Command Palette
Search for a command to run...
Zu einer ausführungsgrundlegenden automatisierten KI-Forschung
Zu einer ausführungsgrundlegenden automatisierten KI-Forschung
Chenglei Si Zitong Yang Yejin Choi Emmanuel Candès Diyi Yang Tatsunori Hashimoto
Zusammenfassung
Automatisierte KI-Forschung birgt großes Potenzial, wissenschaftliche Entdeckungen zu beschleunigen. Allerdings generieren derzeit verwendete große Sprachmodelle (LLMs) oft plausibel erscheinende, aber ineffektive Ideen. Die Ausführungsgrounding-Strategie könnte Abhilfe schaffen, doch unklar ist, ob eine automatisierte Ausführung tatsächlich durchführbar ist und ob LLMs aus Rückmeldungen der Ausführung lernen können. Um diese Fragen zu untersuchen, bauen wir zunächst einen automatisierten Ausführer, um Ideen zu implementieren, und starten großskalige parallele GPU-Experimente, um deren Wirksamkeit zu überprüfen. Anschließend transformieren wir zwei realistische Forschungsfragen – die Vor- und Nachtrainierung von LLMs – in Ausführungsumgebungen und zeigen, dass unser automatisierter Ausführer einen großen Anteil der von fortschrittlichen LLMs generierten Ideen umsetzen kann. Wir analysieren zwei Ansätze, um aus Ausführungsrückmeldungen zu lernen: evolutionäre Suche und Verstärkendes Lernen. Die ausführungsgeleitete evolutionäre Suche erweist sich als sehr dateneffizient: Sie findet eine Methode, die die GRPO-Benchmark-Methode bei der Nachtrainierung deutlich übertrifft (69,4 % gegenüber 48,0 %), und entwirft ein Vortrainierungsrezept, das die nanoGPT-Benchmark-Methode bei der Vortrainierung übertrifft (19,7 Minuten gegenüber 35,9 Minuten), alles innerhalb nur zehn Such-Generationen. Fortschrittliche LLMs generieren während der Suche oft sinnvolle algorithmische Ideen, neigen aber dazu, frühzeitig zu saturieren und nur gelegentlich Skalierungstendenzen zu zeigen. Im Gegensatz dazu leidet das Verstärkende Lernen aus Ausführungsrückmeldungen unter Modus-Kollaps: Es verbessert zwar den Durchschnittswert der Ideen-Generierungsmodelle, nicht jedoch die obere Grenze, da die Modelle sich auf einfache Ideen konzentrieren. Durch eine detaillierte Analyse der ausgeführten Ideen und der Trainingsdynamik legen wir die Grundlage für zukünftige Bemühungen im Bereich der ausführungsgeleiteten, automatisierten KI-Forschung.
One-sentence Summary
Chenglei Si, Zitong Yang, and colleagues from Stanford propose an automated executor for AI research that tests LLM-generated ideas via GPU experiments, using evolutionary search to efficiently outperform baselines in LLM pre- and post-training, while revealing limitations in reinforcement learning and early saturation of frontier models.
Key Contributions
- We introduce a scalable automated executor that implements and evaluates LLM-generated research ideas for open-ended problems like LLM pre-training and post-training, achieving over 90% execution success with frontier models such as Claude-4.5-Opus.
- Execution-guided evolutionary search proves sample-efficient, discovering post-training and pre-training recipes that significantly outperform baselines (69.4% vs 48.0% and 19.7 vs 35.9 minutes) within ten epochs, though scaling trends remain limited for most models.
- Reinforcement learning from execution reward improves average idea quality but suffers from mode collapse, converging to simple, low-diversity ideas and failing to enhance the upper-bound performance critical for scientific discovery.
Introduction
The authors leverage large language models to automate AI research by generating, implementing, and evaluating research ideas through an execution-grounded feedback loop. Prior work in AutoML and LLM-based research agents either operates in constrained search spaces or lacks mechanisms to learn from execution results—limiting their ability to improve idea quality over time. The authors’ main contribution is a scalable automated executor that implements and runs hundreds of LLM-generated ideas in parallel for open-ended problems like LLM pre-training and post-training, achieving over 90% execution rates. They use this system to train ideators via evolutionary search and reinforcement learning, finding that evolutionary search efficiently discovers high-performing ideas while RL suffers from diversity collapse and fails to improve peak performance. Their work demonstrates feasibility and exposes key limitations for future systems to address.
