Command Palette
Search for a command to run...
P1-VL: Brückenschlag zwischen visueller Wahrnehmung und wissenschaftlichem Schlussfolgern in Physik-Olympiaden
P1-VL: Brückenschlag zwischen visueller Wahrnehmung und wissenschaftlichem Schlussfolgern in Physik-Olympiaden
Zusammenfassung
Der Übergang von symbolischer Manipulation zu wissenschaftsgraduierter Schlussfolgerung stellt eine entscheidende Front für große Sprachmodelle (Large Language Models, LLMs) dar, wobei die Physik als kritischer Prüfpunkt fungiert, um abstrakte Logik mit der physischen Realität zu verknüpfen. Die Physik erfordert, dass ein Modell physikalische Konsistenz mit den Gesetzen des Universums aufrechterhält – eine Aufgabe, die grundlegend multimodale Wahrnehmung erfordert, um abstrakte Logik in der Realität zu verankern. Auf Olympiade-Niveau sind Diagramme oft nicht nur illustrativ, sondern konstitutiv: Sie enthalten wesentliche Einschränkungen wie Randbedingungen und räumliche Symmetrien, die im Text fehlen. Um diese visuell-logische Lücke zu schließen, stellen wir P1-VL vor, eine Familie offener, vision-sprachlicher Modelle, die speziell für fortgeschrittene wissenschaftliche Schlussfolgerung konzipiert sind. Unsere Methode vereint Curriculum-Verstärkungslernen, das durch schrittweise Erweiterung der Schwierigkeit die Stabilität nach dem Training gewährleistet, mit agenter Verstärkung, die eine iterative Selbstüberprüfung während der Inferenz ermöglicht. Auf HiPhO, einer strengen Benchmark mit 13 Prüfungen aus den Jahren 2024–2025, erreicht unser Spitzenmodell P1-VL-235B-A22B als erstes offenes Vision-Language-Modell (VLM) zwölf Goldmedaillen und erzielt die führende Leistung unter allen offenen Modellen. Unser agentenverstärktes System erreicht weltweit den zweiten Platz, knapp hinter Gemini-3-Pro. Über die Physik hinaus zeigt P1-VL bemerkenswerte Fähigkeiten in der wissenschaftlichen Schlussfolgerung und Generalisierbarkeit und erzielt signifikante Vorsprünge gegenüber Basismodellen in STEM-Benchmarks. Durch die Open-Source-Veröffentlichung von P1-VL legen wir einen grundlegenden Schritt hin zu allgemeiner physikalischer Intelligenz zurück, um visuelle Wahrnehmung besser mit abstrakten physikalischen Gesetzen zu verbinden und die maschinelle wissenschaftliche Entdeckung voranzutreiben.
One-sentence Summary
Developed by Shanghai AI Laboratory’s P1 Team, P1-VL is the first open-source vision-language model family to achieve 12 gold medals in physics Olympiads by fusing curriculum reinforcement learning with agentic self-verification, uniquely bridging diagrams and physical laws for multimodal scientific reasoning.
Key Contributions
- P1-VL addresses the critical gap in physics reasoning by integrating visual perception with abstract logic, specifically targeting Olympiad problems where diagrams encode essential constraints absent in text, thus enabling grounded scientific reasoning.
- The model leverages Curriculum Reinforcement Learning with progressive difficulty scaling and Agentic Augmentation for iterative self-verification at inference, stabilizing training and enhancing reasoning fidelity beyond standard fine-tuning approaches.
- Evaluated on the HiPhO benchmark of 13 2024–2025 exams, P1-VL-235B-A22B achieves 12 gold medals and ranks No.2 globally when augmented with PhysicsMinions, outperforming all other open-source VLMs and demonstrating strong generalization across STEM tasks.
Introduction
The authors leverage physics Olympiad problems as a high-stakes testbed to push Large Language Models beyond symbolic reasoning into grounded, multimodal scientific understanding. Prior work largely ignores the critical role of diagrams in physics—where visuals encode essential constraints absent in text—limiting models to incomplete, text-only reasoning. To bridge this gap, they introduce P1-VL, an open-source family of vision-language models trained via Curriculum Reinforcement Learning to progressively master complex reasoning, and augmented with an agent framework that enables iterative self-correction at inference. Their flagship model achieves 12 gold medals on the HiPhO benchmark, ranking second globally among all models, and demonstrates strong generalization across STEM domains—setting a new standard for open-source physical intelligence.
