Command Palette
Search for a command to run...
World-VLA-Loop: Closed-Loop-Lernen eines Video-Weltmodells und einer VLA-Politik
World-VLA-Loop: Closed-Loop-Lernen eines Video-Weltmodells und einer VLA-Politik
Xiaokang Liu Zechen Bai Hai Ci Kevin Yuchen Ma Mike Zheng Shou
Zusammenfassung
Neuere Fortschritte bei robotischen Weltmodellen haben Video-Diffusions-Transformern genutzt, um zukünftige Beobachtungen bedingt auf vergangene Zustände und Aktionen vorherzusagen. Obwohl diese Modelle realistische visuelle Ausgänge simulieren können, weisen sie oft eine geringe Präzision bei der Aktionen-Nachfolge auf, was ihre Anwendbarkeit für nachgeschaltete robotische Lernverfahren einschränkt. In dieser Arbeit stellen wir World-VLA-Loop vor, einen geschlossenen Regelkreis zur gemeinsamen Verbesserung von Weltmodellen und Vision-Sprache-Aktion (VLA)-Politiken. Wir entwickeln ein zustandsbewusstes Video-Weltmodell, das als hochgenauer interaktiver Simulator fungiert, indem es zukünftige Beobachtungen und Belohnungssignale gemeinsam vorhersagt. Zur Verbesserung der Zuverlässigkeit führen wir die SANS-Datenbank ein, die nahe-an-Erfolg-Trajektorien enthält, um die Ausrichtung von Aktion und Ergebnis innerhalb des Weltmodells zu verfeinern. Dieser Rahmen ermöglicht einen geschlossenen Regelkreis für die nachträgliche Verstärkungslernung (Reinforcement Learning, RL) von VLA-Politiken vollständig innerhalb einer virtuellen Umgebung. Entscheidend ist, dass unser Ansatz einen ko-evolvierenden Zyklus fördert: durch die VLA-Politik generierte Fehlversuche werden iterativ zurückgespeist, um die Genauigkeit des Weltmodells zu verbessern, was wiederum die nachfolgende RL-Optimierung verstärkt. Evaluierungen in Simulations- und realen Aufgaben zeigen, dass unser Framework die Leistung von VLA erheblich steigert, wobei nur minimale physische Interaktionen erforderlich sind, und so eine wechselseitig vorteilhafte Beziehung zwischen Weltmodellierung und Politiklernen für allgemeine Robotik etabliert. Projektseite: this https URL.
One-sentence Summary
Researchers from Show Lab propose World-VLA-Loop, a closed-loop framework co-optimizing video world models and VLA policies via iterative failure feedback, enhancing action-following precision with the SANS dataset, and enabling high-fidelity RL training in simulation for real-world robotics with 36.7% success rate gains.
Key Contributions
- We introduce World-VLA-Loop, a closed-loop framework that enables iterative co-evolution of world models and Vision-Language-Action policies, using failure rollouts from the policy to refine the model’s action-following precision and improve downstream RL performance.
- Our state-aware video world model achieves high-fidelity simulation by jointly predicting future observations and reward signals, trained on the SANS dataset of near-success trajectories to enhance action-outcome alignment and reduce hallucination of successful outcomes under erroneous actions.
- Evaluations on the LIBERO benchmark and real-world tasks show our framework boosts VLA success rates by 36.7% after two iterations while minimizing physical interaction, demonstrating its effectiveness in bridging simulation-to-reality gaps for general-purpose robotics.
Introduction
The authors leverage video-based world models to enable efficient reinforcement learning for Vision-Language-Action (VLA) policies, addressing the high cost and safety risks of real-world robot training. Prior world models suffer from imprecise action-following and unreliable reward signals, often hallucinating successful outcomes even with incorrect actions—making them unsuitable for RL. To overcome this, the authors introduce World-VLA-Loop, a closed-loop framework that jointly trains the world model and VLA policy: failure rollouts from the policy refine the model’s action-conditioned predictions, while the improved model enables more effective RL. They also introduce the SANS dataset with near-success trajectories to sharpen action-outcome alignment, resulting in a state-aware world model that predicts both video frames and rewards with higher fidelity. Evaluations show a 36.7% improvement in real-world success rates after just two iterations, reducing reliance on physical interaction.
Dataset

-
The authors use the Success and Near-Success Dataset (SANS) to train robust world models by including trajectories that nearly achieve goals but fail due to minor positioning errors—critical for capturing fine spatial dynamics and realistic failure modes encountered during policy execution.
