Command Palette
Search for a command to run...
VIBE: Visual Instruction Based Editor
VIBE: Visual Instruction Based Editor
Grigorii Alekseenko Aleksandr Gordeev Irina Tolstykh Bulat Suleimanov Vladimir Dokholyan Georgii Fedorov Sergey Yakubson Aleksandra Tsybina Mikhail Chernyshov Maksim Kuprashevich
Zusammenfassung
Die instruktionsbasierte Bildbearbeitung gehört zu den am schnellsten entwickelnden Bereichen im Bereich generativer KI. In den vergangenen zwölf Monaten hat sich das Feld auf eine neue Stufe erhoben, wobei zahlreiche Open-Source-Modelle gemeinsam mit hochleistungsfähigen kommerziellen Systemen veröffentlicht wurden. Dennoch erreichen derzeit nur eine begrenzte Anzahl offener Ansätze eine Qualität, die im realen Einsatz nutzbar ist. Zudem sind Diffusions-Backbones – die dominierende Wahl für solche Pipelines – oft groß und rechenintensiv für viele Einsatz- und Forschungsumgebungen; weit verbreitete Varianten enthalten typischerweise zwischen 6B und 20B Parametern. In dieser Arbeit präsentieren wir eine kompakte, hochdurchsatzfähige, instruktionsbasierte Bildbearbeitungspipeline, die ein modernes 2B-Parameter-Modell Qwen3-VL zur Steuerung des Bearbeitungsprozesses und das 1,6B-Parameter-Diffusionsmodell Sana1.5 zur Bildgenerierung nutzt. Unsere Architekturentscheidungen in Bezug auf Modellstruktur, Datenverarbeitung, Trainingskonfiguration und Evaluation zielen darauf ab, kostengünstige Inferenz und strenge Quellkonsistenz zu gewährleisten, während gleichzeitig eine hohe Qualität in den wichtigsten Bearbeitungskategorien erreicht wird, die bei diesem Skalenniveau möglich sind. Auf den Benchmarks ImgEdit und GEdit evaluiert, erreicht die vorgeschlagene Methode die Leistungsfähigkeit oder übertrifft sogar deutlich schwerere Baselines – einschließlich Modelle mit mehrfach so vielen Parametern und höheren Inferenzkosten – und zeigt sich besonders stark bei Bearbeitungen, die die Erhaltung des Eingabebildes erfordern, wie z. B. Attribute-Anpassungen, Objektentfernung, Hintergrundänderungen und gezielte Ersetzungen. Das Modell benötigt lediglich 24 GB GPU-Speicher und erzeugt bearbeitete Bilder mit bis zu 2K-Auflösung in etwa 4 Sekunden auf einer NVIDIA H100 in BF16, ohne zusätzliche Optimierungen oder Distillation.
One-sentence Summary
The authors, from SALUTEDEV's R&D Department, propose VIBE, a compact instruction-based image editing pipeline using a 2B-parameter Qwen3-VL for guidance and a 1.6B-parameter diffusion model Sana1.5 for generation, achieving high-quality edits with strict source consistency at low computational cost—matching or exceeding heavier baselines while running efficiently on 24 GB GPU memory and generating 2K images in ~4 seconds on an H100.
Key Contributions
-
This work introduces VIBE, a compact and high-throughput instruction-based image editing system that combines a 2B-parameter Qwen3-VL vision-language model for image-aware instruction understanding with a 1.6B-parameter diffusion model (Sana1.5), enabling efficient, source-consistent editing with minimal computational overhead.
-
The method achieves state-of-the-art performance on ImgEdit and GEdit benchmarks, matching or surpassing significantly larger models despite its small size, particularly excelling in attribute adjustments, object removal, and background edits while preserving input fidelity through strict source consistency.
-
Trained on approximately 15 million triplets using a four-stage pipeline—including alignment, pre-training, supervised fine-tuning, and Direct Preference Optimization—the system leverages diverse, real-world instructions and advanced data filtering to ensure high-quality, human-aligned edits that run in under 4 seconds at 2K resolution on an NVIDIA H100.
