Command Palette
Search for a command to run...
MOSS Transkribieren Diarisieren: Genauere Transkription mit Sprecherdiarisierung
MOSS Transkribieren Diarisieren: Genauere Transkription mit Sprecherdiarisierung
Zusammenfassung
Die Sprecherzuordnende, zeitgestempelte Transkription (SATS) zielt darauf ab, das Gesagte genau zu transkribieren und die genaue Zeit jedes Sprechers zu bestimmen, was insbesondere für die Transkription von Besprechungen von großem Wert ist. Bestehende SATS-Systeme verwenden selten eine end-to-end-Formulierung und sind zudem durch begrenzte Kontextfenster, eine schwache Langzeit-Sprechererinnerung und die Unfähigkeit, Zeitstempel auszugeben, eingeschränkt. Um diese Limitationen zu überwinden, präsentieren wir MOSS Transcribe Diarize, ein einheitliches multimodales Großsprachmodell, das die Sprecherzuordnende, zeitgestempelte Transkription in einer end-to-end-Paradigma gemeinsam durchführt. Auf umfangreichem, realen Wilddaten trainiert und mit einem 128k-Kontextfenster für Eingaben bis zu 90 Minuten ausgestattet, skaliert MOSS Transcribe Diarize effizient und generalisiert robust. In umfassenden Evaluationen übertrifft es mehrere state-of-the-art kommerzielle Systeme auf verschiedenen öffentlichen und internen Benchmarks.
One-sentence Summary
The authors propose MOSS Transcribe Diarize, a unified multimodal large language model with a 128k context window that enables end-to-end Speaker-Attributed, Time-Stamped Transcription, overcoming prior limitations in context length and timestamp output by leveraging extensive real-world data and robust long-range speaker memory, significantly outperforming state-of-the-art systems in meeting transcription scenarios.
Key Contributions
-
MOSS Transcribe Diarize introduces the first unified multimodal large language model that performs Speaker-Attributed, Time-Stamped Transcription (SATS) in a single end-to-end pass, eliminating error-prone modular pipelines by jointly modeling speech recognition, speaker attribution, and timestamp prediction without intermediate hand-offs.
-
The model leverages a 128k-token context window, enabling it to process up to 90-minute meetings in a single pass, which significantly enhances long-range speaker memory, discourse coherence, and accurate handling of cross-turn references and speaker consistency.
-
Trained on extensive real-world conversational data, MOSS Transcribe Diarize outperforms state-of-the-art commercial systems across multiple public and in-house benchmarks, demonstrating superior performance in both speaker attribution accuracy and temporal precision for long-form meeting transcription.
Introduction
Speaker-Attributed, Time-Stamped Transcription (SATS) is critical for applications like meeting assistants, call-center analytics, and legal discovery, where knowing who said what and when is as important as the content itself. Prior systems typically rely on cascaded pipelines combining separate ASR and diarization modules, leading to error propagation, poor long-range speaker consistency, limited context windows, and the inability to natively output precise timestamps. While recent efforts have introduced hybrid or semi-end-to-end approaches, they still face constraints in scalability to long-form conversations, suffer from chunking artifacts, and lack robust long-range memory. The authors present MOSS Transcribe Diarize, a unified multimodal large language model that performs SATS in a single, end-to-end pass. It leverages a 128k-token context window to process up to 90-minute meetings without chunking, enabling strong long-range speaker memory, continuous discourse modeling, and native segment-level timestamping. This approach eliminates modular mismatches, reduces identity drift, and outperforms state-of-the-art systems on both public and in-house benchmarks.
Dataset

- The dataset comprises real and simulated multilingual audio, sourced from public corpora, podcasts, films, and in-house collections, designed to cover diverse multi-speaker scenarios.
- Real data includes the AISHELL-4 Test set, featuring long-form, far-field overlapping recordings from meeting rooms; the authors use the averaged channel of far-field signals for both training and evaluation.
- Two additional test sets are curated: Podcasts from high-quality YouTube interviews with available subtitles for reference transcripts, and Movies, consisting of short, overlapping audio segments from films and TV series in Chinese, English, Korean, Japanese, and Cantonese, all manually annotated for high-quality ground truth.
- Simulated data is generated using a probabilistic simulator that constructs synthetic conversations by randomly selecting 2–12 speakers, segmenting their utterances into word runs with log-normal weights, and placing them on a timeline with Gaussian-distributed gaps to enforce alternation and allow overlaps up to 80% of the shorter segment.
- Segment boundaries are snapped to low-energy points and smoothed with 50 ms cross-fades to improve perceptual continuity.
- Mixtures are augmented with real-world noise and reverberation, with SNR sampled uniformly from 0 to 15 dB.
- The model is trained using a mixture of real and simulated data, with training splits derived from the curated real and synthetic datasets.
- For evaluation, the model is tested on three benchmarks: AISHELL-4 (real meeting audio), Podcast (multi-guest interviews), and Movies (overlapping film/TV clips), with performance measured using normalized transcripts.
