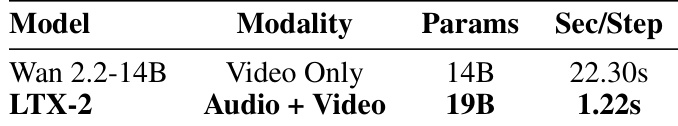Command Palette
Search for a command to run...
LTX-2: Effizientes gemeinsames Audio-Visual-Grundmodell
LTX-2: Effizientes gemeinsames Audio-Visual-Grundmodell
Zusammenfassung
Rezenten Text-zu-Video-Diffusionsmodelle können überzeugende Videosequenzen generieren, bleiben jedoch stumm – sie vermissen die semantischen, emotionalen und atmosphärischen Hinweise, die Audio liefert. Wir stellen LTX-2 vor, ein quelloffenes Grundmodell, das hochwertige, zeitlich synchronisierte Audiovisuelles Inhalt auf einheitliche Weise generieren kann. LTX-2 besteht aus einem asymmetrischen Dual-Stream-Transformer mit einem 14-Billionen-Parameter-Video-Stream und einem 5-Billionen-Parameter-Audio-Stream, die durch bidirektionale Audio-Video-Cross-Attention-Lagen mit zeitlichen Positionseingaben und cross-modaler AdaLN für gemeinsame Zeitstempel-Steuerung verbunden sind. Diese Architektur ermöglicht eine effiziente Schulung und Inferenz eines integrierten Audiovisuellen Modells und verteilt dabei mehr Kapazität auf die Video- als auf die Audio-Generierung. Wir nutzen einen mehrsprachigen Text-Encoder für eine breitere Prompt-Verständnisfähigkeit und führen eine modality-orientierte, klassifikatorfreie Leitungsmechanik (modality-CFG) ein, um die Audiovisuelle Ausrichtung und Steuerbarkeit zu verbessern. Neben der Sprachgenerierung erzeugt LTX-2 reichhaltige, kohärente Audio-Tracks, die den Charakteren, der Umgebung, dem Stil und der Emotion jeder Szene folgen – inklusive natürlicher Hintergrund- und Foley-Elemente. In unseren Evaluierungen erreicht das Modell führende Audiovisuelle Qualität und Prompt-Genauigkeit unter quelloffenen Systemen und liefert Ergebnisse, die denen proprietärer Modelle bei einem Bruchteil der Rechenkosten und Inferenzzeit entsprechen. Alle Modellgewichte und der Quellcode sind öffentlich verfügbar.
One-sentence Summary
The authors, affiliated with Lightricks, propose LTX-2, a unified open-source audiovisual diffusion model featuring an asymmetric dual-stream transformer with 14B-video and 5B-audio streams, enabling temporally synchronized, emotionally coherent generation of rich audio tracks—complete with background and Foley effects—via modality-aware classifier-free guidance and cross-modality AdaLN, achieving state-of-the-art open-source performance at low computational cost.
Key Contributions
- Existing text-to-video models generate visually compelling but silent videos, lacking the semantic and emotional depth provided by synchronized audio; LTX-2 addresses this gap by introducing a unified, open-source text-to-audio+video (T2AV) model that jointly generates high-fidelity audio and video from text prompts.
- The model employs an asymmetric dual-stream transformer with separate 14B-parameter video and 5B-parameter audio streams, connected via bidirectional audio-video cross-attention and modality-aware classifier-free guidance, enabling efficient training and precise control over audiovisual alignment and controllability.
- LTX-2 achieves state-of-the-art audiovisual quality and prompt adherence among open-source systems, producing rich, coherent soundscapes—including speech, Foley, and ambient effects—while matching proprietary models in performance at significantly lower computational cost and inference time.