Introduction
Instruction-based image editing enables intuitive, language-driven visual modifications, democratizing content creation beyond expert-level tools. However, most open-source systems rely on large diffusion backbones (6B–20B parameters), leading to high computational costs and slow inference, while proprietary models dominate in real-world quality. Prior work often struggles with source consistency—preserving unintended details like identity, composition, or lighting—especially for complex edits, and frequently uses synthetic or templated instructions that diverge from real user behavior. The authors present VIBE, a compact, high-throughput editing pipeline using a 2B-parameter Qwen3-VL VLM to generate image-aware edit instructions and a 1.6B-parameter diffusion model (Sana1.5) for generation. Their key contribution is a four-stage training pipeline—alignment, pre-training, supervised fine-tuning, and Direct Preference Optimization—that enables strict source consistency and high-quality edits at low cost, fitting in 24 GB of GPU memory and generating 2K images in ~4 seconds on an H100. The system is trained on ~15 million triplets curated from diverse, real-world sources with aggressive filtering and data augmentation, including triplet inversion and bootstrapping, to reduce noise and improve robustness. VIBE matches or exceeds heavier baselines on ImgEdit and GEdit benchmarks, particularly excelling in attribute adjustments, object removal, and background edits, while maintaining efficiency and accessibility.
Dataset
-
The dataset is composed of multiple sources, including remastered versions of large-scale editing datasets like UltraEdit, real-world triplets from photos and videos, synthetic data from perception and recognition datasets, and curated text-to-image (T2I) images. A total of approximately 7.7 million high-quality triplets were selected for pretraining after filtering out noisy data from an initial 21 million triplet mix.
-
Pretraining data includes 6.4 million triplets from a remastered UltraEdit-based pipeline, where candidate edits were generated using instruction-guided models and filtered via automated validation. Images were resampled to resolutions between 860×860 and 2200×2200 with aspect ratios in [1:6, 6:1], and spatial consistency was enforced using facial alignment (IoU threshold of 0.9) and homography correction to eliminate geometric shifts.
-
For supervised fine-tuning (SFT), approximately 6.8 million high-quality triplets were used, drawn from diverse sources: real tripod photos (4,139 triplets), video-derived frames from RORD (10% retained via embedding-based diversity sampling), VITON-HD for garment changes (with compositing and harmonization), LVIS for object-level and full-image stylization (363,280 stylized triplets and 363,280 inverted ones), visual concept sliders (195,525 triplets), autonomous mining from Open Images v7 and other real photo collections (2.9 million triplets), inpainting with ControlNet (177,739 triplets), and perception datasets like HaGRID and EasyPortrait (107,619 and 40,000 triplets respectively).
-
A generation-augmented retrieval-based dataset was constructed for DPO, using real-world editing requests from open and internal sources. This involved clustering user intents, generating synthetic instructions grounded in real phrasing via retrieval from a Qdrant vector database, validating instruction-image applicability with Gemini 3 Flash, and producing target images via proprietary models. The final dataset contains 176,532 triplets, with additional triplets created through instruction inversion and composite transitions between edits.
-
All SFT data underwent filtering using a task-tuned Gemini validator (threshold 3.5) and a geometric filter based on facial IoU (threshold 0.9), removing ~15% and ~35% of data respectively to eliminate artifacts and spatial inconsistencies. Homography correction was applied to align input-output pairs.
-
The model uses the data in a multi-stage training pipeline: pretraining with a mix of editing and T2I data (Edit %: 50%, T2I %: 50%), followed by SFT with a balanced mix of real, synthetic, and augmented triplets. DPO training uses a composite preference dataset combining self-generated, symmetric, and distillation-based pairs to improve instruction adherence and aesthetic quality.
-
Metadata construction includes semantic clustering of real user intents, retrieval-based grounding of synthetic instructions to natural language, and automated generation of inverted and composite instructions to increase dataset diversity and bidirectionality.
