Command Palette
Search for a command to run...
3D-empfundene implizite Bewegungssteuerung für ansichtsadaptive Generierung menschlicher Videos
3D-empfundene implizite Bewegungssteuerung für ansichtsadaptive Generierung menschlicher Videos
Zhixue Fang Xu He Songlin Tang Haoxian Zhang Qingfeng Li Xiaoqiang Liu Pengfei Wan Kun Gai
Zusammenfassung
Bekannte Methoden zur Steuerung menschlicher Bewegungen in der Videogenerierung basieren typischerweise entweder auf 2D-Posen oder expliziten 3D-parametrischen Modellen (z. B. SMPL) als Steuersignale. Allerdings binden 2D-Posen die Bewegung fest an die Perspektive des Treiberbildes und verhindern die Synthese neuer Ansichten. Explizite 3D-Modelle sind zwar strukturell informativ, leiden jedoch unter inhärenten Ungenauigkeiten (z. B. Tiefenambiguität und ungenaue Dynamik), die, wenn sie als starke Einschränkung verwendet werden, die starke intrinsische 3D-Wahrnehmung großer Videogeneratoren überlagern. In dieser Arbeit betrachten wir die Bewegungssteuerung aus einer 3D-orientierten Perspektive neu und plädieren für eine implizite, ansichtsunabhängige Bewegungsrepräsentation, die sich natürlich an die räumlichen Vorwissen des Generators anpasst, anstatt auf extern rekonstruierte Einschränkungen angewiesen zu sein. Wir stellen 3DiMo vor, das gemeinsam einen Bewegungs-Encoder mit einem vortrainierten Videogenerator trainiert, um Treiberframes in kompakte, ansichtsunabhängige Bewegungstoken zu komprimieren, die semantisch über Kreuz-Attention injiziert werden. Um die 3D-Wahrnehmung zu fördern, trainieren wir mit reichhaltiger Ansichts-Supervision (d. h. Einzelansicht-, Mehransicht- und bewegte-Kamera-Videos), was die Bewegungskonsistenz über verschiedene Perspektiven erzwingt. Zusätzlich nutzen wir ergänzende geometrische Supervision, bei der SMPL lediglich zur frühen Initialisierung dient und allmählich auf null abgekühlt wird, wodurch das Modell von externer 3D-Anleitung auf die eigentliche 3D-raumliche Bewegungsverstehensfähigkeit aus den Daten und den Vorwissen des Generators übergeht. Experimente bestätigen, dass 3DiMo die Treiberbewegungen präzise reproduziert und dabei eine flexible, textgesteuerte Kamera-Steuerung ermöglicht, wobei es bestehende Methoden sowohl hinsichtlich der Bewegungstreuheit als auch der visuellen Qualität erheblich übertrifft.
One-sentence Summary
Researchers from Kuaishou Technology, Tsinghua University, and CASIA propose 3DiMo, a view-agnostic motion representation that enables faithful 3D motion reproduction from 2D videos via text-guided camera control, outperforming prior methods by aligning with generator priors rather than relying on rigid 3D models.
Key Contributions
- 3DiMo introduces a 3D-aware motion control framework that extracts implicit, view-agnostic motion tokens from 2D driving videos, enabling novel-view synthesis and text-guided camera control without rigid geometric constraints from external 3D models.
- The method jointly trains a motion encoder with a pretrained video generator using view-rich supervision—including single-view, multi-view, and moving-camera videos—to enforce motion consistency across viewpoints and align with the generator’s intrinsic spatial priors.
- Auxiliary geometric supervision from SMPL is used only during early training and gradually annealed to zero, allowing the model to transition from external guidance to learning genuine 3D motion understanding, resulting in state-of-the-art motion fidelity and visual quality on benchmark tasks.
Introduction
The authors leverage large-scale video generators’ inherent 3D spatial awareness to rethink human motion control, moving beyond rigid 2D pose conditioning or error-prone explicit 3D models like SMPL. Prior methods either lock motion to the driving viewpoint or impose inaccurate 3D constraints that override the generator’s native priors, limiting viewpoint flexibility and motion fidelity. Their main contribution is 3DiMo, an end-to-end framework that learns implicit, view-agnostic motion tokens from 2D driving frames via a Transformer encoder, injected through cross-attention to align with the generator’s spatial understanding. Training uses view-rich supervision—single-view, multi-view, and moving-camera videos—plus an annealed auxiliary loss tied to SMPL for early geometric guidance, enabling the model to transition toward genuine 3D motion reasoning. This yields high-fidelity, text-guided camera control while preserving 3D consistency across views.
Dataset

- The authors construct a view-rich 3D-aware dataset combining three sources: large-scale internet videos for expressive motion diversity, synthetic UE5-rendered sequences for precise camera motion control, and real-world multi-view captures (including proprietary recordings) for authentic 3D supervision.
