Command Palette
Search for a command to run...
Wie viel Reasoning fügen Retrieval-Augmented-Modelle über LLMs hinaus hinzu? Ein Benchmarking-Framework für Multi-Hop-Inferenz über hybride Wissensbasen
Wie viel Reasoning fügen Retrieval-Augmented-Modelle über LLMs hinaus hinzu? Ein Benchmarking-Framework für Multi-Hop-Inferenz über hybride Wissensbasen
Junhong Lin Bing Zhang Song Wang Ziyan Liu Dan Gutfreund Julian Shun Yada Zhu
Zusammenfassung
Große Sprachmodelle (LLMs) stoßen weiterhin auf Schwierigkeiten bei wissensintensiven Fragen, die aktuelle Informationen und mehrschrittige Schlussfolgerungen erfordern. Die Erweiterung von LLMs durch hybride externe Wissensquellen – wie unstrukturierte Texte und strukturierte Wissensgraphen – bietet eine vielversprechende Alternative zu kostspieligen kontinuierlichen Vortrainings. Daher wird eine zuverlässige Bewertung ihrer Retrieval- und Schlussfolgerungsfähigkeiten zunehmend kritisch. Allerdings überlappen sich viele bestehende Benchmarks zunehmend mit den Vortrainingsdaten von LLMs, was bedeutet, dass Antworten oder unterstützende Wissensinhalte bereits in den Modellparametern kodiert sein können. Dies erschwert die Unterscheidung zwischen echtem Retrieval und Schlussfolgerung einerseits und parametrischer Erinnerung andererseits. Wir stellen HybridRAG-Bench vor, einen Rahmen zur Konstruktion von Benchmarks zur Bewertung von wissensintensiven, mehrschrittigen Schlussfolgerungen über hybride Wissensquellen. HybridRAG-Bench koppelt automatisch unstrukturierte Texte und strukturierte Wissensgraphen, die aus jüngsten wissenschaftlichen Arbeiten auf arXiv abgeleitet wurden, und generiert wissensintensive Frage-Antwort-Paare, die auf expliziten Schlussfolgerungspfaden basieren. Der Rahmen unterstützt eine flexible Auswahl von Domänen und Zeiträumen und ermöglicht somit eine kontaminationsbewusste und anpassbare Evaluation, während Modelle und Wissensquellen sich weiterentwickeln. Experimente in drei Domänen (Künstliche Intelligenz, Governance und Politik, Bioinformatik) zeigen, dass HybridRAG-Bench echtes Retrieval und Schlussfolgerung belohnt, anstatt parametrische Erinnerung, und somit eine fundierte Testumgebung für die Bewertung hybrider, wissensverstärkter Schlussfolgerungssysteme bietet. Wir stellen unseren Code und die Daten unter github.com/junhongmit/HybridRAG-Bench zur Verfügung.
One-sentence Summary
Researchers from MIT, IBM, and UCF introduce HYBRIDRAG-BENCH, a contamination-aware framework that evaluates LLMs’ multi-hop reasoning over hybrid knowledge by coupling arXiv-derived text and knowledge graphs, enabling domain-specific, time-bound assessments that distinguish true retrieval from parametric recall.
Key Contributions
- HYBRIDRAG-BENCH introduces a contamination-aware benchmark framework that constructs multi-hop reasoning tasks from recent arXiv literature, ensuring questions rely on external retrieval rather than parametric recall by using time-framed, evolving scientific corpora.
- The framework automatically generates hybrid knowledge environments combining unstructured text and structured knowledge graphs, producing diverse question types grounded in explicit reasoning paths to evaluate genuine retrieval and reasoning across domains like AI, policy, and bioinformatics.
- Experiments show HYBRIDRAG-BENCH effectively discriminates between models that perform true retrieval-based reasoning and those relying on pretraining memorization, offering a scalable, customizable testbed for evaluating hybrid knowledge-augmented systems.
