Command Palette
Search for a command to run...
K-EXAONE Technischer Bericht
K-EXAONE Technischer Bericht
Zusammenfassung
Dieser technische Bericht stellt K-EXAONE vor, ein großskaliges mehrsprachiges Sprachmodell, das von LG AI Research entwickelt wurde. K-EXAONE basiert auf einer Mixture-of-Experts-Architektur mit insgesamt 236 Milliarden Parametern, wobei während der Inferenz 23 Milliarden Parameter aktiviert werden. Das Modell unterstützt einen Kontextfensterumfang von bis zu 256.000 Tokens und deckt sechs Sprachen ab: Koreanisch, Englisch, Spanisch, Deutsch, Japanisch und Vietnamesisch. Wir evaluieren K-EXAONE anhand einer umfassenden Benchmark-Suite, die Fähigkeiten im Bereich Schlussfolgern, Agenz, Allgemeinwissen, koreanisches Sprachverständnis sowie Mehrsprachigkeit abdeckt. In allen Bewertungen zeigt K-EXAONE Leistungen, die vergleichbar sind mit jenen offenen Modellen ähnlicher Größe. K-EXAONE, das entwickelt wurde, um die künstliche Intelligenz für ein besseres Leben voranzutreiben, positioniert sich als leistungsstarkes proprietäres Grundmodell für eine Vielzahl industrieller und forschungsbezogener Anwendungen.
One-sentence Summary
LG AI Research presents K-EXAONE, a 236B-parameter Mixture-of-Experts model with 23B active parameters, supporting a 256K-token context and six languages including Korean, English, German, Japanese, and Vietnamese. It achieves competitive performance across reasoning, agentic, multilingual, and long-context benchmarks by leveraging a hybrid attention mechanism, fine-grained MoE routing with sequence-level load balancing, and a multi-stage training curriculum with FP8 precision. The model integrates a Multi-Token Prediction module for efficient inference and employs a Korea-Augmented Universal Taxonomy to ensure culturally grounded safety, positioning it as a sovereign AI foundation model for industrial and research applications.
Key Contributions
- K-EXAONE addresses South Korea's infrastructure limitations in AI hardware and data centers by leveraging government-supported resources to develop a trillion-parameter foundation model, enabling global competitive performance despite regional constraints.
- The model introduces a hybrid architecture combining reasoning and non-reasoning capabilities with a Mixture-of-Experts (MoE) design and a hybrid attention mechanism, enabling efficient long-context processing and scalable computation.
- K-EXAONE extends multilingual support to include German, Japanese, and Vietnamese, and demonstrates robust performance across benchmarks while adhering to strict AI compliance protocols to mitigate risks related to data privacy, bias, and inappropriate content.
Introduction
The development of large language models (LLMs) is increasingly driven by scaling, with open-weight models closing the performance gap with closed-source counterparts through massive parameter counts. However, countries like South Korea face significant infrastructure constraints—limited access to AI-specialized data centers and high-performance chips—hindering large-scale model development. To overcome this, the Korean government launched a strategic initiative providing critical resources, enabling LG AI Research to develop K-EXAONE, a trillion-parameter foundation model. The authors leverage a hybrid architecture combining reasoning and non-reasoning capabilities, a hybrid attention mechanism for long-context processing, and a Mixture-of-Experts (MoE) design to enable efficient, scalable computation. K-EXAONE extends multilingual support to include German, Japanese, and Vietnamese, enhancing its global applicability. A key contribution is the creation of CODEUTILITYBENCH, a real-world coding benchmark that evaluates practical coding workflows across understanding, implementation, refinement, and maintenance tasks, where K-EXAONE outperforms its predecessor. Additionally, the authors introduce KGC-SAFETY, a culturally grounded safety benchmark based on the Korea-Augmented Universal Taxonomy (K-AUT), addressing the limitations of Western-centric ethical frameworks in evaluating AI safety within Korean sociocultural contexts.
Dataset

- The dataset is composed of in-house and publicly available resources, with a focus on evaluating long-context understanding in Korean.
- Key components include KO-LONGBENCH, an in-house benchmark featuring diverse tasks such as Document QA, Story Understanding, Dialogue History Understanding, In-Context Learning, Structured QA, and RAG.