- Internet videos dominate in volume and train expressive motion dynamics under single-view reconstruction; synthetic and real multi-view data are smaller but critical for enforcing 3D consistency via cross-view motion reproduction and moving-camera supervision.
- Text prompts for camera viewpoints and movements are generated using Qwen2.5-VL, unifying annotations across all data types for text-guided camera control.
- Training follows a three-stage progressive strategy: Stage 1 uses only single-view reconstruction for stable motion initialization; Stage 2 mixes reconstruction and cross-view reproduction to transition toward 3D semantics; Stage 3 focuses entirely on multi-view and camera-motion data to strengthen view-agnostic motion features.
- Reference images are taken from the first frame of the target video to align generated motion with subject orientation, avoiding explicit camera alignment or SMPL regression.
- Auxiliary geometric supervision is introduced early via a lightweight MLP decoder predicting SMPL/MANO pose parameters (excluding global root orientation) to stabilize training and initialize motion representations; this supervision is gradually annealed and removed by Stage 3.
- Proprietary real-world captures use a three-camera array with randomized camera motions—including static, linear, zoom, and complex trajectories—paired with identical human motions to maximize view-agnostic learning signals.
Method
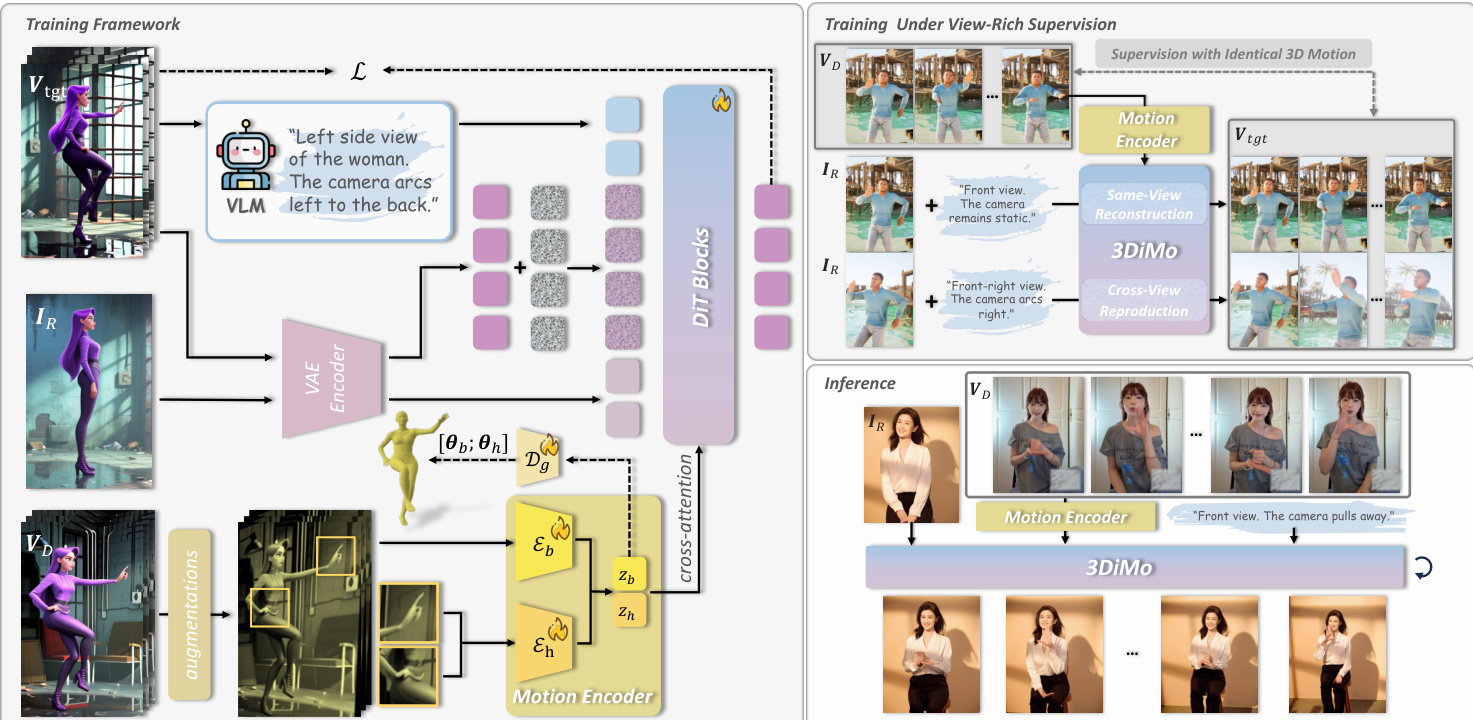
The authors leverage a pretrained DiT-based video generation model as the backbone, which is conditioned on a reference image, a driving video, and a text prompt to synthesize a target video that reenacts the driving motion while preserving text-guided camera control. The core innovation lies in the design of an implicit motion encoder, trained end-to-end with the generator, that extracts view-agnostic motion representations from 2D driving frames and injects them via cross-attention to enable semantically coherent motion transfer.