Introduction
The authors leverage retrieval-augmented generation (RAG) and structured knowledge graphs to tackle knowledge-intensive, multi-hop reasoning tasks where large language models (LLMs) often fail due to outdated knowledge or insufficient reasoning. Prior benchmarks suffer from pretraining contamination—where models answer correctly by memorization rather than retrieval—making it hard to assess whether systems truly reason or just recall. To address this, they introduce HYBRIDRAG-BENCH, a framework that automatically constructs contamination-aware benchmarks from recent arXiv papers, coupling unstructured text with structured knowledge graphs and generating questions tied to explicit reasoning paths. Their method enables fair, scalable evaluation across domains and timeframes, distinguishing genuine retrieval and multi-hop reasoning from parametric recall.
Dataset

The authors use HYBRIDRAG-BENCH, a dynamically constructed, domain-specific benchmark for evaluating retrieval-augmented and knowledge-grounded LLMs. Key details:
-
Dataset Composition and Sources
- Built from arXiv papers collected per domain using subject categories (e.g., cs.AI) and optional keywords.
- Each domain has its own evolving knowledge graph derived from documents within a user-specified time window, postdating LLM pretraining cutoffs to prevent parametric memorization.
- No shared entities or relations across domains.
-
Key Subset Details
- Question Types: Single-hop, single-hop with conditions, multi-hop, difficult multi-hop (via high-degree entities), counterfactual, and open-ended.
- Size: Varies by domain; distribution per type shown in Table 2.
- Filtering: Questions must be answerable solely from hybrid context (KG path + supporting text), pass LLM-as-a-judge faithfulness checks, and avoid document-local references or ambiguity.
- Metadata: Includes paper title, authors, categories, and timestamps; text is segmented by section (abstract, methods, etc.).
-
Data Usage in Model Training/Evaluation
- Questions are generated by conditioning an LLM on: (1) a sampled KG reasoning path, (2) associated textual evidence, and (3) in-context examples.
- Each QA pair is tied to a specific knowledge graph snapshot at time t_i, ensuring temporal isolation.
- Used exclusively for evaluation—not training—of LLMs to measure ability to integrate structured and unstructured evidence.
-
Processing and Cropping Strategy
- Reasoning paths are sampled from the domain’s knowledge graph; textual spans are retrieved for each entity/relation.
- Questions are synthesized to obscure intermediate nodes (in multi-hop cases) or include counterfactual perturbations.
- Final QA pairs undergo normalization (lowercasing, punctuation) and multi-stage filtering for clarity, faithfulness, and independence.
Method
The authors leverage a four-stage automated pipeline to construct HYBRIDRAG-BENCH, a benchmark designed to evaluate retrieval-augmented reasoning over hybrid knowledge sources. The framework begins with user-specified parameters—such as time frame, topic area, and question types—which guide the collection of a time-framed arXiv corpus. This corpus serves as the foundational data source for both unstructured text chunks and structured knowledge graphs.
Refer to the framework diagram for an overview of the pipeline’s architecture. The first stage, Time-Framed Corpus Collection, ingests documents from arXiv based on user constraints. These documents are then processed in parallel to generate two complementary knowledge representations: unstructured text chunks and a structured knowledge graph. The knowledge graph is constructed using EvoKG, a document-driven framework that extracts entities and relations via large language models. Entity extraction is followed by context-aware alignment, which resolves lexical variation and semantic ambiguity by matching new mentions against existing nodes using joint embeddings of type, name, and description. If no sufficiently similar node exists, a new entity is created; otherwise, the mention is merged, preserving provenance.
