Command Palette
Search for a command to run...
Zur Entropiedynamik bei der Verstärkungsfine-Tuning großer Sprachmodelle
Zur Entropiedynamik bei der Verstärkungsfine-Tuning großer Sprachmodelle
Shumin Wang Yuexiang Xie Wenhao Zhang Yuchang Sun Yanxi Chen Yaliang Li Yanyong Zhang
Zusammenfassung
Die Entropie dient als entscheidender Metrik zur Messung der Vielfalt der Ausgaben, die von großen Sprachmodellen (LLMs) generiert werden, und liefert wertvolle Einblicke in deren Fähigkeit zur Exploration. Während in jüngsten Studien zunehmend darauf abgezielt wird, die Entropie zu überwachen und anzupassen, um ein besseres Gleichgewicht zwischen Exploration und Exploitation im Rahmen der Verstärkungsfine-Tuning (RFT) zu erreichen, fehlt bisher ein fundiertes, theoretisches Verständnis der Entropiedynamik während dieses Prozesses. In diesem Paper stellen wir einen theoretischen Rahmen zur Analyse der Entropiedynamik im Verlauf des RFT-Prozesses vor, der mit einer diskriminierenden Darstellung beginnt, die die Änderung der Entropie unter einer einzelnen Logit-Update-Operation quantifiziert. Diese Grundlage ermöglicht die Ableitung einer ersten Ordnung der Entropieänderung, die weiterhin auf die Aktualisierungsformel des Group Relative Policy Optimization (GRPO) erweitert werden kann. Die daraus abgeleiteten Korollare und Erkenntnisse inspirieren die Entwicklung von Entropie-Kontrollmethoden und bieten zudem eine einheitliche Perspektive zur Interpretation verschiedener entropiebasierter Ansätze in vorliegenden Studien. Wir liefern empirische Belege, um die zentralen Schlussfolgerungen unserer Analyse zu stützen, und demonstrieren die Wirksamkeit der abgeleiteten Entropie-Diskriminatoren-Abschneidungsverfahren. Diese Studie liefert neue Erkenntnisse über die Trainingsdynamik im RFT-Prozess und bietet sowohl theoretische Fundierung als auch praktische Strategien zur Optimierung des Gleichgewichts zwischen Exploration und Exploitation bei der Fine-Tuning von LLMs.
One-sentence Summary
Shumin Wang and Yanyong Zhang (Tsinghua) with collaborators propose a theoretical framework for entropy dynamics in LLM reinforcement fine-tuning, deriving a first-order entropy update formula applicable to GRPO, enabling novel entropy control methods that improve exploration-exploitation balance with empirical validation.
Key Contributions
- We introduce a theoretical framework that quantifies entropy change at the token level during reinforcement fine-tuning, deriving a first-order expression extendable to Group Relative Policy Optimization (GRPO), revealing that entropy dynamics depend on token update direction and a discriminator score S⋆.
- Our analysis provides a unified interpretation of existing entropy-based methods and inspires new entropy control strategies, including clipping techniques grounded in the discriminant S⋆, offering principled guidance for balancing exploration and exploitation.
- Empirical results validate our theoretical predictions, demonstrating that S⋆ reliably indicates entropy trends and that our clipping methods effectively stabilize entropy during RFT, improving model exploration without compromising performance.
Introduction
The authors leverage entropy as a diagnostic tool to understand and control exploration-exploitation trade-offs during reinforcement fine-tuning (RFT) of large language models. While prior entropy-based methods often rely on heuristics and lack theoretical grounding—leading to inconsistent strategies and costly hyperparameter tuning—the authors derive a principled framework that quantifies how single-token logit updates propagate to entropy changes. They extend this to GRPO, revealing that entropy dynamics depend on the interplay between token probability, update direction, and policy entropy, which explains common entropy collapse. Their framework enables practical entropy clipping strategies and unifies the interpretation of existing entropy-based techniques.
