Command Palette
Search for a command to run...
DreaMontage: Frame-gesteuerte One-Shot-Videoerzeugung mit beliebigen Rahmen
DreaMontage: Frame-gesteuerte One-Shot-Videoerzeugung mit beliebigen Rahmen
Zusammenfassung
Die „One-Shot“-Technik repräsentiert eine einzigartige und anspruchsvolle ästhetische Herangehensweise im Filmemachen. Ihre praktische Umsetzung wird jedoch häufig durch prohibitiv hohe Kosten und komplexe realweltliche Einschränkungen behindert. Obwohl sich neu entwickelte Videogenerationsmodelle als virtuelle Alternative anbieten, basieren bestehende Ansätze typischerweise auf einer naiven Clip-Konkatenation, die häufig die visuelle Glätte und zeitliche Kohärenz nicht aufrechterhält. In diesem Paper stellen wir DreaMontage vor – einen umfassenden Rahmen, der für die beliebige, frame-gestützte Generierung konzipiert ist und in der Lage ist, nahtlose, ausdrucksstarke und langdauernde One-Shot-Videos aus vielfältigen Benutzereingaben zu synthetisieren. Um dies zu erreichen, bearbeiten wir die Herausforderung auf drei zentrale Dimensionen. (i) Wir integrieren eine leichtgewichtige Zwischenbedingungsmechanik in die DiT-Architektur. Durch die Anwendung einer adaptiven Anpassungsstrategie, die die Basis-Trainingsdaten effizient nutzt, erschließen wir robuste Fähigkeiten zur beliebigen Frame-Steuerung. (ii) Um die visuelle Qualität und künstlerische Ausdruckskraft zu steigern, haben wir ein hochwertiges Datenset zusammengestellt und eine Visual Expression SFT-Stufe implementiert. Bei der Lösung zentraler Probleme wie der Bewegungsrationalität des Objekts und der Übergangsglättung setzen wir ein maßgeschneidertes DPO-Schema ein, das die Erfolgsrate und Benutzbarkeit der generierten Inhalte erheblich verbessert. (iii) Um die Erzeugung erweiterter Sequenzen zu ermöglichen, haben wir eine segmentweise autoregressive (SAR) Inferenzstrategie entworfen, die speichereffizient arbeitet. Umfangreiche Experimente zeigen, dass unser Ansatz visuell beeindruckende und nahtlos kohärente One-Shot-Effekte erzielt, während gleichzeitig eine hohe rechnerische Effizienz gewährleistet wird. Dadurch können Benutzer fragmentierte visuelle Materialien in lebendige, kohärente One-Shot-Kinematik-Erlebnisse transformieren.
One-sentence Summary
ByteDance researchers propose DreaMontage, a framework for seamless one-shot video generation that overcomes prior clip concatenation limitations through adaptive tuning within DiT architecture and segment-wise autoregressive inference, enabling cinematic-quality long sequences from fragmented inputs via visual expression refinement and tailored optimization.
Key Contributions
- The one-shot filmmaking technique faces prohibitive real-world costs and constraints, while existing video generation methods rely on naive clip concatenation that fails to ensure visual smoothness and temporal coherence across transitions. DreaMontage introduces a lightweight intermediate-conditioning mechanism integrated into the DiT architecture, using an Adaptive Tuning strategy to leverage base training data for robust arbitrary-frame control capabilities.
- To address critical issues like subject motion rationality and transition smoothness in generated content, the framework curates a high-quality dataset and implements a Visual Expression Supervised Fine-Tuning stage followed by a Tailored DPO scheme. This pipeline significantly improves cinematic expressiveness and the success rate of seamless one-shot video synthesis.
- For generating extended one-shot sequences under memory constraints, DreaMontage designs a Segment-wise Auto-Regressive inference strategy that enables long-duration production while maintaining computational efficiency. Extensive experiments confirm the approach achieves visually striking, temporally coherent results that transform fragmented inputs into cohesive cinematic experiences.
Introduction
The authors address the challenge of generating seamless "one-shot" long videos, which are highly valued in filmmaking for immersive storytelling but traditionally require costly production and physical constraints. While recent video diffusion models offer potential, prior approaches relying on first-last frame conditioning fail to ensure temporal coherence, often producing disjointed transitions due to limitations in latent space representation of intermediate frames, semantic shifts between keyframes, and prohibitive computational demands for extended durations. To overcome these, the authors introduce DreaMontage, which implements three key innovations: an intermediate-conditioning mechanism with Shared-RoPE and Adaptive Training for precise frame-level control, Supervised Fine-Tuning with Differentiable Prompt Optimization on curated datasets to enhance visual continuity and reduce abrupt cuts, and a Segment-wise Auto-Regressive inference strategy that enables memory-efficient long-video generation while maintaining narrative integrity.