Dataset

The authors use two research environments to train and evaluate their automated idea executor:
-
Pre-Training Environment (nanoGPT)
- Source: Adapted from the nanoGPT speedrun (Jordan et al., 2024), using a 124M GPT-2 model trained on FineWeb corpus (Penedo et al., 2024).
- Objective: Optimize for validation loss (or its reciprocal, 1/loss) under a fixed 25-minute wall-clock budget on 8 H100 GPUs.
- Modifications:
- Proxy reward (1/loss) replaces raw training time as the optimization target.
- Evaluation hyperparameters are frozen; inference is restricted to single-token prediction to prevent attention-based reward hacking.
- Final validation uses a locked inference function to ensure fair comparison with human solutions on the original leaderboard.
-
Post-Training Environment (GRPO)
- Source: Baseline GRPO algorithm (Shao et al., 2024) finetuning Qwen2.5-Math-1.5B (Yang et al., 2024) on MATH dataset (Hendrycks et al., 2021).
- Objective: Maximize validation accuracy on MATH within a fixed wall-clock time.
- Safeguards: Validation code is isolated in a separate file; the executor cannot access or modify it to prevent reward manipulation.
-
General Setup
- Both environments allow unrestricted ideation scope—from hyperparameter tuning to novel architectures or training methods.
- No constraints are imposed on the types of improvements the ideator model can propose.
- The environments are designed to be open-ended yet measurable, combining innovation space with clear benchmarking.
Method
The system architecture consists of two primary components: the Automated Idea Executor and the Automated AI Researcher, which operate in a closed-loop feedback system. The Automated Idea Executor functions as a high-level API that transforms a batch of natural language ideas into benchmark performance metrics. This component is composed of three core modules: the Implementer, Scheduler, and Worker. The Implementer, hosted on a CPU machine with high I/O capacity, receives a batch of natural language ideas and generates executable code changes. It makes parallelized API calls to a code execution LLM, prompting it with both the idea and the baseline codebase to sample multiple code diff files. To ensure patchability, the model undergoes a sequential self-revision process up to two times, returning the first successfully applied diff. The patched codebase is then uploaded as a .zip file to a cloud bucket. The Scheduler, operating under a fixed clock frequency, periodically downloads new codebases from the cloud. For unexecuted codebases, it assesses the resource requirements of the research environment and prepares a job configuration. The Worker, a GPU-equipped cluster, connects to available resources upon receiving a job configuration from the Scheduler. It runs the experiment and uploads the results, including performance metrics and full metadata (idea content, code change, execution log), to a cloud bucket (e.g., wandb). The Automated AI Researcher, which includes the ideator model, receives the experiment results and uses them to update the ideator via reinforcement learning or evolutionary search, generating new natural language ideas to continue the cycle. 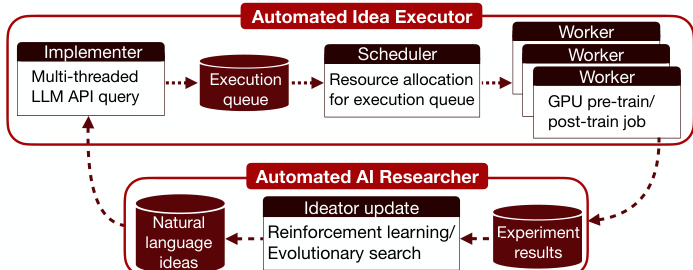
Experiment
- Built automated executor to implement LLM-generated ideas and validate them via GPU experiments on LLM pre-training and post-training tasks.
- Execution-guided evolutionary search found superior methods: 69.4% accuracy on GRPO (vs 48.0% baseline) and 19.7 min training time on nanoGPT (vs 35.9 min baseline) within 10 epochs.