Dataset
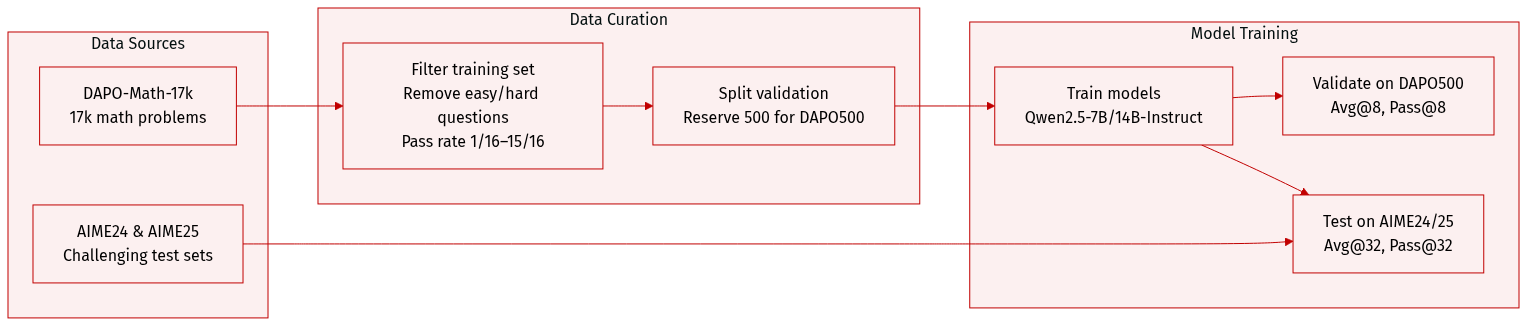
- The authors use DAPO-Math-17k (Yu et al., 2025) as the primary training dataset, selecting 17,000 math problems for fine-tuning Qwen2.5-7B-Instruct and Qwen2.5-14B-Instruct models.
- From DAPO-Math-17k, they reserve 500 questions as a validation set (DAPO500), following prior work (Lightman et al., 2023).
- They filter training samples by excluding those with pass rates ≤ 1/16 or ≥ 15/16 when evaluated by Qwen2.5-7B-Instruct, ensuring moderate difficulty for effective training.
- For testing, they use AIME24 and AIME25 — two challenging math datasets — and evaluate using Avg@32 and Pass@32 metrics.
- For DAPO500 validation, they use Avg@8 and Pass@8 metrics, where Avg@K is the mean accuracy across K responses per question, and Pass@K is the probability that at least one of K responses is correct.
Method
The authors leverage a theoretical framework to characterize token-level entropy dynamics during policy optimization in Reinforcement Fine-Tuning (RFT), with a focus on Group Relative Policy Optimization (GRPO). Their analysis begins at the microscopic level—examining how a single token update alters the entropy of the next-token distribution—and extends to the full GRPO optimization step, enabling principled control over entropy evolution during training.
At the core of their method is the entropy discriminator score S∗t, defined for a token ak sampled at position t as S∗t=pkt(Ht+logpkt), where pkt is the token’s probability under the current policy and Ht is the entropy of the full token distribution at that step. This score serves as a first-order predictor of entropy change: a positive update (reward) to a token increases entropy if S∗t<0 (i.e., the token is relatively low-probability) and decreases entropy if S∗t>0 (i.e., the token is high-probability). This relationship is derived from a Taylor expansion of entropy under a logit perturbation δz=ε⋅ek, yielding ΔH=−εS∗+O(ε2).
Extending this to GRPO, the authors model the entropy change induced by a full optimization step. Under GRPO, each token’s update is governed by a surrogate loss L(z)=r⋅A⋅logpk(z), where r is the importance ratio and A is the advantage. A gradient step with learning rate η induces a logit update δz=α(ek−p), where α=ηrA. Substituting this into the entropy gradient yields the key result: the first-order entropy change is ΔH=−α(S∗−Ei∼p[Si])+O(α2). This reveals that entropy change is not determined by S∗ alone, but by its deviation from the policy-weighted expectation Ei∼p[Si], which acts as a dynamic baseline. This baseline ensures that, under on-policy sampling, the expected entropy change across the vocabulary or batch is zero—a property formalized in Corollaries 3.4 and 3.5.
Building on this, the authors propose two clipping methods to stabilize entropy during training. The first, ClipB, operates at the batch level: for each token t in a batch TB, it computes the batch mean Sˉ and standard deviation σ of S∗t, then applies a mask mt=1{−μ−σ≤S∗t−Sˉ≤μ+σ} to filter outlier tokens that drive extreme entropy fluctuations. The second, ClipV, operates at the vocabulary level: for each token, it computes the centered score Sct=S∗t−Ei∼pt[Sit], then applies a mask based on the batch standard deviation of these centered scores. Both methods require minimal computation—operating on scalar values—and can be seamlessly integrated into existing RFT pipelines.
