Command Palette
Search for a command to run...
Schlussfolgerungsmodelle erzeugen Gesellschaften des Denkens
Schlussfolgerungsmodelle erzeugen Gesellschaften des Denkens
Junsol Kim Shiyang Lai Nino Scherrer Blaise Agüera y Arcas James Evans
Zusammenfassung
Große Sprachmodelle haben beachtliche Fähigkeiten in verschiedenen Bereichen erzielt, doch die zugrundeliegenden Mechanismen komplexer Denkprozesse bleiben weiterhin unklar. Neuere Denkmodelle übertrumpfen vergleichbare instruktionsangepasste Modelle bei anspruchsvollen kognitiven Aufgaben, was auf eine erweiterte Berechnung durch längere Denkketten zurückgeführt wird. In dieser Arbeit zeigen wir, dass die verbesserte Denkfähigkeit nicht allein durch eine verlängerte Berechnung entsteht, sondern vielmehr durch die Simulation von interaktiven, multi-Agenten-artigen Prozessen – einer „Gesellschaft des Denkens“ –, die Vielfalt und Diskussion innerhalb interner kognitiver Perspektiven ermöglicht, die sich durch unterschiedliche Persönlichkeitsmerkmale und fachliche Expertise auszeichnen. Durch quantitative Analysen und mechanistische Interpretierbarkeitsmethoden, angewandt auf Denkverläufe, stellen wir fest, dass Denkmodelle wie DeepSeek-R1 und QwQ-32B eine deutlich größere Perspektivenvielfalt aufweisen als instruktionsangepasste Modelle und während des Denkprozesses eine breitere Spannung zwischen heterogenen, personen- und fachgebietsspezifischen Merkmalen aktivieren. Diese multi-Agenten-Struktur zeigt sich in kommunikativen Verhaltensweisen wie Fragen- und Antwort-Interaktionen, Perspektivenwechseln sowie der Versöhnung widersprüchlicher Ansichten, sowie in sozio-emotionalen Rollen, die lebhafte, konfrontative Gespräche charakterisieren – zusammen tragen diese Merkmale zum Leistungsadvantage bei kognitiven Aufgaben bei. Kontrollierte Experimente mit Verstärkungslernen zeigen, dass Basismodelle bei Belohnung ausschließlich für die Genauigkeit des Denkprozesses eine höhere Konversationsfähigkeit entwickeln, und dass die Feinabstimmung mit einer konversationellen Strukturierung die Verbesserung des Denkvermögens gegenüber Basismodellen beschleunigt. Diese Ergebnisse deuten darauf hin, dass die soziale Organisation des Denkens eine effektive Erkundung des Lösungsraums ermöglicht. Wir vermuten, dass Denkmodelle eine rechnerische Parallele zur kollektiven Intelligenz in menschlichen Gruppen darstellen, bei der Vielfalt, wenn systematisch strukturiert, zu überlegener Problemlösung führt – was neue Möglichkeiten für die Organisation von Agenten eröffnet, um das Wissen der Menge nutzbar zu machen.
One-sentence Summary
Google, University of Chicago, and Santa Fe Institute researchers propose that advanced reasoning models like DeepSeek-R1 and QwQ-32B achieve superior performance not through longer chains of thought alone, but by implicitly simulating a "society of thought"—a multi-agent-like dialogue among diverse, personality- and expertise-differentiated internal perspectives. Through mechanistic interpretability and controlled reinforcement learning, they demonstrate that conversational behaviors (e.g., questioning, conflict, reconciliation) and perspective diversity are causally linked to improved accuracy, with steering a discourse marker for surprise doubling reasoning performance. This social organization of thought enables systematic exploration of solution spaces, suggesting that collective intelligence principles—diversity, debate, and role coordination—underlie effective artificial reasoning.
Key Contributions
- Reasoning models like DeepSeek-R1 and QwQ-32B achieve superior performance on complex tasks not merely through longer chains of thought, but by implicitly simulating a "society of thought" — a structured, multi-agent interaction among diverse internal perspectives with distinct personality traits and domain expertise.