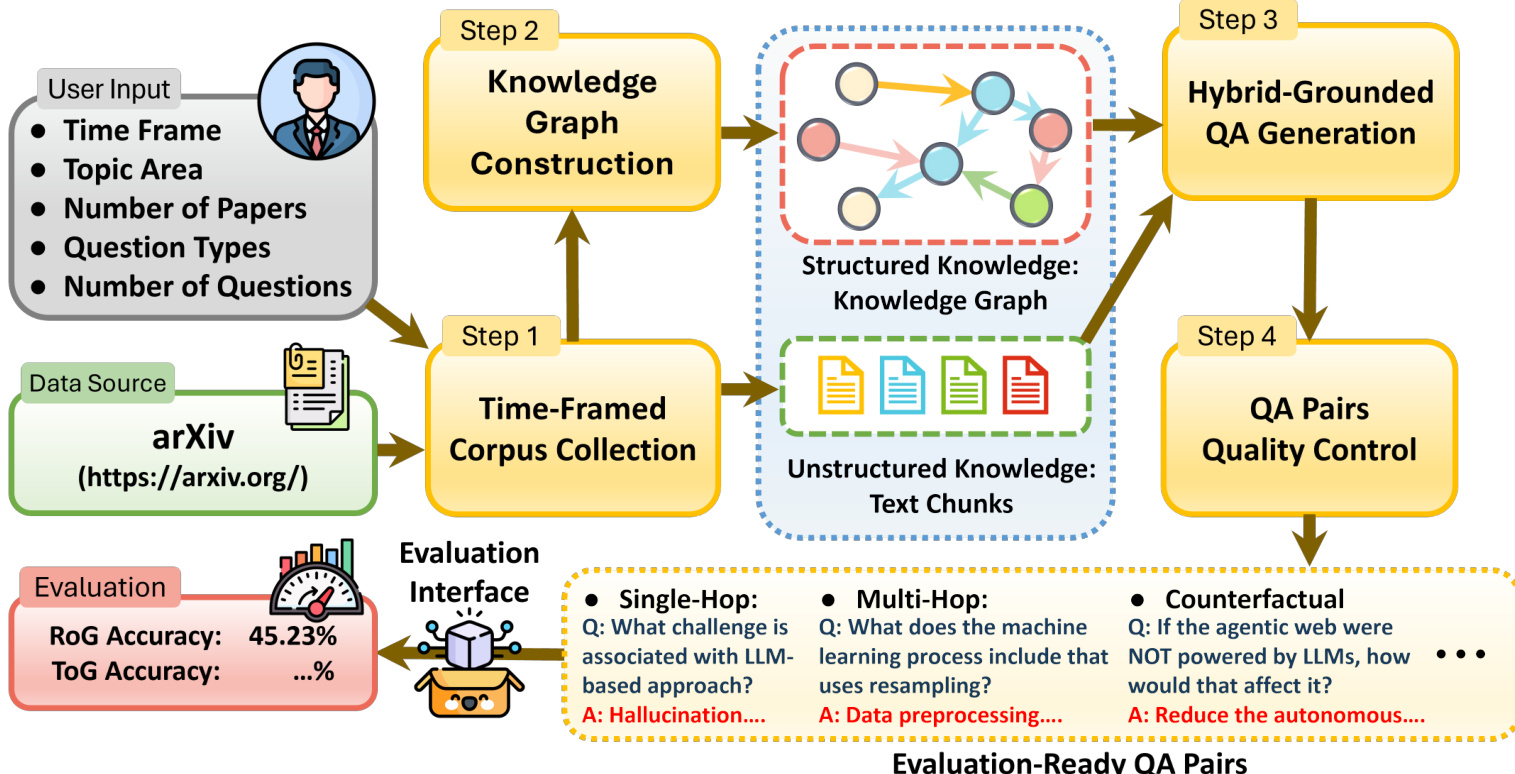
Relation normalization follows, where extracted relations are mapped to a domain-specific schema and linked to supporting textual evidence. The graph retains multiple candidate relations when supported by the corpus, annotated with confidence scores derived from frequency, recency, and textual support—thereby preserving the uncertainty and variation inherent in scientific literature.
