Command Palette
Search for a command to run...
Chain of Mindset: Denken mit adaptiven kognitiven Modi
Chain of Mindset: Denken mit adaptiven kognitiven Modi
Zusammenfassung
Das menschliche Problemlösen ist niemals die Wiederholung eines einzigen Denkmodus, unter dem wir einen spezifischen Modus kognitiver Verarbeitung verstehen. Bei der Bewältigung einer bestimmten Aufgabe setzen wir nicht auf einen einzigen Denkansatz, sondern integrieren mehrere Denkansätze innerhalb eines einzigen Lösungsprozesses. Bestehende Schlussfolgerungsverfahren für große Sprachmodelle (LLM) geraten jedoch in einen typischen Fehltritt: Sie wenden über alle Schritte hinweg denselben festen Denkansatz an und übersehen dabei, dass verschiedene Phasen der Lösung derselben Aufgabe grundlegend unterschiedliche Denkansätze erfordern. Diese einseitige Annahme hindert Modelle daran, die nächste Stufe der Intelligenz zu erreichen. Um diese Einschränkung zu überwinden, schlagen wir Chain of Mindset (CoM) vor – einen trainingsfreien, agentialen Rahmen, der eine schrittweise adaptive Orchestrierung von Denkansätzen ermöglicht. CoM zerlegt die Schlussfolgerung in vier funktional unterschiedliche Denkansätze: räumlich (Spatial), konvergent (Convergent), divergent (Divergent) und algorithmisch (Algorithmic). Ein Meta-Agent wählt dynamisch den optimalen Denkansatz basierend auf dem sich verändernden Schlussfolgerungszustand aus, während ein bidirektionaler Kontext-Gate den Informationsfluss zwischen den Modulen filtert, um Effektivität und Effizienz zu gewährleisten. Experimente an sechs anspruchsvollen Benchmarks, die Mathematik, Codegenerierung, wissenschaftliche Fragen und Antworten sowie räumliches Denken abdecken, zeigen, dass CoM Spitzenleistung erzielt: Es übertrifft die stärkste Baseline um 4,96 % und 4,72 % in der Gesamtgenauigkeit auf Qwen3-VL-32B-Instruct und Gemini-2.0-Flash, wobei gleichzeitig eine Balance zwischen Schlussfolgerungseffizienz und Leistung gewahrt wird. Unser Code ist öffentlich verfügbar unter https://github.com/QuantaAlpha/chain-of-mindset.
One-sentence Summary
Researchers from PKU, BJTU, QuantaAlpha, and others propose Chain of Mindset (CoM), a training-free framework that dynamically selects among four cognitive mindsets during reasoning, outperforming baselines by nearly 5% on key benchmarks while maintaining efficiency, advancing LLM problem-solving beyond fixed-mode approaches.
Key Contributions
- We identify a critical limitation in current LLM reasoning: the reliance on a single fixed mindset across all steps, despite human problem-solving requiring dynamic transitions between distinct cognitive modes such as Spatial, Convergent, Divergent, and Algorithmic thinking.
- We introduce Chain of Mindset (CoM), a training-free agentic framework that dynamically selects the optimal mindset per reasoning step via a Meta-Agent and controls cross-module information flow using a bidirectional Context Gate to preserve efficiency and effectiveness.
- CoM achieves state-of-the-art results across six diverse benchmarks, improving overall accuracy by 4.96% and 4.72% over the strongest baselines on Qwen3-VL-32B-Instruct and Gemini-2.0-Flash, while maintaining computational efficiency without model retraining.
Introduction
The authors leverage cognitive science to address a key limitation in LLM reasoning: current methods apply a single fixed mindset across all reasoning steps, despite human problem-solving dynamically switching between distinct cognitive modes. Prior approaches either lock models into one strategy or select a static method at task onset, failing to adapt as subtask demands evolve. Their main contribution is Chain of Mindset (CoM), a training-free agentic framework that dynamically orchestrates four functionally distinct mindsets—Spatial, Convergent, Divergent, and Algorithmic—using a Meta-Agent that selects the optimal mode per step. A bidirectional Context Gate filters information flow to maintain efficiency and reduce interference, enabling state-dependent switching without retraining. CoM achieves state-of-the-art results across six benchmarks, outperforming baselines by up to 4.96% while generalizing across models and preserving computational efficiency.
