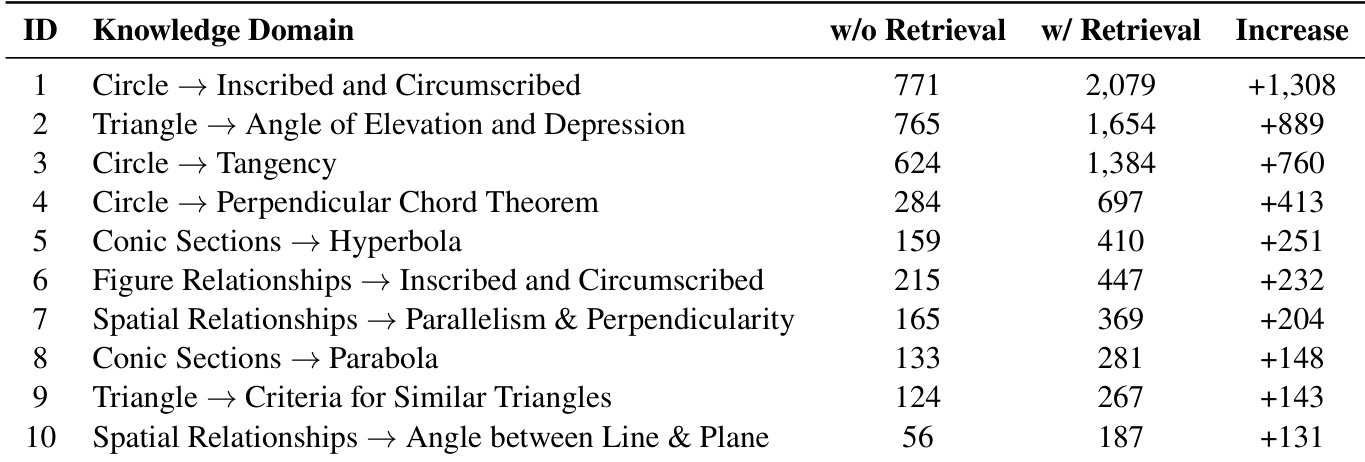
Training on DeepVision data consistently improves both mathematical and general multimodal reasoning across multiple benchmarks, outperforming models trained on math-only or unverified data. The inclusion of visual logic data enhances spatial reasoning and pattern recognition, which transfer positively to both math and general tasks, while verified correct answers are essential for effective reward signals in reinforcement learning. Models fine-tuned with DeepVision show stronger visual perception, reflection, and mathematical reasoning compared to their base counterparts.