Command Palette
Search for a command to run...
ACoT-VLA: Action Chain-of-Thought für Vision-Language-Action-Modelle
ACoT-VLA: Action Chain-of-Thought für Vision-Language-Action-Modelle
Linqing Zhong Yi Liu Yifei Wei Ziyu Xiong Maoqing Yao Si Liu Guanghui Ren
Zusammenfassung
Vision-Language-Action (VLA)-Modelle sind als universelle Roboterpolitiken für vielfältige Manipulationsaufgaben hervorgetreten und basieren traditionell auf der direkten Übersetzung multimodaler Eingaben in Aktionen mittels Vision-Language-Model (VLM)-Einbettungen. In jüngster Zeit wurden explizite Zwischenschritte zur Reasoning-Prozessierung eingeführt, wie beispielsweise die Vorhersage von Teil-Aufgaben (in Sprache) oder die Synthese von Zielbildern (in Vision), um die Aktionserzeugung zu leiten. Diese Zwischen-Reasoning-Phasen sind jedoch oft indirekt und beschränkt in ihrer Fähigkeit, die vollständigen und fein granulären Informationen bereitzustellen, die für eine präzise Aktionserfüllung erforderlich sind. Stattdessen vermuten wir, dass die effektivste Form von Reasoning direkt im Aktionsraum erfolgt. Wir stellen ACoT (Action Chain-of-Thought) vor, ein Paradigma, bei dem der Reasoning-Prozess selbst als strukturierte Folge grober Aktionsabsichten formuliert wird, die die finale Policy leiten. In diesem Artikel präsentieren wir ACoT-VLA, eine neuartige Architektur, die das ACoT-Paradigma konkretisiert. Konkret führen wir zwei ergänzende Komponenten ein: einen expliziten Aktions-Reasoner (EAR) und einen impliziten Aktions-Reasoner (IAR). Ersterer schlägt grobe Referenztrajektorien als explizite, aktionsbasierte Schlussfolgerungsschritte vor, während letzterer latente Aktionsprioritäten aus den internen Darstellungen multimodaler Eingaben extrahiert und gemeinsam mit dem EAR eine ACoT bildet, die die nachgeschaltete Aktionshead bedingt und eine fundierte Policy-Lernung ermöglicht. Umfangreiche Experimente in realen und simulierten Umgebungen belegen die Überlegenheit unseres Ansatzes, der jeweils 98,5 %, 84,1 % und 47,4 % auf LIBERO, LIBERO-Plus und VLABench erreicht.
One-sentence Summary
The authors from Beihang University and AgiBot propose ACoT-VLA, a novel VLA architecture that advances robot policy learning by introducing Action Chain-of-Thought reasoning, where explicit coarse action intents and implicit latent action priors jointly guide precise action generation, outperforming prior methods on LIBERO, LIBERO-Plus, and VLABench benchmarks.
Key Contributions
-
The paper addresses the semantic-kinematic gap in vision-language-action models by introducing Action Chain-of-Thought (ACoT), a novel paradigm that formulates reasoning as a sequence of coarse action intents directly in the action space, enabling more grounded and precise robot policy learning compared to prior language- or vision-based intermediate reasoning.
-
To realize ACoT, the authors propose ACoT-VLA, which integrates two complementary components: an Explicit Action Reasoner (EAR) that generates coarse reference trajectories from multimodal inputs, and an Implicit Action Reasoner (IAR) that infers latent action priors via cross-attention, together providing rich, action-space guidance for policy execution.
-
Extensive experiments across real-world and simulation environments demonstrate the method's effectiveness, achieving state-of-the-art success rates of 98.5%, 84.1%, and 47.4% on LIBERO, LIBERO-Plus, and VLABench benchmarks, respectively.
Introduction
The authors address the challenge of bridging the semantic-kinematic gap in vision-language-action (VLA) models, where high-level, abstract inputs from vision and language fail to provide precise, low-level action guidance for robotic control. Prior approaches rely on reasoning in language or visual spaces—either generating sub-tasks via language chains or simulating future states with world models—both of which offer indirect, suboptimal guidance for action execution. This limits generalization and physical grounding in real-world robotic tasks. To overcome this, the authors introduce Action Chain-of-Thought (ACoT), a novel paradigm that redefines reasoning as a sequence of explicit, kinematically grounded action intents directly in the action space. They propose ACoT-VLA, a unified framework featuring two complementary modules: the Explicit Action Reasoner (EAR), which synthesizes coarse motion trajectories from multimodal inputs, and the Implicit Action Reasoner (IAR), which infers latent action priors via cross-attention between downsampled inputs and learnable queries. This dual mechanism enables direct, rich action-space guidance, significantly improving policy performance. Experiments across simulation and real-world benchmarks demonstrate state-of-the-art results, with success rates of 98.5%, 84.1%, and 47.4% on LIBERO, LIBERO-Plus, and VLABench, respectively.