- Mechanistic interpretability and quantitative analysis of reasoning traces reveal that these models exhibit significantly higher perspective diversity and conflict between heterogeneous cognitive features, manifesting in conversational behaviors such as perspective shifts, debate, and reconciliation, which directly support effective reasoning strategies.
- Controlled reinforcement learning experiments show that models spontaneously develop more conversational behaviors when rewarded for accuracy, and fine-tuning with conversational scaffolding accelerates reasoning improvement over monologue-based methods, demonstrating that social organization of thought enhances problem-solving through collective intelligence.
Introduction
The authors investigate the mechanisms behind advanced reasoning in large language models, focusing on why models like DeepSeek-R1 and QwQ-32B outperform standard instruction-tuned models on complex tasks. While prior work attributed improved reasoning to longer chains of thought, the authors demonstrate that the key lies not in length but in the emergence of a "society of thought"—an implicit, multi-agent-like dialogue within the model’s reasoning process. This structure involves diverse, simulated perspectives with distinct personalities and expertise, engaging in question-answering, perspective shifts, conflict, and reconciliation, which collectively enhance problem-solving through cognitive diversity and structured debate. Using mechanistic interpretability and controlled reinforcement learning, they show that models spontaneously develop conversational behaviors when rewarded for accuracy, and that fine-tuning with conversational scaffolding accelerates reasoning improvement. The findings suggest that effective AI reasoning arises not from solitary monologues but from the social organization of thought, mirroring principles of collective intelligence in human groups.
Dataset

- The dataset comprises 8,262 reasoning problems drawn from diverse domains, including symbolic logic, mathematical problem solving, scientific reasoning, instruction following, and multi-agent inference.
- It integrates multiple benchmark suites: BigBench Hard (BBH) for multi-step logical inference and compositional reasoning; GPQA for graduate-level physics questions; MATH (Hard) for complex derivations in algebra, geometry, probability, and number theory; MMLU-Pro for advanced conceptual knowledge; IFEval for evaluating instruction-following consistency; and MUSR for symbolic manipulation and structured mathematical reasoning.
- Responses were generated using six models in a zero-shot setting: DeepSeek-R1 (671B parameters), QwQ-32B, DeepSeek-V3 (671B parameters), Qwen-2.5-32B-Instruct, Llama-3.3-70B-Instruct, and Llama-3.1-8B-Instruct. DeepSeek-R1 and QwQ-32B are reasoning-optimized variants derived from their base instruction-tuned counterparts.
- All model responses were generated with a temperature of 0.6, a value recommended for balanced reasoning performance.
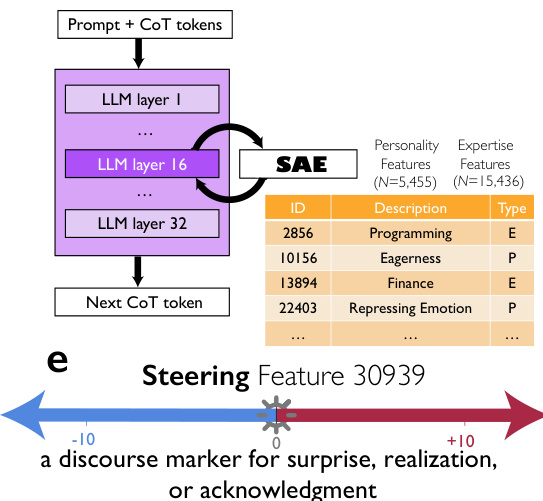
- The dataset is structured to support multi-perspective reasoning, with each instance including a specified number of perspectives (n_perspectives), answers from each perspective across 10 questions, and open-ended domain expertise descriptions for each perspective.
- The data is used to train and evaluate the model with a mixture of tasks from the included benchmarks, with training splits derived directly from the original datasets and processed to align with the required JSON format.
- No explicit cropping is applied; instead, the data is processed to ensure consistent formatting, including proper nesting of answers and expertise descriptions within the JSON structure.
