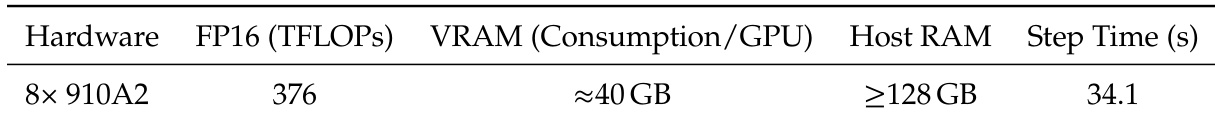Command Palette
Search for a command to run...
MOVA: Hin zu skalierbarer und synchroner Video-Audio-Generierung
MOVA: Hin zu skalierbarer und synchroner Video-Audio-Generierung
Zusammenfassung
Audio ist für reale Videos unverzichtbar, doch Generativmodelle haben den audiovisuellen Aspekt bisher weitgehend vernachlässigt. Derzeitige Ansätze zur Erzeugung audiovisueller Inhalte basieren oft auf kaskadierten Pipelines, die die Kosten erhöhen, Fehler akkumulieren und die Gesamtqualität beeinträchtigen. Obwohl Systeme wie Veo 3 und Sora 2 den Wert einer simultanen Generierung betonen, bringt die gemeinsame multimodale Modellierung einzigartige Herausforderungen hinsichtlich Architektur, Daten und Training mit sich. Zudem begrenzt die geschlossene Quelle bestehender Systeme den Fortschritt in der Forschung. In dieser Arbeit stellen wir MOVA (MOSS Video and Audio) vor, ein quelloffenes Modell, das hochwertige, synchronisierte audiovisuelle Inhalte erzeugen kann – inklusive realistischer Lippenbewegungen bei Sprache, umgebungssensibler Klangeffekte und inhaltsbasiertem Musikmaterial. MOVA nutzt eine Mixture-of-Experts-(MoE)-Architektur mit insgesamt 32 Milliarden Parametern, wobei während der Inferenz 18 Milliarden aktiv sind. Es unterstützt die IT2VA-Aufgabe (Image-Text zu Video-Audio). Durch die Veröffentlichung der Modellgewichte und des Quellcodes zielen wir darauf ab, die Forschung voranzutreiben und eine lebendige Community von Kreativen zu fördern. Der veröffentlichte Codebase bietet umfassende Unterstützung für effiziente Inferenz, LoRA-Feinabstimmung und Prompt-Optimierung.
One-sentence Summary
The SII-OpenMOSS Team introduces MOVA, an open-source 32B-parameter MoE model that generates synchronized audio-visual content with realistic lip-sync and environment-aware sounds, advancing joint multimodal generation beyond cascaded pipelines and enabling community-driven innovation via released code and weights.
Key Contributions
- MOVA addresses the gap in open-source audio-visual generation by introducing a jointly trained model that synthesizes synchronized video and audio, including lip-synced speech and environment-aware sound, overcoming the error accumulation and cost of cascaded pipelines.
- It employs an asymmetric dual-tower architecture with bidirectional cross-attention and a Mixture-of-Experts design (32B total, 18B active), enabling efficient, high-fidelity IT2VA generation while handling modality-specific challenges like information density disparity.
- The model demonstrates scalable performance improvements through a fine-grained audio-video annotation pipeline and released training infrastructure, supporting community research via open weights, LoRA fine-tuning, and prompt enhancement tools.
Introduction
The authors leverage the growing capabilities of diffusion-based video generation to tackle the underexplored challenge of synchronized audio-visual synthesis, where most prior systems either ignore audio or rely on error-prone cascaded pipelines. Existing joint models like Veo3 and Sora2 demonstrate feasibility but remain closed-source, while open alternatives suffer from limited scale, poor audio fidelity, or restricted modality fusion. MOVA addresses this by introducing a scalable 32B-parameter Mixture-of-Experts dual-tower architecture with bidirectional cross-attention, enabling high-quality lip-synced speech, environment-aware sound effects, and content-aligned music—all generated end-to-end from image-text prompts. By releasing weights, training code, and inference tools, the authors aim to democratize research and accelerate progress in synchronized multimodal generation.