Dataset

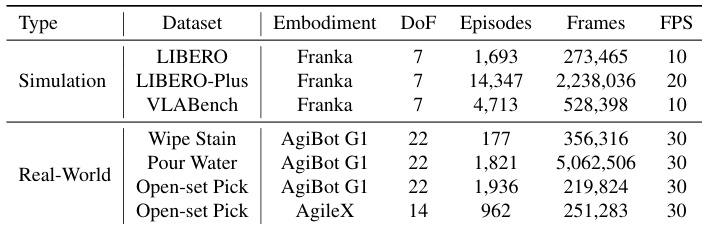
- The dataset comprises three public simulation benchmarks—LIBERO, LIBERO-Plus, and VLABench—and custom-collected real-world data from three tasks: Wipe Stain, Pour Water, and Open-set Pick.
- LIBERO includes 1,693 episodes and 273,465 frames at 10 Hz, featuring uniform trajectory lengths and smooth motion patterns, widely used as a standard benchmark.
- LIBERO-Plus contains 14,347 episodes and 2,238,036 frames at 20 Hz, designed with perturbation-oriented variations in motion magnitude and camera–robot viewpoints to challenge policy generalization under structured distribution shifts.
- VLABench’s training set consists of 4,713 episodes and 528,398 frames at 10 Hz, requiring advanced visual and physical reasoning due to complex task dynamics.
- Real-world data includes 177 episodes (356,316 frames) for Wipe Stain, characterized by dense tool-surface contact and fine-grained force control; 1,821 episodes (5,062,506 frames) for Pour Water, with long-horizon, multi-stage execution; and Open-set Pick with 1,936 episodes (219,824 frames) from AgiBot G1 and 962 episodes (251,283 frames) from AgileX, both featuring diverse tabletop layouts and natural-language instructions.
- The authors use a mixture of these datasets for training, with training splits derived from the full episode collections and mixture ratios adjusted to balance task complexity and scale.
- Data is processed with consistent frame sampling and temporal alignment; for real-world tasks, episodes are filtered to ensure task completion and valid demonstrations.
- No explicit cropping is applied, but visual inputs are standardized to a fixed resolution during training.
- Metadata such as task type, platform, and instruction modality are constructed to support multi-task learning and evaluation.
Method
The authors introduce ACoT-VLA, a novel architecture that implements the Action Chain-of-Thought (ACoT) paradigm by formulating reasoning as a structured sequence of coarse action intents within the action space. The framework is built upon a shared pre-trained Vision-Language Model (VLM) backbone, which processes the natural language instruction and current visual observation to generate a contextual key-value cache. This cache serves as the foundation for two complementary action reasoners: the Explicit Action Reasoner (EAR) and the Implicit Action Reasoner (IAR), which provide distinct forms of action-space guidance. The overall architecture is designed to synergistically integrate these explicit and implicit cues to condition the final action prediction.

As shown in the figure below, the framework consists of three main components operating on features from a shared VLM backbone. The first component, the Explicit Action Reasoner (EAR), is a light-weight transformer module that synthesizes a coarse reference trajectory to provide explicit action-space guidance. The second component, the Implicit Action Reasoner (IAR), employs a cross-attention mechanism with learnable queries to extract latent action priors from the VLM's internal representations. The final component, the Action-Guided Prediction (AGP) head, synergistically integrates both explicit and implicit guidances via cross-attention to condition the final denoising process, producing the executable action sequence.