- KO-LONGBENCH is designed to assess large language models’ performance in practical, long-context scenarios and includes detailed statistics, prompt examples, and task descriptions as documented in the EXAONE 4.0 Technical Report [2].
- The authors use KO-LONGBENCH as part of their evaluation suite, applying both prompt-loose and prompt-strict metrics from IFBENCH and IFEVAL benchmarks to measure model performance.
- No explicit cropping or metadata construction is described; the focus is on leveraging existing task structures and prompt formats for consistent evaluation.
- The dataset is used in model training and evaluation workflows, with mixture ratios and split configurations derived from benchmark-specific guidelines and technical documentation.
Method
The authors leverage a Mixture-of-Experts (MoE) architecture to construct K-EXAONE, a large-scale multilingual language model with 236B total parameters, of which approximately 23B are activated during inference. The overall framework is built upon a transformer-based design, with the model composed of multiple stacked blocks that process input tokens through a sequence of transformations. As shown in the figure below, the architecture is divided into two primary components: the main model block and the Multi-Token Prediction (MTP) block, which is used during training and inference for self-drafting.
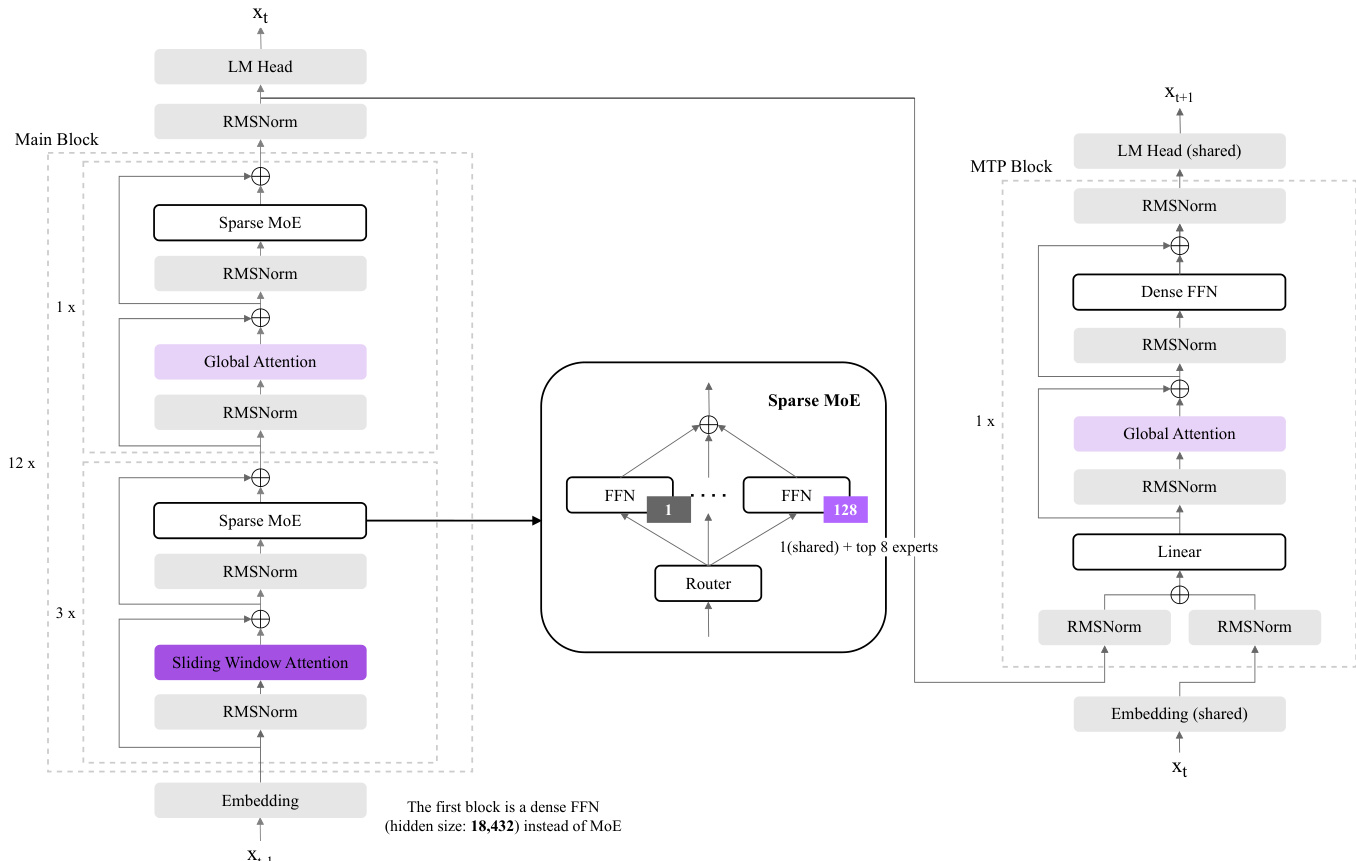
The main block, which processes the primary input sequence, begins with an embedding layer that converts input tokens into dense vectors. The first block in this stack is a dense feed-forward network (FFN) with a hidden size of 18,432, serving as a training stability mechanism. This is followed by a sequence of 12 blocks, each containing a sparse MoE layer, a global attention mechanism, and RMSNorm normalization. The MoE layer is the core computational component, where the input is routed to a subset of experts. Specifically, the model employs a fine-grained sparse MoE design with 128 experts, and for each token, the top-8 experts are selected along with a shared expert, resulting in nine concurrently active experts per routing decision. The routing mechanism is managed by a dedicated router that determines the contribution of each expert to the final output. The sparse MoE block is followed by a global attention layer, which computes attention across the entire sequence, and RMSNorm normalization to stabilize training dynamics.
In addition to the main block, the model incorporates a hybrid attention architecture that combines global attention with sliding window attention (SWA) to efficiently handle long-context inputs. The architecture includes both global attention and sliding window attention layers, which are selectively applied across different layers to balance computational cost and modeling capacity. The sliding window size is reduced to 128 tokens to minimize key-value cache usage while preserving the model's ability to capture long-range dependencies. This design enables cost-efficient long-context modeling, supporting a maximum context length of 256K tokens.