Dataset
The authors describe their Visual Expression SFT dataset as follows:
- Composition and sources: The dataset comprises newly collected, category-balanced video samples specifically targeting model weaknesses. It originates from a fine-grained analysis of underperforming cases, structured using a hierarchical taxonomy.
- Key subset details: The data spans five major classes (Camera Shots, Visual Effects, Sport, Spatial Perception, Advanced Transitions), each divided into precise subclasses (e.g., "Basic Camera Movements – Dolly In" under Camera Shots; "Generation – Light" under Visual Effects). It is a small-scale collection where videos per subclass were carefully selected for core scenario characteristics and high motion dynamics. Videos are longer (up to 20 seconds) and feature more seamless scene transitions compared to prior adaptive tuning data.
- Usage in training: The authors apply Supervised Fine-Tuning (SFT) using this dataset directly on the model weights obtained from the previous adaptive tuning stage. They reuse similar training strategies and random condition settings from that prior stage.
- Processing details: The primary processing distinction is the intentional collection of longer-duration videos emphasizing motion dynamics and transitions. No specific cropping strategies or metadata construction beyond the hierarchical classification and selection criteria are mentioned.
Method
The authors leverage a DiT-based video generation framework, extending it with a novel intermediate-conditioning mechanism and a progressive training pipeline to enable arbitrary-frame guided synthesis of long, cinematic one-shot videos. The overall architecture, as shown in the figure below, is structured around two core components: a training pipeline that incrementally refines the model’s capabilities, and an inference pipeline that supports flexible, memory-efficient generation.