The authors further demonstrate that existing entropy control methods—such as clipping mechanisms, entropy regularization, and probability-weighted updating—can be interpreted through the lens of their entropy dynamics framework. For instance, clipping in GRPO predominantly affects low-probability tokens, which tend to have S∗−E[Si]<0; thus, clipping positive samples (which reward these tokens) tends to increase entropy, while clipping negative samples (which penalize them) tends to decrease it. Similarly, entropy regularization methods that update only high-entropy tokens implicitly target tokens with S∗−E[Si]>0, whose updates on positive samples decrease entropy. This unified perspective allows the authors to explain why certain methods promote exploration (by amplifying entropy-increasing updates) while others suppress it (by amplifying entropy-decreasing updates).
Finally, the authors extend their analysis to off-policy settings, showing that the same entropy dynamics hold when incorporating the importance ratio r, with the entropy change factor becoming r(S∗−Ei∼p[Si]). They also derive batch-level covariance expressions (Corollaries C.2 and C.2.1) that link entropy change to the covariance between advantage and the discriminator score deviation, providing a computable metric for monitoring entropy collapse during training. Their empirical results confirm that this covariance is predominantly negative, indicating that models tend to reinforce “safe” high-probability tokens, thereby suppressing exploration—a dynamic their clipping methods are designed to counteract.
Experiment
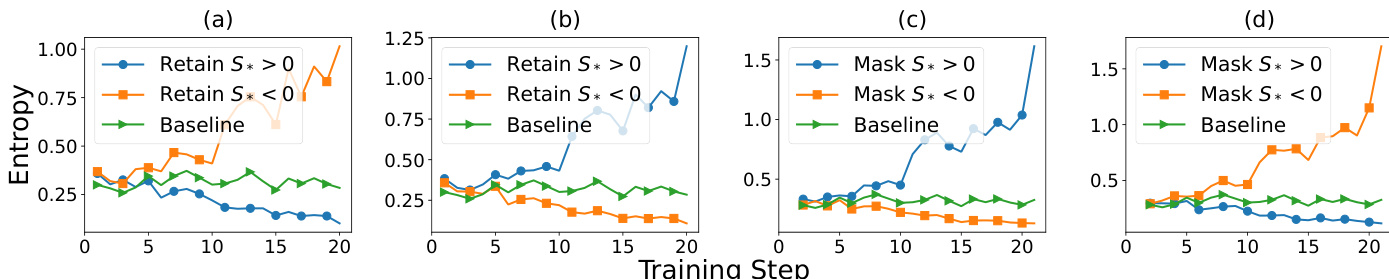
- Empirical tests confirm that discriminator scores reliably predict entropy changes: positive scores reduce entropy in positive samples and increase it in negative ones, and vice versa for negative scores, validating theoretical claims.
- Gradient masking experiments further support this relationship, showing entropy increases when entropy-reducing gradients are masked and decreases when entropy-increasing gradients are masked.
- Clipping methods (Clip_B and Clip_V) effectively control entropy decay during training, allowing flexible adjustment via hyperparameter μ and preventing excessive entropy collapse.
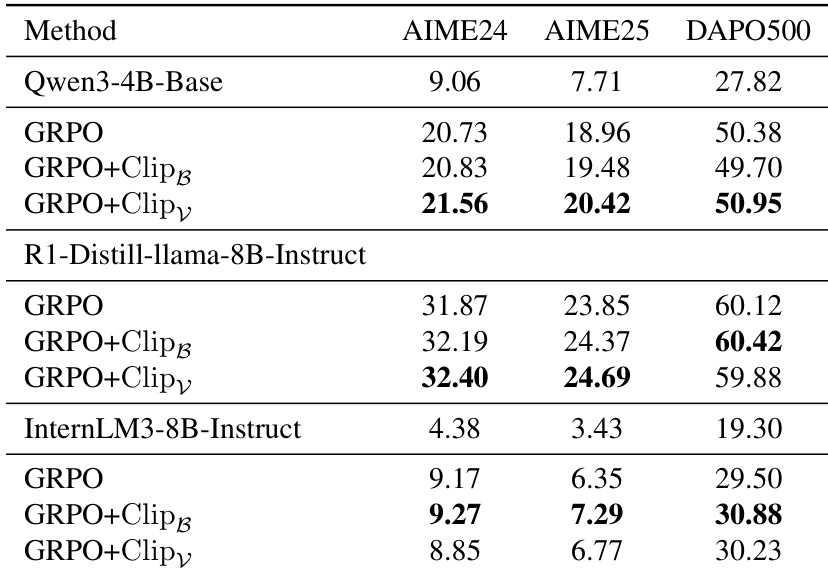
- Models trained with clipping methods outperform standard GRPO across datasets, preserving exploration and improving overall performance.
