Command Palette
Search for a command to run...
UniReason 1.0: Ein einheitlicher Reasoning-Framework für weltwissensbasierte Bildgenerierung und -bearbeitung
UniReason 1.0: Ein einheitlicher Reasoning-Framework für weltwissensbasierte Bildgenerierung und -bearbeitung
Zusammenfassung
Einheitliche multimodale Modelle stoßen oft bei komplexen Syntheseraufgaben, die tiefgehendes Schlussfolgern erfordern, auf Schwierigkeiten und behandeln typischerweise Text-zu-Bild-Generierung und Bildbearbeitung als voneinander isolierte Fähigkeiten, anstatt sie als miteinander verbundene Schlussfolgerungsschritte zu betrachten. Um dieses Problem anzugehen, schlagen wir UniReason vor, einen einheitlichen Rahmen, der diese beiden Aufgaben durch ein dualer Schlussfolgerungsparadigma harmonisiert. Wir formulieren die Generierung als planungsbasiertes Vorgehen, das durch Weltwissen erweitert ist, um implizite Einschränkungen einzubinden, und nutzen die Bearbeitungsfähigkeiten für feinabgestimmte visuelle Verfeinerung, um visuelle Fehler durch Selbstreflexion weiter zu korrigieren. Dieser Ansatz vereint Generierung und Bearbeitung innerhalb einer gemeinsamen Repräsentation und spiegelt den menschlichen kognitiven Prozess von Planung gefolgt von Verfeinerung wider. Wir unterstützen diesen Rahmen durch die systematische Erstellung einer großskaligen, schlussfolgerungsorientierten Datensammlung (ca. 300.000 Beispiele), die fünf zentrale Wissensbereiche (z. B. kulturelle Alltagsweisheit, Physik) abdeckt, sowie durch eine agentengenerierte Korpus für visuelle Selbstkorrektur. Ausführliche Experimente zeigen, dass UniReason herausragende Leistung auf schlussfolgerungsintensiven Benchmarks wie WISE, KrisBench und UniREditBench erzielt, während gleichzeitig hervorragende allgemeine Synthesefähigkeiten erhalten bleiben.
One-sentence Summary
Fudan University and Shanghai Innovation Institute researchers propose UniReason, a unified framework merging text-to-image generation and editing via dual reasoning—planning with world knowledge and self-reflective refinement—outperforming prior models on reasoning benchmarks while enabling coherent, error-corrected visual synthesis across diverse domains.
Key Contributions
- UniReason introduces a unified framework that treats text-to-image generation and image editing as interconnected reasoning steps, leveraging shared representations to mirror human planning and refinement, thereby closing the gap between abstract intent and faithful visual output.
- It combines world knowledge-enhanced textual reasoning to inject implicit constraints before generation and fine-grained visual refinement via self-reflection after generation, enabling iterative correction and mutual capability transfer between synthesis and editing tasks.
- The framework is supported by a large-scale reasoning dataset (~300k samples) spanning five knowledge domains and an agent-generated corpus for self-correction, achieving state-of-the-art results on benchmarks including WISE, KrisBench, and UniREditBench.
Introduction
The authors leverage a unified framework called UniReason to bridge the gap between text-to-image generation and image editing by treating them as interconnected reasoning steps rather than isolated tasks. Prior methods either reason only before generation without visual feedback or treat generation and editing separately, leaving implicit world knowledge—like physics or cultural commonsense—untapped and failing to exploit their structural synergy. UniReason introduces two key components: world knowledge-enhanced textual reasoning to infer implicit constraints before synthesis, and fine-grained editing-like visual refinement to self-correct errors afterward, all trained on a newly constructed dataset spanning five knowledge domains and an agent-generated refinement corpus. This unified approach achieves state-of-the-art results on reasoning-heavy benchmarks while maintaining strong general synthesis performance.
