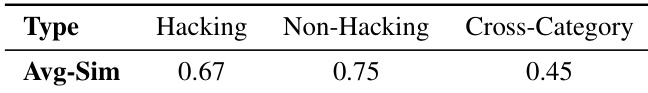Command Palette
Search for a command to run...
Echtzeit-ausgerichtetes Belohnungsmodell jenseits der Semantik
Echtzeit-ausgerichtetes Belohnungsmodell jenseits der Semantik
Zusammenfassung
Reinforcement Learning from Human Feedback (RLHF) ist eine entscheidende Technik zur Ausrichtung großer Sprachmodelle (LLMs) an menschliche Präferenzen, ist jedoch anfällig für Reward-Overoptimierung, bei der Policy-Modelle sich übermäßig an das Reward-Modell anpassen, spurious Reward-Muster ausnutzen und stattdessen nicht mehr die tatsächliche menschliche Intention treu widerspiegeln. Vorherige Ansätze zur Minderung dieser Probleme basieren hauptsächlich auf oberflächlichen semantischen Informationen und adressieren die durch kontinuierliche Verschiebungen der Policy-Verteilung verursachte Fehlausrichtung zwischen Reward-Modell (RM) und Policy-Modell ineffizient. Dies führt zwangsläufig zu einer zunehmenden Diskrepanz im Reward, was die Reward-Overoptimierung weiter verschärft. Um diese Einschränkungen zu überwinden, stellen wir R2M (Real-Time Aligned Reward Model) vor – einen neuartigen, leichtgewichtigen RLHF-Framework. Im Gegensatz zu herkömmlichen Reward-Modellen, die ausschließlich auf semantischen Darstellungen eines vortrainierten LLMs basieren, nutzt R2M die sich dynamisch verändernden versteckten Zustände der Policy (sogenannte Policy-Feedback), um sich in Echtzeit an die sich während des RL-Prozesses verändernde Verteilung der Policy anzupassen. Diese Arbeit eröffnet einen vielversprechenden neuen Ansatz zur Verbesserung der Leistung von Reward-Modellen durch die Echtzeit-Nutzung von Feedback aus Policy-Modellen.
One-sentence Summary
Researchers from multiple institutions propose R2M, a lightweight RLHF framework that dynamically aligns reward models with policy shifts using real-time hidden state feedback, overcoming reward overoptimization by moving beyond static semantic representations to better capture evolving human intent during training.
Key Contributions
- R2M addresses reward overoptimization in RLHF by dynamically aligning the reward model with the policy’s evolving hidden states, mitigating distribution shift without requiring retraining or additional labeled data.
- The framework enhances reward models by integrating policy feedback into the scoring head, enabling real-time adaptation to policy behavior while preserving computational efficiency and compatibility with existing RLHF pipelines.
- Evaluated on UltraFeedback and TL;DR datasets, R2M boosts AlpacaEval win rates by 5.2%–8.0% and TL;DR win rates by 6.3% over baselines, demonstrating consistent gains with minimal added computational cost.
Introduction
The authors leverage the evolving hidden states of the policy model during RLHF to dynamically align the reward model with real-time distribution shifts, addressing a key limitation in traditional reward modeling. Prior methods either rely on static semantic representations or costly retraining, failing to efficiently correct misalignment as the policy evolves—leading to reward overoptimization where models exploit superficial cues rather than human intent. R2M introduces a lightweight, plug-and-play framework that adapts the reward model’s scoring head using policy feedback, without retraining the full model or requiring new labeled data. This enables continuous alignment, reduces reward hacking, and boosts performance across dialogue and summarization tasks with negligible computational overhead.
Dataset

- The authors use 100 “chosen” and 100 “rejected” query-response pairs sampled from UltraFeedback’s preference subset to extract hidden states from specific layers (6, 12, 18, 24, 30) of LLaMA3-8B-Instruct.
- For each pair, they average token-level hidden states to form a single vector per query-response, then compute cosine similarities across all 200 vectors per layer, producing 19,900 pairs per layer.
- These pairs are split into two subsets: intra-category (same preference label) and cross-category (different labels), with mean cosine similarities calculated separately for each.
- At layer 30, they sample 300 pairs and correlate hidden state similarity with reward differences from Skywork-Reward-V2-Llama-3.1-8B.