Dataset

The authors use a carefully curated audio-visual dataset built from both public and in-house sources to train their video-audio generation model. Here’s how the data is composed, processed, and used:
-
Sources & Composition:
The dataset draws from filtered high-quality subsets of public datasets including VGGSound, AutoRe-Cap, ChronoMagic-Pro, ACAV-100M, OpenHumanVid, SpeakerVid-5M, and OpenVid-1M, supplemented by in-house recordings. Content spans diverse domains—education, sports, beauty, news, movies, vlogs, and animations—to ensure broad generalization. -
Key Subset Details:
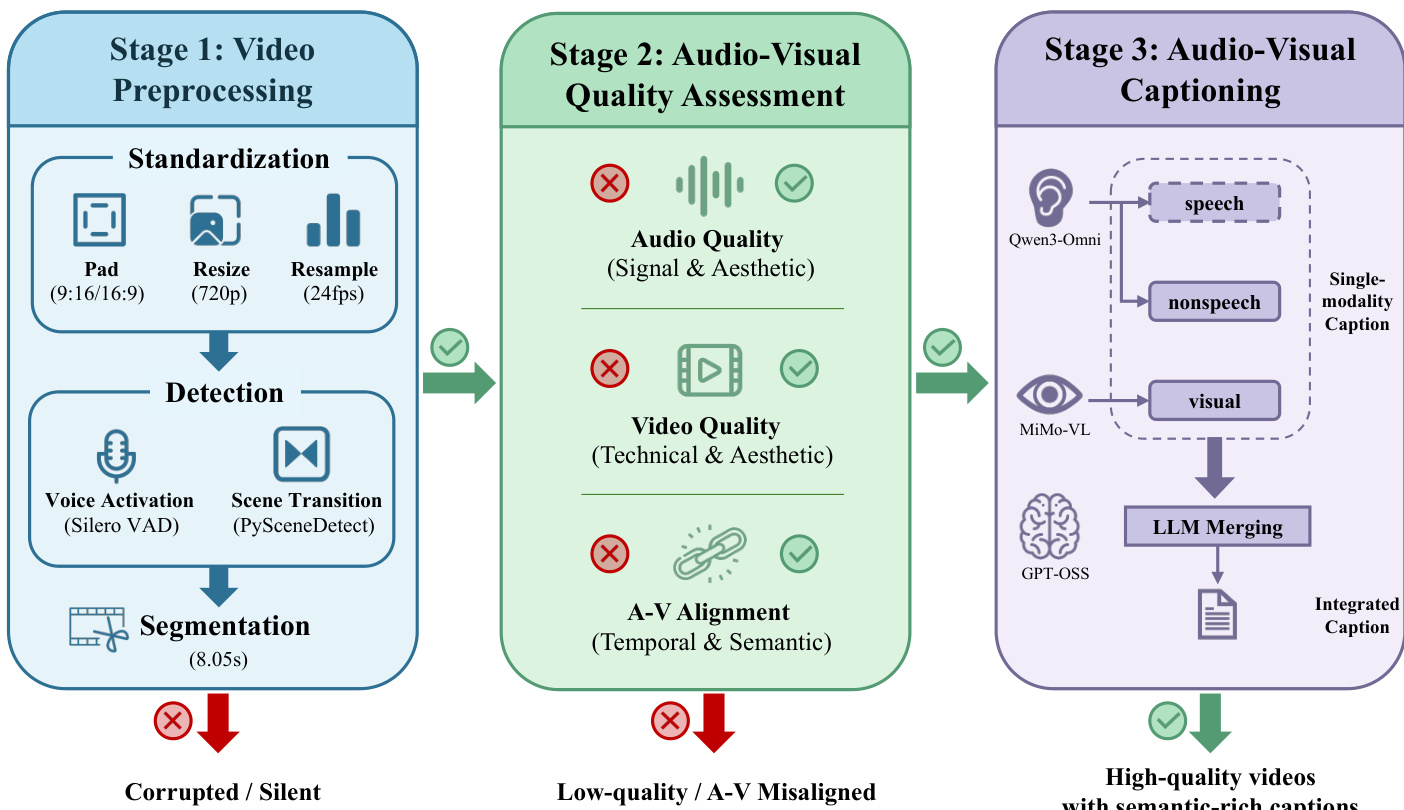
- All raw videos are preprocessed into fixed 8.05-second clips (193 frames at 24fps), resized to 720p, and normalized to 9:16 or 16:9 aspect ratios via cropping and padding.