- Claude-4.5-Sonnet and Claude-4.5-Opus achieved high execution rates (up to 90%) and outperformed baselines in best-of-50 sampling; GPT-5 showed lower execution rates.
- When using GPT-5 as executor, open-weight models like Qwen3-235B still achieved non-trivial completion rates and outperformed baselines.
- Evolutionary search outperformed best-of-N sampling under equal budget, showing effective use of feedback across epochs.
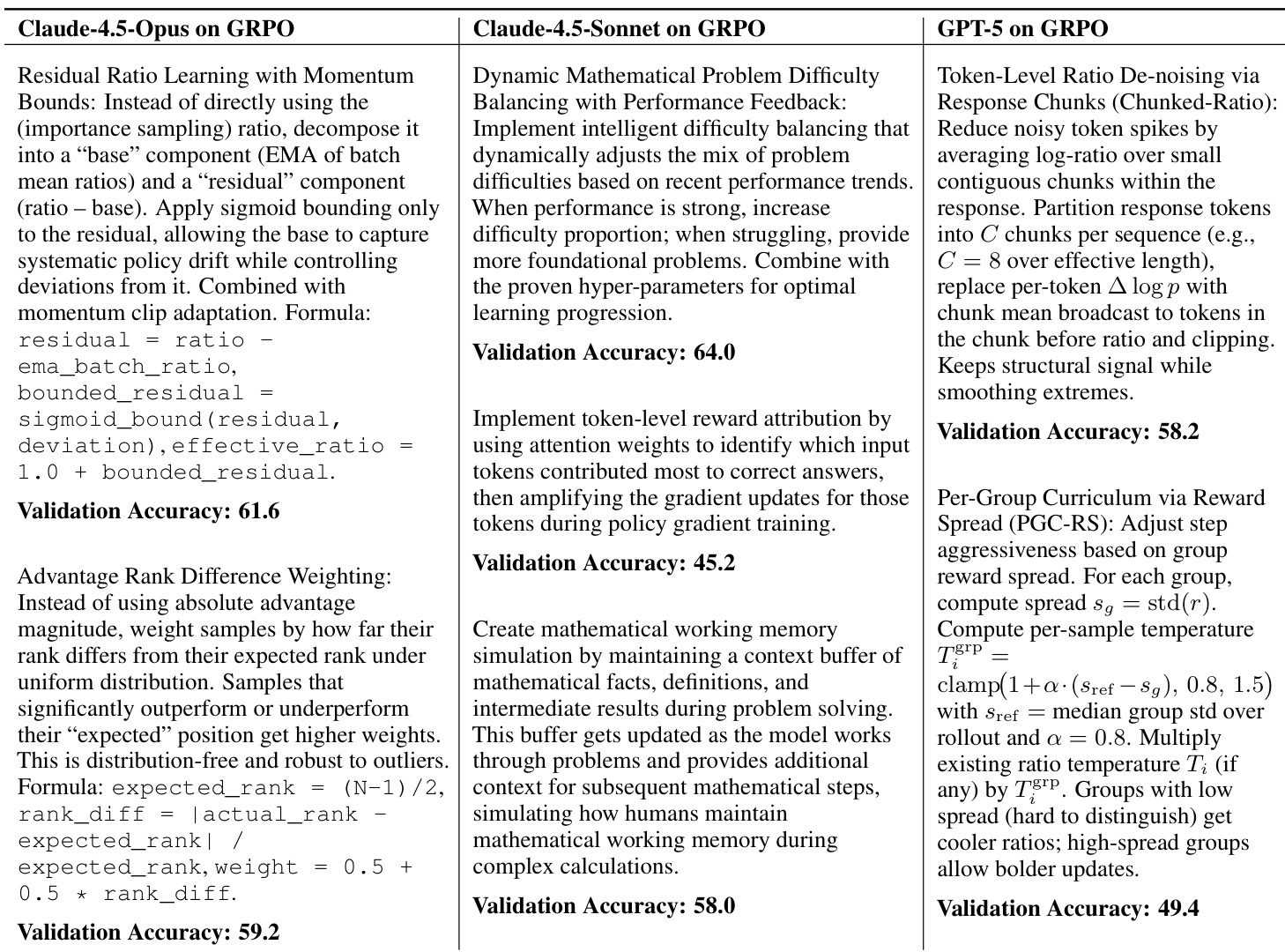
- Claude-4.5-Opus showed scaling trends; Claude-4.5-Sonnet saturated early but found optimal hyper-parameter combinations.
