Command Palette
Search for a command to run...
Context Forcing: Konsistente autoregressive Video-Generierung mit langem Kontext
Context Forcing: Konsistente autoregressive Video-Generierung mit langem Kontext
Shuo Chen Cong Wei Sun Sun Ping Nie Kai Zhou Ge Zhang Ming-Hsuan Yang Wenhu Chen
Zusammenfassung
Neuere Ansätze zur Echtzeit-Generierung langer Videos setzen typischerweise Streaming-Tuning-Strategien ein, bei denen ein lang-contextueller Schüler mittels eines kurz-contextuellen (gedächtnislosen) Lehrers trainiert wird. In diesen Rahmenwerken führt der Schüler längere Ausgaben aus, erhält jedoch nur Supervision von einem Lehrer, der auf kurze Zeitfenster von maximal 5 Sekunden beschränkt ist. Diese strukturelle Diskrepanz führt zu einer kritischen Lehrer-Schüler-Mismatch: Da der Lehrer aufgrund der begrenzten Sicht auf die langfristige Historie nicht in der Lage ist, den Schüler hinsichtlich globaler zeitlicher Abhängigkeiten zu leiten, wird die maximale Kontextlänge des Schülers effektiv begrenzt. Um dieses Problem zu lösen, stellen wir Context Forcing vor – ein neuartiges Framework, das einen lang-contextuellen Schüler mittels eines lang-contextuellen Lehrers trainiert. Durch die Gewährleistung, dass der Lehrer über die vollständige Generationsgeschichte verfügt, eliminieren wir die Supervisions-Mismatch und ermöglichen so eine robuste Ausbildung von Modellen, die eine langfristige Konsistenz aufweisen. Um diese Vorgehensweise rechnerisch auch für extrem lange Dauer (z. B. 2 Minuten) durchführbar zu machen, führen wir ein Kontext-Management-System ein, das den linear wachsenden Kontext in eine Slow-Fast-Memory-Architektur transformiert und somit die visuelle Redundanz erheblich reduziert. Ausführliche Experimente zeigen, dass unsere Methode effektive Kontextlängen von über 20 Sekunden ermöglicht – zwei bis zehn Mal länger als die der derzeitigen State-of-the-Art-Methoden wie LongLive und Infinite-RoPE. Durch die Nutzung dieses erweiterten Kontextes bewahrt Context Forcing eine überlegene Konsistenz über lange Zeiträume und übertrifft die derzeitigen Benchmark-Methoden in verschiedenen Evaluationsmetriken für lange Videos.
One-sentence Summary
Shuo Chen, Cong Wei, and colleagues from UC Merced and Tsinghua propose Context Forcing, a framework using long-context teachers to train students for 20s+ video generation, overcoming forgetting-drifting via Slow-Fast Memory, outperforming LongLive and Infinite-RoPE in long-term consistency.
Key Contributions
- We identify and resolve a critical student-teacher mismatch in long video generation, where short-context teachers fail to supervise long-context students on global temporal dependencies, by introducing Context Forcing—a framework that trains students using long-context teachers aware of full generation history.
- To enable computationally efficient training for extreme durations (e.g., 2 minutes), we design a Slow-Fast Memory architecture that compresses linearly growing context by reducing visual redundancy, allowing stable training and inference with 20+ seconds of effective context.
- Evaluated on long video benchmarks, Context Forcing achieves 2–10× longer usable context than state-of-the-art methods like LongLive and Infinite-RoPE, significantly improving long-term consistency and outperforming baselines on key temporal coherence metrics.
Introduction
The authors leverage causal video diffusion models to tackle the challenge of generating long, temporally consistent videos—critical for applications like digital storytelling and professional editing—where prior methods suffer from either forgetting past context or drifting due to error accumulation. Existing approaches rely on short-context teachers to train long-context students, creating a mismatch that limits learnable temporal dependencies and forces a trade-off between memory and stability. Their main contribution is Context Forcing, a framework that trains a long-context student using a long-context teacher, eliminating this mismatch and enabling robust generation over 20+ seconds via a Slow-Fast Memory architecture that compresses redundant visual information while preserving global coherence.
Method
The authors leverage a two-stage curriculum within a causal autoregressive framework to train a long-context video diffusion model capable of maintaining temporal consistency over extended durations. The overall objective is to minimize the global KL divergence between the student’s induced distribution pθ(X1:N) and the real data distribution pdata(X1:N), where N spans tens to hundreds of seconds. Direct optimization of this global objective is computationally infeasible, so the authors decompose it into local dynamics Llocal and global continuation dynamics Lcontext, enabling a tractable, staged training procedure.