-
SANS is curated across three sources: ManiSkill, LIBERO, and real-world robotic setups. In ManiSkill, success trajectories are collected via ground-truth pose–based policies, then perturbed to generate failures; additional failures come from policy rollouts. In LIBERO, failures are gathered using OpenVLA-OFT rollouts. Real-world data combines manual teleoperation and OpenVLA-OFT rollouts to capture plausible failures.
-
The dataset includes video-action pairs and sparse binary reward signals (indicating success at each step). For ManiSkill, the authors collect ~35k video-action pairs across 23 tasks, mixing successes and failures. For LIBERO and real-world settings, they collect ~50 success and 50 failure trajectories per task—smaller but sufficient for fine-tuning and transfer.
-
The authors pretrain their action-conditioned world model on the ManiSkill portion of SANS using joint video and reward supervision. The model is then fine-tuned on LIBERO and real-world subsets. The full pipeline cycles between dataset augmentation, world model pretraining, policy rollout via GRPO, and deployment—iteratively improving both model and policy.
Method
The authors leverage a four-phase framework to construct and deploy a state-aware video world model for vision-language-action (VLA) policy reinforcement learning. The overall architecture is designed to enable efficient adaptation to new tasks using minimal demonstrations while maintaining high-fidelity visual and reward prediction. Refer to the framework diagram for a high-level overview of the pipeline.
In Phase 1, the authors build the SANS (Success and Near-Success) dataset by collecting trajectories from both manual programming and policy rollouts. These trajectories encompass diverse execution outcomes, including full successes and near-successes, which are critical for training a world model that can distinguish subtle differences in task completion. The dataset serves as the foundation for subsequent model training and iterative refinement.
Phase 2 focuses on training the video world model, which is built atop the pretrained Cosmos-Predict 2 architecture. Given an initial sequence of observed frames x0,…,xh−1 and a sequence of robot actions a1,…,aT∈R6∪{0,1}, the model autoregressively generates future video frames xh,…,xh+T−1. The backbone employs a Diffusion Transformer (DiT), and action conditioning is achieved via an MLP-based action embedder that maps each 6 DoF pose and gripper state into a latent tensor. These embeddings are fused into the DiT by addition with the diffusion timestamp embeddings, enabling the model to ground visual predictions in the provided control sequence.
To enable intrinsic reward prediction, the authors augment the DiT with a lightweight MLP reward head ϕ that maps denoised latents zt to scalar rewards r^t=ϕ(zt). The model is trained with a joint loss combining the flow matching objective and reward prediction error:
L=Lflow+λt=1∑T∥r^t−rt∥2,where λ is modulated by the noise level following the EDM framework to stabilize training. This design ensures reward predictions are tightly coupled with visual outcomes, improving alignment with actual task success and encouraging the generator to better discriminate between successful and failed trajectories.
As shown in the figure below, the trained world model is then deployed in Phase 3 for VLA policy post-training. The authors adopt OpenVLA-OFT as the base policy and integrate it into the SimpleVLA-RL framework, replacing the conventional physics simulator with their learned video world model. The policy generates action chunks, which are fed into the world model to produce the next visual observation and reward signal. This closed-loop interaction enables multi-step rollouts entirely within the neural simulator. Policy updates are performed via GRPO optimization using advantages computed from the world model’s reward predictions.