In the third stage, Hybrid-Grounded QA Generation, the system synthesizes diverse question-answer pairs grounded in explicit reasoning paths that traverse both the knowledge graph and retrieved text chunks. These questions span single-hop, multi-hop, conditional, counterfactual, and open-ended reasoning types. The final stage, QA Pairs Quality Control, applies automated filters to ensure answerability, independence from document phrasing, and non-redundancy, yielding evaluation-ready QA pairs.
The resulting benchmark enables controlled, reproducible evaluation of RAG and KG-RAG systems by providing both structured and unstructured knowledge sources that reflect real-world scientific discourse. The model’s prediction is formally defined as a^=f(q,Gtq(m),Dtq(m)), where the model f reasons over the knowledge graph snapshot Gtq(m) and retrieved documents Dtq(m) available at query time tq.
Experiment
- HYBRIDRAG-Bench poses persistent challenges across LLM scales, confirming questions cannot be reliably answered by parametric knowledge alone and require external retrieval and reasoning.
- External retrieval is essential: text-based RAG significantly improves performance over LLM-only methods, while naive KG injection often degrades results due to noise.
- Structured knowledge adds complementary value: hybrid KG-RAG methods consistently outperform text-only RAG, especially on relational, multi-hop, and disambiguation tasks.
- The benchmark effectively discriminates between reasoning strategies: performance varies meaningfully by question type, with structured methods excelling on multi-hop and counterfactual queries, while text retrieval dominates open-ended questions.
- KG construction is effective and scalable: the pipeline recovers ~71% of verifiable facts and scales near-linearly in cost and latency, ensuring practical deployment without performance bottlenecks.
The authors evaluate their KG construction pipeline against prior methods and find that EvoKG captures significantly more verifiable facts from source documents, achieving a 71.36% recovery rate compared to 66.46% for KGen and lower rates for OpenIE and GraphRAG. This indicates that the knowledge graphs used in HybridRAG-Bench are robust and not a limiting factor in the benchmark’s difficulty. Results confirm that the challenge stems from retrieval and reasoning demands rather than incomplete or inaccurate knowledge extraction.