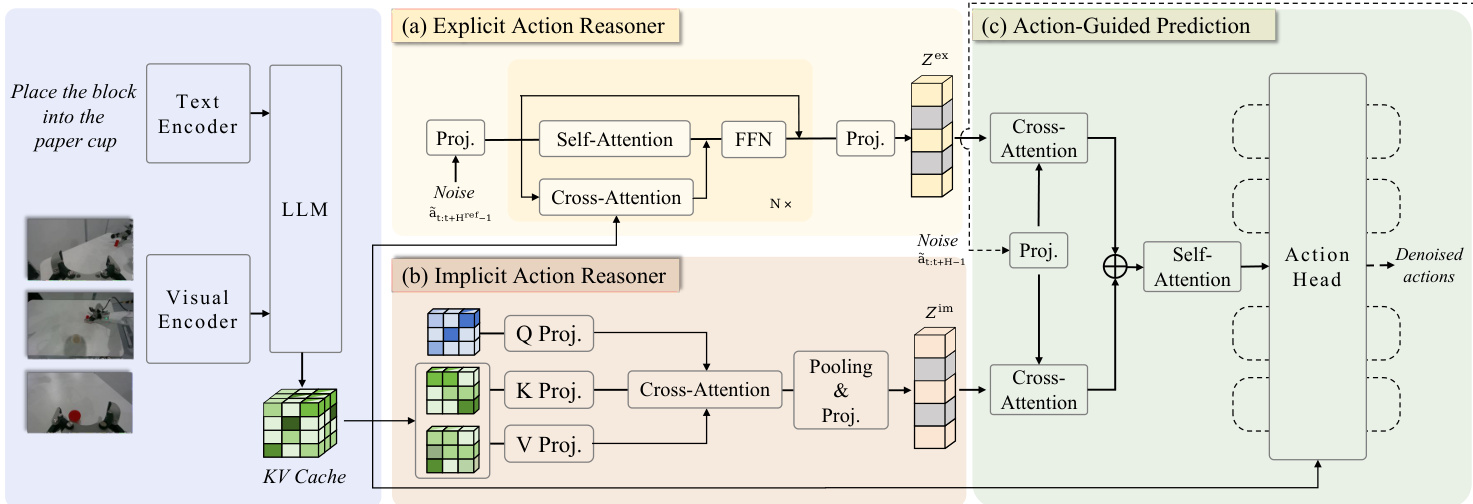
The Explicit Action Reasoner (EAR) operates by taking a noisy action sequence as input and generating a denoised reference action sequence. This process begins with the VLM encoding the instruction and observation into a contextual key-value cache. The EAR, denoted as πθref, then processes the noisy action sequence through a series of transformer layers. At each layer, self-attention captures temporal dependencies within the action sequence, while cross-attention with the VLM's key-value cache injects multimodal contextual priors. The intermediate representation is updated by a feed-forward network in a residual-parallel manner. Through training via flow matching, the EAR learns a distribution over action trajectories, producing a denoised action sequence that is then encoded into an action embedding Zex, serving as explicit action-space guidance.
The Implicit Action Reasoner (IAR) directly operates on the VLM's key-value cache to extract latent action priors. For each VLM layer, a learnable query matrix is initialized, and the corresponding key-value pairs are downsampled into a lower-dimensional space using learnable linear projectors. Cross-attention is then applied to extract action-relevant information from each layer's downsampled key-value pairs. The resulting features are integrated via average pooling and transformed through a MLP projector to produce a compact representation ziim that captures implicit action semantics. By aggregating these representations across all layers, the IAR obtains an implicit action-related feature Zim, which complements the explicit motion priors.
The Action-Guided Prediction (AGP) strategy incorporates both the explicit and implicit action guidances into policy learning. Given a noisy action segment, it is first encoded into a noisy action embedding, which serves as an action query. This query interacts with both Zex and Zim through dual cross-attention operations to retrieve complementary priors. The attended representations, Sex and Sim, are then concatenated and processed through a self-attention fusion block to integrate the priors into a unified representation hˉ. This aggregated representation is finally fed into the action head, which predicts the denoised action sequence. The entire framework is optimized under a standard flow-matching mean-squared error objective, with separate losses for the EAR and the action head.
Experiment
- Evaluated on LIBERO, LIBERO-Plus, and VLABench simulation benchmarks: Achieved state-of-the-art performance, with a 1.6% absolute improvement in average success rate over π₀.₅ on LIBERO, and significant gains under perturbations (e.g., +16.3% on robot initial-state shifts in LIBERO-Plus), demonstrating enhanced robustness and generalization.