- Output normalization is applied uniformly across all systems: parentheticals, angle-bracket tags, and non-speaker square-bracket annotations are removed, retaining only speaker IDs like [S1] and plain text for CER/cpCER/Δcp scoring.
- The Podcast and Movies test sets will be publicly released on Hugging Face to support future research.
Method
The authors leverage a unified architecture for Speaker-Attributed, Time-Stamped Transcription (SATS), combining a speech encoder with a learned projection into a pretrained text large language model (LLM). This framework enables end-to-end modeling of transcription, speaker attribution, and timestamp prediction within a single pass, supported by a 128k-token context window. The model processes audio input through an audio encoder, which extracts acoustic embeddings. These embeddings are then projected into the feature space of the pretrained text LLM via a trainable projection module, allowing the LLM to jointly align speaker identities with lexical content.
As shown in the figure below, the system processes audio in chunks, with temporal information explicitly represented as formatted timestamp text inserted between encoder outputs. This approach avoids reliance on absolute positional indices, which degrade over long durations, and instead enables accurate timestamp generation for hour-scale audio while maintaining stable speaker attribution. The model is trained on diverse in-the-wild conversations and property-aware simulated mixtures that capture overlap, turn-taking, and acoustic variability, enhancing robustness in real-world scenarios.
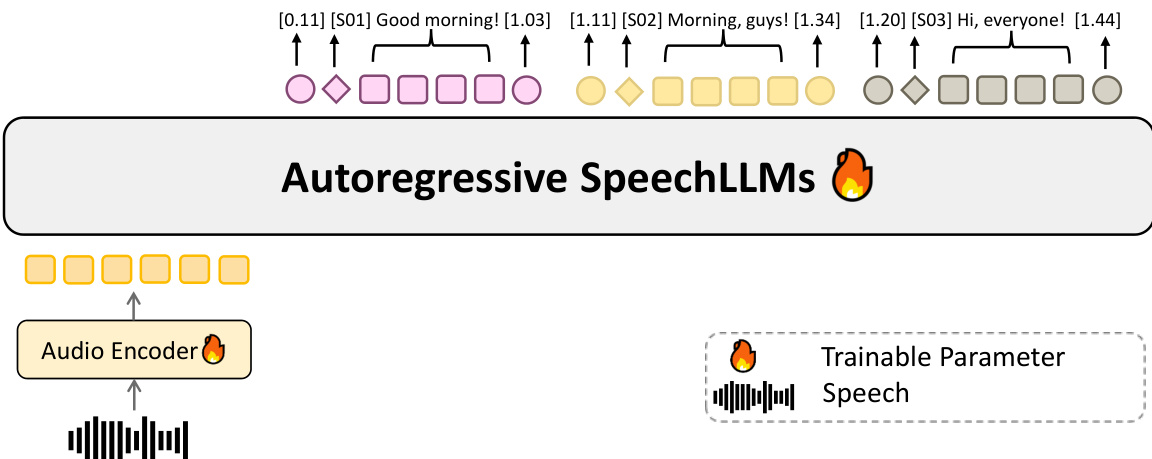
The framework produces structured segments with start/end timestamps and stable speaker IDs, as illustrated in the diagram below. It supports multilingual input, auto-detecting language per segment and preserving speaker tags across languages. The model also handles hour-long audio with consistent speaker tracking and includes optional tags for non-speech events and overlap/interruptions, enabling comprehensive event and overlap modeling.
Experiment
- Evaluated on AISHELL-4, Podcast, and Movies benchmarks using CER, cpCER, and Δcp metrics to assess ASR, speaker diarization, and joint performance.
- On AISHELL-4, achieved the lowest cpCER and Δcp, outperforming closed-source models including GPT-4o and Gemini 3 Pro, which failed on long-form inputs due to length constraints or output format issues.
- On Podcast, attained the best cpCER and smallest Δcp, demonstrating superior speaker attribution in long, multi-speaker discussions with frequent turn-taking.
- On Movies, surpassed all baselines in cpCER and Δcp despite short utterances and high overlap, indicating robust speaker boundary detection.
- Consistently low Δcp across datasets confirms that speaker attribution errors contribute minimally to overall degradation, validating the effectiveness of end-to-end, long-context modeling.
The authors use the table to provide context for the datasets evaluated in their experiments, showing that AISHELL-4 Test consists of long-form meeting recordings with durations around 2290 seconds and 5–7 speakers, Podcast features longer conversations with up to 11 speakers and average duration of 2658 seconds, and Movies contains short, overlap-rich segments with durations up to 29.888 seconds and 1–6 speakers. These characteristics align with the experimental findings that MOSS Transcribe Diarize performs best on long-form and complex conversational data, demonstrating robustness across varying audio lengths and speaker counts.

Results show that MOSS Transcribe Diarize achieves the lowest cpCER and Δcp across all datasets, indicating superior joint performance in speech recognition and speaker attribution. On AISHELL-4, it significantly outperforms all baselines in both CER and cpCER, with a markedly smaller Δcp, demonstrating more reliable speaker attribution over long conversations. On Podcast and Movies, it again achieves the best performance in cpCER and Δcp, highlighting robustness in both long-form and short-form conversational settings.