Command Palette
Search for a command to run...
TwinBrainVLA: Freisetzen des Potenzials von Generalist-VLMs für verkörperte Aufgaben mittels asymmetrischer Mixture-of-Transformers
TwinBrainVLA: Freisetzen des Potenzials von Generalist-VLMs für verkörperte Aufgaben mittels asymmetrischer Mixture-of-Transformers
Zusammenfassung
Standard Vision-Language-Action (VLA)-Modelle feinabstimmen typischerweise einen monolithischen Vision-Language-Model (VLM)-Backbone explizit für die Steuerung von Robotern. Dieser Ansatz erzeugt jedoch einen kritischen Widerspruch zwischen der Aufrechterhaltung eines hochwertigen, allgemeinen semantischen Verständnisses und der Lernfähigkeit für niedrigstufige, feinabgestimmte sensorimotorische Fähigkeiten, was häufig zu einem „katastrophalen Vergessen“ der offenen Welt-Fähigkeiten des Modells führt. Um diesen Konflikt zu lösen, stellen wir TwinBrainVLA vor – eine neuartige Architektur, die einen Generalisten-VLM, der ein universelles semantisches Verständnis bewahrt, mit einem Spezialisten-VLM zur verkörpernden Propriozeption für eine gemeinsame robotische Steuerung koordiniert. TwinBrainVLA verbindet dabei einen gefrorenen „Linken Hirn“ – der robuste allgemeine visuelle Schlussfolgerungsfähigkeiten bewahrt – mit einem trainierbaren „Rechten Hirn“, das auf verkörpernde Wahrnehmung spezialisiert ist, über eine neuartige asymmetrische Mischung aus Transformers (Asymmetric Mixture-of-Transformers, AsyMoT). Diese Architektur ermöglicht es dem Rechten Hirn, dynamisch semantisches Wissen aus dem gefrorenen Linken Hirn abzurufen und es mit propriozeptiven Zuständen zu fusionieren, wodurch eine reichhaltige Bedingung für einen Flow-Matching-Aktions-Experten bereitgestellt wird, der präzise kontinuierliche Steuerungsbefehle generiert. Ausführliche Experimente auf den Benchmarks SimplerEnv und RoboCasa zeigen, dass TwinBrainVLA eine überlegene Manipulationsleistung im Vergleich zu aktuellen State-of-the-Art-Baselines erzielt, während gleichzeitig die umfassenden visuellen Verständnisfähigkeiten des vortrainierten VLM explizit bewahrt werden. Dies eröffnet einen vielversprechenden Ansatz für die Entwicklung allgemein einsetzbarer Roboter, die gleichzeitig ein hohes Maß an semantischem Verständnis und feinmotorischer Geschicklichkeit erreichen.
One-sentence Summary
Researchers from HIT, ZGCA, and collaborators propose TwinBrainVLA, a dual-brain VLA architecture using AsyMoT to fuse frozen semantic understanding with trainable proprioception, enabling robots to master precise control without forgetting open-world vision, validated on SimplerEnv and RoboCasa.
Key Contributions
- TwinBrainVLA introduces a dual-stream VLA architecture that decouples general semantic understanding (frozen Left Brain) from embodied perception (trainable Right Brain), resolving the catastrophic forgetting caused by fine-tuning monolithic VLMs for robotic control.
- It employs an Asymmetric Mixture-of-Transformers (AsyMoT) mechanism to enable dynamic cross-stream attention between the two VLM pathways, allowing the Right Brain to fuse proprioceptive states with semantic knowledge from the Left Brain for precise action generation.
- Evaluated on SimplerEnv and RoboCasa, TwinBrainVLA outperforms state-of-the-art baselines in manipulation tasks while preserving the pre-trained VLM’s open-world visual understanding, validating its effectiveness for general-purpose robotic control.