- For the TL;DR task, they sample 2048 queries per training step from the TL;DR dataset, generating up to 50 tokens per response and training for 1M trajectories using RL with Algorithm 1.
- They use Pythia-2.8B-TL;DR-SFT as the policy model and Pythia-2.8B-TL;DR-RM as the reward model, with a learning rate of 3e-6, Ω=0.6, and group size 4.
- Post-training, they evaluate summary quality using GPT-4 as a judge, comparing against reference summaries from TL;DR to compute win rates.
Method
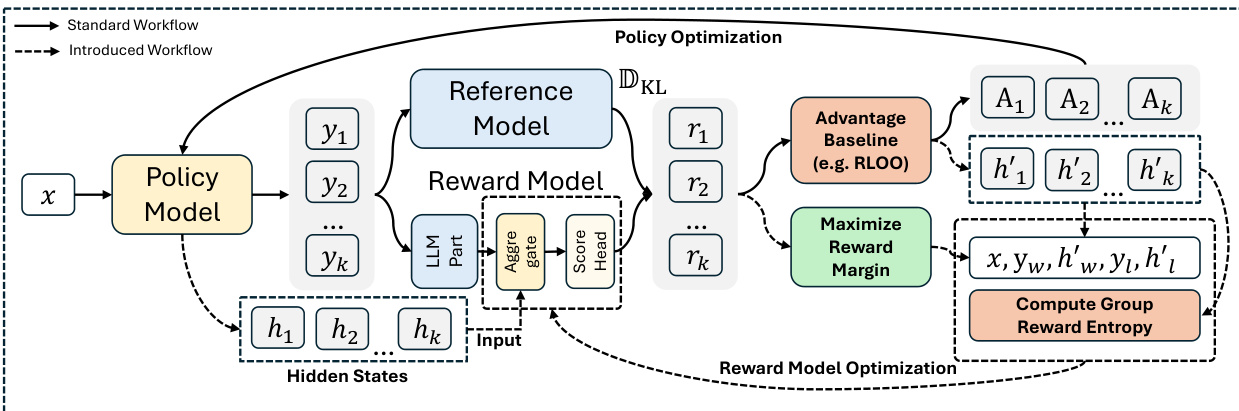
The authors leverage a novel architecture, R2M, designed to enhance the reward model during the RL optimization phase of RLHF by incorporating real-time policy feedback. The core innovation lies in structurally integrating the policy model’s internal hidden states into the reward model’s scoring mechanism, enabling the reward model to dynamically adapt to the policy’s evolving distribution. This is achieved through two key modules: a Sequence-to-Token Cross Attention mechanism and a Time-Step-Based Weighted Combination strategy, both operating within an iterative optimization loop.
As shown in the framework diagram, the overall workflow begins with trajectory sampling, where the current policy model generates K responses for each query. Concurrently, the last-layer hidden states of the policy model for each query-response pair are collected. These hidden states, denoted as hi,j, serve as the policy feedback signal. During the reward annotation phase, the reward model processes the query-response pair through its LLM component to obtain the standard Reward Token Embedding (RTE), Hlasti,j. The critical departure from vanilla reward modeling occurs here: the policy feedback hi,j is injected into the reward model via a cross-attention module. This module treats the RTE as a query and the policy hidden states as keys and values, performing a sequence-to-token attention operation to produce an Aggregated RTE, Hlasti,j, which fuses semantic and policy state information.
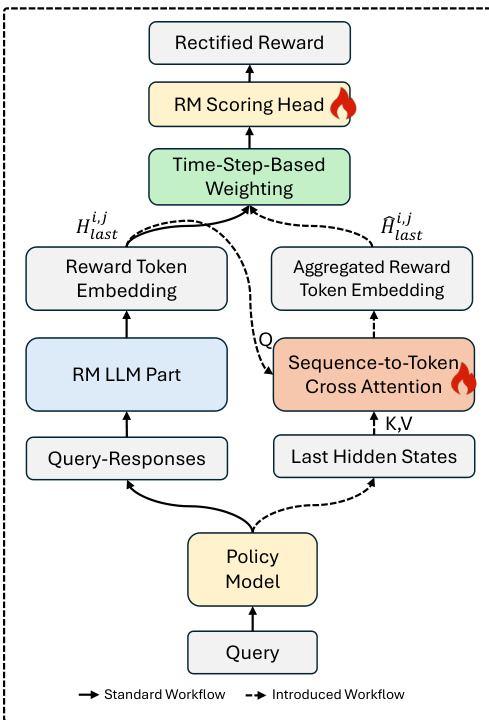
The final reward token embedding, Hfini,j, is then constructed by combining the original RTE and the aggregated RTE using a time-step-based weighting function ω(t). This function, defined as ω(t)=max(21cos(Ttπ)+21,Ω), ensures that early in training, the model relies more on the established semantic representation, while later stages progressively emphasize the policy feedback to adapt to distribution shifts. The final scalar reward is computed by passing Hfini,j through the scoring head ϕ.