Dataset
-
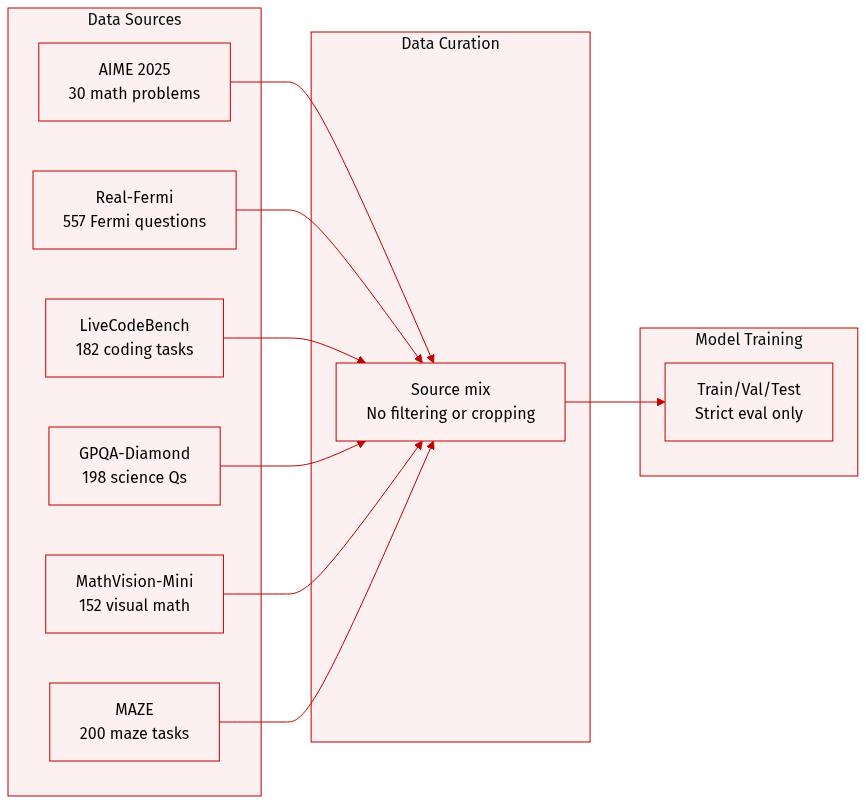
The authors evaluate CoM on six benchmarks across four categories, sourced from recent academic datasets and competitions.
-
Mathematical Reasoning includes:
- AIME 2025: 30 problems covering algebra, geometry, combinatorics, and number theory.
- Real-Fermi: 557 Fermi estimation problems requiring order-of-magnitude reasoning.
-
Code Generation uses LiveCodeBench: 182 programming problems from LeetCode, AtCoder, and CodeForces (Jan–May 2025), categorized as 45 Easy, 55 Medium, and 82 Hard.
-
Science QA features GPQA-Diamond: a curated subset of 198 PhD-level questions in physics, chemistry, and biology, selected because non-experts score only ~30% accuracy.
-
Multimodal Reasoning includes:
- MathVision-Mini: 152 multimodal math questions requiring diagram interpretation before symbolic solving.
- MAZE: 200 maze navigation tasks generated via maze-dataset, where models predict final position after executing a given action sequence on a maze image.
-
No training data is used from these benchmarks; they serve strictly for evaluation. All datasets are used in their original or minimally filtered forms as specified by their respective authors. No cropping or metadata construction is mentioned for these test sets.
Method
The authors leverage a three-layer decoupled architecture called Chain of Mindset (CoM) to enable dynamic, multi-modal reasoning in large language models. This framework separates meta-cognitive orchestration from concrete execution, allowing the system to switch between functionally heterogeneous reasoning paradigms—termed “mindsets”—based on intermediate progress and semantic context. The core components are the Meta-Agent, four specialized Mindset modules, and a bidirectional Context Gate that mediates information flow to prevent context pollution.
The Meta-Agent serves as the central controller, responsible for generating cognitive decisions that define which mindset to invoke at each step. It operates in an iterative Plan-Call-Internalize loop: given the current state st=(q,H<t), it selects a mindset mt via policy π, dispatches a corresponding call ct, receives the output and insight, and internalizes the insight to potentially revise its plan. This enables self-correction and adaptive re-planning during complex reasoning trajectories.
