Command Palette
Search for a command to run...
GlimpRouter: Effiziente kooperative Inferenz durch das Erkennen eines Tokens von Gedanken
GlimpRouter: Effiziente kooperative Inferenz durch das Erkennen eines Tokens von Gedanken
Wenhao Zeng Xuteng Zhang Yuling Shi Chao Hu Yuting Chen Beijun Shen Xiaodong Gu
Zusammenfassung
Große Schlussfolgerungsmodelle (Large Reasoning Models, LRMs) erreichen beachtliche Leistungsfähigkeit durch die explizite Generierung von mehrschrittigen Denkketten. Allerdings verursacht diese Fähigkeit erhebliche Inferenzlatenz und rechnerische Kosten. Die kooperative Inferenz bietet eine vielversprechende Lösung, indem sie die Arbeit gezielt zwischen leichten und großen Modellen aufteilt. Dennoch bleibt eine grundlegende Herausforderung bestehen: zu bestimmen, wann ein Schlussfolgerungsschritt die Kapazität eines großen Modells oder die Effizienz eines kleinen Modells erfordert. Bestehende Routing-Strategien stützen sich entweder auf lokale Token-Wahrscheinlichkeiten oder nachträgliche Verifizierung, was erhebliche Inferenzkosten verursacht. In dieser Arbeit präsentieren wir einen neuen Ansatz für schrittweise Zusammenarbeit: Die Schwierigkeit eines Schlussfolgerungsschritts lässt sich bereits an seinem ersten Token erschließen. Inspiriert durch das Phänomen des „Aha-Moments“ in LRMs zeigen wir, dass die Entropie des ersten Tokens ein starker Prädiktor für die Schwierigkeit eines Schritts ist. Auf dieser Erkenntnis aufbauend stellen wir GlimpRouter vor – einen trainingsfreien Rahmen für schrittweise Zusammenarbeit. GlimpRouter verwendet ein leichtgewichtiges Modell, um nur das erste Token jedes Schlussfolgerungsschritts zu generieren, und leitet den Schritt erst dann an ein größeres Modell weiter, wenn die Entropie des ersten Tokens einen vorgegebenen Schwellwert überschreitet. Experimente auf mehreren Benchmarks zeigen, dass unser Ansatz die Inferenzlatenz erheblich reduziert, ohne die Genauigkeit zu beeinträchtigen. So erreicht GlimpRouter beispielsweise eine signifikante Verbesserung der Genauigkeit um 10,7 %, während die Inferenzlatenz im Vergleich zu einem eigenständigen großen Modell auf AIME25 um 25,9 % sinkt. Diese Ergebnisse deuten auf eine einfache, aber effektive Strategie für Schlussfolgerung hin: die Zuweisung von Rechenressourcen basierend auf einem kurzen Blick auf den Gedankenprozess statt auf eine vollständige Bewertung des gesamten Schritts.
One-sentence Summary
The authors from Shanghai Jiao Tong University propose GlimpRouter, a training-free framework that uses initial token entropy to predict reasoning step difficulty, enabling lightweight models to route complex steps to larger models with minimal overhead; this approach reduces inference latency by 25.9% while improving accuracy by 10.7% on AIME25, demonstrating efficient, glimpse-based collaboration for large reasoning models.
Key Contributions
- Large reasoning models (LRMs) achieve high accuracy through multi-step reasoning but suffer from high inference latency and computational cost, motivating the need for efficient collaborative inference strategies that intelligently allocate tasks between lightweight and large models.
- The authors introduce GlimpRouter, a training-free framework that predicts reasoning step difficulty by analyzing the entropy of the first token generated, leveraging the "Aha Moment" phenomenon to route steps to larger models only when initial uncertainty exceeds a threshold.
- Experiments on benchmarks including AIME25, GPQA, and LiveCodeBench show GlimpRouter reduces inference latency by 25.9% while improving accuracy by 10.7% over standalone large models, demonstrating a strong efficiency-accuracy trade-off.