Refer to the framework diagram, which illustrates the full pipeline. The motion encoder consists of two specialized components: a body encoder Eb and a hand encoder Eh, each designed to capture coarse body motion and fine hand dynamics, respectively. Driving frames are first augmented with random perspective transformations and appearance perturbations to encourage the encoder to discard view-specific and identity-dependent cues. Each frame is patchified into visual tokens and concatenated with a fixed number K of learnable latent tokens. After several attention layers, only the latent tokens are retained as the motion representation zb and zh, forming a semantic bottleneck that strips away 2D structural information while preserving the intrinsic 3D motion semantics.
These motion tokens are then concatenated and injected into the DiT generator via cross-attention layers appended after each full self-attention block. This design allows motion tokens to interact semantically with video tokens without imposing rigid spatial alignment constraints, enabling flexible coexistence with the generator’s native text-driven camera control. The text prompt, which may include camera movement instructions, is processed through the same self-attention mechanism as the visual tokens, allowing joint control over motion and viewpoint.
To endow the motion representations with 3D awareness, the authors introduce early-stage geometric supervision using parametric human models (SMPL for body, MANO for hands). During training, auxiliary decoders regress the motion tokens to external 3D pose parameters θb and θh, providing geometric alignment signals that accelerate spatial understanding. The framework is trained on a view-rich dataset that includes single-view, multi-view, and camera-motion sequences, enabling the model to learn cross-view motion consistency and genuine 3D motion priors. Training alternates between same-view reconstruction and cross-view motion reproduction tasks, reinforcing the emergence of expressive, 3D-aware motion representations.
At inference, the motion encoder directly processes 2D driving frames to extract motion tokens, which are then used to animate any reference subject under arbitrary text-guided camera trajectories. This eliminates the need for external pose estimation or explicit 3D reconstruction, enabling high-fidelity, view-adaptive motion-controlled video generation.
Experiment
- 3DiMo outperforms state-of-the-art 2D and 3D methods in motion control and visual fidelity, particularly in LPIPS, FID, and FVD, demonstrating superior 3D-aware reenactment despite slightly lower PSNR/SSIM due to intentional geometric consistency over pixel alignment.
- Qualitative results show 3DiMo produces physically plausible, depth-accurate motions, avoiding limb ordering errors common in 2D methods and pose inaccuracies in SMPL-based approaches, especially under dynamic camera prompts.
- User studies confirm 3DiMo excels in motion naturalness and 3D plausibility, validating its learned motion representation better captures spatial and dynamic realism than parametric or 2D alignment methods.
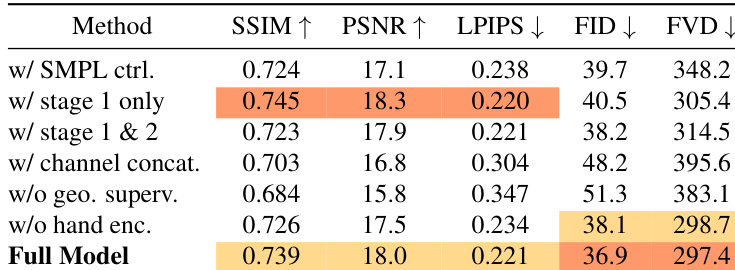
- Ablation studies reveal that implicit motion representation, multi-stage view-rich training, cross-attention conditioning, and auxiliary geometric supervision are critical for stable training and 3D-aware control; removing them degrades quality or causes collapse.
- The model enables novel applications: single-image human novel view synthesis with stable subject rendering, video stabilization by enforcing static camera prompts, and automatic motion-image alignment via view-agnostic motion transfer without manual calibration.
The authors evaluate ablation variants of their model and find that removing key components such as geometric supervision, hand motion encoding, or using channel concatenation instead of cross-attention consistently degrades performance. The full model achieves the best balance across metrics, particularly in FID and FVD, indicating superior visual fidelity and motion coherence. Results confirm that multi-stage training with view-rich data and auxiliary supervision is essential for stable learning and 3D-aware motion control.
The authors use a 3D-aware implicit motion representation to achieve superior motion control and visual fidelity compared to both 2D pose-based and SMPL-based baselines. Results show their method outperforms others in perceptual metrics and user studies, particularly in motion naturalness and 3D plausibility, despite slightly lower pixel-wise scores due to enforced geometric consistency. Ablation studies confirm that multi-stage view-rich training and cross-attention conditioning are critical for stable, high-fidelity 3D motion synthesis.