- Only speech-containing segments (69.47% of preprocessed clips) are retained for training, identified using VAD and scene transition detection.
- Audio-visual quality is assessed using three filters:
- Audio: Silence ratio, bandwidth, and Audiobox-aesthetics scores.
- Video: DOVER tool for technical and aesthetic quality.
- Alignment: SynchFormer (temporal sync) and ImageBind (semantic sync); clips pass if IB-Score ≥ 0.2 OR DeSync ≤ 0.5.
- Speech-specific subsets use EAT classification to retain clips with confirmed speech or singing content.
-
Training Use & Processing:
- The final training set is a mixture of clips that passed all three pipeline stages: preprocessing, quality filtering, and multimodal captioning.
- Captions are generated separately for audio and visual content using Qwen3-Omni and MiMo-VL, then merged into unified, rich descriptions via GPT-OSS.
- Clips are used at 720p resolution with 24fps for model training; only speech segments are included to focus on lip-sync and dialogue generation.
-
Cropping & Metadata:
- Core visual content is centered and padded to standard aspect ratios using FFmpeg’s cropdetect.
- Segmentation metadata combines VAD and scene transition timestamps to generate four clip types—only speech-containing ones are selected.
- Metadata includes timestamps, scene boundaries, and audio classification tags to guide model conditioning and evaluation.
This pipeline ensures high-fidelity, semantically aligned, and temporally coherent training data optimized for joint video-audio generation.
Method
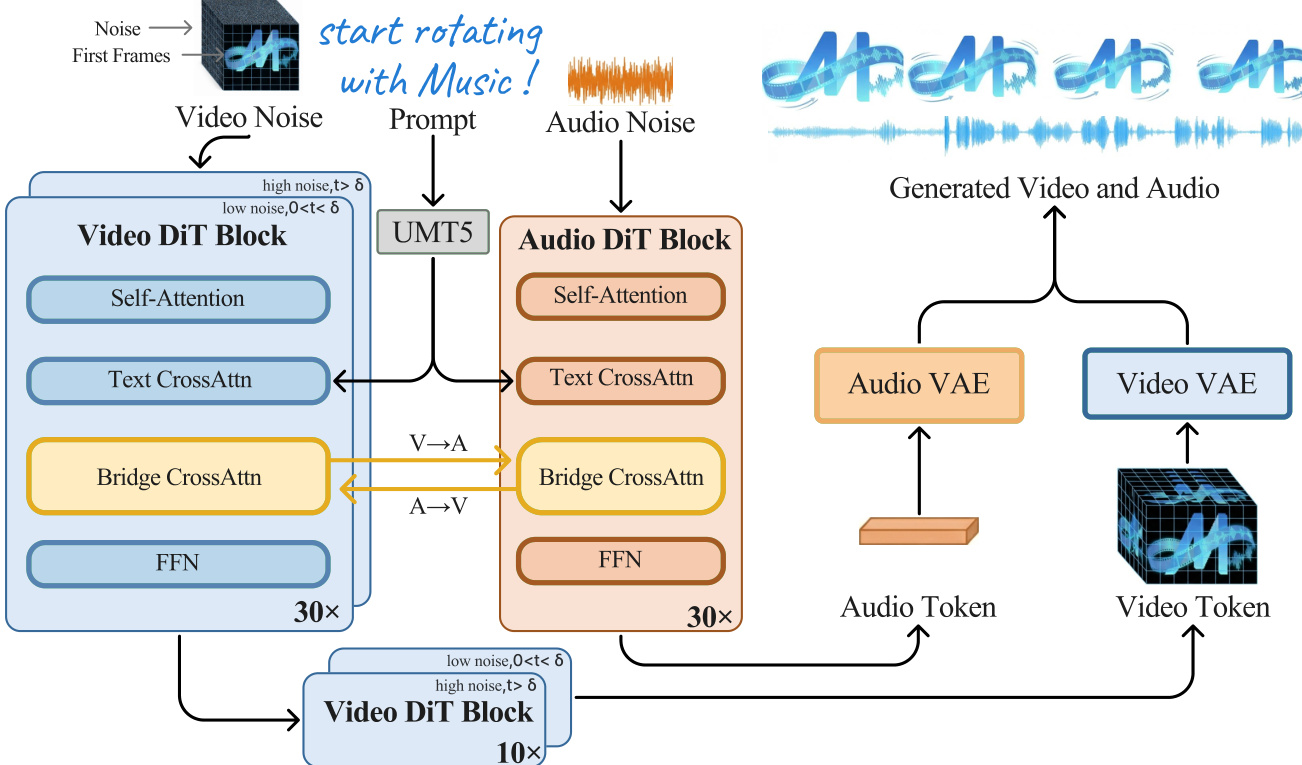
The authors leverage an asymmetric dual-tower architecture, MOVA, to enable synchronized video-audio generation by coupling a large video diffusion transformer with a smaller audio diffusion transformer via a bidirectional Bridge module. The overall framework operates in latent spaces defined by pretrained VAEs: the video VAE compresses input video into a spatiotemporal latent xv, while the audio VAE encodes the waveform into xa. Generation proceeds via flow matching, where at each timestep t∼U(0,1), noisy latents are constructed as xtv=(1−t)xv+tεv and xta=(1−t)xa+tεa, with εv,εa∼N(0,I). The model predicts the velocity fields v^θv and v^θa, targeting vtv=εv−xv and vta=εa−xa, optimized under the loss LFM=Et,c,xv,xa,ε[λv∥v^θv−vtv∥22+λa∥v^θa−vta∥22].