The training process is iterative and lightweight. After the policy optimization step, which updates the policy model πθ and its hidden states, a separate Reward Model Optimization phase is triggered. This phase does not retrain the entire reward model’s LLM component. Instead, it focuses on updating only the cross-attention module and the scoring head ϕ, using a novel Group Reward Entropy Bradley-Terry (GREBT) loss. This loss combines the standard Bradley-Terry objective, which learns from preference pairs (xi,yi,w,hi,w,yi,l,hi,l), with a Group Reward Entropy (GRE) regularization term. The GRE term, defined as −∑j=1Kpi,jlogpi,j where pi,j is the softmax of standardized rewards within a group, explicitly encourages reward diversity to mitigate the “group degeneration” problem where the reward model assigns nearly identical scores to all responses in a group. The overall loss is LGREBT(i;φ)=(1−α)LBT(i;φ)+αLGRE(i;φ), with α controlling the trade-off. This iterative, lightweight optimization allows the reward model to continuously refine its scoring based on the most current policy state, without incurring prohibitive computational costs.
Experiment
- Deep-layer hidden states in transformer policies strongly correlate with human preferences and reward scores, validating their use to enhance reward models beyond semantic features.
- R2M, integrating policy feedback into reward modeling, consistently outperforms vanilla RL and baseline methods across dialogue and summarization tasks, showing broad applicability and superior alignment with human preferences.
- Policy feedback is essential: freezing R2M or replacing feedback with noise degrades performance, confirming that adaptive updates leveraging hidden states are necessary for gains.
- R2M significantly improves reward model accuracy and calibration, enabling more aggressive yet stable policy updates without triggering reward overoptimization.
- Ablation studies confirm all R2M components—feedback integration, mixed GREBT loss, and iterative updates—are indispensable; removing any leads to notable performance drops.
- R2M is computationally efficient, introducing minimal overhead while achieving substantial gains, thanks to lightweight attention-based feedback aggregation and partial model updates.
- Hidden states effectively detect reward overoptimization patterns and policy distribution shifts, supporting R2M’s dual strategy of dynamic reward adaptation and deeper semantic alignment.
The authors integrate policy feedback into reward model training through R2M, which consistently outperforms baseline methods including pretrained and iteratively updated reward models. Results show that simply using policy feedback without model adaptation degrades performance, while full R2M training significantly boosts win rates across both GRPO and RLOO frameworks. This demonstrates that iterative reward model updates guided by policy feedback are essential for effective alignment with human preferences.
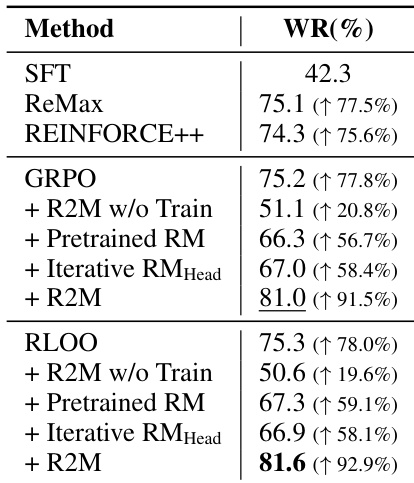
The authors integrate policy feedback into reward model training through R2M, which consistently outperforms baseline methods across multiple evaluation metrics on both dialogue and summarization tasks. Results show that iterative updates using policy-derived hidden states significantly enhance reward model accuracy and alignment with human preferences, while ablation studies confirm that each component of R2M contributes meaningfully to its performance. The approach enables more aggressive and effective policy updates without triggering reward overoptimization, demonstrating its robustness in real-world RLHF settings.