The MTP block, which is used during training and inference, is designed to enhance future-token predictive capability and improve decoding throughput. This block is structured similarly to the main block but includes a dense feed-forward network and a linear layer to predict the next token. During training, the MTP block is supervised to predict an additional future token, providing an auxiliary objective that minimizes routing overhead and memory consumption. At inference time, the MTP block enables self-drafting, allowing the model to generate multiple tokens in parallel and achieving approximately a 1.5× improvement in decoding throughput compared to standard autoregressive decoding. The MTP block also includes a shared embedding layer and RMSNorm normalization, ensuring consistency with the main model's architecture.
To further stabilize training and improve long-context extrapolation, the model incorporates architectural features such as QK Norm and SWA-only RoPE. QK Norm applies layer normalization to the query and key vectors prior to attention computation, mitigating attention logit explosion in deep networks and stabilizing training dynamics. RoPE (Rotary Positional Embeddings) are selectively applied only to the SWA layers, preventing interference with global token interactions and improving robustness to long-sequence extrapolation. These features, combined with the MoE architecture and hybrid attention mechanism, enable K-EXAONE to achieve high performance while maintaining resource efficiency.
Experiment
- Evaluated K-EXAONE across 9 benchmark categories: World Knowledge, Math, Coding/Agentic Coding, Agentic Tool Use, Instruction Following, Long Context Understanding, Korean, Multilinguality, and Safety.
- On MMLU-Pro, GPQA-DIAMOND, and HUMANITY'S LAST EXAM, K-EXAONE demonstrates strong academic knowledge and reasoning, outperforming gpt-oss-120b and Qwen3-235B-A22B-Thinking-2507 on most math benchmarks, except HMMT Nov 2025 where it trails Qwen.
- Achieved 29.0 on TERMINAL-BENCH 2.0 and 49.4 on SWE-BENCH VERIFIED, showing strong agentic coding capability; scored 73.2 on tau2-BENCH, indicating effective multi-step tool use.
- On instruction following, scored 67.3 on IFBENCH and 89.7 on IFEVAL in REASONING mode, surpassing most baselines.
- On long-context benchmarks, achieved 53.5 on AA-LCR and 52.3 on OPENAI-MRCR in REASONING mode, and 45.2 on AA-LCR and 65.9 on OPENAI-MRCR in NON-REASONING mode, demonstrating robust long-context processing.