Refer to the framework diagram, which illustrates the core architecture: the video tower, based on the A14B Wan2.2 DiT, and the audio tower, a 1.3B DiT, are connected through a 2.6B Bridge module that enables bidirectional cross-attention. Each DiT block contains self-attention, text cross-attention, and feed-forward layers. The Bridge injects video hidden states into the audio DiT and vice versa, facilitating cross-modal interaction. To address the temporal misalignment between video and audio latents—video latents are temporally downsampled while audio latents are dense—the authors implement Aligned RoPE. This modifies the standard rotary positional encoding by scaling video token positions by the ratio s=fa/fv, mapping them onto the audio time grid: pη(i)=s⋅i and pα(j)=j. This ensures that tokens representing the same physical time are aligned, preserving translation invariance and preventing audio-visual drift.
The training pipeline is structured in two main stages. The first stage pretrains the audio tower independently on diverse audio data—including music, general sounds, and TTS—using a 1.3B DiT. The second stage performs joint training of the pretrained video tower, audio tower, and randomly initialized Bridge module. This joint training proceeds through three phases with progressively refined data and resolution: Phase 1 trains at 360p on 61,500 hours of diverse data with asymmetric sigma-shift values (shiftv=5.0, shifta=1.0) and aggressive text dropout (pdroptxt=0.5) to encourage Bridge-based alignment. Phase 2 refines the dataset to 37,600 hours of quality-filtered clips using OCR, lip-sync metrics (LSE-D ≤ 9.5, LSE-C ≥ 4.5), and DOVER technical scores (>0.15), aligns the audio sigma shift to 5.0 for improved timbre fidelity, and reduces text dropout to 0.2. Phase 3 upscales to 720p on 11,000 hours of highest-quality data (DOVER > 0.14), adjusting context parallelism from CP=8 to CP=16 to handle longer sequences.