- RL from execution reward improved average performance but caused mode collapse, converging on simple ideas (e.g., RMSNorm→LayerNorm, EMA) without improving upper-bound performance.
- RL training reduced thinking trace length, correlating with higher execution rates but lower idea complexity.
- Models generated algorithmic ideas resembling recent research papers, suggesting potential to support frontier AI research.
- Top solutions from evolutionary search surpassed human expert benchmarks on GRPO (69.4% vs 68.8%) but lagged behind human speedrun on nanoGPT (19.7 min vs 2.1 min).
Results show that execution-guided search achieves a validation accuracy of 69.4% on the post-training task, significantly outperforming the baseline of 48.0% and surpassing the best human expert's result of 68.8%. On the pre-training task, the search reduces training time to 19.7 minutes, improving upon the baseline of 35.9 minutes and approaching the best human solution of 2.1 minutes.
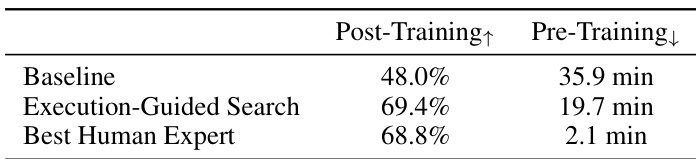
The authors use an automated executor to evaluate and optimize ideas generated by large language models in two environments: GRPO for post-training and nanoGPT for pre-training. Results show that execution-guided evolutionary search enables models to discover high-performing solutions, with Claude-4.5-Sonnet achieving 69.4% accuracy on GRPO and Claude-4.5-Opus reaching a validation loss of 3.1407 on nanoGPT, both outperforming their respective baselines.
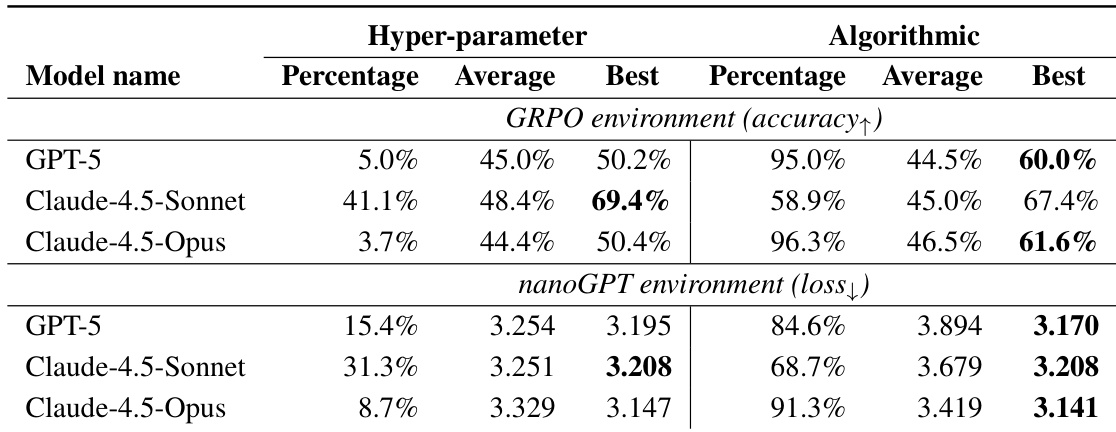
The authors use an automated executor to evaluate and refine ideas generated by large language models for improving LLM training methods. Results show that execution-guided evolutionary search enables models like Claude-4.5-Opus and Claude-4.5-Sonnet to discover methods that significantly outperform baseline approaches, with Claude-4.5-Sonnet achieving a validation accuracy of 69.4% on the GRPO task and Claude-4.5-Opus reducing training time by 45% on the nanoGPT task.