Dataset
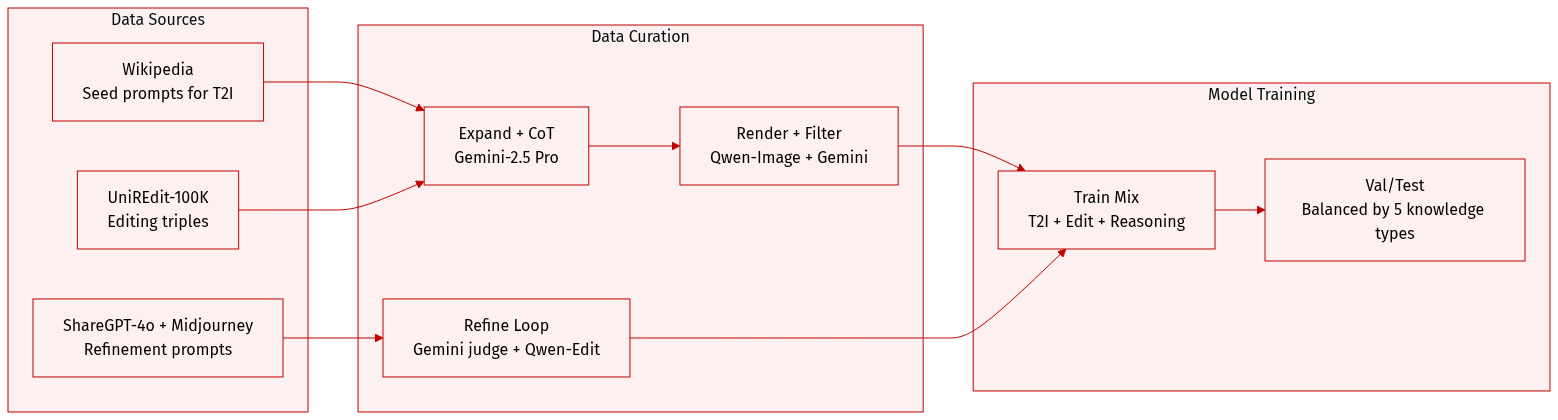
The authors use a two-phase dataset construction pipeline to train UniReason for world knowledge-enhanced multimodal reasoning in image synthesis. Here’s how the data is composed, processed, and used:
-
Dataset Composition and Sources
- Built for both text-to-image (T2I) generation and image editing.
- Draws from Wikipedia for seed prompts, UniREdit-Data-100K for editing triples, and ShareGPT-4o-Image and Midjourney prompts for refinement training.
- Five world knowledge categories are covered: Cultural Commonsense, Natural Science, Spatial Reasoning, Temporal Reasoning, and Logical Reasoning.
-
Key Details per Subset
- T2I Generation: Seed prompts manually crafted from Wikipedia; expanded and paired with CoT reasoning using Gemini-2.5 Pro. Images rendered via Qwen-Image.
- Image Editing: Uses UniREdit-Data-100K triples; augmented with Gemini-2.5 Pro-generated reasoning traces.
- Refinement Data: Generated via an agent pipeline — initial image + reasoning → Gemini-2.5 Pro feedback → Qwen-Image-Edit refinement → Gemini-2.5 Pro judge for improvement validation.
-
Data Filtering and Quality Control
- All samples are evaluated by Gemini-2.5 Pro across three dimensions: instruction alignment, visual fidelity, and reasoning correctness.
- Only verified, hallucination-free samples are retained.
- Refinement phase includes comparative evaluation to ensure measurable visual and semantic improvements.
-
Training Usage and Processing
- Training data mixes T2I and editing samples, each paired with structured reasoning traces.
- Mixture ratios are not explicitly specified but emphasize balanced coverage across the five knowledge categories.
- No cropping or metadata construction is mentioned; focus is on reasoning trace generation and iterative refinement supervision.
Method
The authors leverage a unified multimodal reasoning framework, termed UniReason, designed to support both text-to-image (T2I) generation and image editing through interleaved textual reasoning and visual refinement. The architecture builds upon Bagel’s Mixture-of-Transformers (MoT) foundation, integrating a ViT encoder to process multimodal inputs and enabling joint understanding and generation within a single model. Multimodal understanding is formalized as next-token prediction conditioned on context, minimizing the negative log-likelihood:
Ltext=−t=1∑Tlogpθ(xt∣x<t,C),where xt is the target token, x<t the preceding tokens, and C the multimodal context. Image generation operates in a VAE latent space via rectified flow, minimizing the latent flow-matching loss:
Limage=Et∼U(0,1)∥uθ(zt,t;C)−u⋆(zt,t)∥γ2,with u∗ as the target velocity and uθ the learned time-conditioned velocity field.