The authors use HybridRAG-Bench to evaluate how different retrieval and reasoning strategies perform across domain-specific tasks, finding that LLM-only approaches consistently underperform regardless of model scale. Results show that combining structured knowledge graphs with text-based retrieval yields the strongest performance, especially on multi-hop and counterfactual questions, indicating that effective reasoning requires more than just access to external information. The benchmark meaningfully distinguishes between methods by question type, revealing that hybrid approaches outperform both pure text retrieval and naive graph augmentation.
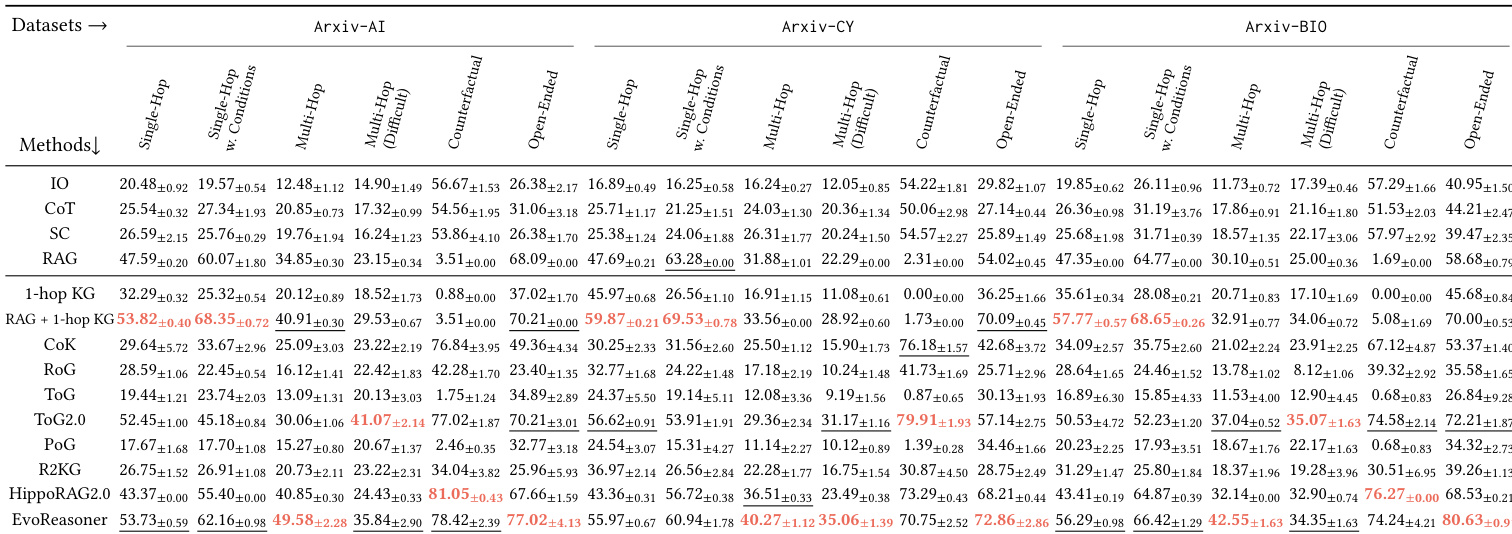
The authors use HybridRAG-Bench to evaluate how different retrieval and reasoning strategies perform across domain-specific tasks, finding that LLM-only approaches consistently underperform regardless of model scale. Results show that combining structured knowledge graphs with text-based retrieval yields the strongest performance, especially on multi-hop and counterfactual questions, indicating that effective reasoning requires more than just access to external information. The benchmark meaningfully distinguishes between methods by question type, revealing that hybrid approaches outperform both pure text retrieval and naive graph augmentation.
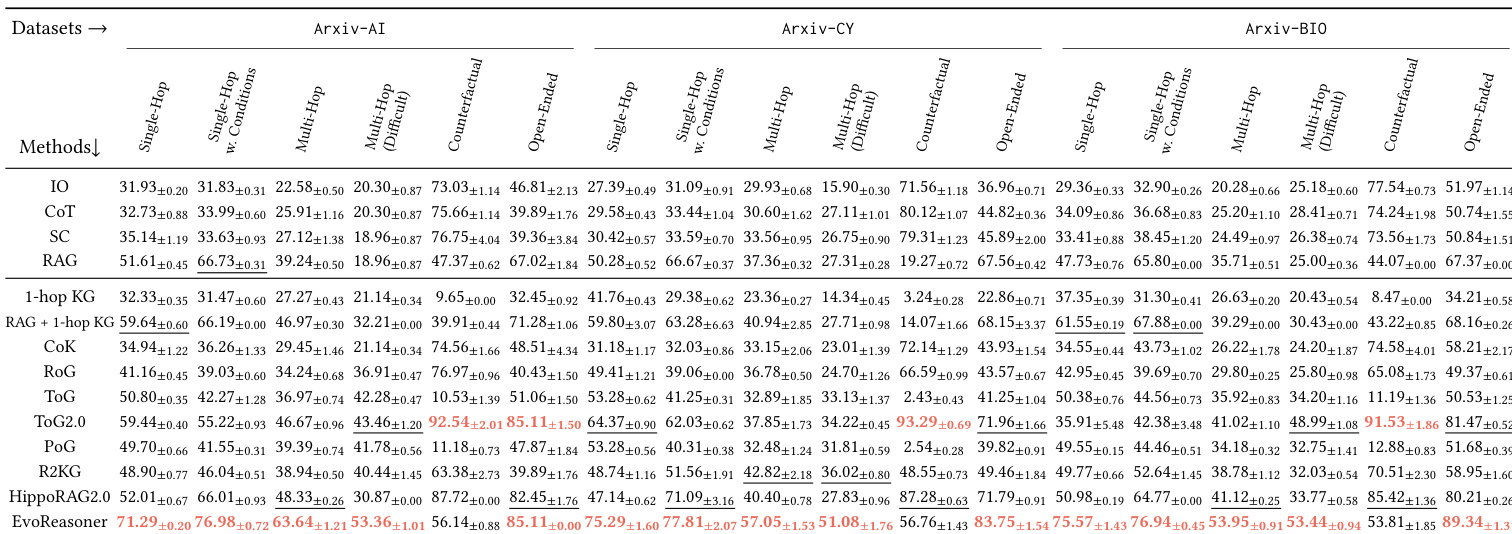
The authors use HybridRAG-Bench to evaluate how different LLMs and retrieval strategies perform on knowledge-intensive reasoning tasks across three domains. Results show that LLM-only approaches perform poorly regardless of model scale, while hybrid methods combining structured knowledge graphs with text retrieval consistently outperform text-only RAG, especially on multi-hop and counterfactual questions. The benchmark effectively discriminates between reasoning strategies, revealing that success depends more on how knowledge is integrated than on model size alone.