As shown in the figure below, the framework dynamically selects the optimal cognitive mode at each step, contrasting with static strategy selection or single-mode reasoning. The four mindsets—Algorithmic, Spatial, Convergent, and Divergent—each encapsulate distinct cognitive strategies and operate within isolated contexts. The Algorithmic Mindset handles precise calculations via a generate-execute-repair loop, iterating up to Nmax=2 times to fix code errors:
(ρi+1,ralgo)=⎩⎨⎧(ρi,EXEC(ρi))(FIX(ρi,ϵi),⊥)(ρi,ϵi)if execution succeedsif error ϵi∧i<NmaxotherwiseThe Spatial Mindset bridges abstract logic and visual intuition by generating or editing images via Nano-Banana-Pro, supporting three modes: Text→Image, Image+Text→Image, and Code→Image. Generated artifacts are registered with unique identifiers (e.g., [GEN_001]) for later reference. The Convergent Mindset performs focused, deep reasoning grounded in established facts, producing a complete logical derivation. The Divergent Mindset breaks deadlocks by generating k∈[2,5] candidate solution branches, each analyzed in parallel, with results returned to the Meta-Agent for deliberation.
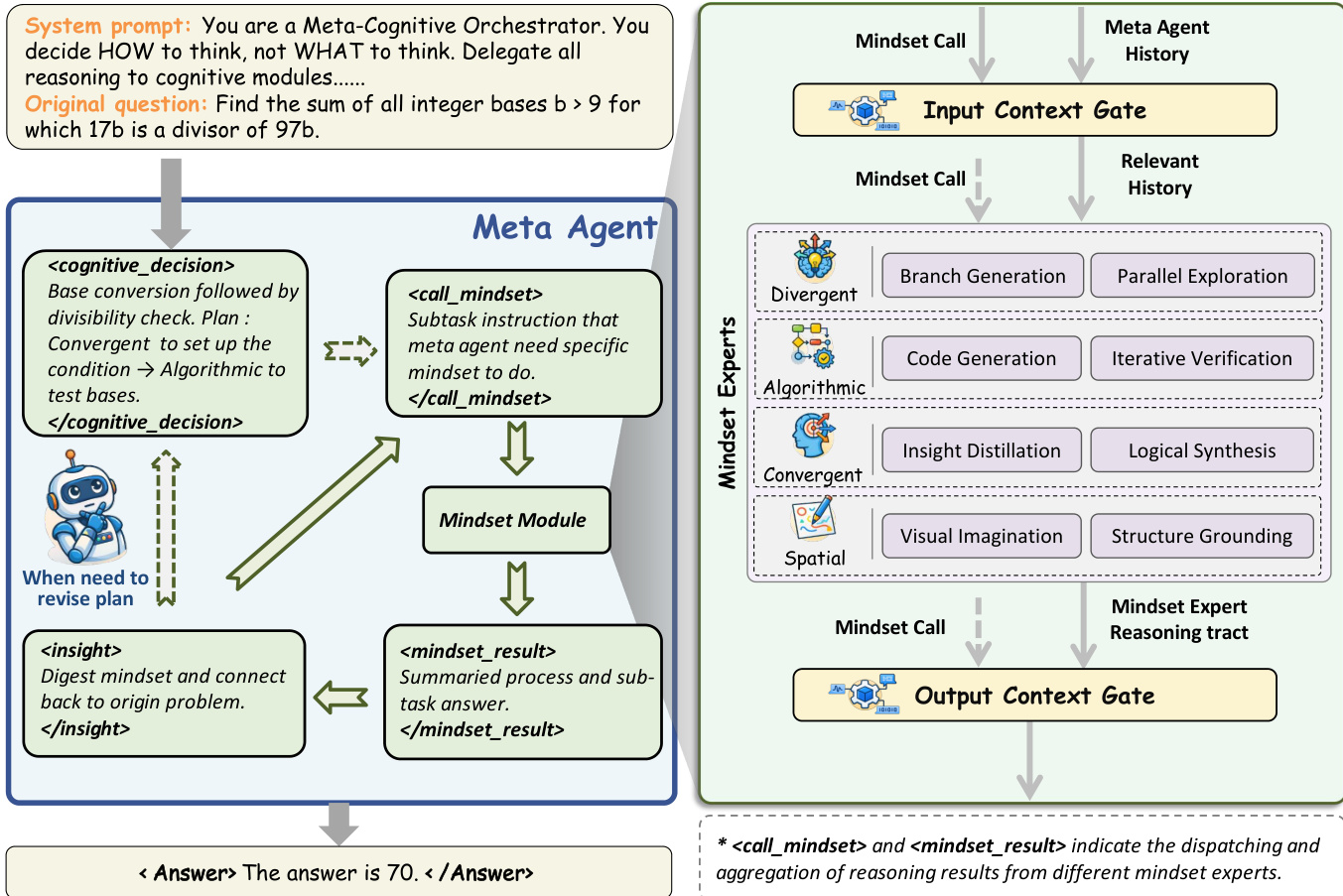
To address the Relevance-Redundancy Trade-off in modular reasoning, the Context Gate implements bidirectional semantic filtering. The Input Gate extracts a minimal sufficient context subset Hrel and relevant images Iini from the full history H, using the call instruction c as a semantic anchor:
(Hrel,Iini)=Gin(H,c,M,I)The Output Gate distills verbose mindset outputs r into concise summaries Osum aligned with the instruction’s goal:
Osum=Gout(r,c,Inew)This ensures high information density in both directions, enabling efficient execution within isolated mindset environments while preserving the compactness of the main reasoning chain. The Meta-Agent internalizes these distilled insights to guide subsequent decisions, forming a closed-loop cognitive architecture capable of dynamic adaptation.