Method
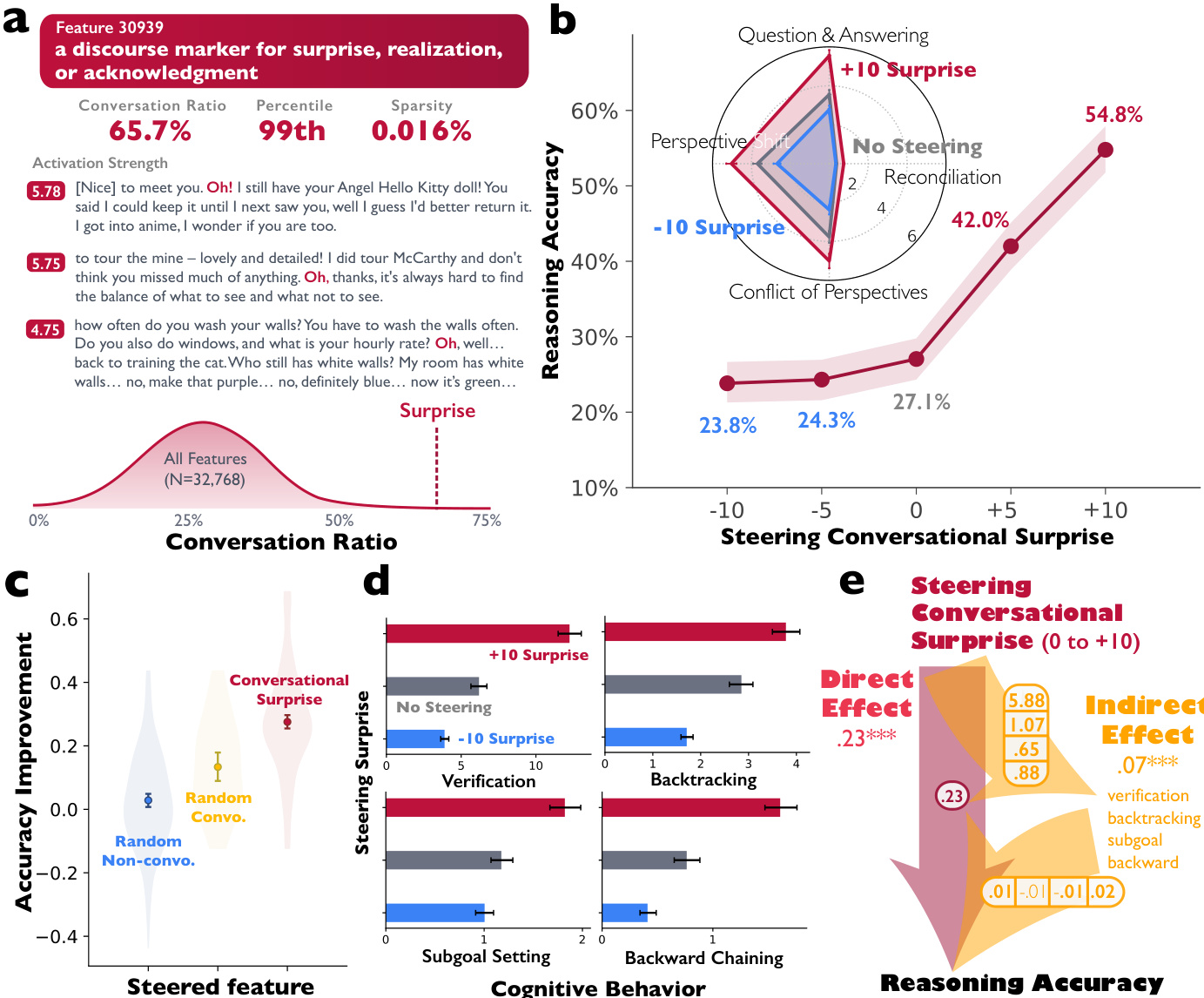
The authors leverage a multi-faceted framework to investigate the role of conversational and socio-emotional behaviors in large language model (LLM) reasoning. The core methodology integrates sparse autoencoders (SAEs) for feature identification and manipulation, LLM-as-judge protocols for behavioral annotation, and statistical modeling to isolate the effects of specific cognitive and social dimensions. The overall architecture begins with the extraction of activations from a target LLM, specifically from Layer 15 of DeepSeek-R1-Llama-8B, which are then processed by an SAE to decompose the high-dimensional activation space into a sparse set of interpretable features. This SAE, trained on the SlimPajama corpus, has a dictionary size of 32,768 features. The authors identify a specific feature, Feature 30939, which is characterized as a discourse marker for surprise, realization, or acknowledgment, and is highly specific to conversational contexts. This feature is then used to steer the model's generation process by adding its decoder vector to the residual stream activations at each token generation step, with a steering strength s that can be positive or negative. The framework is designed to test the causal impact of this conversational feature on reasoning performance and behavior.