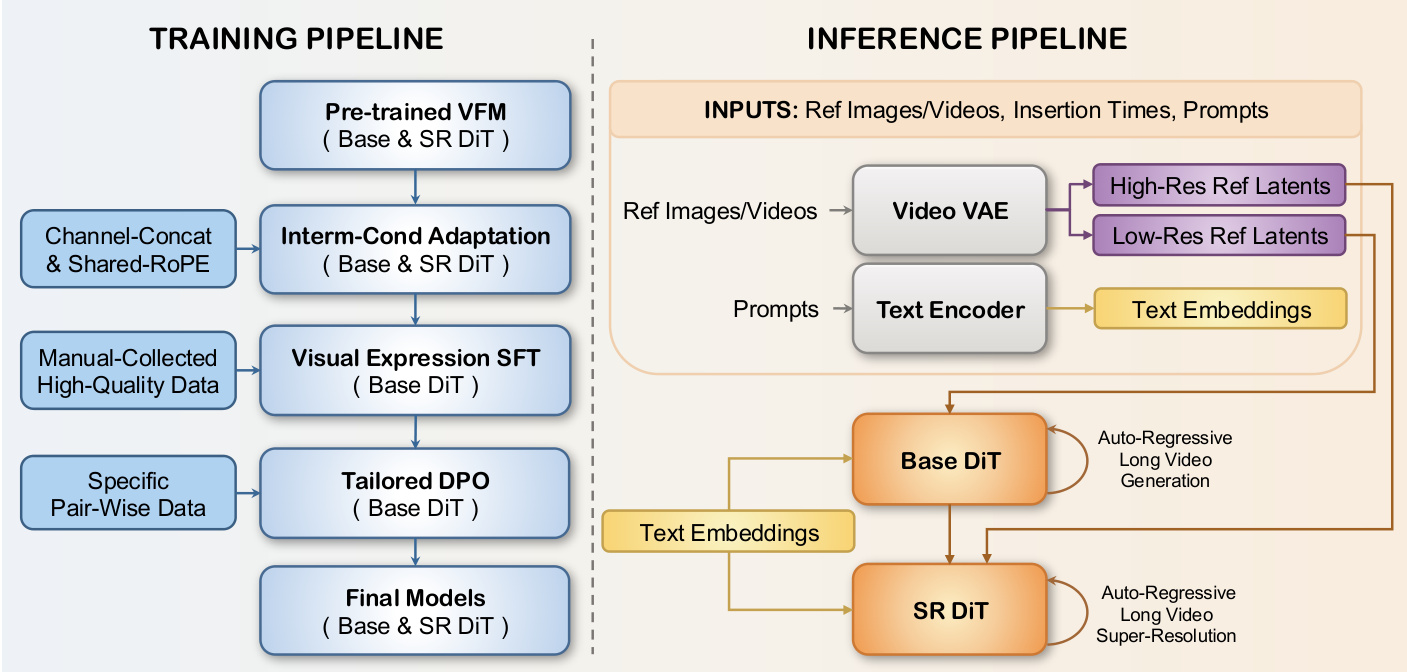
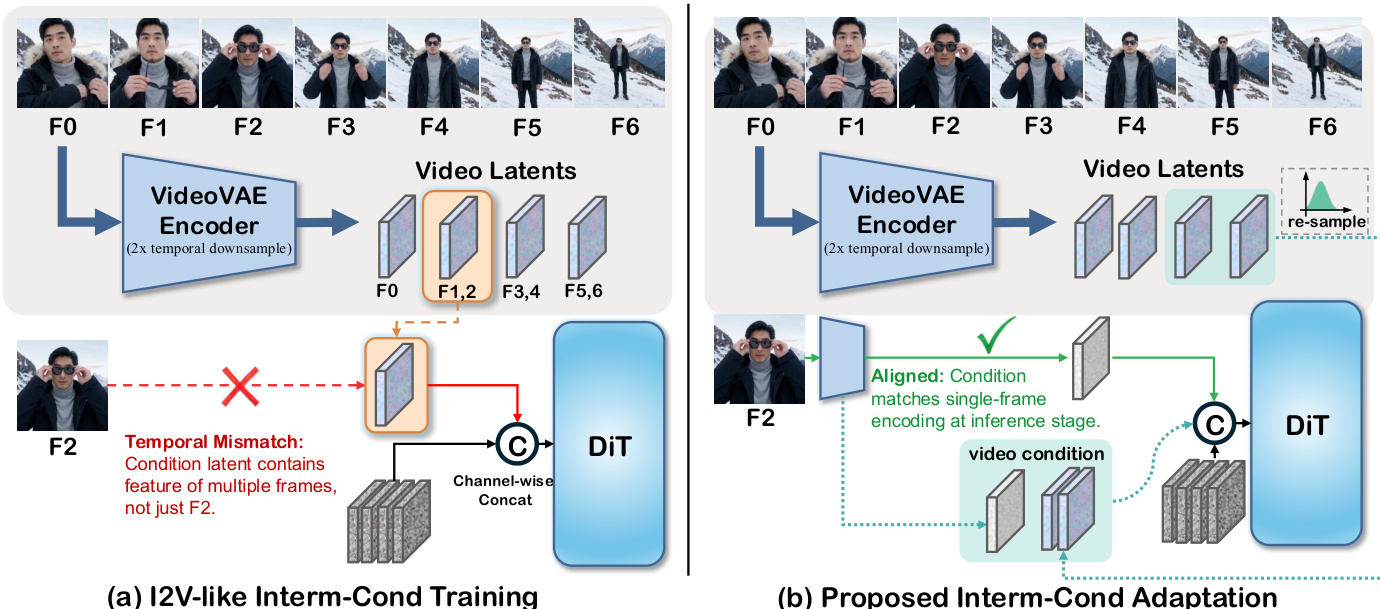
At the core of the framework is the Interm-Cond Adaptation strategy, which addresses the temporal misalignment inherent in conditioning on arbitrary frames. The VideoVAE encoder performs 2x temporal downsampling, meaning a single frame’s latent representation corresponds to multiple generated frames, leading to imprecise conditioning. As shown in the figure below, the authors resolve this by aligning the training distribution with inference: for single-frame conditions, the frame is re-encoded; for video conditions, subsequent frames are re-sampled from the latent distribution to match the temporal granularity of the target video. This lightweight tuning enables robust arbitrary-frame control without architectural overhaul.
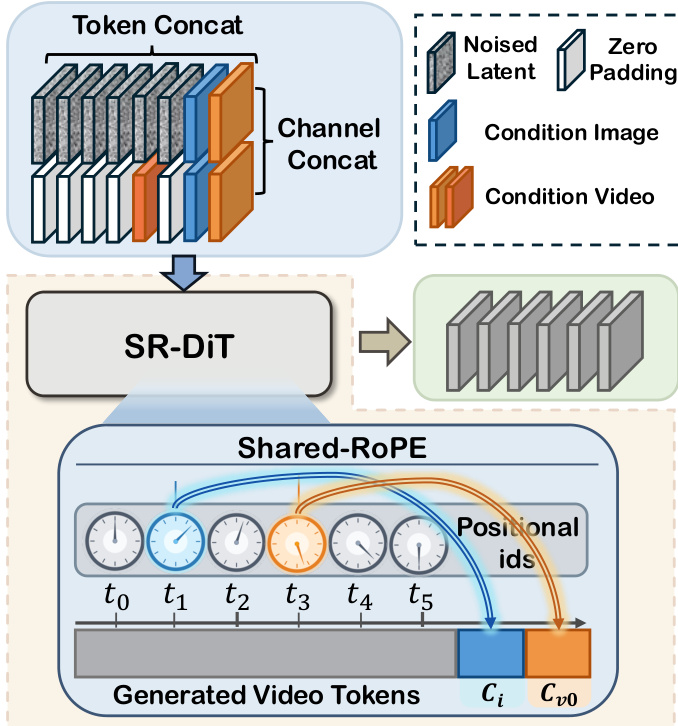
For super-resolution, the authors introduce Shared-RoPE to mitigate flickering and color shifts caused by channel-wise concatenation of conditioning signals. As depicted in the figure below, in addition to channel-wise conditioning, the VAE latent of each reference image is concatenated along the token sequence dimension, with its Rotary Position Embedding (RoPE) set to match the corresponding temporal position. This sequence-wise conditioning ensures spatial-temporal alignment, particularly critical for maintaining fidelity at higher resolutions. For video conditions, Shared-RoPE is applied only to the first frame to avoid computational overhead.
