Command Palette
Search for a command to run...
X-Coder: Fortschritte im Wettbewerbsprogrammieren durch vollständig synthetische Aufgaben, Lösungen und Tests
X-Coder: Fortschritte im Wettbewerbsprogrammieren durch vollständig synthetische Aufgaben, Lösungen und Tests
Jie Wu Haoling Li Xin Zhang Jiani Guo Jane Luo Steven Liu Yangyu Huang Ruihang Chu Scarlett Li Yujiu Yang
Zusammenfassung
Wettbewerbsorientiertes Programmieren stellt für Code-LLMs erhebliche Herausforderungen dar, da es intensive Schlussfolgerungsfähigkeiten und eine hohe logische Komplexität erfordert. Derzeit stützen sich jedoch bestehende Code-LLMs stark auf reale Welt-Daten, was ihre Skalierbarkeit einschränkt. In diesem Paper untersuchen wir einen vollständig synthetischen Ansatz: die Ausbildung von Code-LLMs ausschließlich anhand vollständig generierter Aufgaben, Lösungen und Testfälle, um Code-Reasoning-Modelle zu stärken, ohne auf reale Welt-Daten angewiesen zu sein. Dazu nutzen wir eine featurebasierte Synthese, um einen neuartigen Datensynthesepipeline namens SynthSmith vorzustellen. SynthSmith zeigt großes Potenzial, vielfältige und anspruchsvolle Aufgaben sowie verifizierte Lösungen und Tests zu erzeugen, wodurch sowohl eine überwachte Feinabstimmung (Supervised Fine-Tuning, SFT) als auch Verstärkendes Lernen (Reinforcement Learning, RL) unterstützt werden können. Auf Basis der vorgeschlagenen synthetischen SFT- und RL-Datensätze führen wir die X-Coder-Modellreihe ein, die eine bemerkenswerte Pass-Rate von 62,9 avg@8 auf LiveCodeBench v5 und 55,8 auf v6 erreicht – und dies trotz nur 7B Parametern sogar besser als DeepCoder-14B-Preview und AReal-boba2-14B. Eine detaillierte Analyse zeigt, dass Skalierungsgesetze auch auf unserem synthetischen Datensatz Gültigkeit besitzen, und wir untersuchen, welche Dimensionen effektiver sind, um zu skalieren. Zudem geben wir Einblicke in codezentriertes Verstärkendes Lernen und identifizieren durch umfassende Ablationen und Analysen die entscheidenden Faktoren, die die Leistung beeinflussen. Unsere Ergebnisse belegen, dass die Skalierung hochwertiger synthetischer Daten sowie der Einsatz eines stufenweisen Trainingsprozesses die Entwicklung von Code-Reasoning erheblich voranbringen kann, gleichzeitig aber die Abhängigkeit von realen Programmierdaten reduziert.
One-sentence Summary
The authors from Tsinghua University, Microsoft, and Wuhan University propose X-Coder, a 7B-parameter Code LLM trained entirely on synthetically generated tasks via their novel SynthSmith pipeline, which enables high-quality, scalable data synthesis for code reasoning; by leveraging staged training and reinforcement learning on fully synthetic data, X-Coder achieves state-of-the-art pass rates on LiveCodeBench v5 and v6, demonstrating that synthetic data can effectively replace real-world data while maintaining strong scaling laws and performance gains.
Key Contributions
- Competitive programming poses significant challenges for Code LLMs due to its high logical complexity and reasoning demands, yet existing models are constrained by reliance on limited real-world datasets that hinder scalability and diversity.
- The authors introduce SynthSmith, a feature-based synthetic data pipeline that generates diverse, challenging tasks, verified solutions, and accurate test cases entirely from scratch, enabling both supervised fine-tuning and reinforcement learning without real-world data.
- The resulting X-Coder models achieve state-of-the-art performance on LiveCodeBench v5 (62.9 avg@8) and v6 (55.8 avg@8) with only 7B parameters, demonstrating that high-quality synthetic data and staged training can effectively scale code reasoning capabilities.