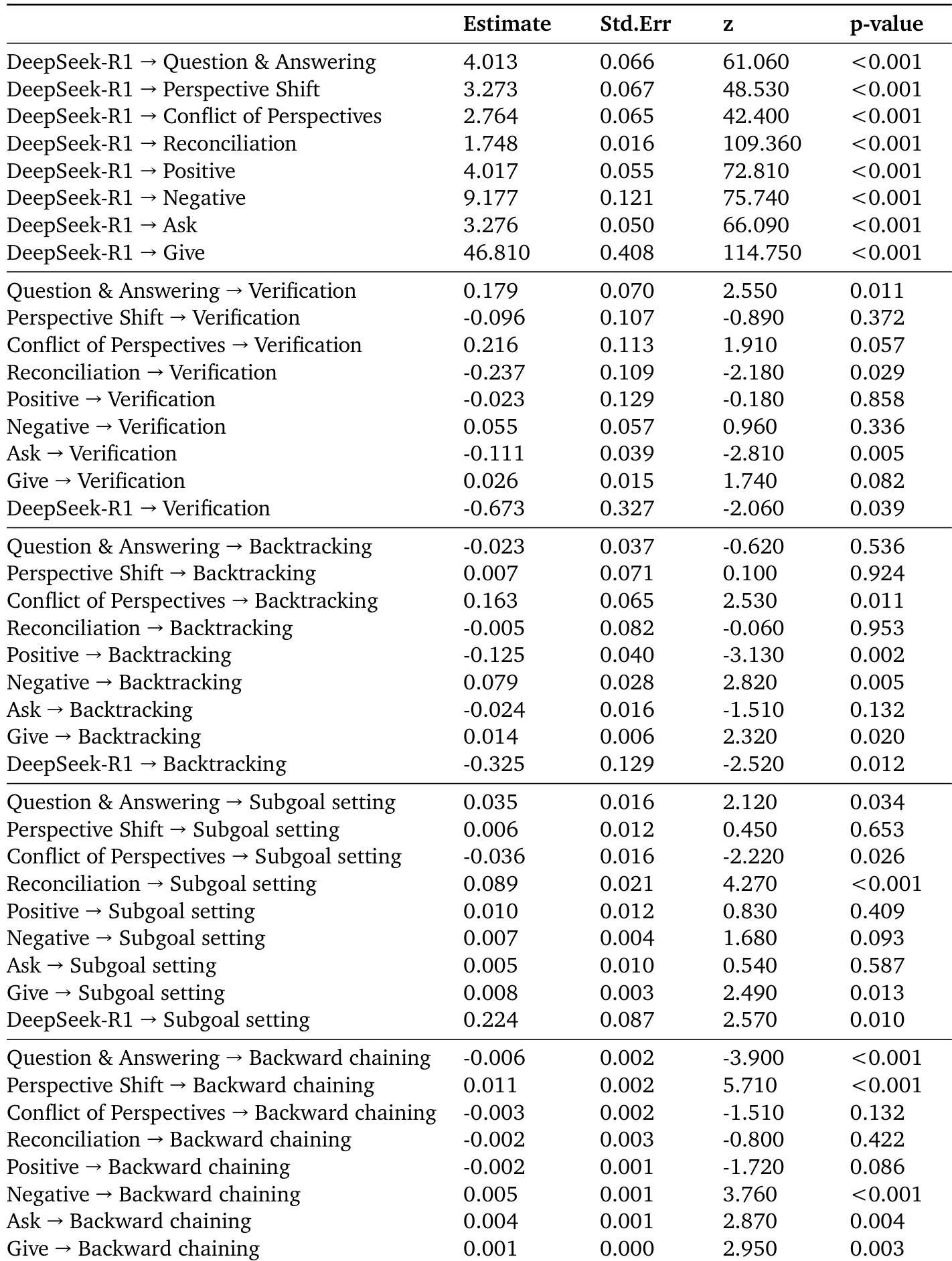
The authors employ a rigorous evaluation protocol to assess the impact of steering. Reasoning performance is measured using the Countdown task, a benchmark for multi-step arithmetic reasoning. For each problem, the model must combine a set of input numbers using basic arithmetic operations to reach a target value. The evaluation uses a standardized prompt template and scores solutions as correct if the final numerical answer matches the target, assessed by Gemini-2.5-flash-lite. To quantify the effect of steering on behavior, the authors use an LLM-as-judge approach (Gemini-2.5-Pro) to count instances of four conversational behaviors—Question-answering, Perspective shift, Conflict of perspectives, and Reconciliation—within each generated reasoning trace. This process is also applied to measure cognitive behaviors such as verification, backtracking, and subgoal setting. The results of these behavioral analyses are visualized in a radar chart, which compares the frequency of these behaviors across different models and steering conditions.
To ensure that observed differences are attributable to the targeted behaviors rather than confounding factors like task difficulty or output length, the authors estimate fixed-effects linear regression models. These models include controls for log-transformed reasoning trace length and task fixed effects, which absorb variation associated with each problem's intrinsic difficulty and phrasing. This allows for a direct comparison of model performance and behavior within the same problem context. The statistical analysis is further extended to examine the diversity of implicit perspectives within a reasoning trace. The authors use an LLM-as-judge protocol to infer the number of distinct perspectives, characterize their personality traits using the BFI-10 inventory, and profile their domain expertise. This process is validated against a human debate corpus, demonstrating high accuracy in predicting the number of speakers and their turns.