- On Korean benchmarks: 67.3 on KMMLU-Pro, 61.8 on KoBALT, 83.9 on CLiCK, 90.9 on HRM8K, and 86.8 on Ko-LONGBENCH, showing strong multilingual and domain-specific performance.
- Achieved 85.7 on MMMLU and 90.5 on WMT24++ (average translation score), indicating balanced and high-quality multilingual capabilities.
- On safety benchmarks, achieved competitive Safe Rates on WILDJAILBREAK and KGC-SAFETY, with strong performance in universal values and social safety, and improved handling of Korean-specific cultural sensitivity and future risks.
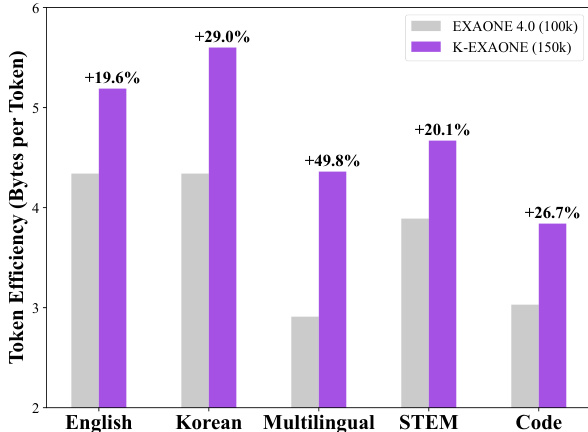
The authors use the bar chart to compare the token efficiency of K-EXAONE and EXAONE 4.0 across different text domains, measuring bytes per token. Results show that K-EXAONE achieves higher token efficiency than EXAONE 4.0 in all categories, with the largest improvement observed in the Korean domain at +29.0%.
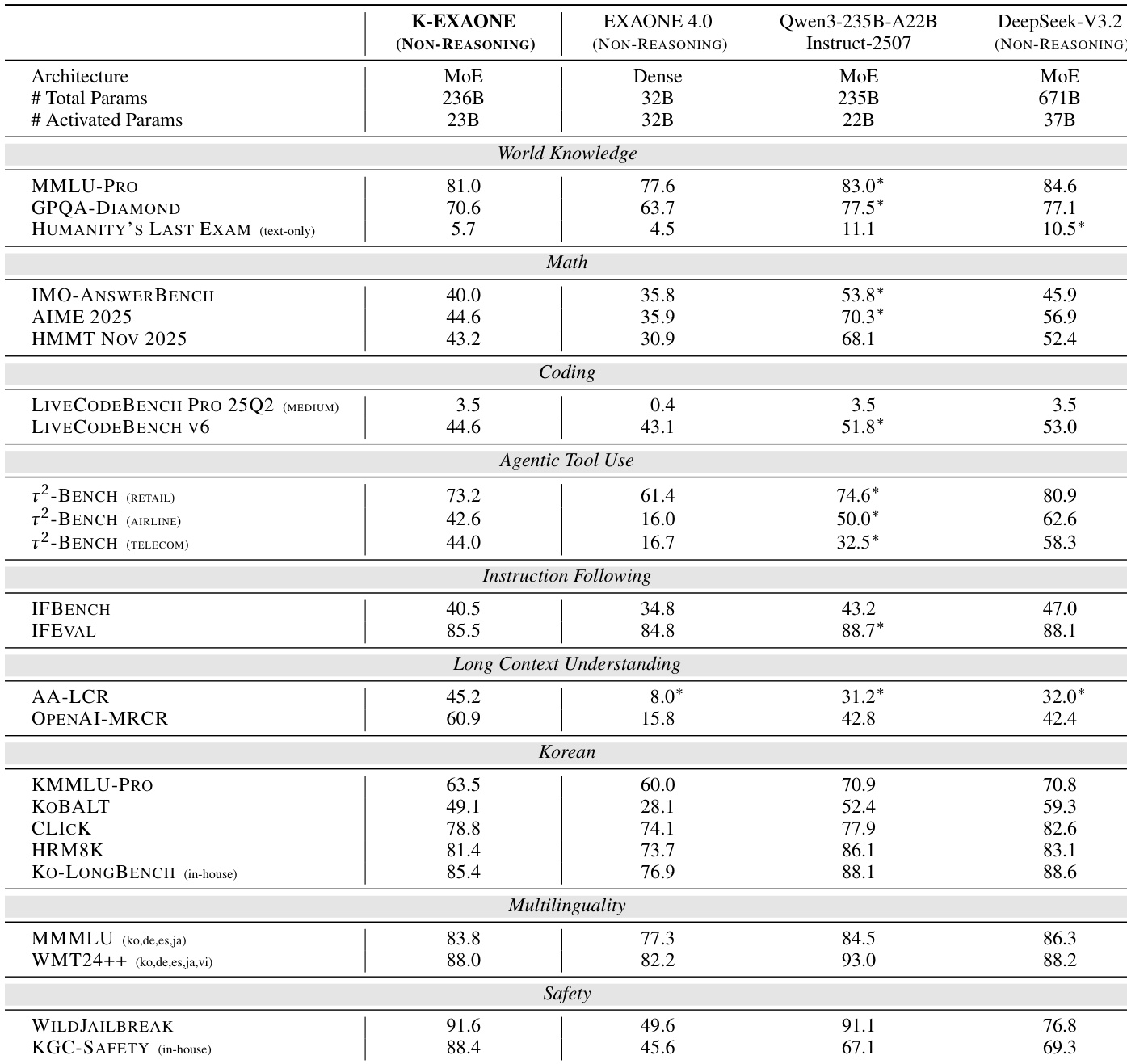
The authors use K-EXAONE in non-reasoning mode to evaluate its performance across multiple domains, showing strong results in world knowledge, math, coding, and safety benchmarks. K-EXAONE achieves competitive scores compared to larger models like Qwen3-235B-A22B-Instruct-2507 and DeepSeek-V3.2, particularly excelling in Korean benchmarks and safety evaluations, while maintaining efficient parameter usage with 23B activated parameters.