Method
The authors leverage a two-component architecture for instruction-based image editing, integrating a Large Vision-Language Model (VLM) with a diffusion transformer. The VLM, specifically Qwen3-VL-2B*, processes the input image and user prompt to generate contextualized guidance. This is achieved by introducing learnable meta-tokens into the VLM's input sequence, which are concatenated with the instruction tokens and processed through the frozen VLM backbone. The resulting meta-token hidden states, denoted as T^M, are then mapped to the conditioning space of the diffusion model via a lightweight, trainable connector module. This connector, implemented as a stack of Transformer encoder blocks, transforms the VLM's output into conditioning features CT that are fed into the diffusion transformer. The diffusion transformer, based on the Sana1.5-1.6B model, synthesizes the edited image by denoising a latent representation conditioned on the input image, the user prompt, and the connector's output. The overall pipeline is illustrated in the framework diagram.
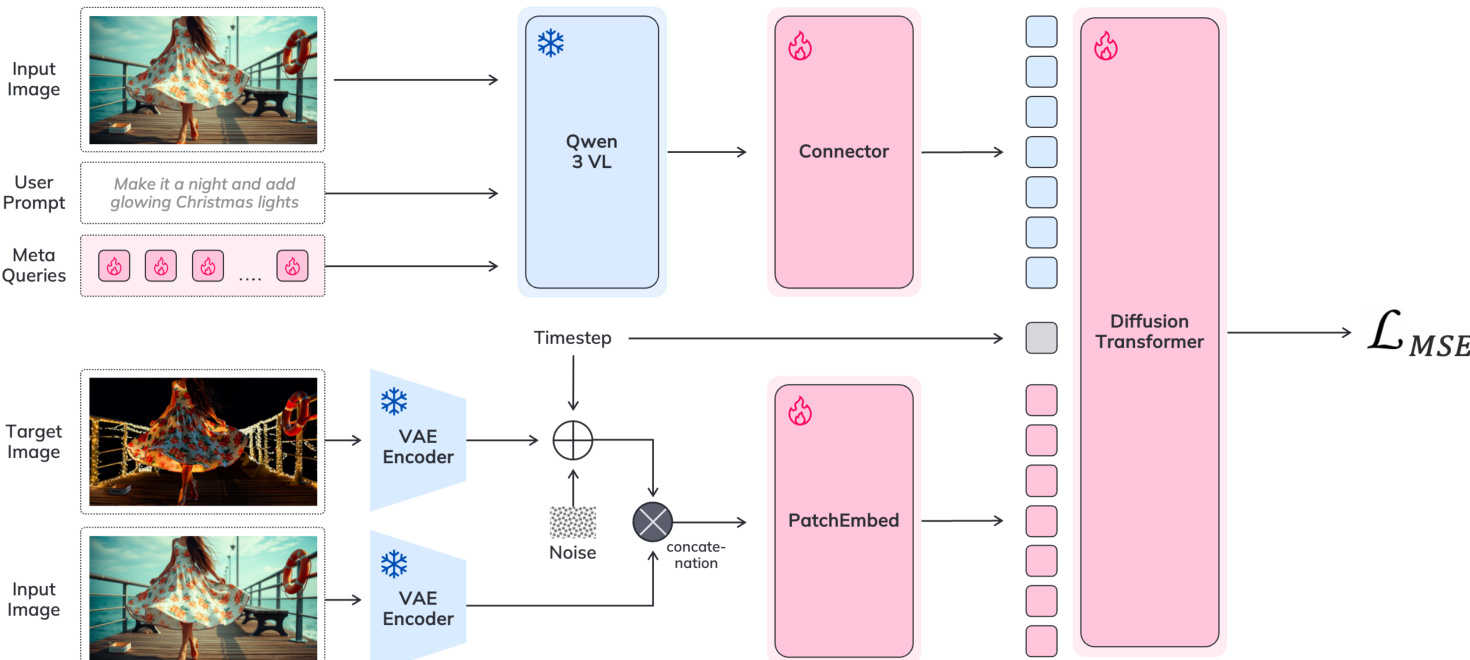
The training process is structured in four stages to ensure stability and high-quality output. The first stage is a connector alignment phase, where the VLM and diffusion model are frozen, and only the connector is trained on a text-to-image generation task to establish a stable interface between the two components. This prevents catastrophic forgetting of the diffusion model's generative prior during subsequent training. The second stage is a multi-stage training phase that begins at 5122 resolution and progresses to 20482. This phase employs a mixed-data strategy, training the model on both instruction-based editing triplets and high-quality text-to-image pairs within the same batch. For text-to-image samples, an empty conditioning image is used, which is masked out in the attention layers. This joint training regularizes learning and preserves the model's foundational generative capabilities. The third stage involves large-scale pre-training