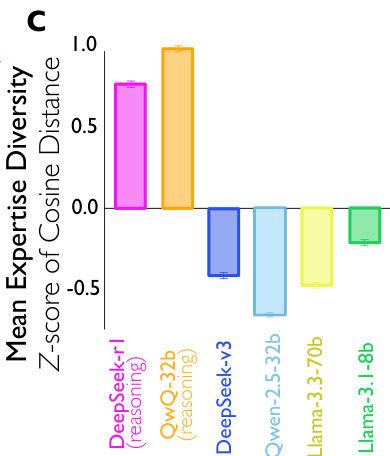
The framework also investigates the effect of conversational steering on the model's internal representation space. By analyzing SAE feature activations before and after steering, the authors compute two measures of diversity: coverage (the number of unique personality- or expertise-related features activated) and entropy (the evenness of activation distribution across features). This analysis reveals that steering conversational features increases the diversity of personality- and expertise-related features in the model's internal representations, suggesting a broader exploration of cognitive and social dimensions during reasoning. The results are presented in a series of bar charts and violin plots, which compare the effects of steering Feature 30939 against randomly selected conversational and non-conversational features, demonstrating the specificity of the effect.
The authors further quantify personality and expertise diversity within a reasoning trace by calculating the standard deviation of personality vectors and the mean cosine distance between expertise embeddings across the identified implicit voices. This provides a numerical measure of the richness and variety of perspectives generated by the model. The framework is designed to provide a comprehensive understanding of how specific, interpretable features in the model's activation space can be manipulated to influence both the external behavior and the internal cognitive processes of LLMs during reasoning. The results are visualized in a series of radar charts and scatter plots, which illustrate the relationships between steering strength, reasoning accuracy, and the frequency of various cognitive and conversational behaviors.