Introduction
Competitive programming poses a significant challenge for code language models due to its high logical complexity and deep reasoning demands, yet existing models are constrained by limited, real-world datasets that are difficult to scale and often reused across training. Prior synthetic data approaches rely on evolving existing problems, which restricts diversity and complexity. The authors introduce SynthSmith, a feature-based data synthesis pipeline tailored for competitive programming that generates diverse, challenging tasks, verified solutions, and high-fidelity test cases through competition-oriented feature extraction and dual-verification strategies. Using this fully synthetic data, they train the X-Coder series—models achieving state-of-the-art pass rates on LiveCodeBench v5 and v6 with only 7B parameters—demonstrating that synthetic data can effectively support both supervised fine-tuning and reinforcement learning. Their analysis confirms scaling laws hold on synthetic data, highlights the importance of staged training and solution verification, and provides actionable insights into code-centric reinforcement learning, advancing code reasoning without dependency on real-world data.
Dataset

- The dataset comprises 240k high-quality samples generated through an iterative feature evolution pipeline, significantly expanding both the quantity and diversity of tasks across multiple domains.
- Data sources include synthetic generation via CYaRon, an open-source Python library for creating random test cases tailored to Informatics Olympiad-level problems, combined with human-in-the-loop validation and model-generated solutions.
- Each task is filtered based on strict criteria: descriptions shorter than 200 tokens are discarded, solutions must include complete think-and-answer tags, contain only one valid Python code block, pass AST validation, and stay under 25k tokens to avoid overthinking and reduce training cost.
- The final dataset follows a normal token distribution with a median length of 16k tokens, as shown in Table 11 and Figure 19, ensuring balanced sequence lengths for efficient training.
- For test case generation, the authors use CYaRon’s built-in templates for graphs, trees, polygons, vectors, and strings, with explicit prompts requiring the model to generate executable Python programs that produce diverse test cases—including base, boundary, and large-scale random inputs—using a configurable random seed for reproducibility.
- Generated test cases are saved as .in files with pure input data only, no comments or validation logic, and must be produced in a single run using Python’s built-in random module.
- The dataset is used in supervised fine-tuning (SFT) with a mixture of task types, where each sample includes a problem description, reasoning trace, and final solution, processed to ensure consistency and reliability.
- A cropping strategy is applied during data collection to exclude overly long or incomplete samples, and metadata such as task difficulty, domain, and test case type are constructed automatically from the generated code and input structure.
Method
The authors present a comprehensive framework for generating high-quality synthetic data for competitive programming, centered around the SynthSmith pipeline. This pipeline is designed to produce both task descriptions and corresponding test cases, enabling a fully synthetic training process for large language models. The overall architecture, as illustrated in the figure below, consists of four primary stages: task generation, test input generation, candidate solution generation, and a dual-verification strategy.
The first stage, task generation, begins with the extraction of features from a corpus of existing code snippets. These features, such as algorithms, data structures, and implementation logic, are explicitly extracted and evolved into a rich, hierarchical feature tree. This tree is then used to select a consistent and challenging subtree of features, which is formulated into a coherent problem scenario. The process is designed to be style-agnostic, supporting the generation of tasks in various formats, including Codeforces-style (narrative-driven), LeetCode-style (function signature-based), and AtCoder-style (concise specification). The separation of feature selection from task formulation is a key design choice, as it prevents the model from oversimplifying complex problems and allows for the generation of more diverse and challenging tasks.
The second stage, test input generation, addresses the critical challenge of creating sufficient and accurate test cases. The framework employs two complementary methods: a prompt-based approach, where an LLM is instructed to generate test inputs based on the problem's constraints, and a tool-based approach that leverages CYaRon, a dedicated test case generation library. This library enables the LLM to construct test inputs by invoking documented functions, ensuring the generation of valid and diverse inputs, including edge cases and stress tests.
The third stage involves generating candidate solutions. For each synthesized task, multiple candidate solutions are produced using advanced reasoning LLMs. These solutions are required to include a complete reasoning process and a correct Python code implementation. The solutions are then subjected to a dual-verification strategy to ensure their reliability and the accuracy of the test cases.
The dual-verification process is a two-step procedure. Step 1, consensus voting, establishes a provisional ground truth for each test input by executing all candidate solutions and determining the output via majority voting. This step also incorporates a weighting function that assigns higher scores to more challenging test cases, such as those with complex input structures or large sizes. Step 2, weighted evaluation and hold-out validation, selects the final "golden" solution. The top-performing candidate is identified based on its weighted accuracy on a primary test suite. This solution is then validated on a separate, unseen hold-out set to ensure it generalizes well and is not overfitted to the specific test cases. This rigorous verification ensures that the final dataset is of high quality and suitable for training.