In Stage 1, the student is warmed up by minimizing Llocal, which aligns the distribution of short video windows X1:k (typically 1–5 seconds) with a high-quality teacher distribution pT(X1:k). This is achieved via Distribution Matching Distillation (DMD), where gradients are estimated using score matching between the student and teacher models on diffused versions of generated frames. This stage ensures the student generates high-fidelity short sequences, providing stable context for the subsequent stage.
Stage 2 targets Lcontext, which enforces alignment between the student’s continuation pθ(Xk+1:N∣X1:k) and the true data continuation pdata(Xk+1:N∣X1:k). Since the true data continuation is inaccessible for arbitrary student-generated contexts, the authors introduce a pretrained Context Teacher T that provides a reliable proxy pT(Xk+1:N∣X1:k). This is justified under two assumptions: (1) the teacher remains accurate when conditioned on contexts near the real data manifold, and (2) Stage 1 ensures the student’s rollouts remain within this reliable region. The resulting Contextual DMD (CDMD) objective is optimized using a conditional score-based gradient estimator, where both student and teacher scores are computed on the same student-generated context, mitigating exposure bias.
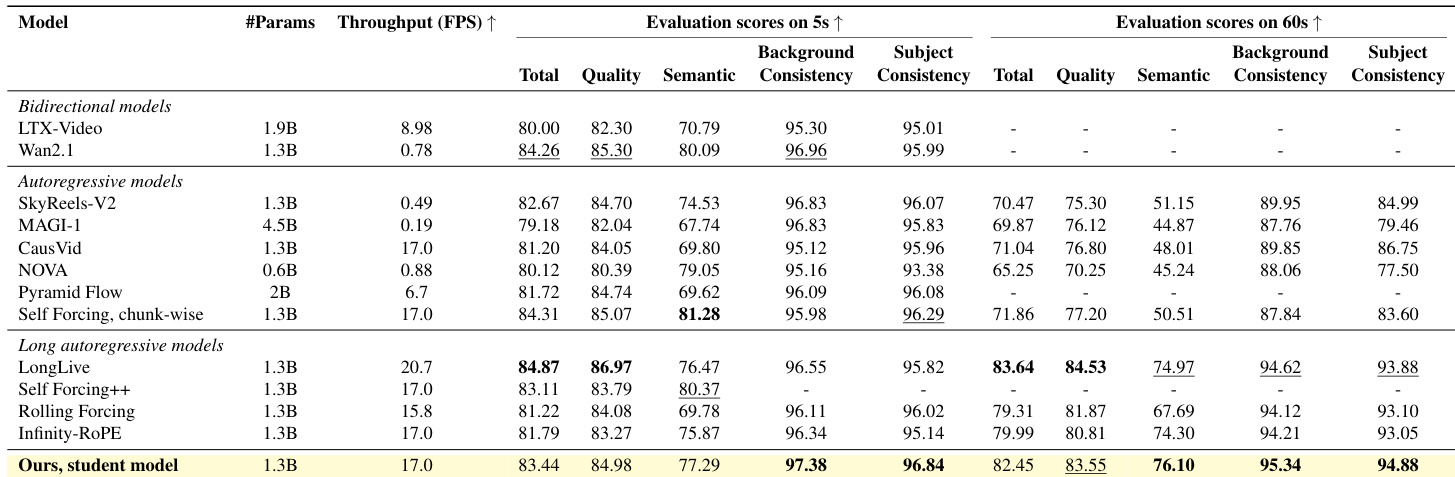
To handle the computational burden of long contexts, the authors design a Context Management System that organizes the KV cache into three functional components: an Attention Sink, Slow Memory, and Fast Memory. The Attention Sink retains initial tokens to stabilize attention, while Fast Memory acts as a rolling FIFO queue for immediate local context. Slow Memory stores high-entropy keyframes selected via a surprisal-based consolidation policy: a new token xt is promoted to Slow Memory if the similarity between its key vector kt and the preceding key kt−1 falls below a threshold τ, ensuring only salient temporal transitions are retained. This architecture enables efficient context retention without linear growth in memory or attention cost.
Refer to the framework diagram, which illustrates the evolution from short-context to long-context training with memory management. The diagram shows how the student progressively learns to generate longer sequences by leveraging the teacher’s supervision and the structured memory system. The memory components are dynamically updated: Fast Memory slides through recent frames, while Slow Memory compresses salient events into a fixed-size buffer. Bounded positional encoding is applied to all tokens, constraining their RoPE indices to a fixed range regardless of generation step, thereby stabilizing attention over long sequences.
The training process further incorporates a Long Self-Rollout Curriculum, where the context horizon k grows linearly with training steps to gradually expose the model to long-range dependencies. A Clean Context Policy ensures that context frames X1:k are fully denoised, while target frames Xk+1:N are supervised via random timestep selection, preserving gradient coverage across all diffusion steps. To enhance the robustness of the Context Teacher, the authors employ Error-Recycling Fine-Tuning, injecting realistic accumulated errors into the teacher’s context during training to ensure it can correct for student drift during inference.