Introduction
Recent advances in text-to-video (T2V) diffusion models have enabled highly realistic and temporally coherent video generation, but these systems remain silent, lacking synchronized audio that is essential for immersive and semantically rich content. While text-to-audio (T2A) models have evolved toward general-purpose capabilities, most remain domain-specific, and existing audiovisual generation approaches rely on decoupled pipelines—first generating video then adding audio (V2A), or vice versa—which fail to model the bidirectional dependencies between vision and sound. This leads to poor synchronization, inconsistent environmental acoustics, and suboptimal generation quality. The authors introduce LTX-2, an efficient joint audiovisual foundation model that overcomes these limitations through a decoupled yet integrated dual-stream architecture. It uses modality-specific VAEs for separate video and audio latent representations, an asymmetric transformer design that allocates computational resources according to each modality’s complexity, and bidirectional cross-attention with 1D temporal RoPE to enable sub-frame precision in audiovisual alignment. A deep multilingual text encoder ensures accurate, expressive speech synthesis with proper lip-sync and emotional tone. The result is a high-fidelity, computationally efficient T2AV model capable of generating synchronized speech, music, and Foley sounds in a unified, end-to-end manner—outperforming symmetric or proprietary alternatives while supporting flexible editing workflows like V2A and A2V.
Dataset

- The dataset is derived from a subset of the data used in LTX-Video [11], selected for video clips with rich and informative audio content, ensuring a balanced representation of both visual and auditory elements.
- Audio is processed as stereo signals at a 16 kHz sampling rate, with mel-spectrograms computed independently for each channel and concatenated along the channel dimension to preserve spatial audio information.
- The audio autoencoder transforms these stereo mel-spectrograms into a compact latent space, producing latent tokens that represent approximately 1/25 seconds of audio each, encoded as 128-dimensional vectors.
- A custom video captioning system generates high-fidelity, multimodal descriptions by capturing every salient visual and auditory detail—including dialogue with speaker, language, and accent identification, ambient sounds, music, camera motion, lighting, and subject behavior—while maintaining factual accuracy and avoiding emotional interpretation.
- The resulting multimodal corpus, combining processed audio latents and detailed captions, forms the training data for LTX-2, with the audio latent sequences and corresponding captions used in a mixture ratio that supports joint learning across modalities.
- No explicit cropping is applied to video or audio; instead, the data is processed in its original temporal segments, with metadata constructed directly from the captioning system to align textual descriptions with precise audio and visual events.
Method
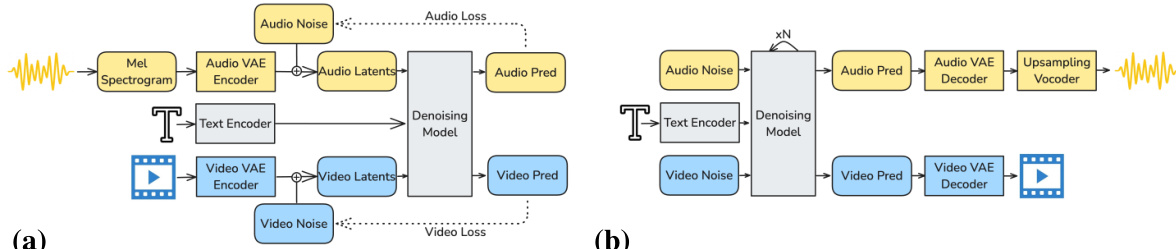
The authors leverage a diffusion-based framework to model the joint distribution of text, video, and audio signals, enabling the generation of synchronized audiovisual content. The overall system architecture, as illustrated in the framework diagram, consists of three primary components: modality-specific variational autoencoders (VAEs) for signal compression, a refined text conditioning pipeline for semantic grounding, and an asymmetric dual-stream diffusion transformer (DiT) for joint denoising. The process begins with the encoding of raw audio and video inputs into compact latent representations. Audio is first converted into a mel spectrogram at 16 kHz, which is then compressed by a causal audio VAE into a temporal sequence of latent tokens. Video is processed by a spatiotemporal causal VAE encoder, producing a sequence of 3D latent tokens that capture both spatial and temporal information. These latents are linearly projected to the transformer's internal dimensionality and fed into the dual-stream DiT backbone.