Dataset
-
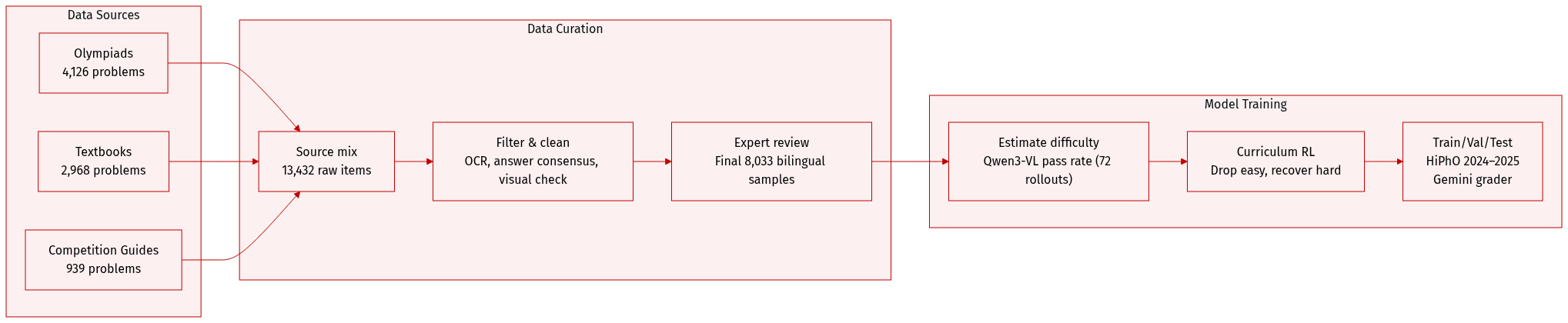
The authors use a curated multimodal physics dataset of 8,033 problems, drawn from three sources: 4,126 from physics Olympiads (including IPhO and APhO up to 2023), 2,968 from undergraduate textbooks, and 939 from competition guides. These sources were selected to balance conceptual depth, visual richness, and verifiable solutions.
-
Each subset was processed through a multi-stage pipeline: OCR correction for scanned materials, model-based answer extraction (using Gemini-2.5-Flash, Claude-3.7-Sonnet, and GPT-4o) with majority-vote consensus, filtering of diagram-generation or open-ended tasks, visual consistency checks via Gemini-2.5-Flash, and final expert review. This reduced the initial 13,432 items to 8,033 high-fidelity, bilingual samples.
-
For training, the authors apply curriculum reinforcement learning. They first estimate problem difficulty using Qwen3-VL-30B-A3B’s pass rate across 72 rollouts. They remove trivial samples (pass rate > 0.7) and recover zero-shot failures (pass rate = 0.0) using Gemini-2.5-Flash for verification and refinement. Training proceeds in stages, progressively lowering the difficulty threshold and expanding group size and generation window to maintain search depth.
-
The dataset is used exclusively for RLVR training, with no test data from the same sources. Evaluation is performed on HiPhO, a separate benchmark of 13 recent Olympiad exams (2024–2025), using Gemini-2.5-Flash as an automated grader that scores both final answers and reasoning steps, mirroring human grading to enable medal-threshold comparisons.
Method
The authors leverage a reinforcement learning (RL) framework to train vision-language models for solving complex Physics Olympiad problems, formulating the task as a Markov Decision Process (MDP) where the state space encompasses the problem context and generated reasoning tokens, and the action space corresponds to the discrete vocabulary of output tokens. The policy is optimized to maximize the expected return, computed as the sum of scalar rewards over a trajectory, with the reward signal derived from the correctness of the final answer relative to ground truth. To stabilize training and improve sample efficiency, they adopt Group Sequence Policy Optimization (GSPO), which operates at the sequence level rather than the token level, employing length-normalized importance ratios to reduce variance and a clipped objective to constrain policy updates.
Refer to the framework diagram, which illustrates the end-to-end data pipeline from raw problem sources to final training data. The process begins with PDF conversion to Markdown, followed by QA parsing to extract question-answer pairs. Human annotators then perform answer annotation, ensuring the solutions adhere to a structured format—such as LaTeX for symbolic expressions and boxed final answers—as specified in the system prompt. Post-processing includes language transformation and expert review, culminating in multi-modal training data that pairs questions, answers, associated images, and metadata. This structured pipeline ensures that the model learns to generate verifiable, format-compliant solutions while handling both textual and visual inputs.

To address the train-inference mismatch inherent in distributed RL training, the authors implement Sequence-level Masked Importance Sampling (Seq-MIS), which rejects entire trajectories whose geometric mean of importance weights exceeds a threshold, thereby enforcing a hard trust region. This mechanism mitigates gradient bias introduced by discrepancies between rollout and training engines. The training dynamics are further stabilized through curriculum learning, where complexity is progressively increased by scaling data difficulty, expanding group sizes, and extending generation windows across stages. The VERL framework is used for implementation, with vision encoders and projection layers frozen during RL training to preserve pre-trained visual representations, while the language model parameters are fine-tuned.