Experiment
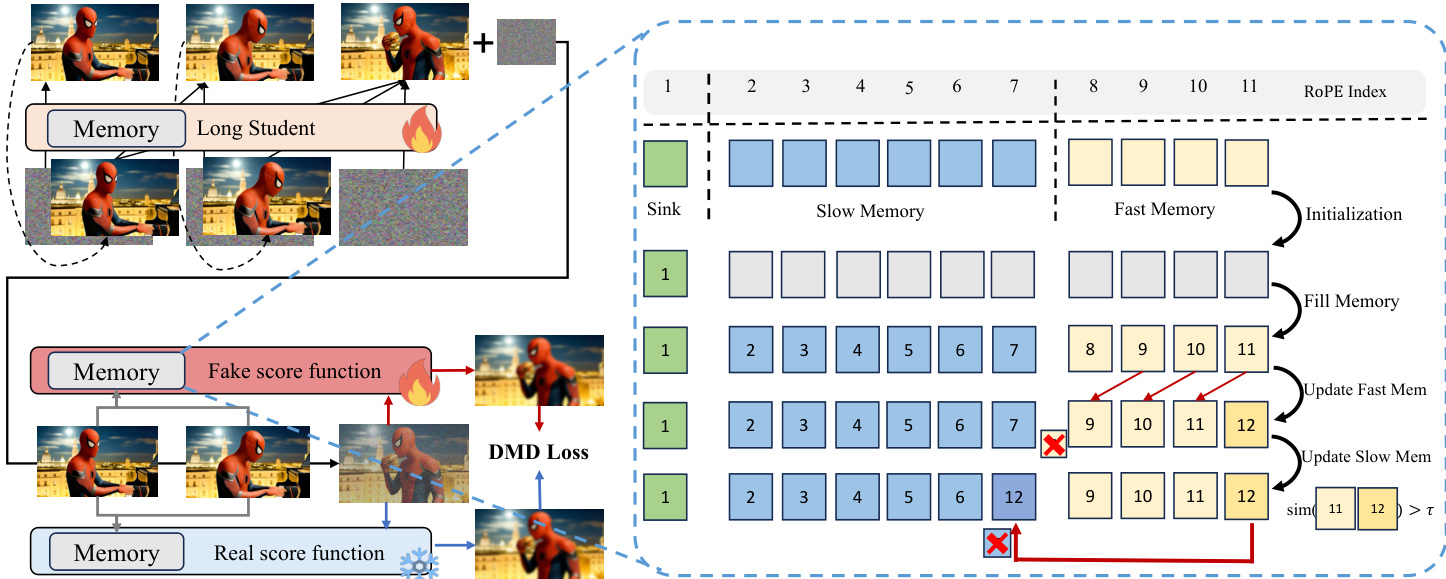
- The robust context teacher successfully generates coherent video continuations from student-generated contexts, validating its ability to maintain long-term consistency across 10-second sequences.
- The method achieves competitive performance on short video generation (5s) while significantly outperforming baselines in 60-second generation, particularly in preserving subject and background consistency over extended durations.
- Ablation studies confirm that similarity-based slow memory sampling, Context DMD distillation, and bounded positional encoding are each critical for maintaining semantic and temporal coherence in long videos.
- Error-Recycling Fine-Tuning enhances the context teacher’s robustness to accumulated generation errors, leading to cleaner rollouts and improved distillation quality.
- Compared to LongLive and other long-video baselines, the proposed method avoids abrupt scene resets and cyclic motion artifacts, demonstrating superior qualitative stability despite comparable quantitative scores.
The authors evaluate ablation components of their video generation system, showing that their full method outperforms variants lacking key mechanisms like contextual distillation or bounded positional encoding. Results indicate that similarity-based slow memory sampling and bounded positional encoding significantly improve background and subject consistency over long sequences. The full model achieves the highest overall score, confirming the combined effectiveness of its architectural choices in maintaining temporal coherence.

The authors use a robust context teacher and student framework to generate long videos, achieving high consistency across 60-second sequences as measured by DINOv2, CLIP-F, and CLIP-T scores. Results show their method outperforms baselines like FramePack, LongLive, and Infinity-RoPE in maintaining subject and background stability over time, particularly beyond 20 seconds. Ablation studies confirm that key components—including similarity-based memory sampling, context distillation, and bounded positional encoding—are critical to sustaining long-term coherence.

The authors use a two-stage training approach with a robust context teacher to enable long video generation, achieving high consistency in both short and extended sequences. Results show their student model outperforms most baselines in background and subject consistency for 60-second videos, particularly excelling in maintaining stable semantics and structure over time. Ablation studies confirm that key components like similarity-based memory sampling and bounded positional encoding are critical for sustaining long-term coherence.