The training process for the X-Coder model series follows a supervised fine-tuning (SFT) then reinforcement learning (RL) paradigm. The SFT stage minimizes the negative log-likelihood of the target solution conditioned on the task, enabling the model to learn from the generated task-solution pairs. The RL stage employs Group Relative Policy Optimization (GRPO), an efficient alternative to PPO that eliminates the need for a critic network. GRPO estimates advantages directly from the rewards of multiple rollouts to the same prompt, which is particularly advantageous for large models. The objective function combines a clipped probability ratio to stabilize policy updates with a KL-divergence term to maintain alignment with a reference policy, ensuring controlled optimization. The final training data, consisting of the verified task-solution pairs and test cases, is used to compute the SFT loss and to train the model via the GRPO algorithm.
Experiment
- Main experiments validate the effectiveness of synthetic data generation, SFT, and RL fine-tuning for code reasoning models.
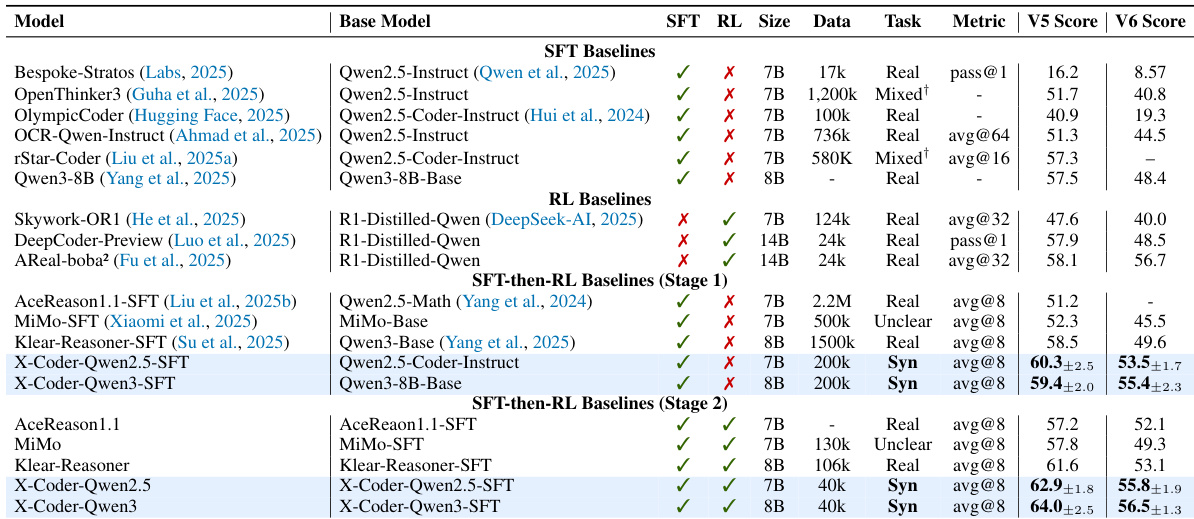
- On LiveCodeBench v5 and v6, X-Coder-SFT achieves an avg@8 pass rate of 60.3, improving over 14B-based RL models and SFT-then-RL baselines; after RL, it reaches 62.9, and on Qwen3-Base, it attains 64.0.
- Scaling SFT data shows that increasing unique tasks (v4: 192k tasks) yields better performance (62.7%) than increasing solutions per task (v6: 8k×8), with task diversity being more efficient under fixed compute.
- The proposed SynthSmith dataset outperforms OpenCodeReasoning by 6.7 points and SelfCodeAlign by 4.6 points, demonstrating superior task quality and diversity.
- RL fine-tuning provides a 4.6% absolute gain over SFT-only models, confirming its role as a powerful refiner, with performance strongly dependent on the SFT initializer quality.
- Dual-verification and long CoT solutions significantly improve performance (17.2% gain), while tool-based test generation outperforms prompting-based methods in accuracy, coverage, and test quality.
- Ablation studies confirm that longer reasoning, Codeforces-style tasks, and rationale-based data selection yield higher performance, and the model shows resilience to noisy synthetic feedback.
- Failure analysis reveals that reasoning errors (Wrong Answer) and context truncation (No Code Block Generated) are primary failure modes, with pass rate decreasing as reasoning length increases.