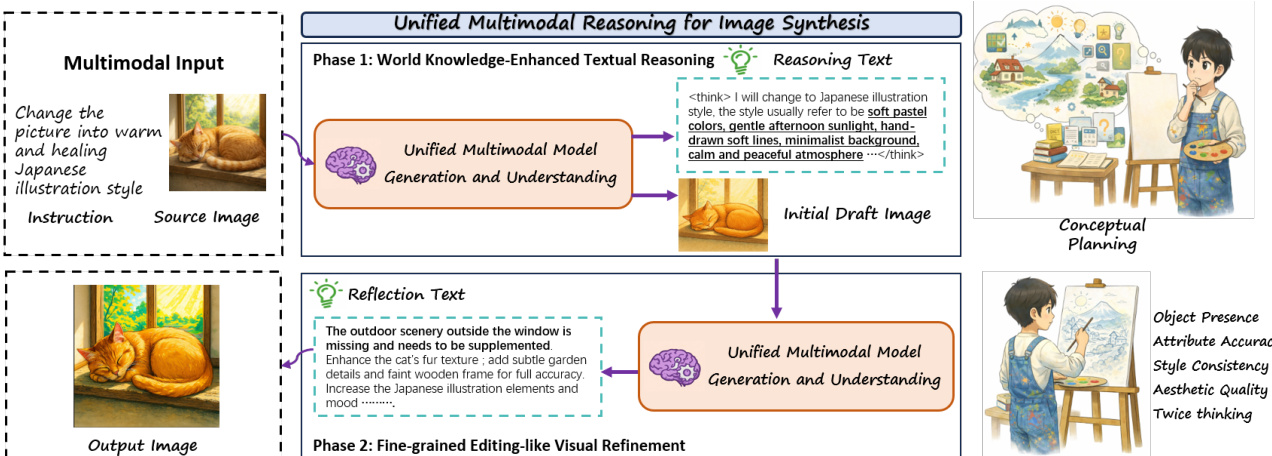
The framework operates in two sequential phases. Phase 1, World Knowledge-Enhanced Textual Reasoning, initiates synthesis by generating a reasoning trace that incorporates domain-specific knowledge—such as style, object attributes, or spatial constraints—before producing an initial draft image. This phase is supported by a data pipeline that expands seed prompts using world knowledge sources (e.g., Commonsense, Natural Science) and generates reasoning chains via Gemini 2.5 Pro, followed by image rendering via Qwen-Image and verification.
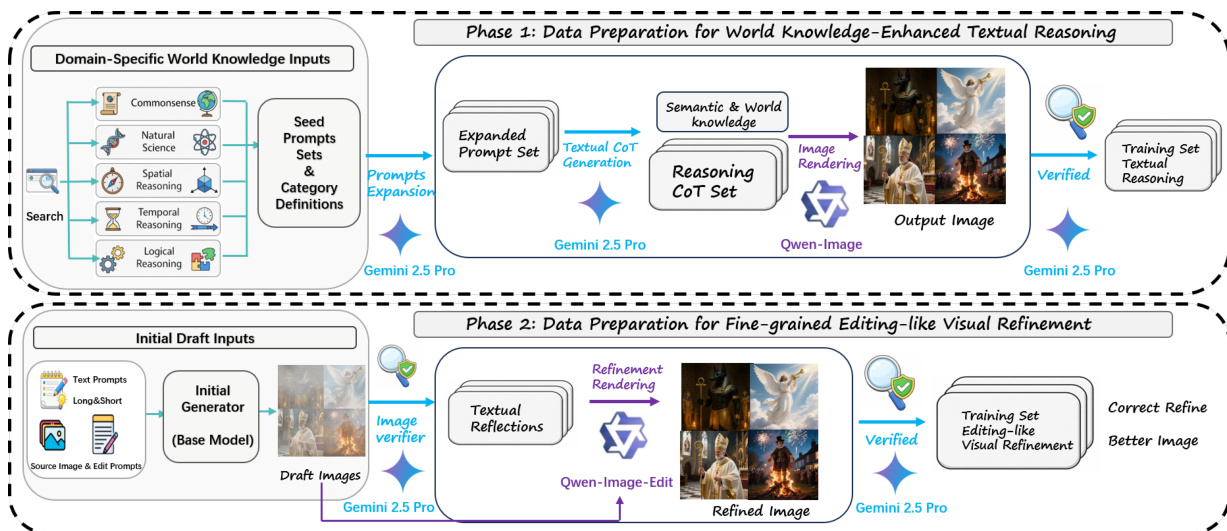
Phase 2, Fine-grained Editing-like Visual Refinement, iteratively improves the draft by reflecting on its shortcomings. The model generates textual reflections identifying inconsistencies or missing details—such as object presence, attribute accuracy, or aesthetic quality—and optionally performs a second round of reasoning to guide visual refinement. This process mirrors image editing, enabling a synergistic loop where T2I generation benefits from editing expertise and vice versa. The refinement data is constructed using an agent pipeline: an initial generator produces a draft, a verifier (Gemini 2.5 Pro) outputs structured edit directives, a refinement teacher (Qwen-Image-Edit) applies them, and a final judge retains only improved outputs.