Introduction
The authors leverage a dual-brain architecture to resolve the core conflict in Vision-Language-Action (VLA) models: the trade-off between preserving general semantic understanding and acquiring precise sensorimotor control. Prior VLA approaches fine-tune a single VLM backbone for robotics, which often causes catastrophic forgetting of open-world capabilities—undermining the very generalization they aim to exploit. TwinBrainVLA introduces an asymmetric design with a frozen “Left Brain” for semantic reasoning and a trainable “Right Brain” for embodied perception, fused via a novel Asymmetric Mixture-of-Transformers (AsyMoT) mechanism. This enables the system to generate accurate continuous actions while explicitly retaining the pre-trained VLM’s broad visual and linguistic understanding, validated across SimplerEnv and RoboCasa benchmarks.
Method
The authors leverage a dual-stream architecture to disentangle high-level semantic reasoning from fine-grained sensorimotor control, addressing the challenge of catastrophic forgetting in vision-language models for embodied tasks. The framework, named TwinBrainVLA, consists of two distinct pathways: a frozen "Left Brain" and a trainable "Right Brain," which interact through a novel Asymmetric Mixture-of-Transformers (AsyMoT) mechanism. The Left Brain functions as a generalist, preserving open-world visual-linguistic knowledge, while the Right Brain specializes in embodied motor control, integrating visual, textual, and proprioceptive inputs. This separation enables the model to maintain general semantic capabilities while allowing the control stream to adapt to specific robotic tasks without interference.
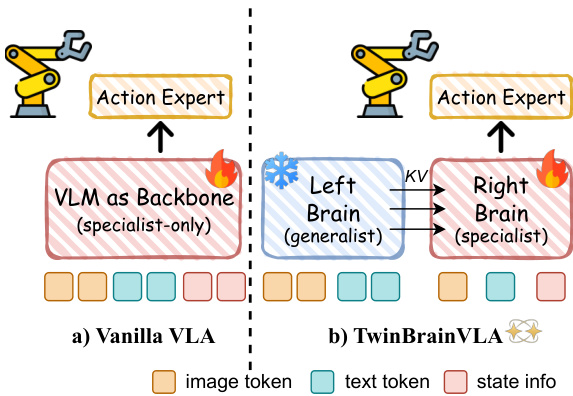
As shown in the figure below, the overall architecture of TwinBrainVLA features an asymmetric dual-stream design. The Left Brain processes only visual and textual inputs, receiving a sequence of image and text tokens derived from the vision encoder V(I) and text tokenizer T(T). This stream remains frozen during training, ensuring that its pre-trained semantic knowledge is preserved. In contrast, the Right Brain processes a multimodal input sequence that includes visual tokens, text tokens, and a projection of the robot's proprioceptive state s, encoded by a lightweight MLP state encoder ϕ. This design allows the Right Brain to ground its reasoning in the robot's physical configuration, a critical requirement for closed-loop control.
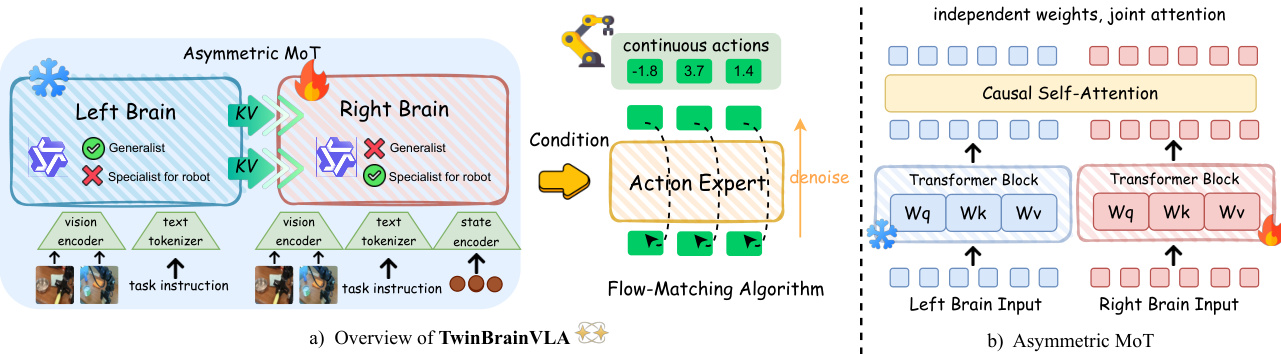
The core innovation lies in the AsyMoT mechanism, which enables the Right Brain to attend to the frozen key-value (KV) pairs of the Left Brain while maintaining its own trainable parameters. At each layer, the Left Brain computes its hidden states independently using its frozen self-attention mechanism. The Right Brain, however, employs an asymmetric joint attention mechanism where its query QR attends to a concatenated key and value set formed by the Left Brain's KV pairs (with stop-gradient applied) and its own KV pairs. This asymmetric flow ensures that the Right Brain can leverage high-level semantic features from the Left Brain without corrupting them, establishing a strict hierarchy where the Left Brain acts as a stable semantic anchor.