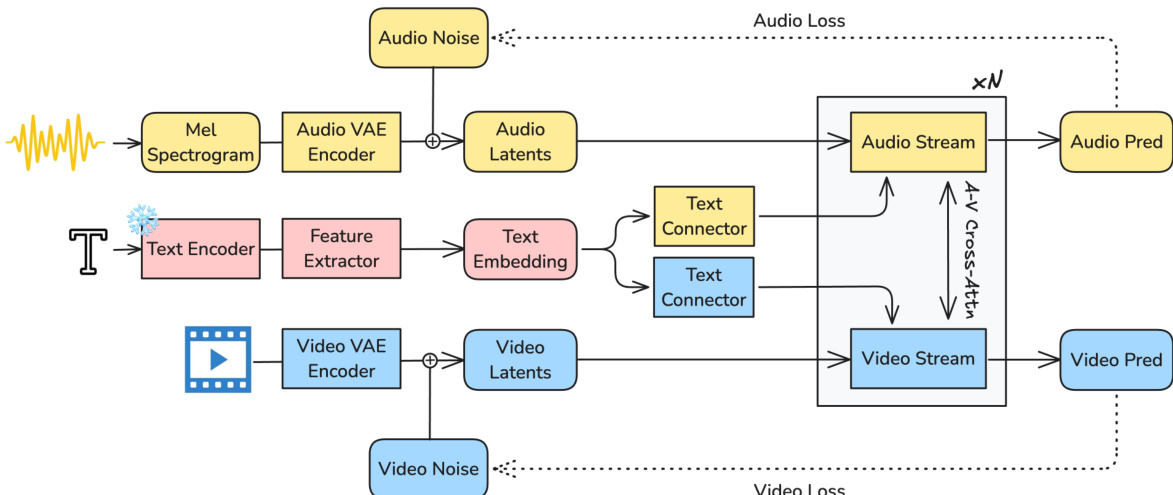
The core of the model is an asymmetric dual-stream DiT architecture, which processes video and audio latents in parallel through dedicated streams. The video stream, with 14 billion parameters, is designed to handle the high information density of visual data, while the audio stream, with 5 billion parameters, is optimized for efficiency. Each stream processes its respective latents through a series of DiT blocks. Within each block, the sequence of operations includes self-attention within the same modality, text cross-attention for conditioning on the prompt, audio-visual cross-attention for inter-modal exchange, and a feed-forward network for refinement. The video stream employs 3D rotary positional embeddings (RoPE) to encode spatiotemporal dynamics, whereas the audio stream uses 1D temporal RoPE, reflecting the different structural properties of the modalities. This asymmetry ensures that the majority of the model's capacity is allocated to the more complex video generation task.
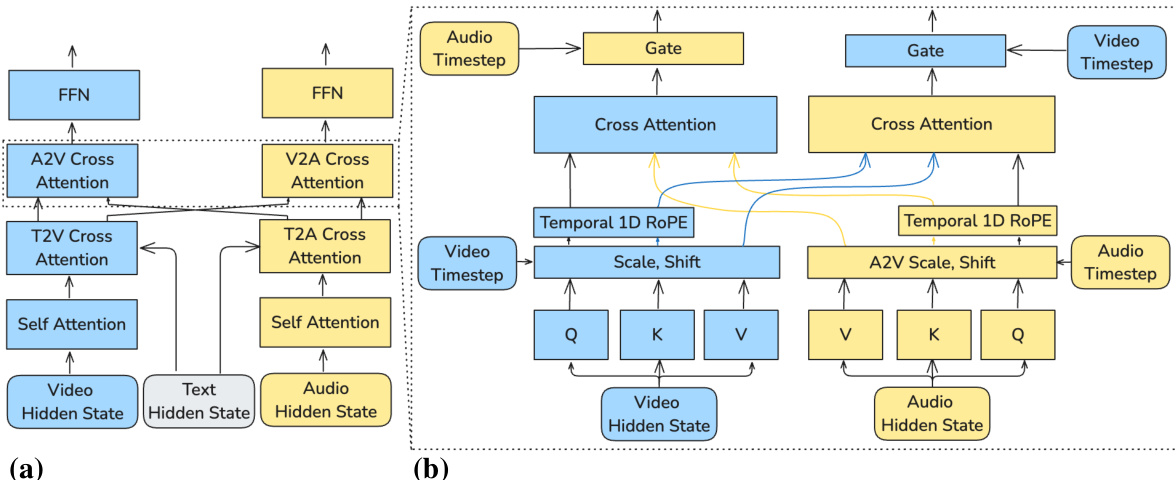
The bidirectional audio-visual cross-attention mechanism, detailed in the figure below, is central to the model's ability to achieve synchronization. At each layer, this module enables information flow between the video and audio streams. Both modalities' hidden states are projected into queries, keys, and values. The queries and keys are then modulated by cross-modality AdaLN gates, where the scaling and shift parameters are conditioned on the hidden states of the other modality. This allows each modality to control its own representation's receptivity to the other. Temporal rotary embeddings are applied to the queries and keys to align their positions along the shared time axis, ensuring that cross-modal attention focuses on temporal synchronization. The attended representations are then passed through an additional AdaLN gate, whose parameters depend on the other modality's timestep, effectively regulating the integration of cross-modal information during the denoising process.