Training proceeds via a two-stage supervised fine-tuning strategy. Stage 1 freezes the understanding branch and trains only the generation branch on standard T2I and editing datasets to strengthen foundational synthesis. Stage 2 unfreezes all parameters and jointly trains both branches on interleaved reasoning data, supervising reasoning traces and refined images while leaving initial drafts unsupervised. The overall loss is a weighted sum:
L=λtextLtext+λimgLimg,where Ltext and Limg are the text and image losses, and λtext, λimg are scalar weights balancing their contributions.
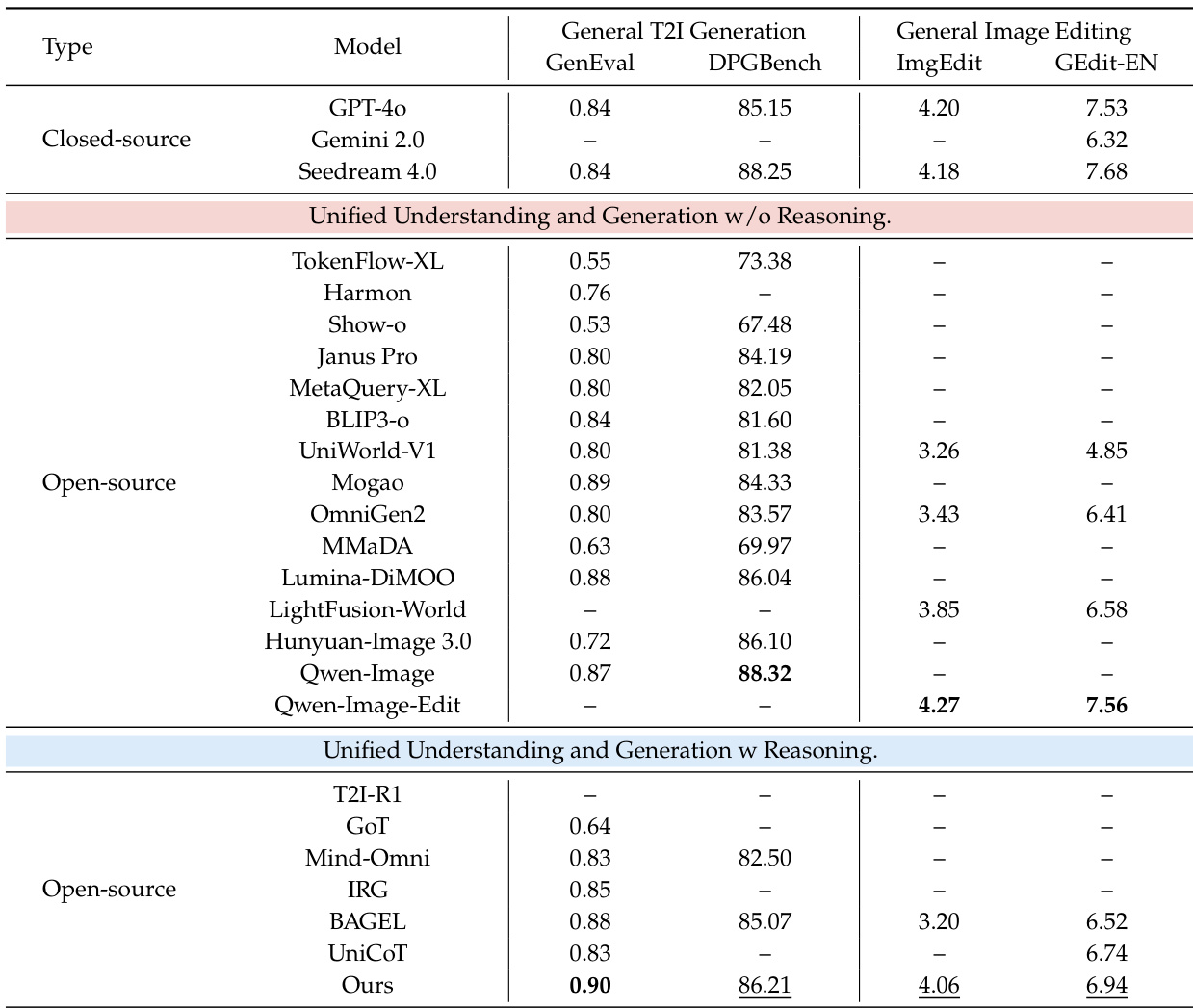
Experiment
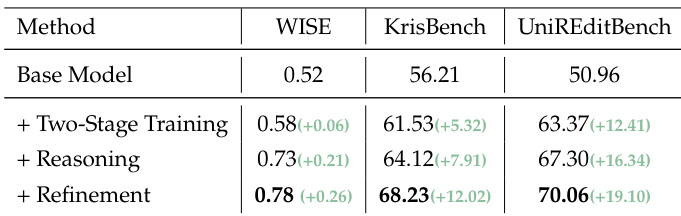
- Two-stage training successfully integrates knowledge-enhanced reasoning and visual refinement into a unified multimodal model, significantly boosting performance on knowledge-intensive tasks.
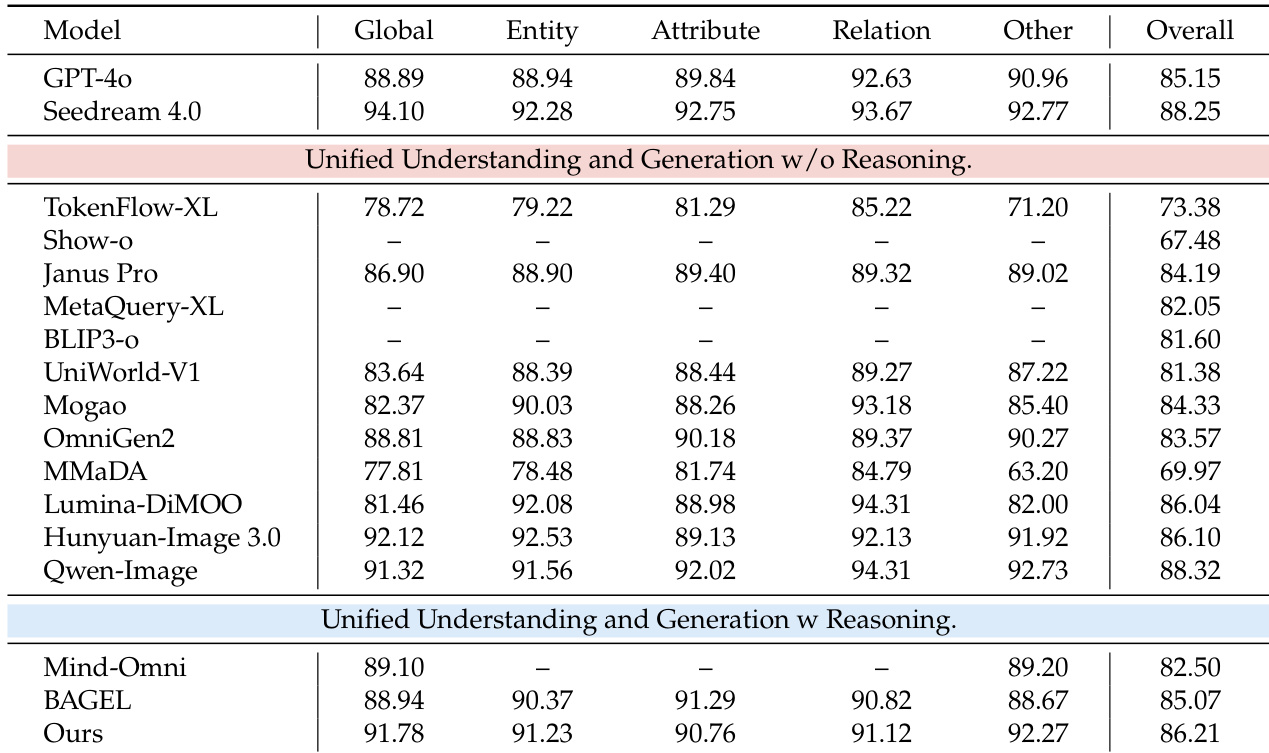
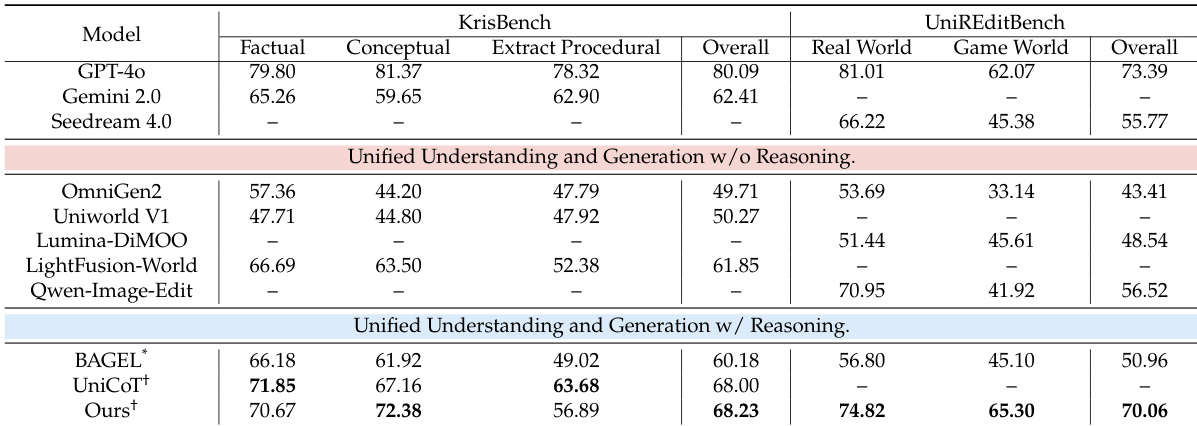
- The model outperforms leading open-source unified models and matches or exceeds closed-source counterparts like GPT-4o and Gemini 2.0 on key benchmarks, particularly in cultural, spatial, and scientific reasoning.