- Analysis of Pass@K and Avg@K metrics reveals that clipping enhances both solution diversity (exploration) and pattern exploitation, broadening the range of solvable problems.
- Distribution of problem pass rates shows clipping encourages balanced exploration, reducing extreme solve/fail outcomes and promoting moderate success across varied problems.
- Experiments with PPO and multiple model architectures (Qwen3, Distilled-Llama, InternLM) confirm the generalizability of clipping methods in stabilizing training and improving performance.
- For InternLM, clipping prevents training collapse and stabilizes gradients, highlighting its role in filtering outlier tokens and enhancing training robustness.
The authors use entropy-based clipping methods to selectively control token updates during reinforcement fine-tuning, which effectively stabilizes entropy and prevents its collapse. Results show that both Clip_B and Clip_V consistently improve model performance across multiple datasets and model sizes, particularly enhancing exploration as measured by Pass@K. These gains stem from encouraging broader solution diversity rather than over-relying on high-reward patterns, leading to more robust and stable training dynamics.
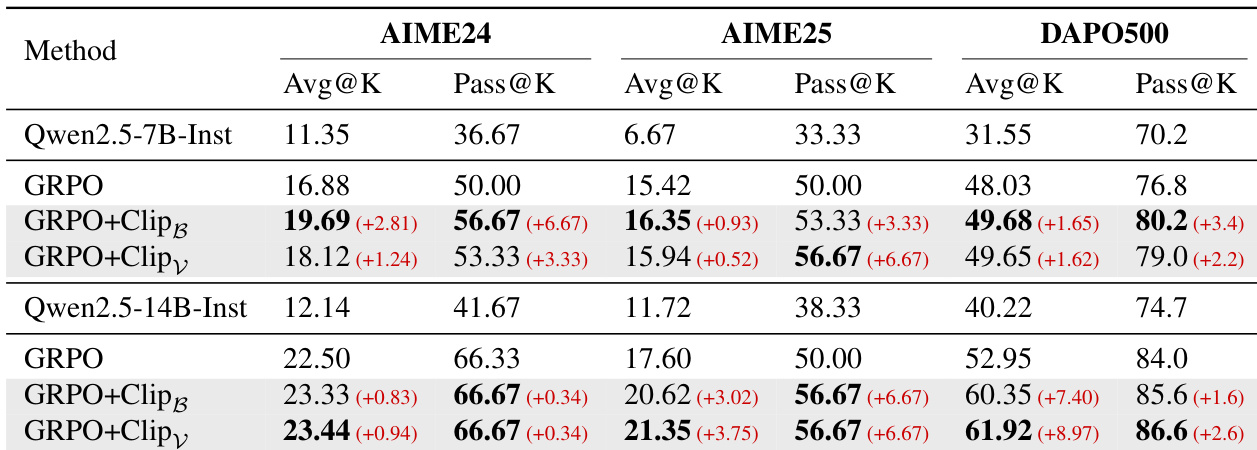
The authors use entropy-based clipping methods to selectively control token updates during reinforcement fine-tuning, which stabilizes entropy and improves model performance across multiple datasets and architectures. Results show that both Clip_B and Clip_V consistently outperform standard GRPO, particularly in maintaining exploration and preventing entropy collapse. These gains are observed across diverse models, including Qwen3, Distilled-Llama, and InternLM, confirming the generalizability of the approach.
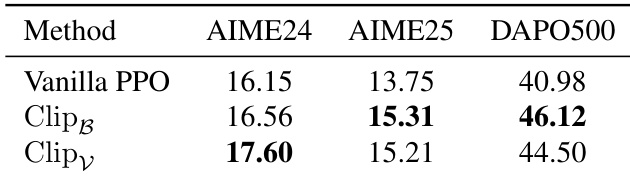
The authors apply entropy control methods to PPO training and observe consistent performance gains across multiple datasets. Results show that both Clip_B and Clip_V outperform Vanilla PPO, with Clip_V achieving the highest scores on AIME24 and DAPO500. These improvements suggest that regulating token-level entropy during training enhances model exploration and overall effectiveness.