Experiment
- CoM demonstrates adaptive mindset switching for complex reasoning, using Spatial for visual grounding, Convergent for ambiguity resolution, and Algorithmic for precise computation.
- It outperforms baselines across multiple benchmarks, showing strongest gains on tasks requiring flexible strategy adaptation, such as Fermi estimation and spatial reasoning.
- Ablation studies confirm the Context Gate is critical for coordination, while Divergent and Spatial mindsets drive performance on mathematical and visual tasks, respectively.
- CoM achieves state-of-the-art accuracy with moderate computational cost, placing it on the Pareto frontier of accuracy-efficiency trade-offs.
- Mindset invocation patterns reveal task-specific collaboration: Fermi and code tasks favor Algorithmic-Convergent pairs, while multimodal tasks heavily rely on Spatial reasoning.
- Dynamic re-planning is a core strength—CoM revises its strategy mid-process based on intermediate insights, enabling more efficient problem solving than static meta-reasoning approaches.
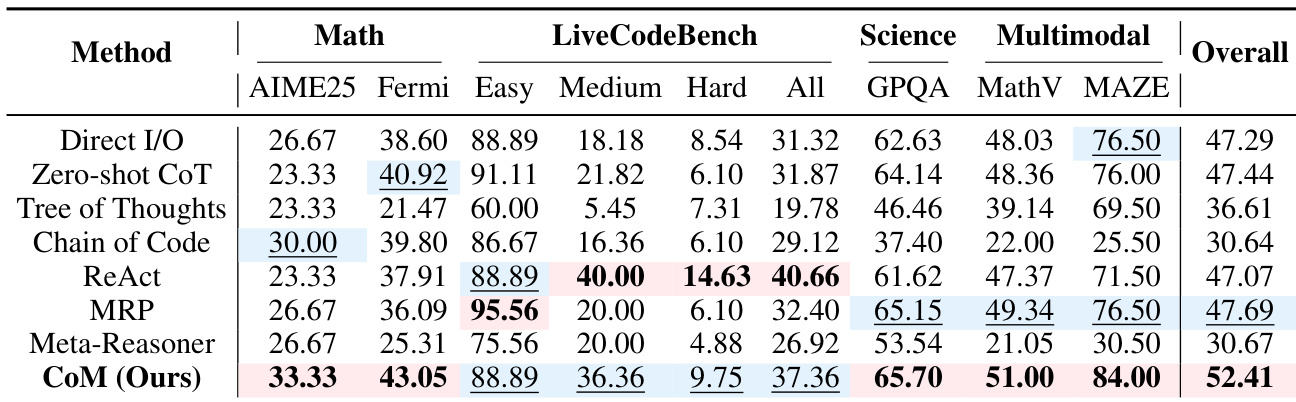
The authors use CoM to dynamically switch between cognitive mindsets during reasoning, achieving the highest overall accuracy across multiple benchmarks by adapting strategies based on problem context. Results show that removing key components like the Context Gate or Divergent mindset significantly degrades performance, confirming that coordinated, adaptive reasoning is essential for complex tasks. CoM also demonstrates efficiency gains by invoking only necessary mindsets per task, balancing accuracy with computational cost.