Experiment
- Conducted experiments on reasoning models (DeepSeek-R1, QwQ-32B) versus instruction-tuned models (DeepSeek-V3, Qwen-2.5-32B-IT, Llama-3.3-70B-IT, Llama-3.1-8B-IT) across six benchmarks: BigBench Hard, GPQA, MATH (Hard), MMLU-Pro, MUSR, and IFEval, covering symbolic logic, math, science, multi-agent inference, and instruction following.
- Found that reasoning models exhibit significantly higher conversational behaviors (question-answering, perspective shifts, conflict of perspectives, reconciliation) and socio-emotional roles (asking/giving, positive/negative emotions) compared to instruction-tuned models, even after controlling for trace length and task difficulty.
- Demonstrated that conversational behaviors and socio-emotional roles are more prevalent in complex problems (e.g., GPQA, challenging math), and these behaviors mediate accuracy gains through cognitive strategies like verification, backtracking, subgoal setting, and backward chaining.
- Showed that steering a specific conversational feature (feature 30939, a discourse marker for surprise/realization) in DeepSeek-R1-Llama-8B using sparse autoencoders increases reasoning accuracy by 27.7 percentage points (from 27.1% to 54.8%) on the Countdown task, with causal increases in all four conversational behaviors and cognitive strategies.
- Revealed that reasoning models generate more diverse implicit perspectives in terms of personality (higher extraversion, agreeableness, neuroticism, openness) and domain expertise, with higher entropy and coverage of personality- and expertise-related SAE features, especially under conversational steering.
