Command Palette
Search for a command to run...
Selbst-Distillation ermöglicht kontinuierliches Lernen
Selbst-Distillation ermöglicht kontinuierliches Lernen
Idan Shenfeld Mehul Damani Jonas Hübotter Pulkit Agrawal
Zusammenfassung
Kontinuierliches Lernen, das Modellen ermöglicht, neue Fähigkeiten und Kenntnisse zu erwerben, ohne bestehende Fähigkeiten zu beeinträchtigen, bleibt eine grundlegende Herausforderung für Grundmodelle. Während die on-policy-Verstärkungslernverfahren das Verlernen reduzieren können, erfordern sie explizite Belohnungsfunktionen, die häufig nicht verfügbar sind. Die Alternativmethode, Lernen aus Expertendemonstrationen, wird hauptsächlich durch überwachtes Feintuning (Supervised Fine-Tuning, SFT) dominiert, das intrinsisch off-policy ist. Wir stellen Self-Distillation Fine-Tuning (SDFT) vor, eine einfache Methode, die on-policy-Lernen direkt aus Demonstrationen ermöglicht. SDFT nutzt kontextbasiertes Lernen, indem ein demonstationsspezifisches Modell als eigenes Lehrmodell dient und so on-policy-Trainingssignale erzeugt, die bestehende Fähigkeiten bewahren, während neue Fähigkeiten erworben werden. In Aufgaben zum Erwerb von Fähigkeiten und Wissen übertrifft SDFT konsistent SFT, erreicht eine höhere Genauigkeit bei neuen Aufgaben und reduziert das katastrophale Verlernen erheblich. In sequenziellen Lernexperimenten ermöglicht SDFT es einem einzelnen Modell, im Laufe der Zeit mehrere Fähigkeiten zu akkumulieren, ohne dass die Leistung abnimmt, und etabliert damit die on-policy-Distillation als praktikable Lösung für kontinuierliches Lernen aus Demonstrationen.
One-sentence Summary
Idan Shenfeld et al. from MIT, Improbable AI Lab, and ETH Zurich propose SDFT, an on-policy distillation method that uses self-generated in-context signals from demonstrations to reduce forgetting, outperforming SFT in continual skill and knowledge acquisition without performance regression.
Key Contributions
- SDFT addresses the challenge of continual learning from demonstrations by enabling on-policy updates without requiring explicit reward functions, using in-context learning to turn a model into its own teacher conditioned on expert examples.
- The method trains a student model to match the output distribution of a demonstration-conditioned teacher version of itself, minimizing reverse KL divergence to generate policy-aligned training signals that preserve prior capabilities while acquiring new skills.
- Evaluated across skill learning and knowledge acquisition tasks, SDFT outperforms supervised fine-tuning by achieving higher new-task accuracy and significantly reducing catastrophic forgetting, with sequential experiments showing stable multi-skill accumulation without performance regression.
Introduction
The authors leverage self-distillation to enable on-policy continual learning directly from expert demonstrations — a setting where traditional supervised fine-tuning fails due to catastrophic forgetting and off-policy drift. Prior methods either require handcrafted reward functions (as in reinforcement learning) or rely on inverse reinforcement learning, which struggles with scalability and strong structural assumptions. Their main contribution, Self-Distillation Fine-Tuning (SDFT), repurposes a model’s in-context learning ability: it conditions the same model on demonstrations to act as a teacher while training a student version on its own outputs, producing on-policy updates that preserve prior capabilities while acquiring new skills. This approach consistently outperforms standard fine-tuning across sequential learning benchmarks, enabling stable, long-term skill accumulation without performance regression.
Dataset

The authors use a multi-domain dataset composed of four key subsets, each sourced and processed differently to support skill learning and knowledge acquisition:
-
Science Q&A (Chemistry L-3 from SciKnowEval):
Split into 75% train, 5% validation, and 20% test. Expert demonstrations were generated by querying GPT-4o, sampling up to 8 responses per prompt and selecting one that matched the correct final answer. All training examples received valid demonstrations. Accuracy is measured via exact match of multiple-choice selections. -
Tool Use (ToolAlpaca):
Uses the original train-test split from Tang et al. (2023). Expert demonstrations are pre-included. Evaluation uses regex matching against ground-truth API calls, allowing for flexible argument ordering. -
Medical (HuatuoGPT-o1 subset):
Trains only on ~20,000 English-language questions from the SFT set. For evaluation, 1,000 verifiable clinical questions are randomly sampled. Responses are auto-evaluated by GPT-5-mini using a prompt focused on medical accuracy and completeness, outputting “CORRECT” or “INCORRECT”. -
Knowledge Acquisition (Synthetic 2025 Disaster Wiki Q&A):
Built from Wikipedia-style articles on fictional 2025 natural disasters. GPT-5 generates 100 multi-fact questions per article using a custom prompt; duplicates are manually removed. Evaluation uses GPT-5-mini with a three-tier rubric (“CORRECT”, “PARTIALLY_CORRECT”, “INCORRECT”) to assess factual accuracy and completeness.