Introduction
Large reasoning models (LRMs) achieve strong performance on complex tasks by generating multi-step chains of thought, but this comes at the cost of high inference latency and computational expense. Collaborative inference—where lightweight and large models work together—offers a way to reduce this cost, yet existing methods struggle with inefficiencies: token-level strategies rely on fine-grained, repetitive verification, while step-level approaches often require full-step evaluation or post-hoc validation, introducing significant overhead. The authors identify a key insight: the difficulty of a reasoning step can be predicted early, based on the entropy of its first token. Drawing from the "Aha Moment" phenomenon, they show that initial token uncertainty strongly correlates with step complexity—low entropy signals routine steps suitable for small models, while high entropy indicates a need for larger models. Building on this, they propose GlimpRouter, a training-free, step-wise collaboration framework that uses a lightweight model to generate only the first token of each step and routes the step to a large model only when the initial token’s entropy exceeds a threshold. This approach enables efficient, real-time decision-making with minimal overhead. Experiments show GlimpRouter reduces inference latency by 25.9% and improves accuracy by 10.7% on AIME25 compared to a standalone large model, demonstrating a practical, scalable path to efficient reasoning.
Method
The authors leverage a collaborative inference framework that orchestrates a large, high-capacity reasoning model (LLM) and a small, computationally efficient model (SLM) to accelerate reasoning while preserving solution quality. The framework operates on a step-wise basis, decomposing the reasoning process T={s1,…,sK} into individual steps, each conditioned on the preceding context ck. The core of the system, GlimpRouter, is a training-free, step-aware strategy that dynamically routes each reasoning step to either the SLM or the LLM based on a single, low-cost probe. This "Probe-then-Dispatch" mechanism is designed to minimize inference latency by offloading routine steps to the SLM while reserving the LLM for complex, high-uncertainty steps.
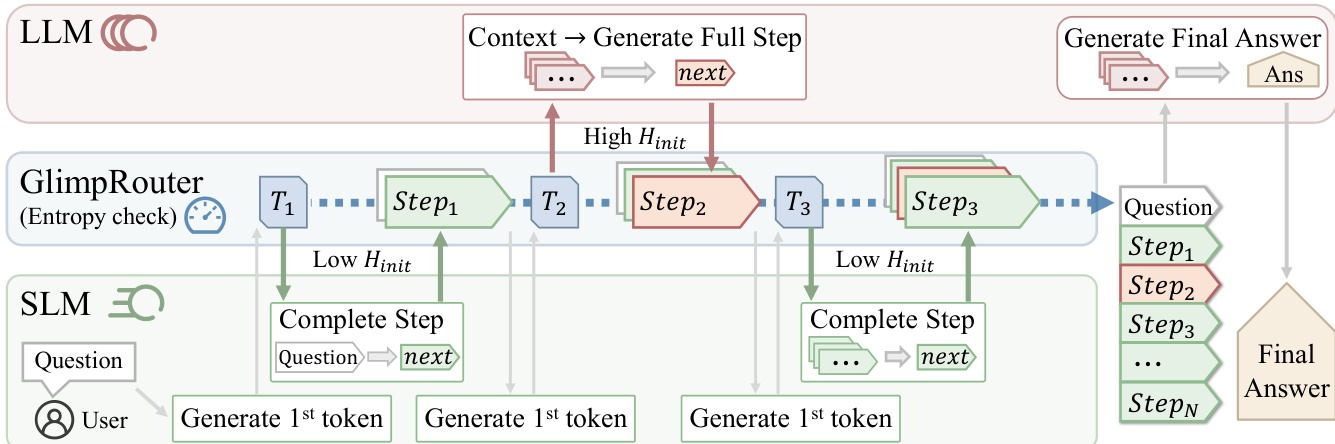
As shown in the figure below, the system begins with a user-provided question. At the start of each reasoning step k, the SLM is invoked to generate only the first token of the step, conditioned on the context ck. This initial token generation is a minimal operation, incurring a computational cost equivalent to decoding a single token. The probability distribution over the vocabulary for this first token is used to compute the initial token entropy, Hinit(sk), which serves as a proxy for the cognitive uncertainty or difficulty of the upcoming step. This entropy value is then evaluated against a predefined threshold τ to make a routing decision. If Hinit(sk)≤τ, the step is classified as routine, and the SLM is responsible for generating the remainder of the step tokens. Conversely, if Hinit(sk)>τ, the step is deemed complex, and the context is handed over to the LLM to generate the full step. The final answer is always generated by the LLM to ensure correctness. This design ensures that the high computational cost of the LLM is only incurred for steps that require its superior reasoning capabilities, while the SLM handles the majority of routine steps, leading to significant efficiency gains. The framework's step-level granularity allows it to be combined with other acceleration techniques, such as speculative decoding, for further performance improvements.