and supervised fine-tuning (SFT) at resolutions up to 20482, utilizing a high-quality, filtered dataset. During this phase, the model is trained on both editing and text-to-image tasks, with the VLM backbone remaining frozen. The final stage applies Diffusion-DPO (DPO) to refine the model's instruction adherence and visual quality. The training pipeline also employs a mixed-resolution strategy, training simultaneously on data from 3842 to 20482 with diverse aspect ratios, which accelerates convergence and preserves high-resolution generative priors. This approach diverges from traditional progressive resizing, as the pre-trained diffusion backbone does not require a low-resolution warm-up.

Experiment
- Strict-dominance pair filtering effectively reduced reward over-optimization and achieved balanced gains, matching or outperforming complex multi-preference sampling strategies.
- Sequence-wise reference image concatenation improved instruction-following performance over channel-wise, though it doubled inference time with Sana’s linear attention and caused superlinear slowdown in DiT models.
- The meta-queries configuration significantly enhanced instruction-following compared to Q-Former and native-encoder baselines.
- For both connector types, four layers proved optimal; ELLA showed only marginal and inconsistent improvements over standard encoders.
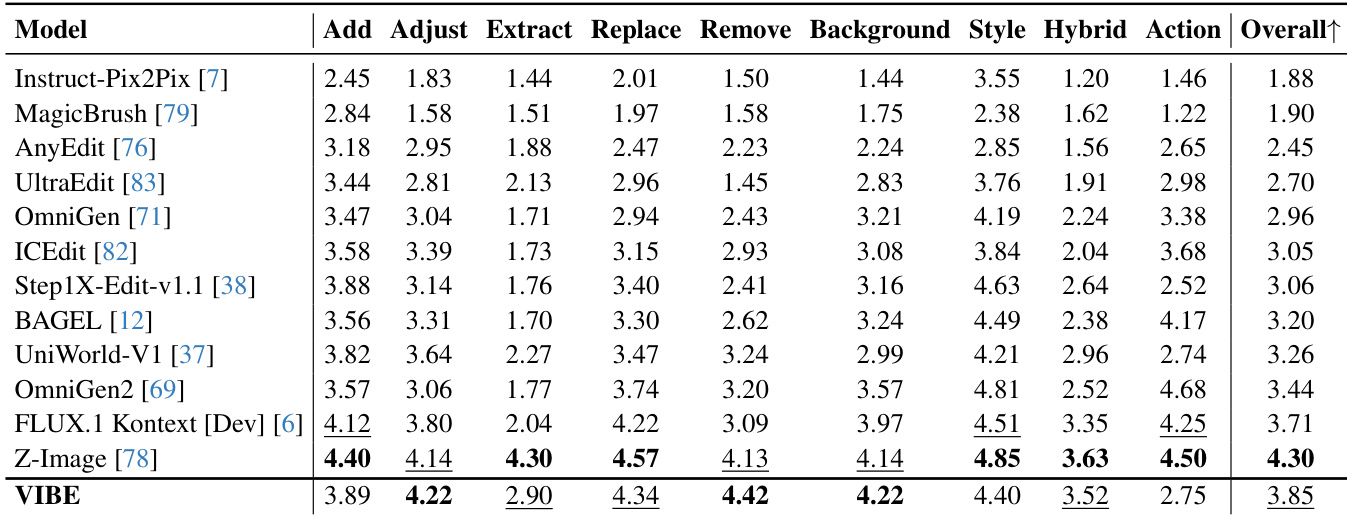
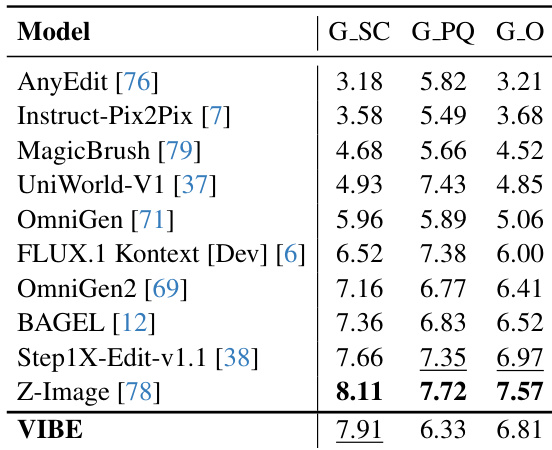
- On ImgEdit-Bench, VIBE achieved an overall score of 3.85 (second place), leading in core categories like Adjust (4.22), Remove (4.42), and Background (4.22), demonstrating strong fidelity in minimal edits despite a smaller backbone.
- On GEdit-Bench-EN, VIBE achieved an overall score of 6.81, with a second-highest semantic consistency score of 7.91, indicating reliable instruction adherence, though perceptual quality (6.33) was lower than specialized models, likely due to minor artifacts rather than semantic misalignment.