As shown in the figure below, the joint training leverages heterogeneous learning rates: the Bridge module is optimized with ηbr=2×10−5, while the backbone towers use ηb=1×10−5, accelerating Bridge convergence without destabilizing pretrained priors. Additionally, the authors decouple the timestep sampling for video and audio, drawing tv and ta independently from U(0,1) and applying modality-specific noise schedules via σm(t)=shiftm+t(1−shiftm)shiftm⋅t. This allows independent control over denoising aggressiveness per modality, which is critical for audio timbre fidelity.
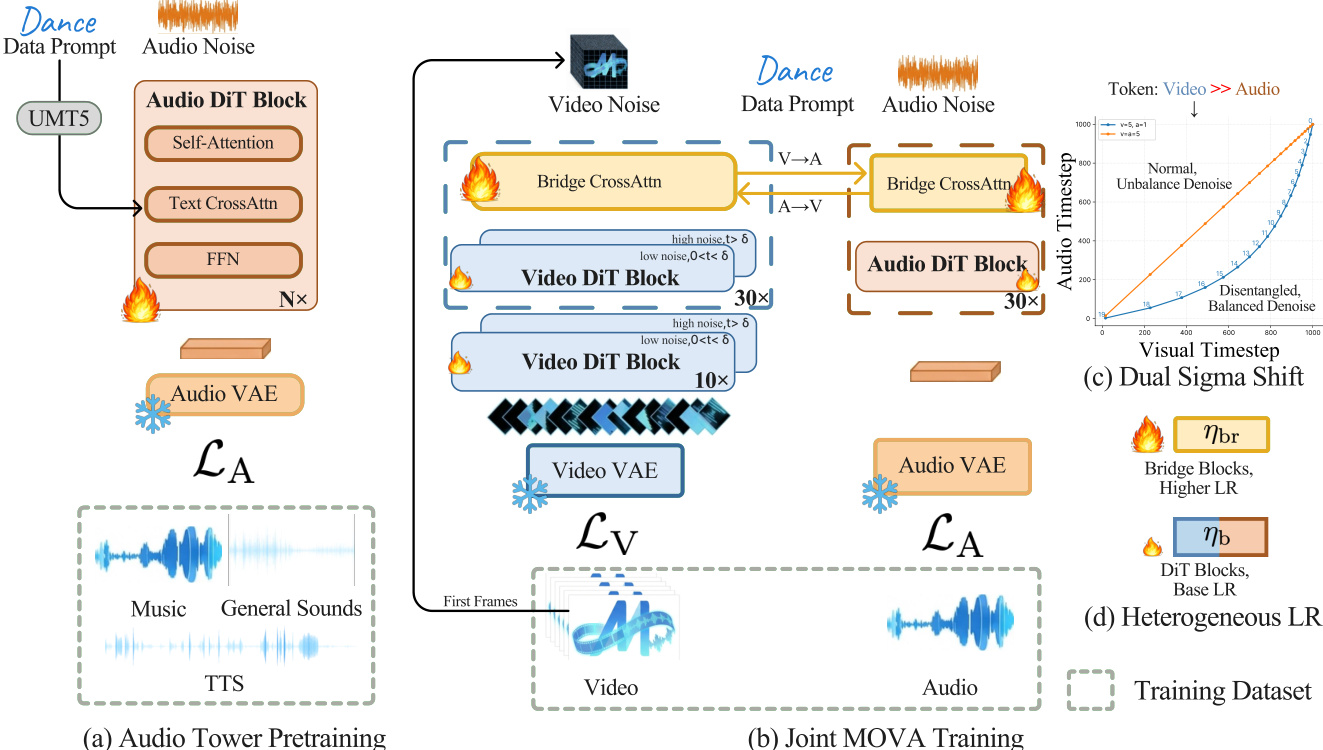
For inference, the authors implement a dual Classifier-Free Guidance (dual CFG) scheme to independently control text guidance and cross-modal alignment. The joint posterior is factorized as P(z∣cT,cB)∝P(cT∣cB,z)P(cB∣z)P(z), leading to a velocity prediction v~θ=vθ(zt,∅,∅)+sB⋅[vθ(zt,∅,cB)−vθ(zt,∅,∅)]+sT⋅[vθ(zt,cT,cB)−vθ(zt,∅,cB)]. By tuning sB and sT, users can trade off between alignment strength and perceptual quality. The general dual CFG requires three function evaluations per step (NFE=3), while special cases like text-only CFG (sB=1,sT=s) or text + modality CFG (sB=s,sT=s) reduce to NFE=2.