The final hidden states of the Right Brain, HRfinal, are passed to an Action Expert, which generates continuous robotic actions. The Action Expert is a Diffusion Transformer (DiT) architecture trained via a flow-matching objective. It operates as a conditional decoder that denoises a noisy action trajectory, conditioned on the Right Brain's representations. The flow-matching loss is defined as the expected squared error between the DiT's predicted vector field and the straight-line target vector field from a standard Gaussian prior to the ground-truth action distribution. During inference, actions are synthesized by solving the corresponding ordinary differential equation.
The training strategy is designed to preserve the generalist capabilities of the Left Brain. The total loss is solely the flow-matching loss, minimizing the discrepancy between the generated and ground-truth actions. The optimization is constrained by an asymmetric update rule: gradients are blocked at the AsyMoT fusion layer, preventing any backpropagation into the Left Brain's parameters. This ensures that the Right Brain and the state encoder can specialize in control dynamics, while the frozen Left Brain implicitly safeguards the model's general semantic priors.
Experiment
- Evaluated TwinBrainVLA on SimplerEnv and RoboCasa simulation benchmarks using 16× H100 GPUs under starVLA framework; training followed default protocols for fair comparison.
- On SimplerEnv with WidowX robot, TwinBrainVLA (Qwen3-VL-4B-Instruct) achieved 62.0% success rate across 4 tasks, surpassing Isaac-GR00T-N1.6 (57.1%) by +4.9%, validating asymmetric dual-brain design.
- On RoboCasa GR1 Tabletop Benchmark (24 tasks), TwinBrainVLA (Qwen3-VL-4B-Instruct) reached 54.6% Avg@50 success rate, outperforming Isaac-GR00T-N1.6 (47.6%) by +7.0%, QwenGR00T (47.8%) by +6.8%, and QwenPI (43.9%) by +10.7%.
- Model trained on Bridge-V2 and Fractal subsets of OXE dataset; uses AdamW, 40k steps, 1e-5 LR, DeepSpeed ZeRO-2, and gradient clipping; supports Qwen2.5-VL-3B and Qwen3-VL-4B backbones.
The authors use TwinBrainVLA with Qwen3-VL-4B-Instruct to achieve the highest average success rate of 54.6% on the RoboCasa GR1 Tabletop Benchmark, outperforming all baselines including Isaac-GR00T-N1.6 by 7.0 percentage points. Results show that the asymmetric dual-brain architecture enables superior performance in complex tabletop manipulation tasks compared to models trained with the same dataset and backbone.