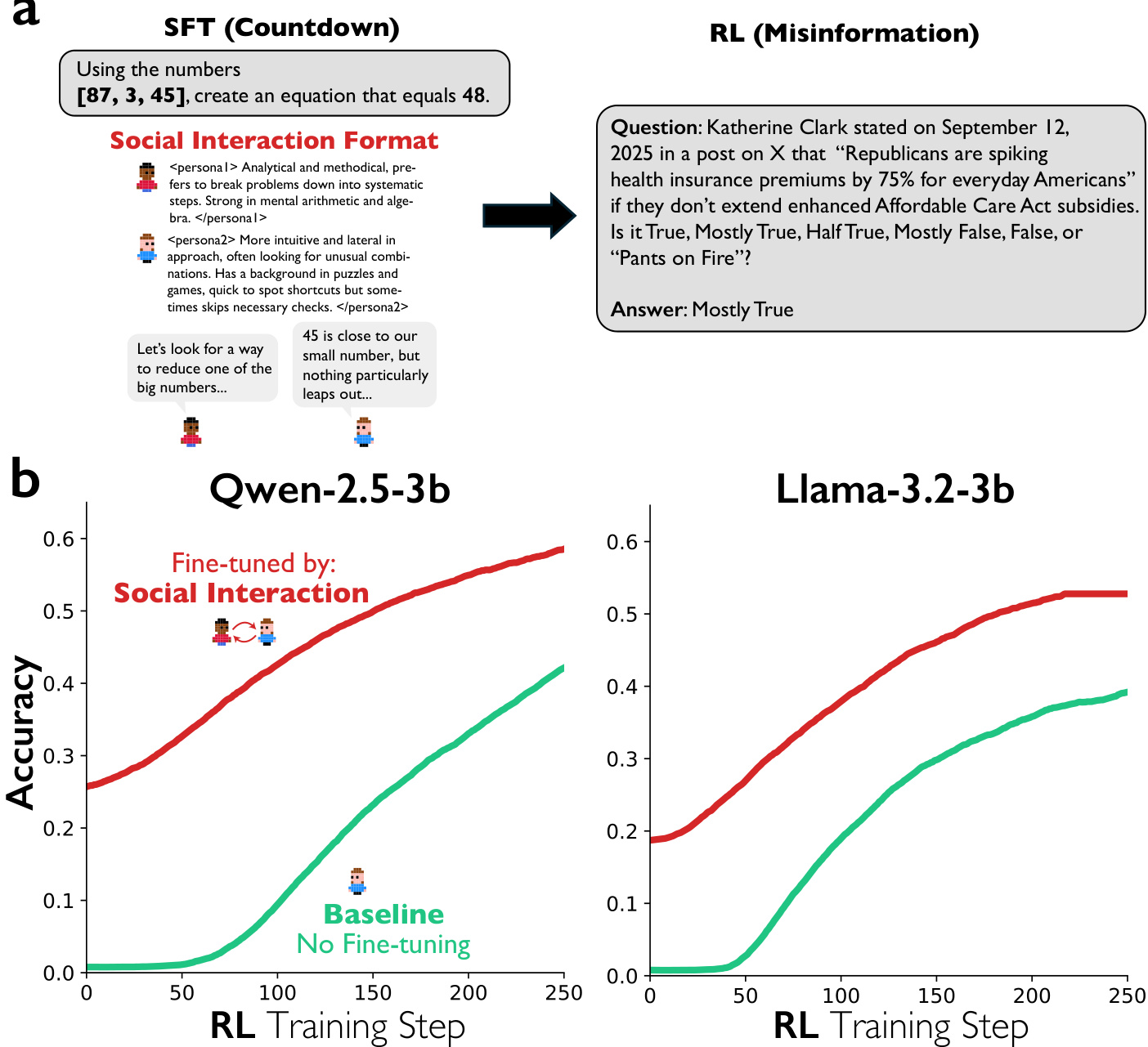
- Found that reinforcement learning with accuracy rewards alone leads to spontaneous emergence of conversational behaviors and improved accuracy, and that prior fine-tuning on multi-agent dialogues accelerates learning and boosts final accuracy compared to monologue fine-tuning, with transferable benefits to unrelated tasks like misinformation detection.
The authors use a suite of benchmarks to compare reasoning models (DeepSeek-R1 and QwQ-32B) with instruction-tuned models (DeepSeek-V3, Qwen-2.5-32B-IT, Llama-3.3-70B-IT, Llama-3.1-8B-IT) on conversational behaviors and socio-emotional roles. Results show that reasoning models exhibit significantly higher frequencies of question-answering, perspective shifts, conflicts of perspectives, and reconciliation compared to their instruction-tuned counterparts, and they also display more balanced, reciprocal socio-emotional roles, including both asking and giving information and both positive and negative emotional expressions.
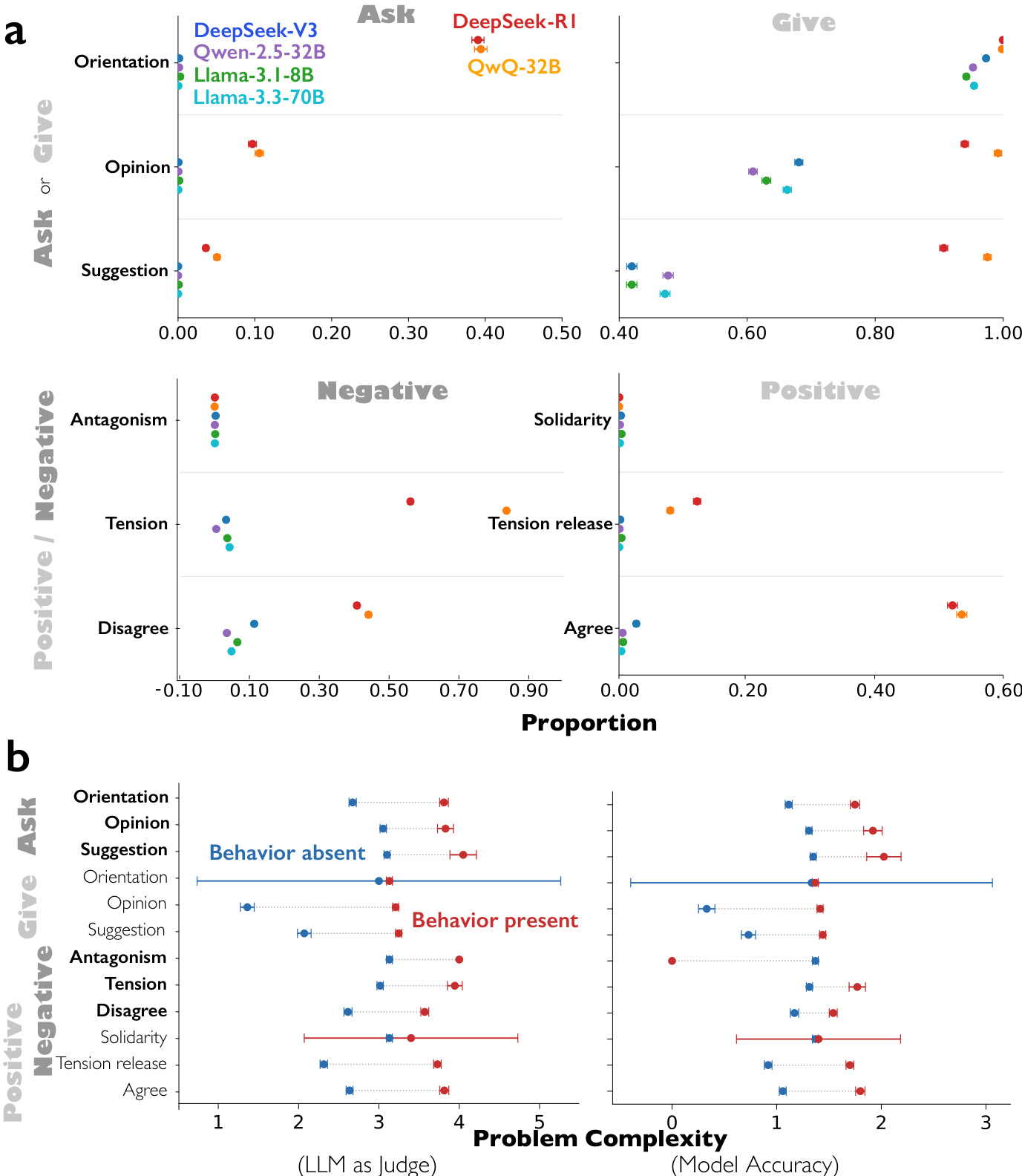
The authors use a structural equation model to analyze the pathways from reasoning models to accuracy, showing that conversational behaviors and socio-emotional roles mediate the accuracy advantage of DeepSeek-R1 and QwQ-32B, both directly and indirectly through cognitive behaviors like verification, backtracking, subgoal setting, and backward chaining. The results indicate that conversational behaviors significantly influence cognitive strategies, with direct and indirect effects on accuracy, particularly through verification and backward chaining.
The authors use a suite of benchmarks including BigBench Hard, GPQA, MATH (Hard), MMLU-Pro, MUSR, and IFEval to evaluate reasoning models. Results show that DeepSeek-R1 and QwQ-32B exhibit significantly higher frequencies of conversational behaviors and socio-emotional roles compared to their instruction-tuned counterparts, with these behaviors increasing in more complex problems.

The authors use reinforcement learning to examine whether conversational behaviors emerge when models are rewarded for correct answers without direct incentives for such behaviors. Results show that models trained with accuracy rewards spontaneously develop conversational behaviors, including question-answering and perspective shifts, as training progresses. Additionally, models pre-trained on multi-agent dialogue data achieve significantly faster accuracy gains compared to those fine-tuned on monologue-style reasoning, indicating that conversational scaffolding accelerates reasoning development.
The authors use a sparse autoencoder to analyze the activation space of DeepSeek-R1-Llama-8B and find that steering a conversational feature increases the diversity of personality- and expertise-related features activated during reasoning. This indicates that conversational behaviors lead to a broader exploration of internal representations, with more diverse features being activated across reasoning traces.