- It maintains strong general generation and editing capabilities, surpassing systems like Qwen-Image and Seedream 4.0 on general benchmarks without relying on external LLMs.
- Ablation studies confirm that each component—two-stage training, textual reasoning, and visual refinement—contributes progressively to improved outcomes, with reasoning yielding the largest gains.
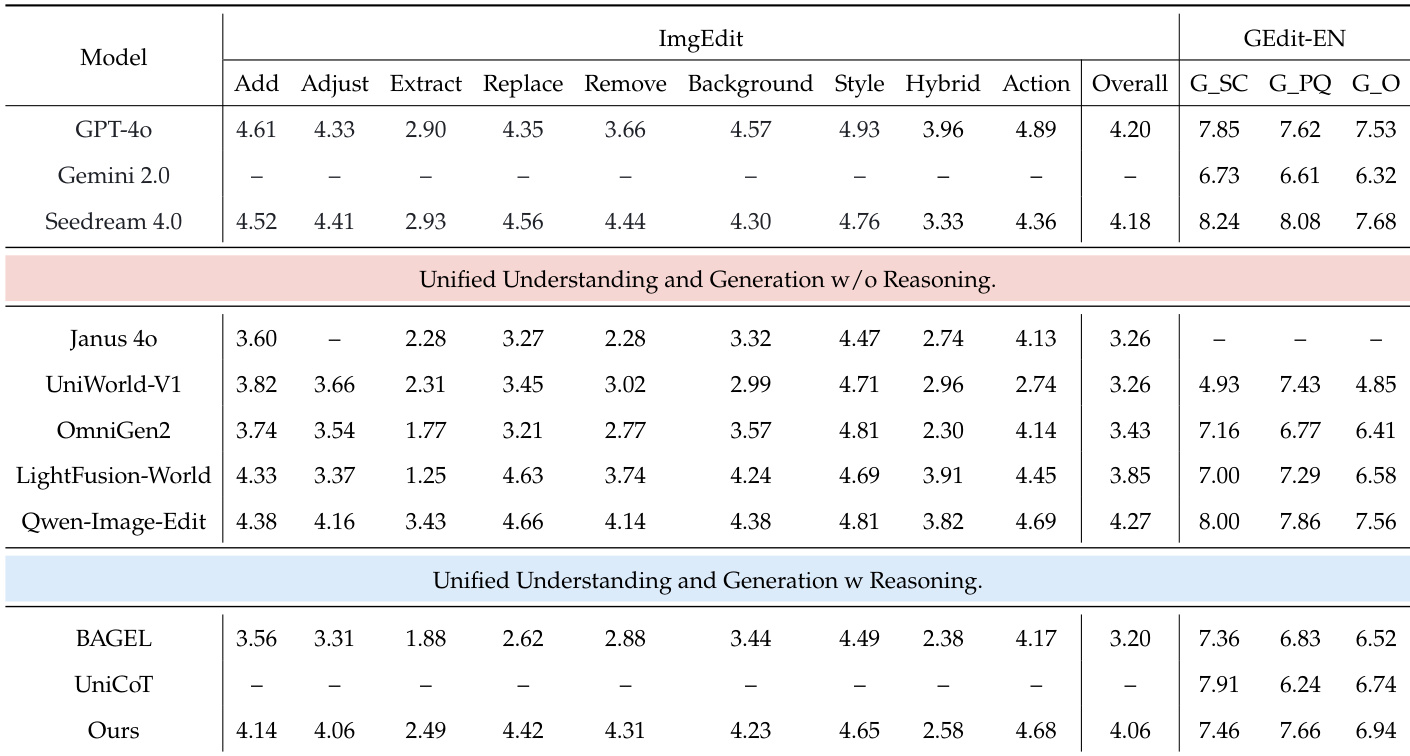
- Image editing proficiency directly correlates with refinement effectiveness, underscoring the need for joint training of generation and editing within a unified reasoning framework.
- Qualitative results show the model handles complex reasoning scenarios and refines fine details like faces, text, and gestures, enhancing both accuracy and visual fidelity.
The authors use a two-stage training approach to enhance a unified multimodal model’s ability to perform both image generation and editing while incorporating explicit reasoning. Results show the model outperforms other open-source unified models across knowledge-intensive tasks and matches or exceeds