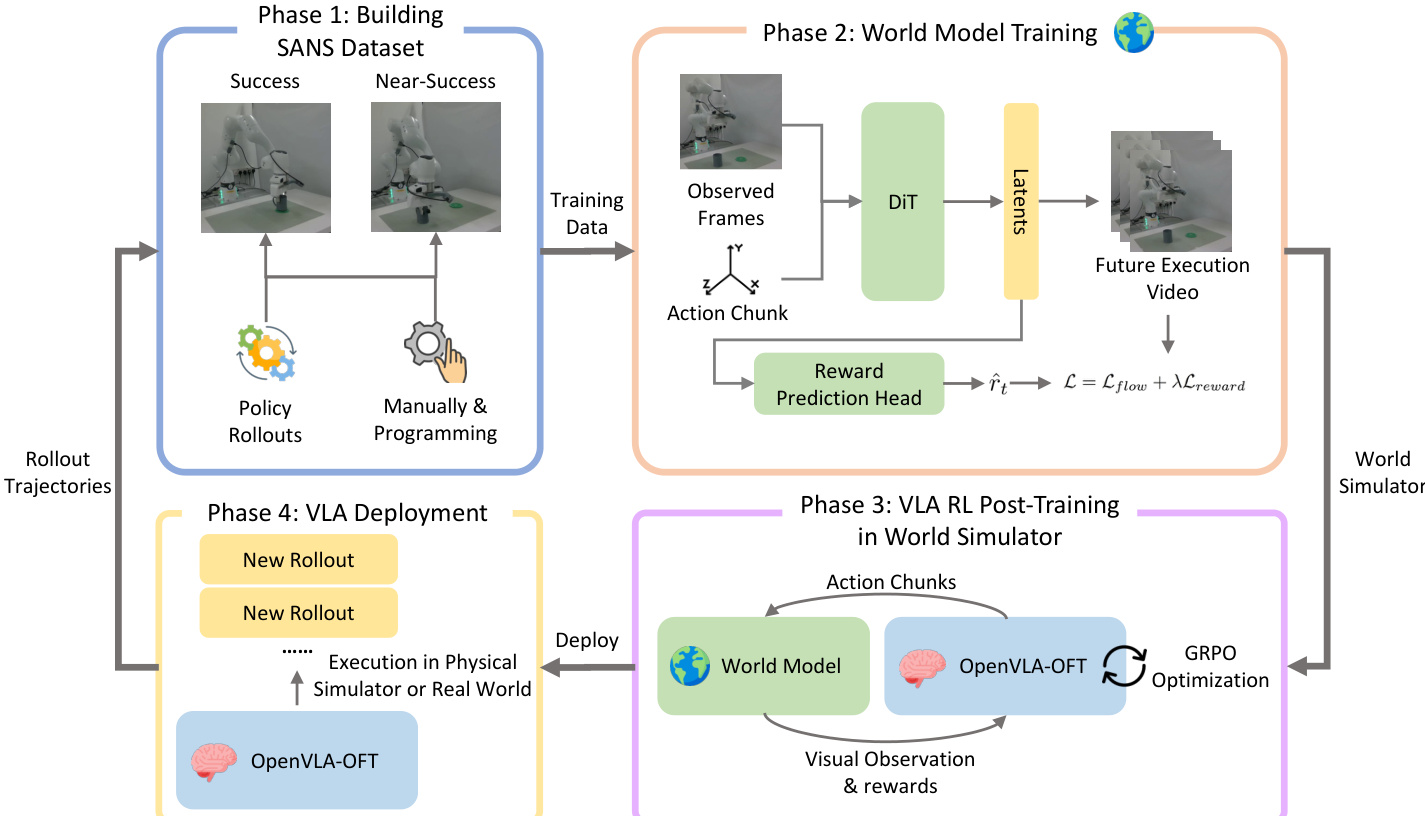
In Phase 4, the authors close the loop by deploying the refined policy in the real world or a physical simulator to collect new rollouts. These trajectories—particularly success and near-success cases—are added to the SANS dataset to further fine-tune the world model. This iterative refinement cycle enhances both the world model’s predictive fidelity and the policy’s performance. The authors demonstrate that this joint optimization leads to substantial gains: starting from a 13.3% success rate with supervised fine-tuning, iterative RL refinement boosts performance to 50.0% in real-world evaluations.
The entire system is implemented with a request-response architecture to support batched policy rollouts, enabling efficient training on high-end hardware. A batch of 24 video frames takes approximately 7 seconds on an NVIDIA H100, allowing full RL training for a task to complete within 30 hours. This scalable design ensures practical deployment while maintaining high visual and reward fidelity across diverse manipulation tasks.
Experiment
- The world model demonstrates high visual and reward alignment, confirming its reliability as a simulator for policy rollouts across simulated and real-world settings.
- RL post-training within the simulator significantly improves policy success rates on both LIBERO benchmarks and real-world tasks, validating the simulator’s utility for policy enhancement.
- Iterative refinement of the world model and policy leads to further gains in real-world accuracy, highlighting the value of joint optimization cycles.
- Ablation studies confirm that the integrated reward prediction head is critical for maintaining generation quality and outcome discrimination, outperforming external vision-language models in reliability.
- Including near-success trajectories during training is essential for modeling failure modes and improving action-outcome fidelity.
- Qualitative results show the world model generalizes to novel action sequences, accurately simulating physical consequences and distinguishing subtle success-failure boundaries, enabling more robust policy learning.