At inference time, the system is augmented with PhysicsMinions, a multi-agent framework comprising Visual, Logic, and Review Studios. The Visual Studio processes diagrams and converts them into symbolic representations, enabling grounded reasoning. The Logic Studio iteratively refines solutions via solver-introspector collaboration, while the Review Studio validates outputs using domain-specific verifiers. This agentic loop supports scalable, robust reasoning on multimodal problems, with domain-adaptive mechanisms routing problems to appropriate solvers and verifiers based on detected scientific discipline.
Experiment
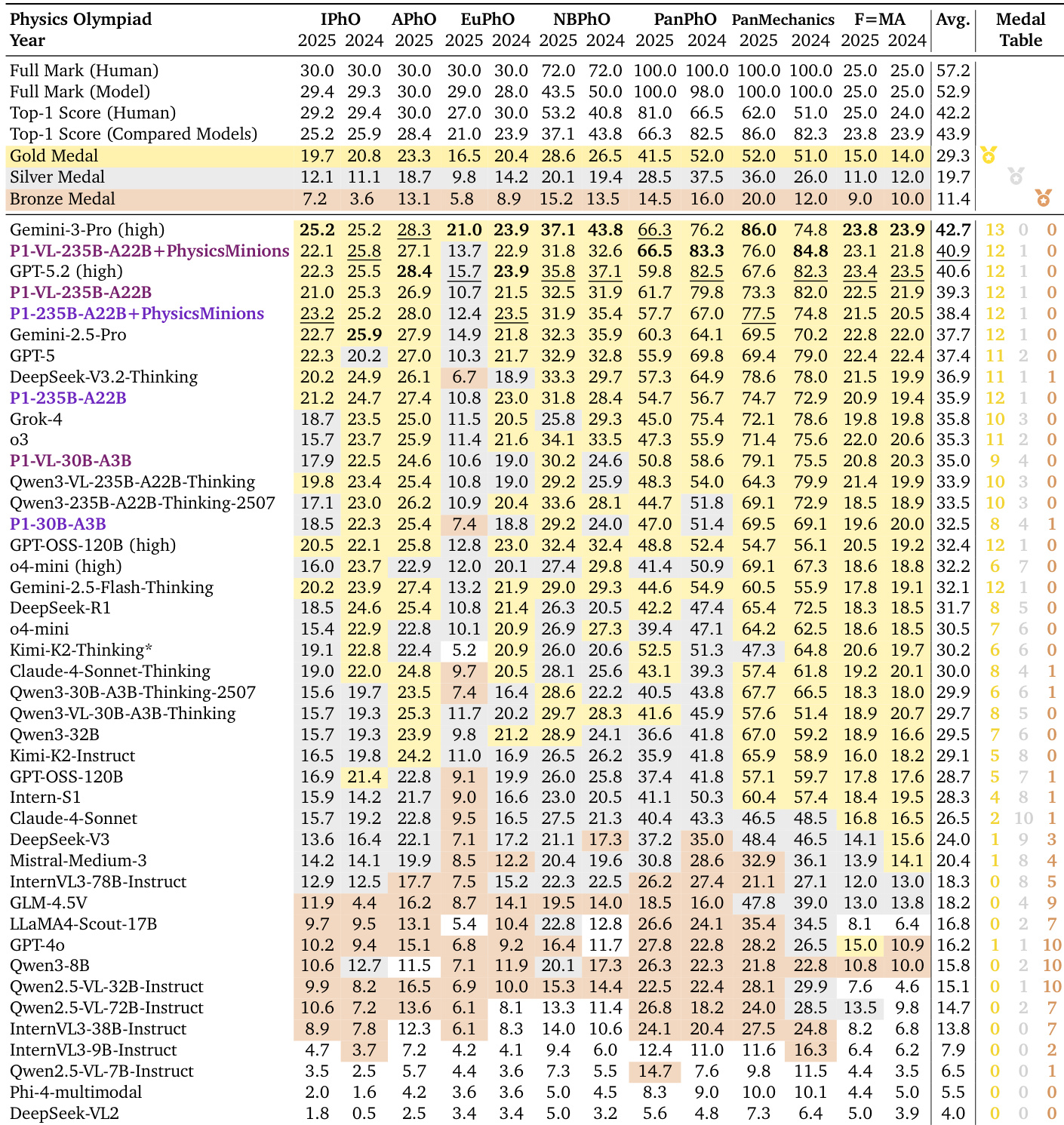
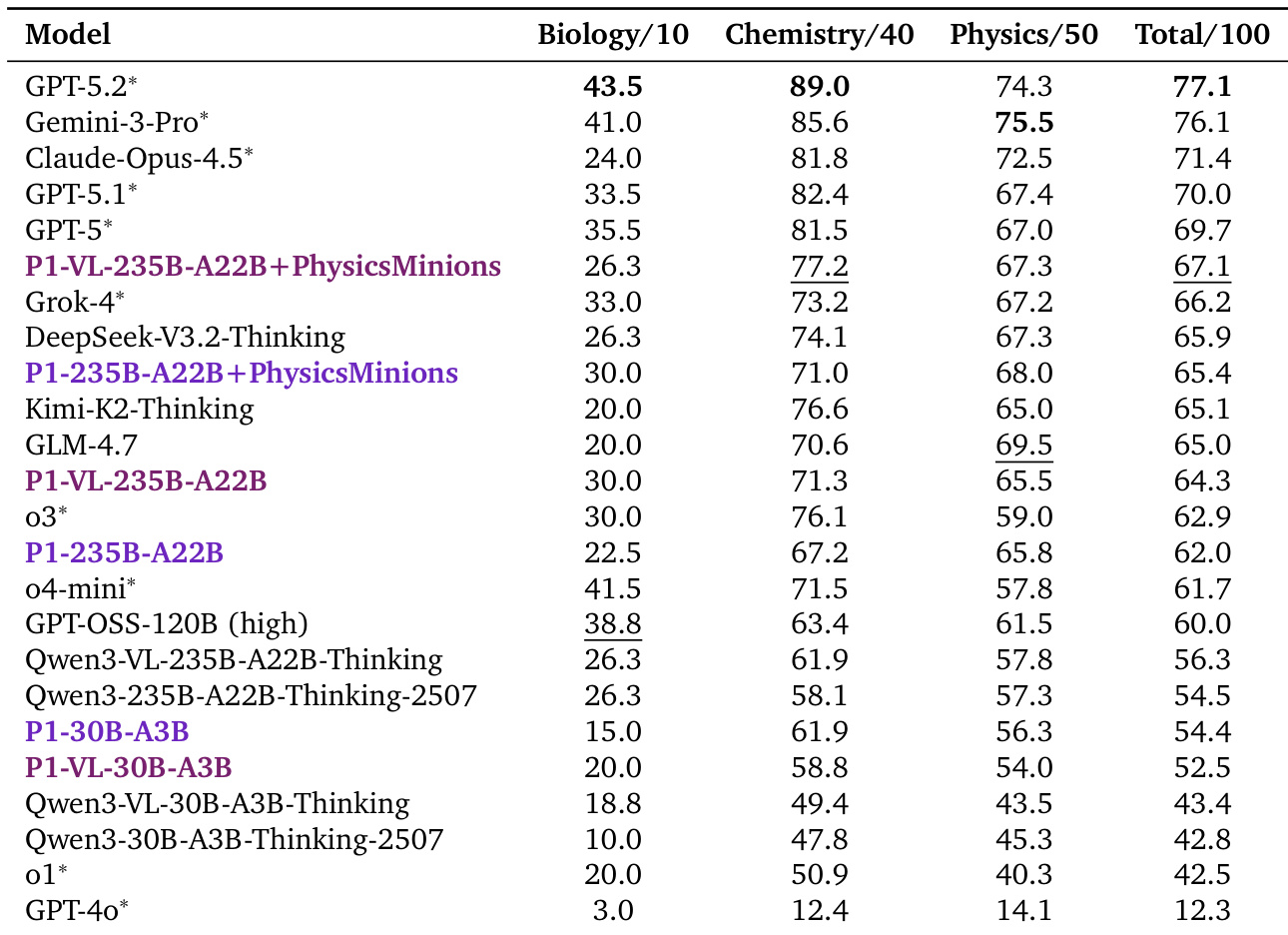
- P1-VL models trained via reinforcement learning achieve top-tier performance on physics Olympiads, outperforming many closed-source models and demonstrating superior visual-scientific reasoning without agent augmentation.
- Agent-augmented P1-VL systems surpass even top closed-source models, setting new benchmarks across multiple Olympiads and validating the “model + system” paradigm for complex scientific tasks.
- P1-VL models generalize well beyond physics, showing strong transfer to diverse STEM benchmarks including math and multi-modal reasoning, with consistent gains over base models and minimal catastrophic forgetting.
- Training stability is achieved through Sequence-Level Masked Importance Sampling, which mitigates train-inference mismatch and prevents RL collapse observed with other sampling methods.