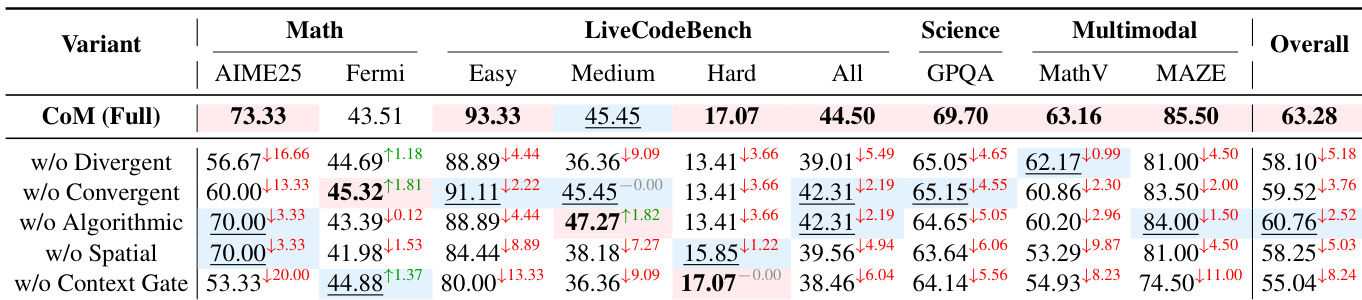
The authors use CoM to dynamically switch between cognitive mindsets during reasoning, achieving the highest overall accuracy across multiple benchmarks compared to both direct and meta-reasoning baselines. Results show that CoM particularly excels on tasks requiring flexible strategy adaptation, such as mathematical reasoning and multimodal spatial problems, while maintaining efficiency in token usage. The framework’s strength lies in its ability to coordinate specialized reasoning modes—like Algorithmic for computation and Spatial for visualization—based on problem context rather than relying on fixed or uniform strategies.
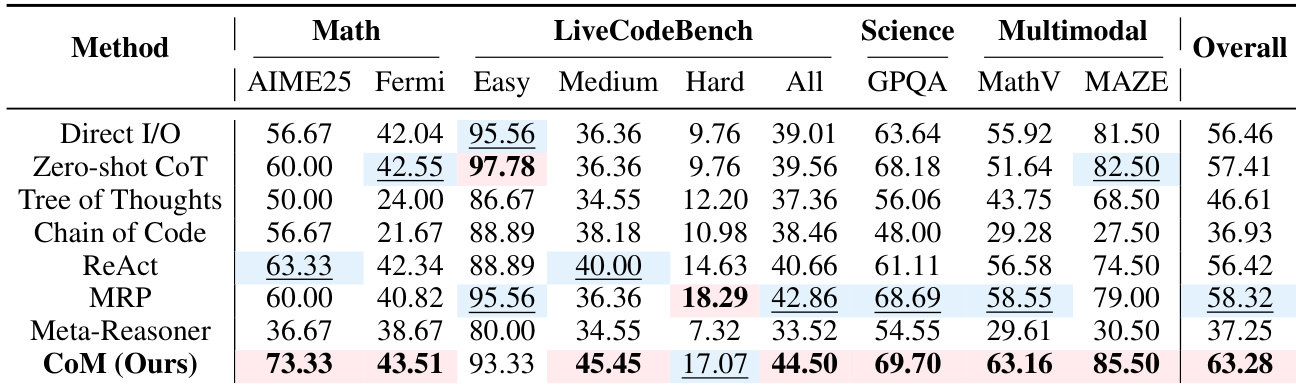
The authors use CoM to dynamically switch between cognitive mindsets during reasoning, achieving the highest overall accuracy across multiple benchmarks compared to both direct and meta-reasoning baselines. Results show that CoM particularly excels on tasks requiring flexible strategy adaptation, such as mathematical reasoning and multimodal spatial problems, while maintaining efficiency in token usage. The method’s strength lies in its ability to coordinate specialized reasoning modes—like Algorithmic for computation and Spatial for visualization—based on problem context rather than relying on fixed or uniform strategies.
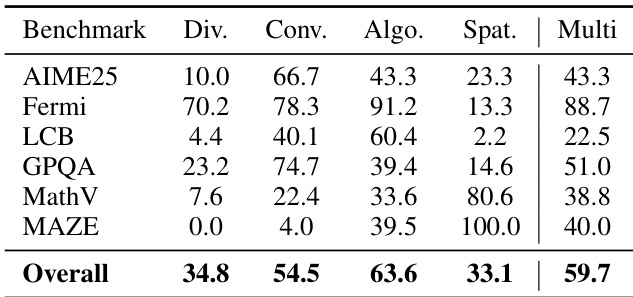
The authors use CoM to dynamically switch between cognitive mindsets—Divergent, Convergent, Algorithmic, and Spatial—based on problem requirements, with most tasks invoking multiple mindsets to achieve optimal reasoning. Results show that Algorithmic and Convergent mindsets are most frequently engaged overall, while Spatial is critical for visual tasks like MAZE and MathVision, and Divergent plays a key role in mathematical reasoning such as AIME25. The multi-mindset collaboration enables adaptive problem-solving, with 59.7% of problems requiring at least two distinct modes for effective resolution.