All datasets are used in a self-distillation fine-tuning framework (SDFT). The model generates responses during training using student and teacher context prompts, computes token-level log probabilities, and updates parameters via gradient descent with teacher EMA. Importance sampling is optionally applied to align inference and training engines. No cropping or metadata construction beyond prompt-based evaluation is mentioned.
Method
The authors leverage a self-distillation framework for fine-tuning large language models, where a single model serves as both teacher and student by exploiting its in-context learning capabilities. The core architecture, illustrated in the framework diagram, consists of two modes: a student mode and a teacher mode, both operating on the same underlying language model parameters θ. The student mode processes a query x to generate responses y∼πθ(⋅∣x), while the teacher mode conditions the same model on both the query x and a demonstration c to produce a conditioned policy π(⋅∣x,c). The demonstration is incorporated via a simple prompt structure that encourages the model to infer the intent behind the example rather than copying it verbatim. 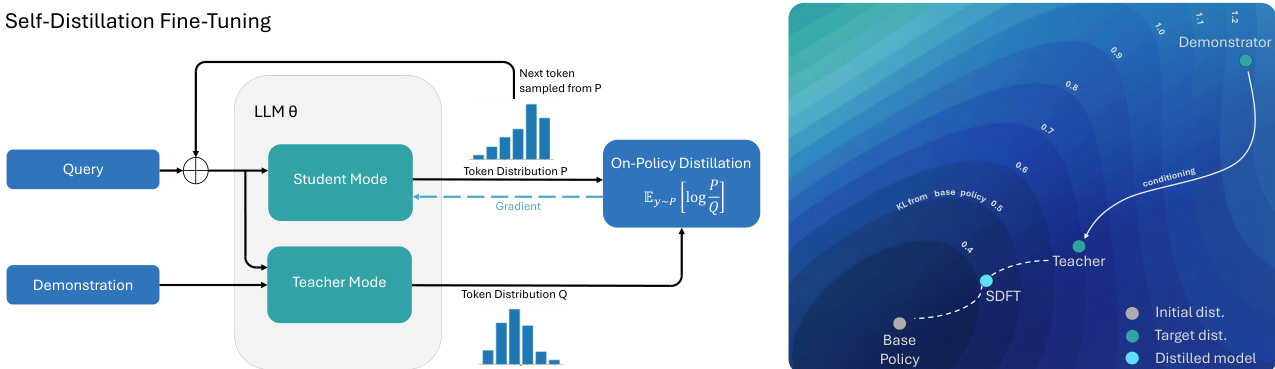
The training objective is to minimize the reverse Kullback-Leibler (KL) divergence between the student and teacher output distributions, defined as L(θ)=DKL(πθ(⋅∣x)∥π(⋅∣x,c)). This objective is computed on a per-token basis, leveraging the autoregressive nature of the model. The gradient of this loss with respect to the student parameters θ is derived by decomposing the sequence-level KL into a sum of token-level terms, resulting in the gradient estimator ∇θL(θ)=Ey∼πθ[∑t∑yt∈Vlogπ(yt∣y<t,x,c)πθ(yt∣y<t,x)∇θlogπθ(yt∣y<t,x)]. This formulation enables on-policy learning, where the student is updated based on its own current behavior, ensuring stability and continuity.
A critical design choice is the parameterization of the teacher model. While the teacher is always conditioned on the demonstration c, its weights can be defined in multiple ways. The authors use an exponential moving average (EMA) of the student parameters for the teacher, which provides a stable and smooth teacher policy that avoids abrupt shifts. This choice is essential for maintaining the on-policy nature of the learning process and preventing catastrophic forgetting. The framework diagram highlights the flow of information, where the student's token distribution P is used to compute the gradient for the on-policy distillation step, which updates the student model parameters θ.
The method can also be interpreted as an inverse reinforcement learning (IRL) algorithm. The self-distillation objective is mathematically equivalent to maximizing an implicit reward function derived from the difference in log-probabilities between the demonstration-conditioned teacher and the current student policy. This reward function, rt(yt∣y<t,x,c)=logπk(yt∣y<t,x)π(yt∣y<t,x,c), is defined at the token level and captures the immediate improvement in behavior induced by the demonstration. The policy gradient under this reward is shown to be equivalent to the gradient of the reverse KL divergence, demonstrating that the method is effectively an on-policy RL algorithm that learns from its own in-context learning capabilities. The figure on the right, which visualizes the policy space, illustrates this process: the base policy is updated towards the teacher policy, which is conditioned on the demonstration, while remaining close to the initial policy to preserve general capabilities.