Experiment
- GlimpRouter validates that initial token entropy (Hinit) serves as a high-sensitivity discriminator for reasoning step difficulty, exhibiting a bimodal distribution that clearly separates routine and complex steps, unlike PPLstep, Hstep, and LLM-as-a-Judge, which suffer from signal dilution or saturation.
- On AIME24, AIME25, GPQA-Diamond, and LiveCodeBench, GlimpRouter achieves superior efficiency-performance trade-offs, with GlimpRouter using Qwen3-4B (SLM) and DeepSeek-R1-Distill-Qwen-32B (LLM) surpassing the standalone LLM in accuracy (e.g., 51.67% on AIME25 vs. 46.67%) while reducing latency by 25.2%–27.4%.
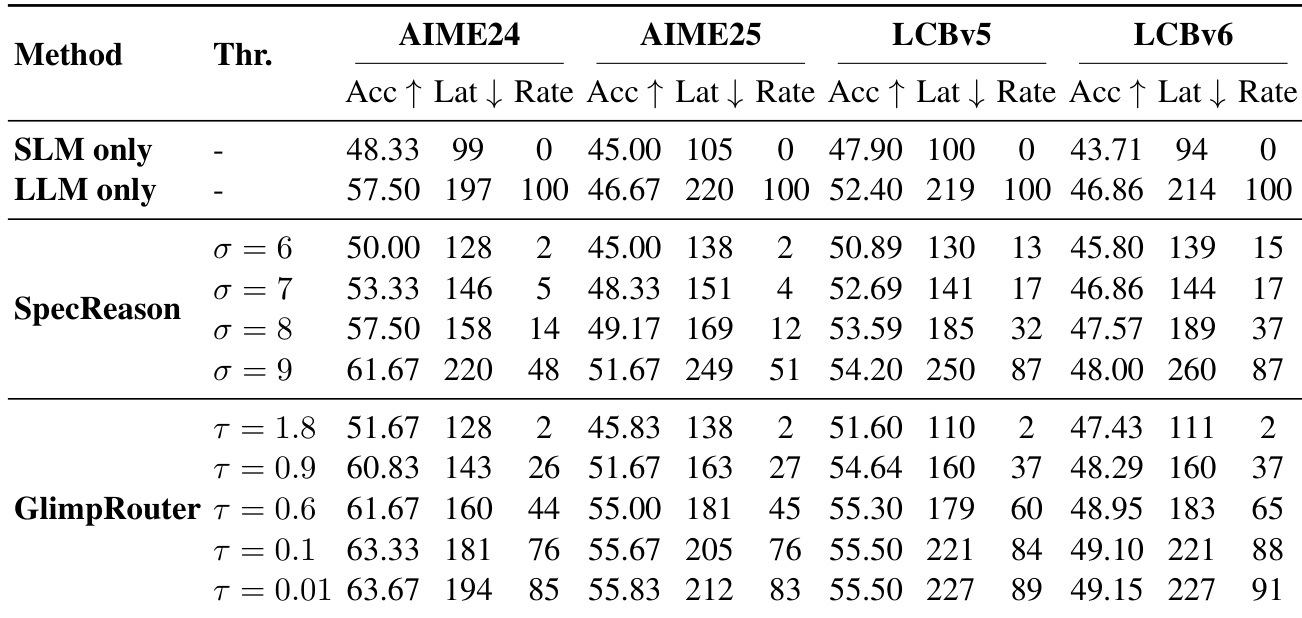
- GlimpRouter outperforms reactive baselines (RSD, SpecCoT, SpecReason) by leveraging a "Probe-then-Dispatch" mechanism based on Hinit, avoiding the sunk cost of full-step generation; for example, SpecReason’s latency exceeds the standalone LLM on GPQA (213s vs. 176s), while GlimpRouter maintains lower latency.