- VIBE prioritizes faithful, minimally invasive edits over aggressive scene reconstruction, excelling in local and structural edits but facing challenges in complex, non-local edits like Action.
Results show that VIBE achieves the highest semantic consistency score of 7.91 on GEdit-Bench-EN, outperforming all other models in this metric, while also securing the second-highest overall score of 6.81. The model demonstrates strong instruction-following capabilities, particularly in preserving input image details, though its perceptual quality score trails behind some baselines due to minor visual artifacts.
The authors use a comprehensive dataset composed of pretraining and fine-tuning components, with the majority of data coming from pretraining sources such as UltraEdit Remake and Aurora. The total dataset size is approximately 14.5 million samples, combining pretraining, supervised fine-tuning, and GAN-based data, which supports the model's strong performance in image editing tasks.
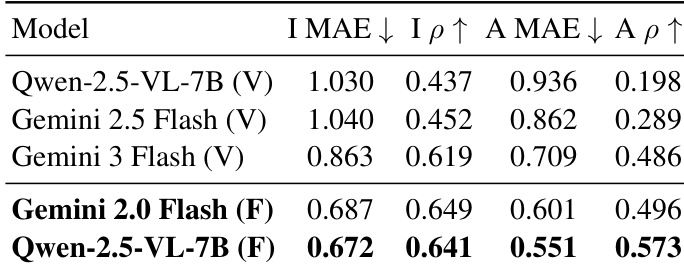
The authors use a quantitative comparison to evaluate model performance on the ImgEdit benchmark, focusing on metrics such as I MAE, I ρ, A MAE, and A ρ. Results show that the Gemini 2.0 Flash (F) model achieves the best performance across all metrics, outperforming both Gemini 2.5 Flash (V) and Qwen-2.5-VL-7B (V) and (F), with the lowest I MAE and A MAE values and the highest I ρ and A ρ scores.

The authors use a four-stage training process that progressively increases resolution and focuses on different trainable modules and data compositions. The final stage, Preference Alignment, uses only preference pairs at high resolution with DiT as the trainable module, indicating a shift toward fine-tuning for instruction-following and editing quality.

Results show that VIBE achieved an overall score of 3.85 on the ImgEdit benchmark, ranking second among the compared methods. It led several core edit categories requiring strict preservation of the input image, including Adjust, Remove, and Background, while demonstrating strong instruction grounding across a range of operations despite using a smaller diffusion backbone.