- Mixed training data (text-only + image-text) enhances performance without negative transfer, supporting the use of heterogeneous data for robust multimodal training.
- Curriculum-based RL training significantly improves reasoning depth and response length, proving essential for developing advanced scientific reasoning capabilities.
- RL training is broadly effective across model architectures, including InternVL series, confirming its generalizability for unlocking latent scientific reasoning in diverse base models.
The authors use a physics Olympiad benchmark to evaluate models trained with reinforcement learning, showing that their P1-VL series outperforms both open-source and closed-source baselines in scientific reasoning, even without agent augmentation. When combined with multi-agent systems, the models achieve state-of-the-art results across multiple competitions, demonstrating that structured training and system-level collaboration significantly enhance complex problem-solving. The models also generalize well to other STEM domains, improving performance on text-only and multi-modal tasks while maintaining robust visual reasoning capabilities.
The authors use reinforcement learning to train P1-VL models, achieving top-tier performance on physics Olympiads and demonstrating strong generalization to other STEM domains. Results show that even smaller variants outperform larger baselines, and combining the model with agent frameworks further boosts scores, highlighting the value of integrated system design. The models also retain and enhance reasoning capabilities across text-only and multi-modal tasks, indicating effective vision-language alignment without catastrophic forgetting.
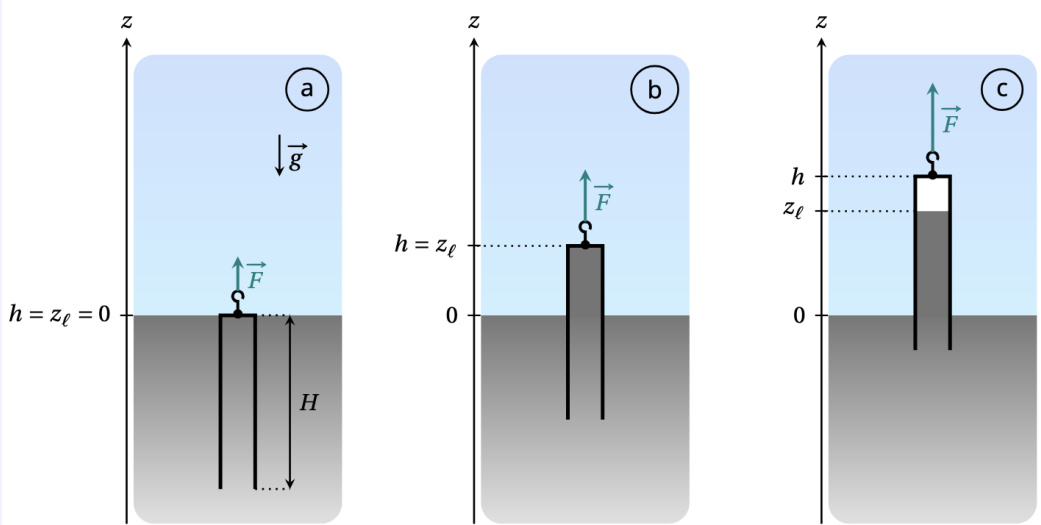
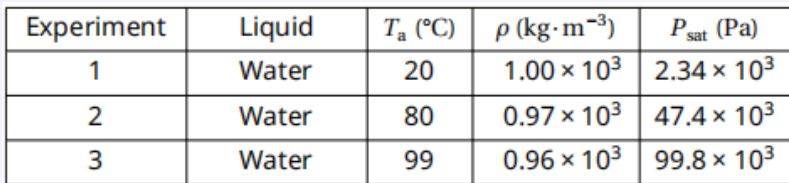
The authors use a physics problem involving fluid mechanics and atmospheric pressure to evaluate model reasoning, requiring integration of visual schematics, tabular data, and symbolic equations. Results show the model correctly identifies behavioral regimes and computes precise force values across experiments, demonstrating robust alignment between visual perception and scientific calculation. This case underscores the model’s ability to sustain multi-step reasoning under real-world physical constraints without hallucinating invalid assumptions.

The authors use reinforcement learning to train P1-VL models, achieving top-tier performance on physics Olympiad benchmarks, with the largest variant ranking third among all models and outperforming several closed-source systems even without agent augmentation. When combined with the PhysicsMinions agent framework, the model climbs to second place globally, setting new state-of-the-art scores on multiple competitions, demonstrating that multi-agent collaboration significantly enhances complex scientific reasoning. Results also show strong generalization beyond physics, with consistent gains over base models across diverse STEM and multimodal benchmarks, indicating that domain-specific training does not compromise but rather amplifies broader reasoning capabilities.