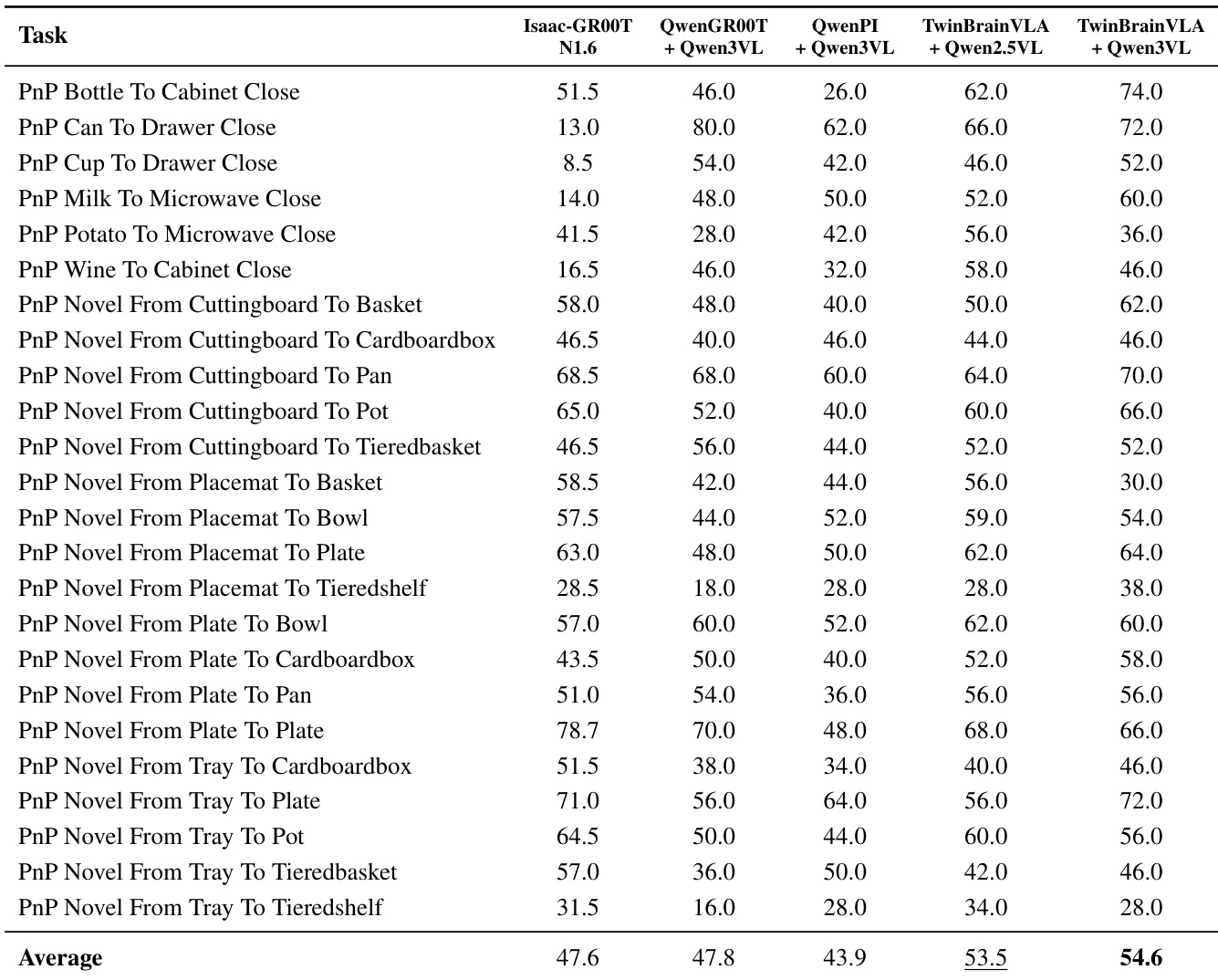
The authors use TwinBrainVLA with Qwen2.5-VL-3B-Instruct and Qwen3-VL-4B-Instruct backbones to evaluate performance on SimplerEnv, achieving state-of-the-art results with success rates of 58.4% and 62.0% respectively. Results show that TwinBrainVLA surpasses the strongest baseline, Isaac-GR00T-N1.6, by +4.9% on average, demonstrating the effectiveness of its asymmetric dual-brain architecture in combining high-level semantic understanding with low-level robotic control.