- On VLABench, achieved the best results in both Intention Score (IS) and Progress Score (PS), with +12.6% IS and +7.2% PS on the unseen-texture track, highlighting strong resistance to distributional shifts.
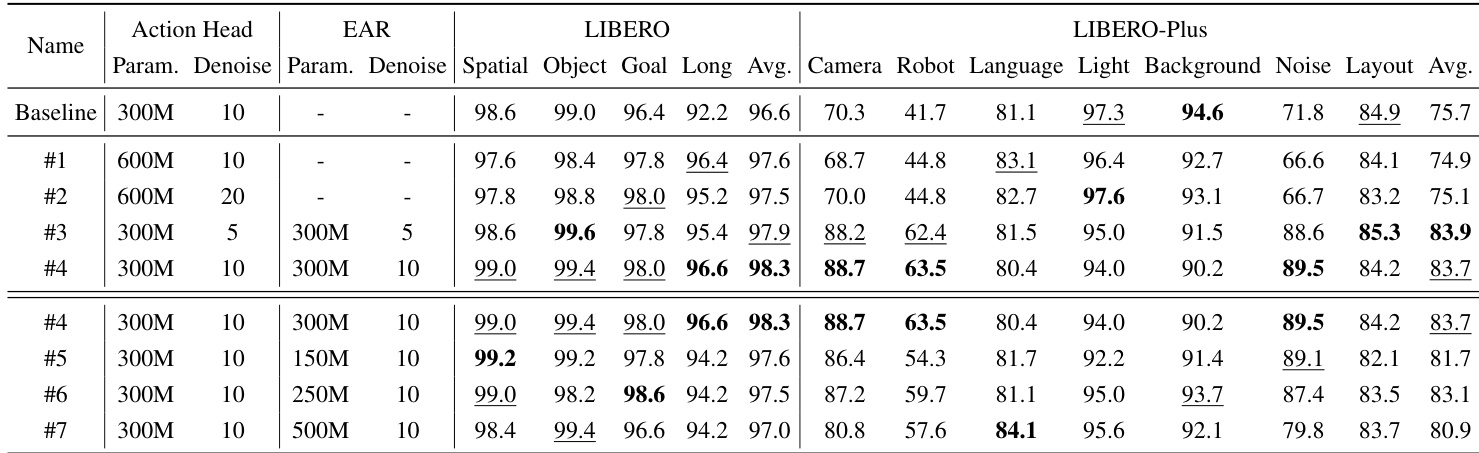
- Ablation studies on LIBERO and LIBERO-Plus confirmed that both Explicit Action Reasoner (EAR) and Implicit Action Reasoner (IAR) modules contribute significantly, with EAR + IAR achieving 98.5% success rate—showing complementary benefits from explicit action guidance and implicit action cues from VLM’s key-value cache.
- Real-world deployment on AgiBot G1 and AgileX robots achieved 66.7% success rate across three tasks (Wipe Stain, Pour Water, Open-set Pick), outperforming π₀.₅ (61.0%) and π₀ (33.8%), validating effectiveness and cross-embodiment adaptability under real sensing and actuation noise.
The authors use the LIBERO benchmark to evaluate their approach, comparing it against various state-of-the-art methods across four task suites. Results show that their method achieves the highest average success rate of 98.5%, outperforming all baselines, particularly in the Long-horizon manipulation tasks, where it achieves a 96.0% success rate, demonstrating the effectiveness of action-space guidance.