The authors use ablation experiments to show that excluding near-success data or removing the reward prediction head significantly degrades the world model’s visual and reward alignment performance. Their proposed method, which includes both components, achieves substantially higher alignment rates across tasks, demonstrating that joint training and diverse trajectory coverage are critical for accurate simulation. Results show the model’s internal reward head outperforms external vision-language models in predicting task outcomes, reinforcing its reliability for policy training.
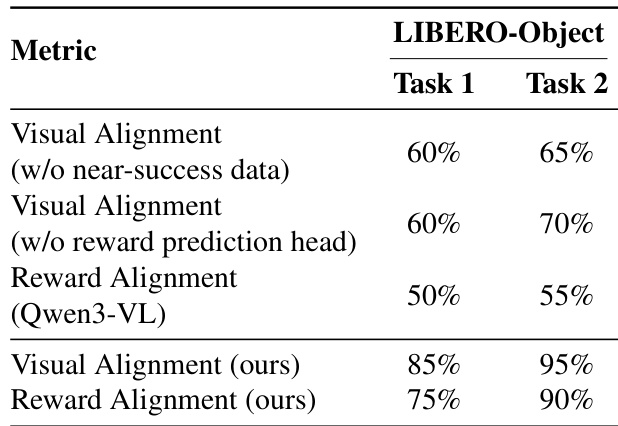
The authors use a world model to simulate robotic task execution and refine policies through reinforcement learning, achieving substantial gains over the baseline. Results show consistent success rate improvements across both simulated LIBERO benchmarks and real-world tasks, with the largest gains observed in real-world deployment. The iterative refinement process further enhances policy robustness by better modeling edge cases and failure modes.

The authors use a world model with a reward prediction head to generate high-fidelity visual rollouts, achieving over 85% visual and reward alignment across simulated and real-world tasks. Results show that joint training of the reward head and video generator significantly improves outcome discrimination and video quality compared to models without reward supervision. The model’s ability to generalize to novel action sequences and accurately simulate failure modes supports its use in refining VLA policies through iterative RL training.
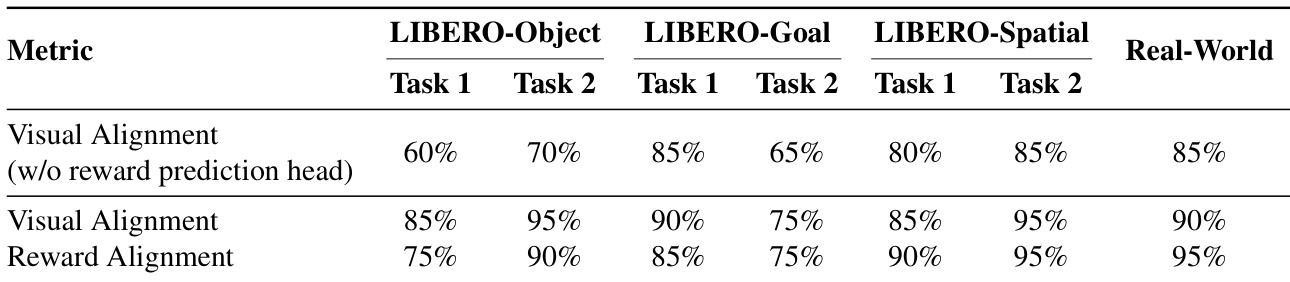
The authors use a world model to simulate robotic task outcomes, achieving high alignment between generated and actual visual and reward-based results across both simulated and real-world environments. Results show the model reliably distinguishes success from failure, with visual and reward alignment consistently exceeding 75% and often reaching 90% or higher. This fidelity supports effective policy training and refinement, enabling robust performance in diverse task settings.

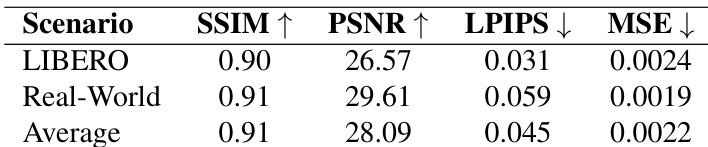
The authors use a world model to generate high-fidelity visual sequences for policy training, achieving strong video quality metrics across both simulated and real-world settings. Results show consistent performance between environments, with high SSIM and PSNR scores and low LPIPS and MSE values, indicating the model preserves structural and perceptual detail effectively. This visual reliability supports stable downstream policy learning and generalizes well beyond the training distribution.