- X-Coder achieves 51.3-point gain over Qwen2.5-Coder-7B-Instruct in pass@16 and matches Qwen3-8B with 8× fewer rollouts, indicating high reasoning diversity and efficiency.
- The model generalizes across architectures (Llama-3.1-8B-Instruct) and benchmarks (MBPP+, HumanEval+), and synthetic training reduces data leakage compared to real-world trained models.
The authors use a synthetic data pipeline to train code reasoning models, demonstrating that their approach achieves a 62.9% avg@8 pass rate on LiveCodeBench v5, outperforming several SFT and RL baselines. Results show that scaling the number of unique tasks during SFT is more effective than increasing solutions per task, and that RL further improves performance, with X-Coder-7B surpassing other models on both v5 and v6 benchmarks.
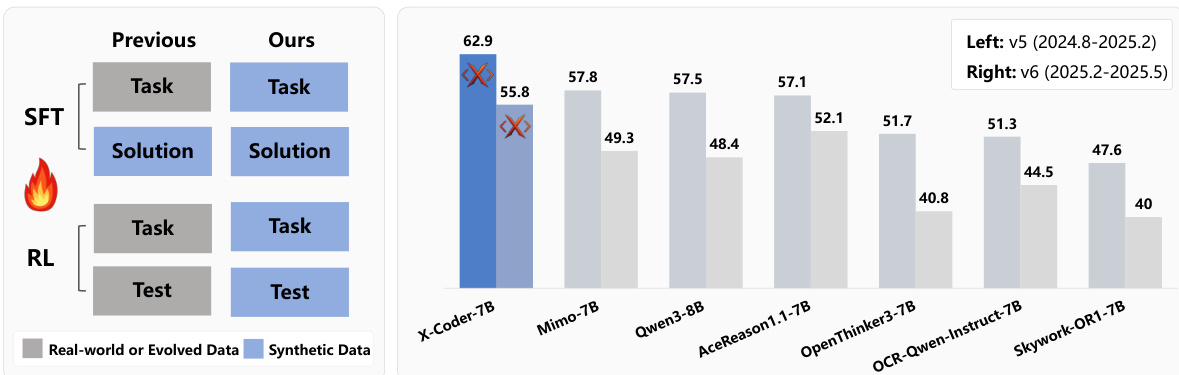
The authors use a combination of SFT and RL to improve code reasoning models, with X-Coder-SFT achieving an avg@8 pass rate of 60.3 and further improving to 62.9 after RL. The results show that X-Coder-SFT outperforms 14B-based RL models and achieves a 64.0 pass rate on Qwen3-Base, demonstrating the effectiveness of the proposed training pipeline.
The authors compare two generation methods for code reasoning tasks, finding that the two-stage approach (Ours) significantly outperforms the one-step end-to-end method. The two-stage method achieves an avg@4 score of 40.1, which is 5.3 points higher than the 34.8 score of the one-step method.

The authors use the table to compare the performance of Qwen3-8B and X-Coder models on LiveCodeBench v2 and v5, showing that both models exhibit a significant drop in pass rate from v2 to v5. X-Coder-7B-SFT and X-Coder-7B achieve higher pass rates on v5 than Qwen3-8B, with X-Coder-7B-SFT showing a 3.8-point improvement and X-Coder-7B showing a 5.4-point improvement, indicating better generalization to newer benchmarks.

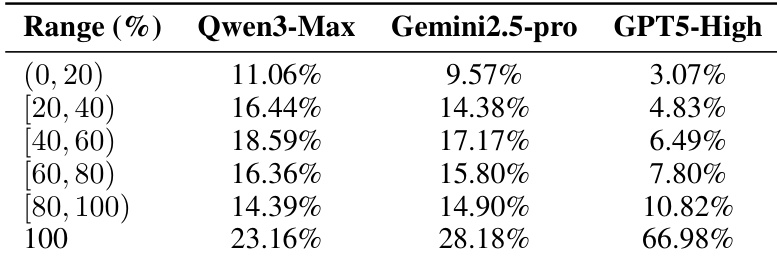
The authors analyze the solvability of generated problems by evaluating the pass@1 performance of proprietary LLMs on voted test cases, showing that even the strongest model, GPT5-High, fails on a small subset of tasks, indicating potential ambiguities or unsolvability in the dataset.