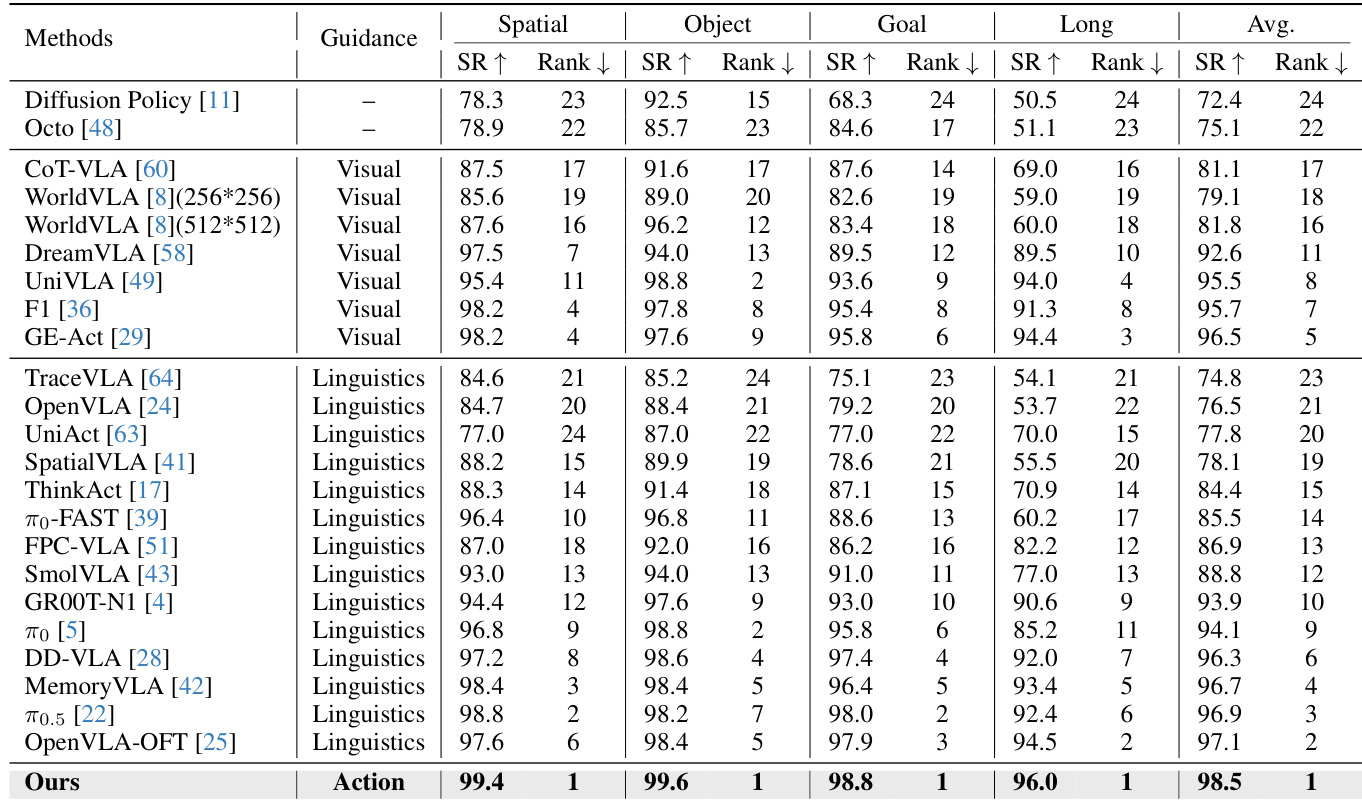
Results show that the proposed method outperforms the baseline approaches across all evaluation tracks on the VLABench benchmark. The authors achieve the highest average success rate of 63.5% and 47.4% in Intention Score and Progress Score, respectively, demonstrating significant improvements in both in-distribution and out-of-distribution settings.

The authors use a unified training setup across simulation and real-world benchmarks, with varying action horizons and control types depending on the environment. Results show that their approach achieves higher average success rates in real-world tasks compared to baseline methods, demonstrating effectiveness under real-world sensing conditions and adaptability across different robotic embodiments.
The authors use the LIBERO benchmark to evaluate the impact of their proposed modules, showing that adding the Explicit Action Reasoner (EAR) and Implicit Action Reasoner (IAR) improves performance across all task suites. Results show that combining both modules achieves the highest average success rate of 98.5%, with significant gains in the Long-horizon suite, indicating that explicit and implicit action guidance are complementary for robust policy learning.
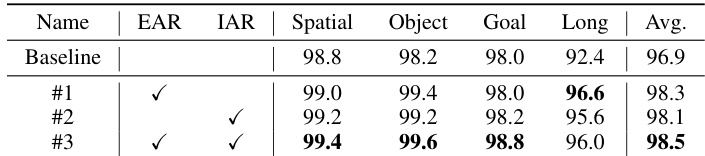
The authors use the LIBERO and LIBERO-Plus benchmarks to evaluate their approach, with results showing that their method consistently outperforms the baseline across all task suites and perturbation conditions. The proposed approach achieves the highest success rates on both benchmarks, particularly excelling in long-horizon tasks and under challenging perturbations such as camera-viewpoint shifts and sensor noise, demonstrating the effectiveness of action-space guidance.