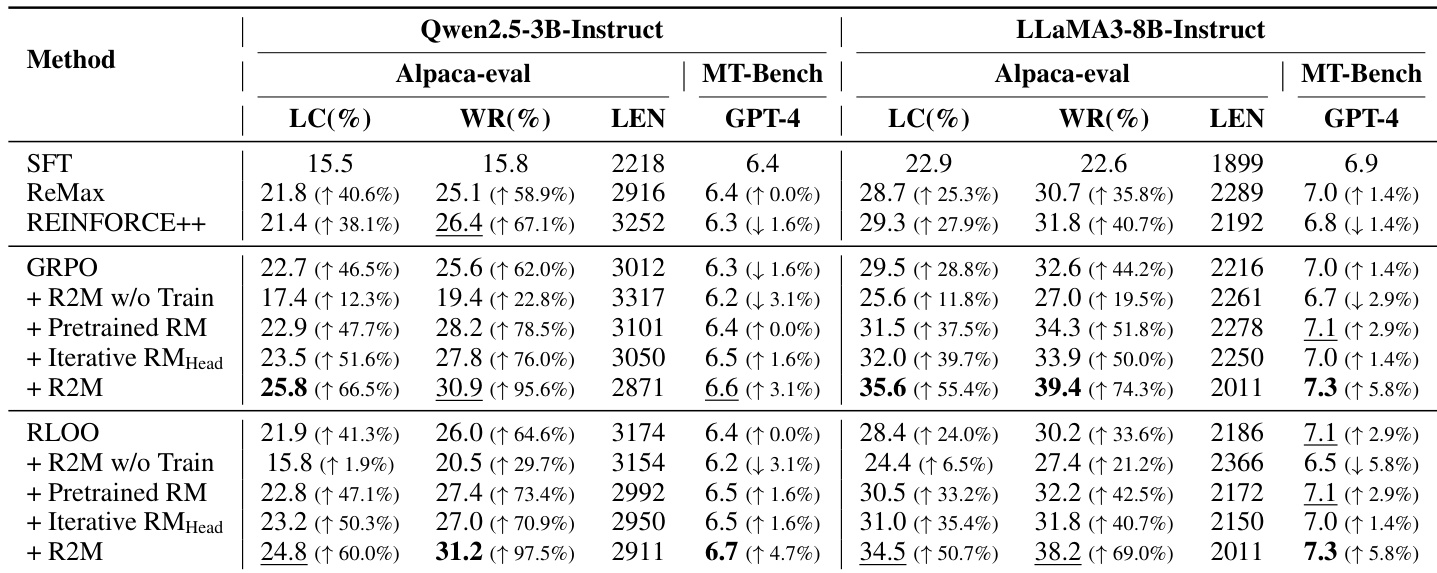
The authors integrate policy feedback into reward model training through R2M, which consistently outperforms baseline methods including frozen and noise-augmented variants. Results show that updating the reward model with policy-derived hidden states is essential for performance gains, as static or untrained feedback yields minimal improvement. The full R2M approach achieves the highest win rates, confirming that iterative alignment with policy dynamics enhances reward signal quality and model alignment with human preferences.
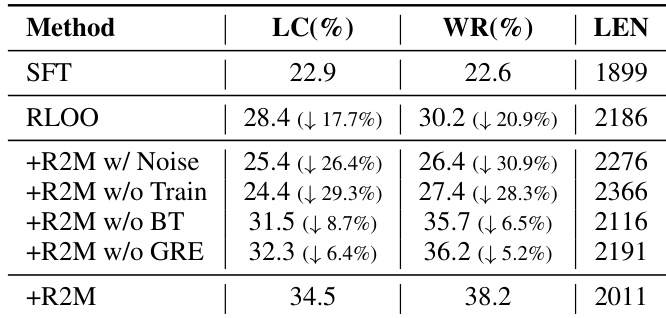
The authors use R2M to iteratively update the reward model by incorporating policy feedback during training, which significantly improves its accuracy on preference prediction. Results show that after training, R2M outperforms both the vanilla reward model and its own pre-trained version, confirming that policy feedback enhances reward alignment with human preferences. This improvement is consistent across different policy models and stems from the model’s ability to leverage deep-layer hidden states for more reliable reward allocation.
The authors use hidden state similarity to distinguish between responses exhibiting reward overoptimization and normal outputs, finding that within-category similarities are significantly higher than cross-category similarities. This supports the use of policy hidden states as indicators for detecting reward hacking behavior. Results show that such semantic and state-based signals can help align reward models with true human preferences and mitigate overoptimization.