The authors use the KGC-SAFETY benchmark to evaluate model safety across multiple dimensions, including universal human values, social safety, Korean sensitivity, and future risk. Results show that K-EXAONE achieves the highest total score of 96.1, outperforming all compared models across all categories, particularly excelling in universal human values and social safety.

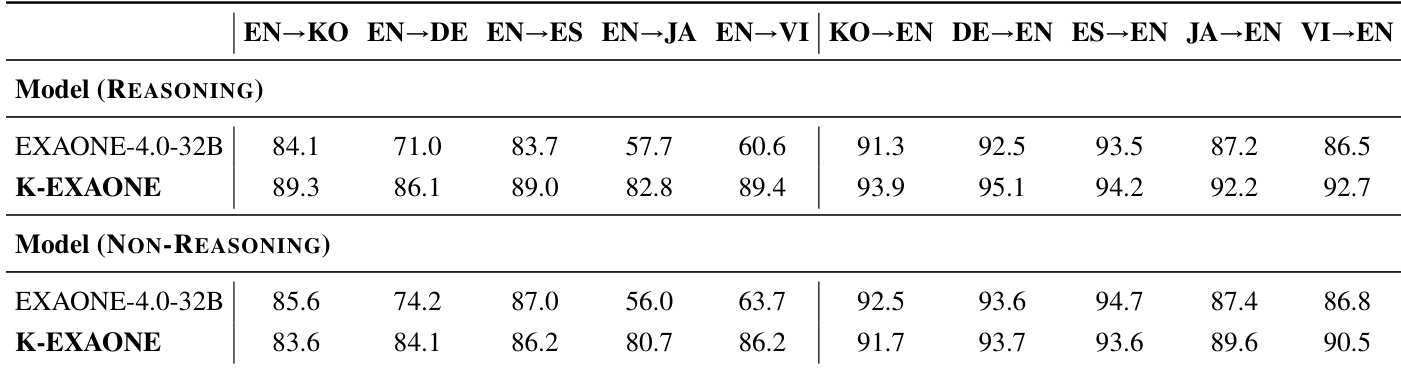
The authors use the table to compare the multilingual translation performance of K-EXAONE and EXAONE 4.0 across various language pairs. Results show that K-EXAONE achieves higher scores than EXAONE 4.0 in most translation directions, particularly in EN→KO, EN→DE, EN→ES, EN→JA, EN→VI, and KO→EN, indicating improved multilingual translation quality.
The authors use the table to present key training resources for the 236B-A23B model, indicating it was pretrained on 11 trillion tokens and required 1.52 × 10²⁴ FLOPs of computation. This data provides context for the model's scale and computational demands.