To enhance the text conditioning, the model employs a sophisticated pipeline that moves beyond simple embeddings. The text prompt is first encoded by a Gemma3-12B decoder-only language model. Instead of using the final-layer output, the model extracts intermediate features from all decoder layers, capturing a hierarchy of linguistic information from phonetics to semantics. These features are aggregated and projected into a unified embedding space using a learnable projection matrix. This process is followed by a text connector module, which consists of transformer blocks with full bidirectional attention. This module processes the text embeddings and refines them by incorporating a set of learnable "thinking tokens" that are appended to the input. These tokens act as global information carriers, allowing the model to prepare extra tokens that may carry aggregated contextual information or missing details, thereby improving the conditioning signal for the diffusion process. A separate text connector is used for each stream, ensuring modality-specific conditioning.
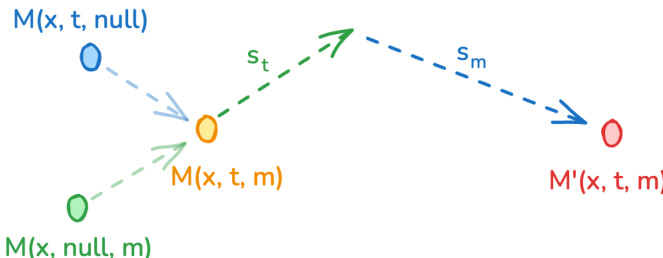
During inference, the model utilizes a modality-aware classifier-free guidance (modality-CFG) scheme to improve audiovisual alignment and controllability. This approach extends the standard CFG formulation by introducing an independent guidance term for the complementary modality. For each stream, the guided prediction is computed as a combination of the fully conditioned model output, a text guidance term scaled by st, and a cross-modal guidance term scaled by sm. This formulation allows for independent modulation of textual conditioning and inter-modal alignment, enabling the model to balance the contributions of the text prompt and the cross-modal features. The authors empirically observe that increasing the cross-modal guidance strength sm promotes mutual information refinement, leading to improved temporal synchronization and semantic coherence between the generated video and audio.
Experiment
- Evaluated LTX-2 across audiovisual quality, visual-only performance, and computational efficiency, demonstrating it as the highest-performing open-source audiovisual model with unprecedented inference speed.
- In human preference studies, LTX-2 outperformed open-source models like Ovi and achieved scores comparable to proprietary models Veo 3 and Sora 2 in visual realism, audio fidelity, and temporal synchronization.
- On video-only benchmarks (Artificial Analysis, Nov 6, 2025), LTX-2 ranked 3rd in Image-to-Video and 4th in Text-to-Video, surpassing proprietary Sora 2 Pro and large open models like Wan 2.2-14B.
- On NVIDIA H100 GPU, LTX-2 achieved 18× faster inference per diffusion step than Wan 2.2-14B, with performance advantage increasing at higher resolutions and longer durations; also faster than Ovi due to asymmetric design.
- LTX-2 generates up to 20 seconds of continuous video with synchronized stereo audio, exceeding temporal limits of Veo 3 (12s), Sora 2 (16s), Ovi (10s), and Wan 2.5 (10s), enabling long-form creative applications.
Results show that LTX-2 achieves significantly faster inference speed compared to Wan 2.2-14B, requiring only 1.22 seconds per diffusion step versus 22.30 seconds, demonstrating an 18× improvement. The authors use this efficiency to highlight LTX-2's capability for generating long-form audiovisual content, with support for up to 20 seconds of synchronized video and audio, surpassing existing open-source and proprietary models.