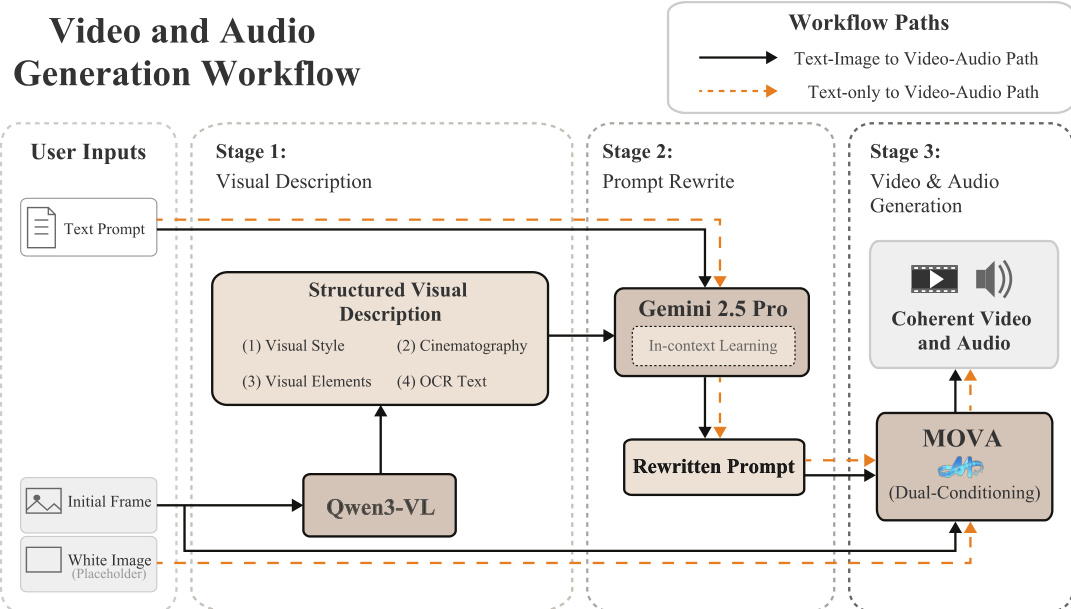
The generation workflow supports both text-image and text-only inputs. For text-image generation, the initial frame is processed by Qwen3-VL to extract a structured visual description covering style, cinematography, elements, and OCR text. This description is merged with the user prompt via an LLM (e.g., Gemini 2.5 Pro) using in-context learning to produce a rewritten prompt that aligns with the training data distribution. MOVA then generates video and audio using dual conditioning on the rewritten prompt and the initial frame. For text-only generation, a white placeholder image is used, enabling zero-shot synthesis.