closed-source systems in specific benchmarks, particularly in cultural, spatial, and scientific reasoning. It also maintains strong performance on general generation and editing tasks, demonstrating broad capability without sacrificing versatility.
The authors use a progressive ablation study to show that adding two-stage training, reasoning, and refinement components sequentially improves performance across knowledge-intensive benchmarks. Results show that each stage contributes meaningfully, with reasoning providing the largest gain on WISE and refinement further boosting scores across all tasks. This indicates that integrating explicit reasoning and visual refinement into a unified framework enhances both knowledge handling and output quality.
The authors evaluate their model on general image editing benchmarks, showing it achieves the highest overall score among unified models with reasoning capabilities. Results indicate strong performance across fine-grained editing categories like Add, Adjust, and Replace, while also maintaining competitive scores on GEdit-EN. This demonstrates the model’s ability to balance general editing proficiency with reasoning-enhanced control.
The authors use a unified multimodal model with explicit reasoning and refinement mechanisms to achieve top performance among open-source systems on knowledge-intensive image generation and editing tasks. Results show the model outperforms comparable unified models and rivals closed-source systems like GPT-4o and Gemini 2.0 on specific benchmarks, particularly in factual and conceptual reasoning. The model also maintains strong general generation and editing capabilities, demonstrating broad applicability without sacrificing versatility.
The authors use a two-stage training approach to enhance a unified multimodal model’s ability to perform both text-to-image generation and image editing while incorporating reasoning. Results show the model achieves top performance among open-source systems on general benchmarks and outperforms several closed-source models in specific knowledge-intensive tasks. It also maintains strong generalization across both generation and editing, indicating that reasoning integration does not compromise broad capability.