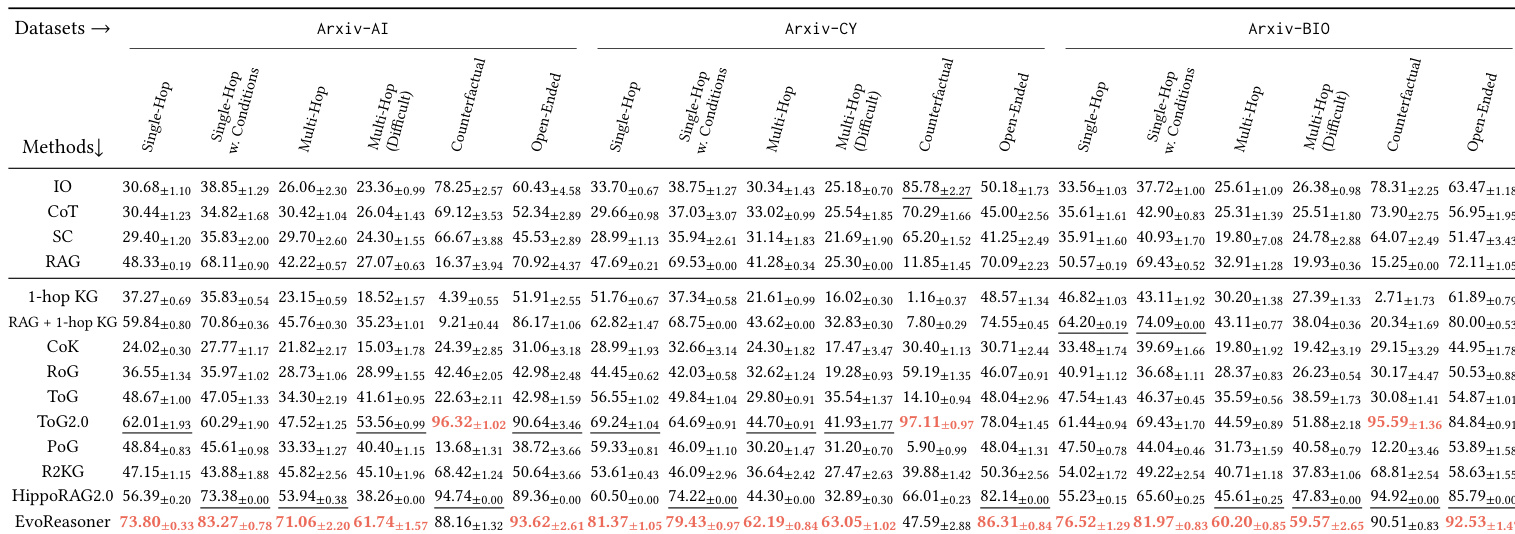
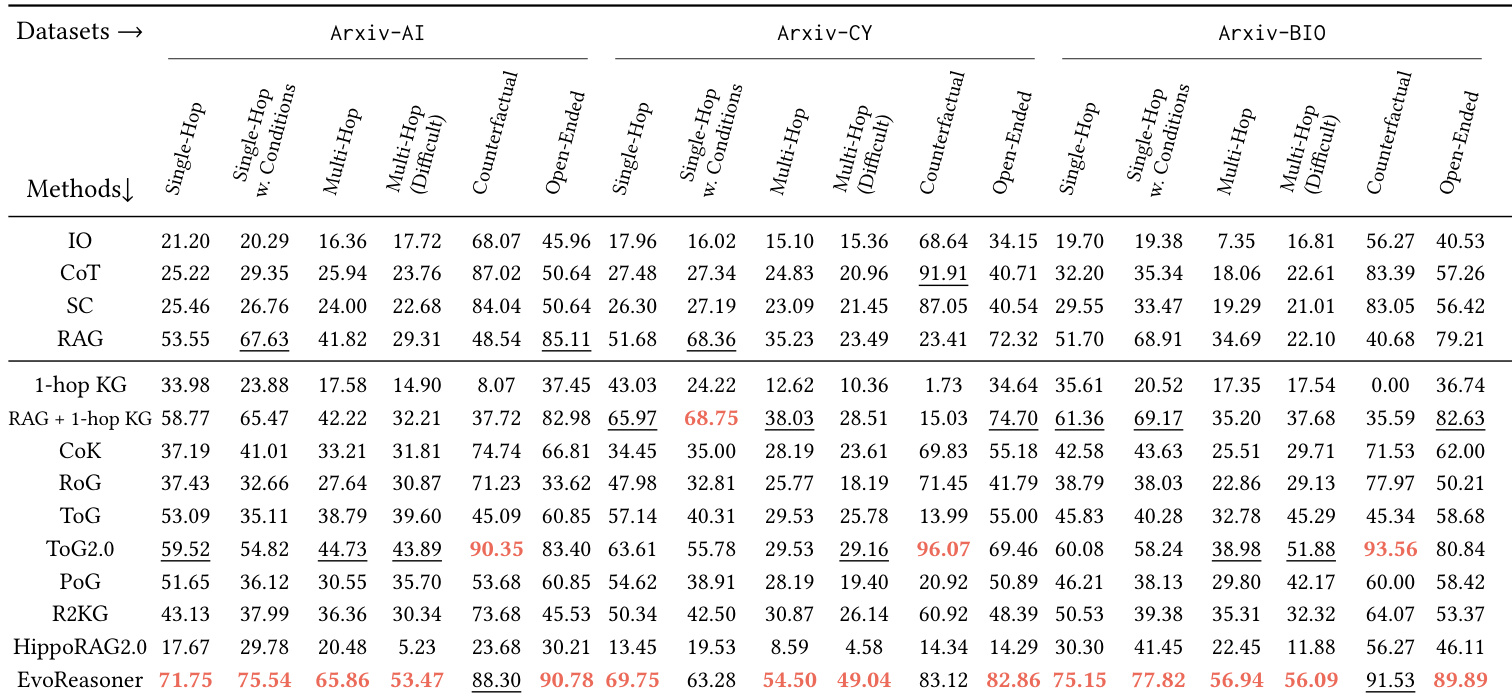
The authors use HybridRAG-Bench to evaluate how different retrieval and reasoning strategies perform across domain-specific tasks, finding that LLM-only approaches consistently underperform regardless of model scale. Results show that combining structured knowledge graphs with text-based retrieval yields the strongest performance, especially on multi-hop and counterfactual questions, indicating that effective reasoning requires more than just access to external information. The benchmark meaningfully distinguishes between methods by question type, revealing that hybrid approaches outperform text-only or naive graph augmentation strategies across all domains.