To support large-scale training, the authors curate over 100,000 hours of bimodal data using a three-stage pipeline: preprocessing (standardization, voice activation, scene detection), quality assessment (audio, video, and A-V alignment filters), and captioning. For captioning, they employ MiMo-VL-7B-RL for video, Qwen3-Omni-Instruct for speech, and Qwen3-Omni-Captioner for non-speech audio, then merge these using GPT-OSS-120B with explicit rules to ensure coherence, avoid repetition, and anchor speech to visual context. This pipeline produces high-quality, semantically rich captions suitable for training.
Experiment
- Training efficiency is optimized via FSDP, sequence parallelism, and memory management, achieving ~35% MFU; VAE redundancy is reduced by preprocessing once per CP group and broadcasting features, with further gains on Ascend NPUs via operator fusion.
- MOVA outperforms baselines (LTX-2, Ovi, WAN2.1+MMAudio) in audio fidelity, speech clarity, and audio-visual alignment, particularly excelling in lip-sync precision and multi-speaker attribution, with dual CFG enhancing cross-modal binding at the cost of slight speech quality and instruction-following degradation.
- Scaling to 720p maintains strong cross-modal coherence and improves lip-sync and speaker attribution, validating staged training; dual CFG boosts alignment metrics but reduces speech naturalness and instruction adherence due to guidance imbalance.
- MOVA exhibits emergent T2VA capability, generating synchronized audio-visual content from text alone with high audio fidelity and temporal alignment, despite lacking visual conditioning.
- Human evaluations confirm MOVA’s superiority in preference and win rates, with prompt refinement significantly boosting performance; dual CFG improves objective alignment but slightly reduces subjective preference due to weakened text guidance.
- Lip-sync quality improves progressively through three training stages: initial bridging establishes alignment, refined noise schedules enhance consistency, and high-resolution scaling preserves synchronization while adding detail.
- Limitations include constrained audio modeling for music/singing, multi-speaker synchronization challenges due to data noise, and high computational cost from long sequence lengths, pointing to needed improvements in physical reasoning, supervision, and efficiency.
Results show that removing the reference image in MOVA-360p-T2VA leads to improved audio fidelity and temporal synchronization, as indicated by higher IS and lower DeSync scores, while slightly reducing lip-sync precision and multi-speaker attribution accuracy. This suggests the model can generate coherent audio-visual content from text alone, leveraging its internalized cross-modal priors even without visual conditioning.

The authors use a staged filtering process to refine training data, progressively reducing the retention ratio from raw video to Stage 2 by prioritizing speech content and removing nonspeech segments. Results show that speech-only data constitutes less than 60% of the initial dataset, and further curation in Stage 2 retains only about a quarter of the original material, indicating a strong focus on high-quality, speech-relevant samples for training. This selective filtering likely contributes to the model’s improved audio-visual alignment and lip-sync performance observed in later evaluations.

The authors use a 1.3B parameter model with 100 NFE steps, achieving a lower FID and higher IS than smaller models like TangoFLUX and AudioLDM2, indicating improved sample quality and diversity despite higher KL divergence. Results show that scaling model size and optimizing inference steps can enhance generative performance even when some alignment metrics degrade.

The authors use a three-phase training strategy to progressively scale resolution and refine cross-modal alignment, starting at 360p and advancing to 720p while adjusting hyperparameters like text dropout and audio normalization to stabilize learning. Results show that this staged approach enables the model to maintain strong audio-visual synchronization and lip-sync accuracy even at higher resolutions, without significant degradation in alignment metrics. The training duration and checkpoint intervals are adjusted per phase to accommodate the increasing complexity and data requirements of higher-resolution synthesis.

The authors measure training efficiency on 8× Ascend 910A2 devices using a configuration with CP=4 and DP-shard=2, achieving a step time of 34.1 seconds. The system consumes approximately 40 GB of VRAM per GPU and requires at least 128 GB of host RAM, operating at 376 TFLOPs in FP16 precision. These benchmarks reflect optimized memory management and operator fusion to reduce framework overhead during large-scale training.