- Ablation studies confirm Hinit significantly outperforms step-wise metrics (Hstep, PPLstep), achieving 10.7% relative accuracy gain on AIME25 and lower latency due to proactive routing.
- GlimpRouter demonstrates orthogonality with speculative decoding, achieving the lowest end-to-end latency across benchmarks when combined, due to compound speedup from coarse-grained routing and fine-grained token-level acceleration.
- Case studies illustrate that high Hinit correlates with cognitive pivots (e.g., solution planning), and LLM intervention enables self-correction of logical errors, improving reasoning fidelity beyond mere text continuation.
Results show that GlimpRouter achieves a superior efficiency-performance trade-off compared to SpecReason across all benchmarks, consistently outperforming it in accuracy while reducing latency. The method's "Probe-then-Dispatch" mechanism, which routes steps based on initial token entropy, avoids the sunk cost of generating full steps before verification, leading to lower latency and higher accuracy than reactive baselines.
The authors use GlimpRouter to compare its performance against variants that employ step-wise entropy and step-wise perplexity for routing decisions. Results show that GlimpRouter consistently achieves higher accuracy and lower latency across all benchmarks, demonstrating the superiority of initial token entropy over metrics that average uncertainty over entire reasoning steps.
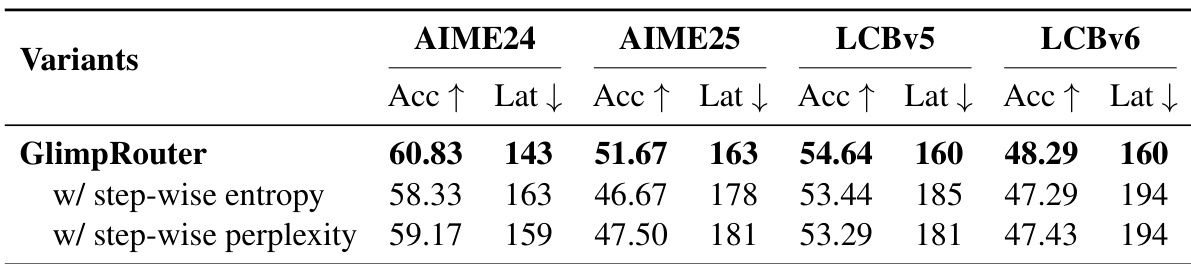
Results show that GlimpRouter using initial token entropy achieves the highest accuracy and lowest latency compared to variants using step-wise entropy or perplexity. The superior performance demonstrates that initial token entropy provides a more effective and efficient signal for routing decisions than metrics that average uncertainty over the entire reasoning step.

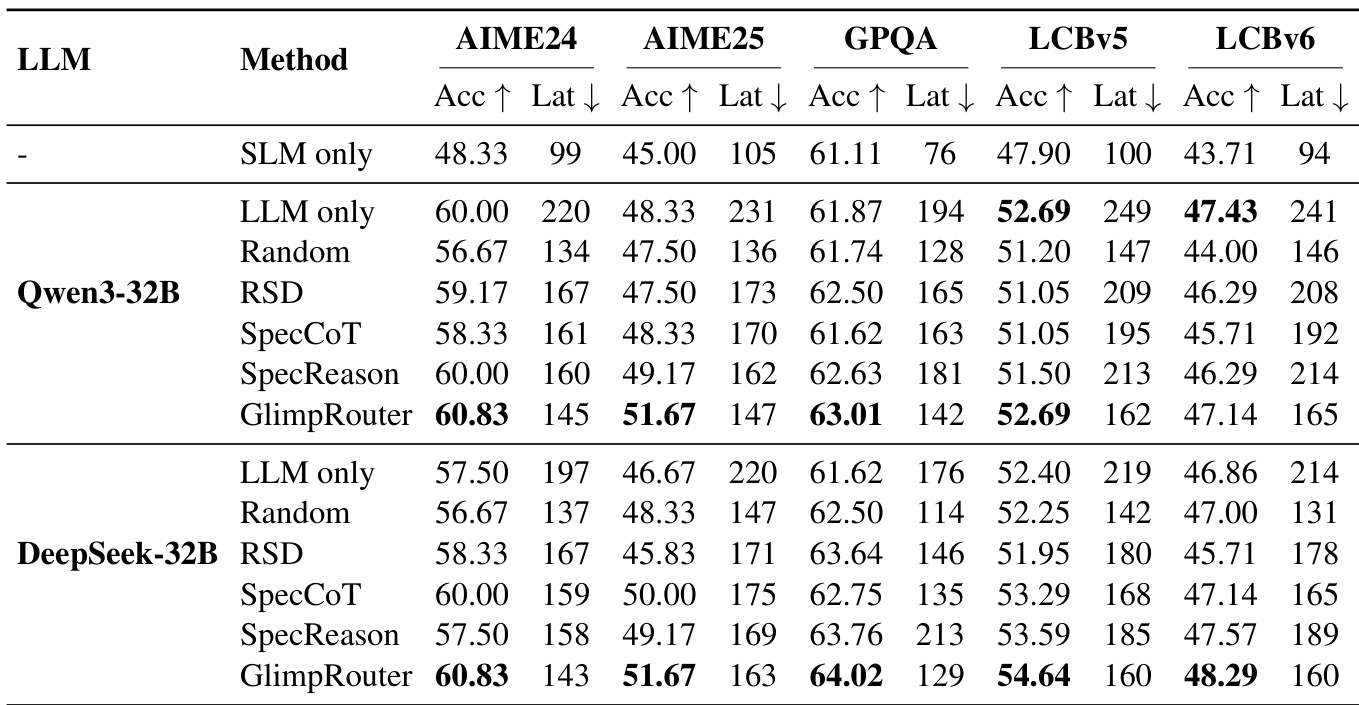
Results show that GlimpRouter achieves higher accuracy and lower latency compared to both standalone models and collaborative baselines across multiple benchmarks. When combined with speculative decoding, GlimpRouter further reduces latency while maintaining superior performance, demonstrating its efficiency and scalability.
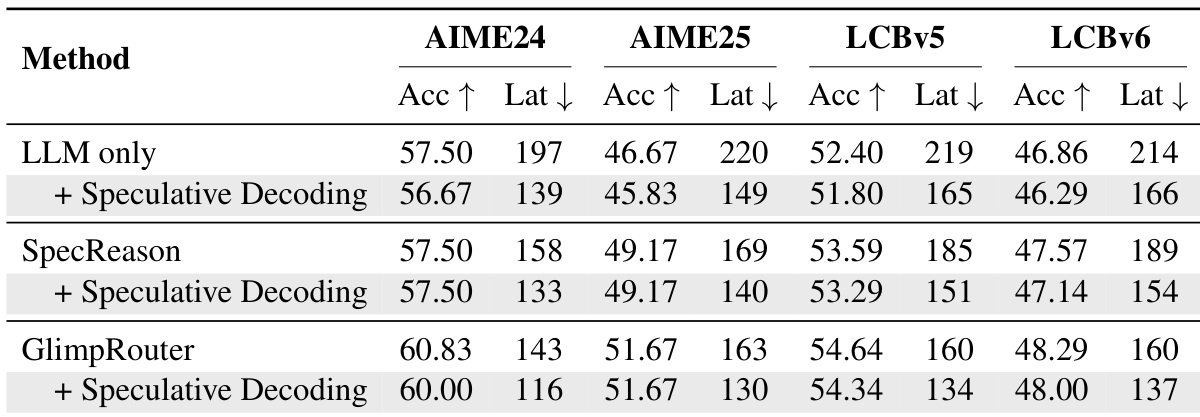
The authors use GlimpRouter to dynamically route reasoning steps between a small model (SLM) and a large model (LLM) based on the initial token entropy Hinit. Results show that GlimpRouter achieves the best trade-off between accuracy and latency across all benchmarks, outperforming both standalone models and existing collaborative methods by significantly reducing latency while maintaining or improving accuracy.