Experiment
- On Science Q&A, Tool Use, and Medical tasks, SDFT outperforms SFT and DFT in new-task accuracy while preserving prior capabilities, achieving Pareto-efficient trade-offs.
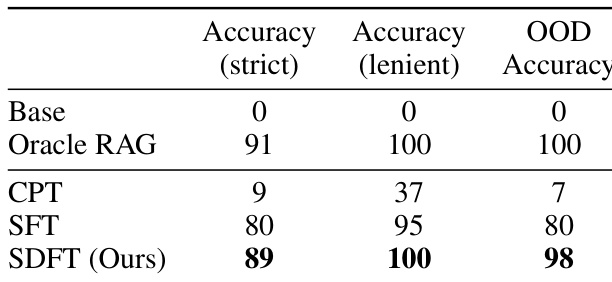
- In Knowledge Acquisition, SDFT achieves 89% strict accuracy on 2025 disaster facts (vs. 80% for SFT) and near-perfect out-of-distribution accuracy, surpassing CPT and matching oracle RAG.
- SDFT mitigates catastrophic forgetting: in multi-task continual learning, it enables stable skill accumulation, while SFT causes severe interference and performance oscillation.
- Model scaling enhances SDFT: Qwen2.5-14B gains 7 points over SFT on Science Q&A, confirming dependence on strong in-context learning.
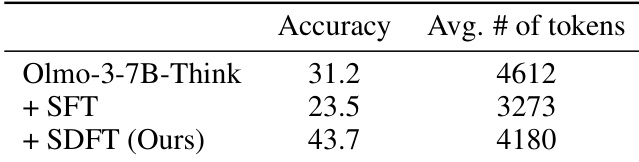
- On Olmo-3-7B-Think with answer-only medical data, SDFT boosts accuracy to 43.7% (vs. 23.5% for SFT) without collapsing reasoning depth.
- On-policy distillation is critical: offline distillation from the same teacher underperforms SDFT, proving gains stem from on-policy learning, not just teacher quality.
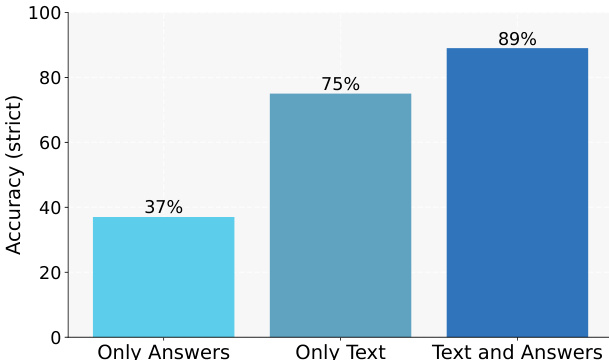
- Teacher context matters: conditioning on both article text and answer yields 89% accuracy vs. 75% for text-only in knowledge injection.
- EMA teacher ensures stable training: outperforms frozen base and unstable self-teacher variants.
- SDFT incurs 2.5× FLOPs and 4× wall-clock time vs. SFT but may reduce total cost when compared to multi-stage baselines like Re-invocation.
Results show that SDFT achieves the highest accuracy across all metrics in the Knowledge Acquisition setting, outperforming CPT and SFT. The method reaches 89% strict accuracy and 100% lenient accuracy, while also achieving 98% out-of-distribution accuracy, demonstrating effective integration of new factual knowledge.
The authors use SDFT to train a model on the Tool Use task while evaluating its impact on prior capabilities. Results show that SDFT achieves the highest accuracy on the new task (70.6) and maintains the best performance across previous tasks, including HellaSwag, HumanEval, and TruthfulQA, compared to SFT and DFT baselines. This demonstrates that SDFT effectively improves task performance without significant catastrophic forgetting.

The authors evaluate the impact of teacher context on knowledge integration, showing that conditioning the teacher on both the source text and the answer leads to significantly higher strict accuracy compared to using only the text or only the answer. Results indicate that the full demonstration context is critical for effective knowledge transfer, with the text-and-answers condition achieving 89% accuracy, substantially outperforming the only-text condition at 75% and the only-answers condition at 37%.
The authors compare SFT, CPT, and SDFT using the Qwen2.5 7B-Instruct model, with SDFT using an exponential moving average (EMA) teacher and on-policy learning. SDFT achieves better performance than SFT and CPT by leveraging demonstration-conditioned teacher signals and on-policy distillation, which reduces catastrophic forgetting and improves both in-distribution and out-of-distribution accuracy.
The authors use a demonstration-conditioned teacher policy to train reasoning models without explicit reasoning data, comparing standard SFT and their SDFT method on a medical task with answer-only supervision. Results show that SDFT improves accuracy from 31.2% to 43.7% while maintaining reasoning depth, whereas SFT degrades both performance and response length.