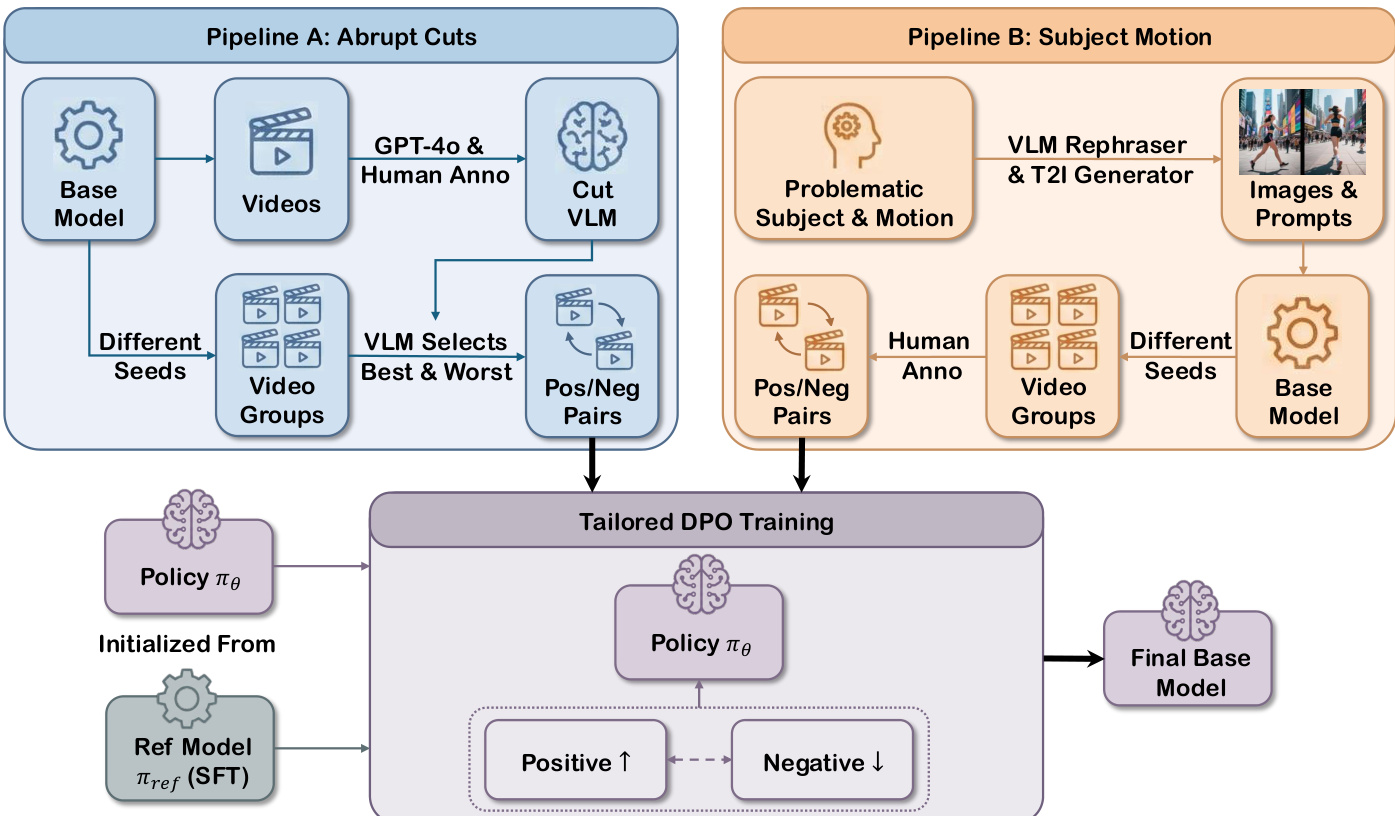
To enhance visual expressiveness and temporal coherence, the authors implement a Visual Expression SFT stage using a manually curated high-quality dataset. This is followed by a Tailored DPO training phase, which targets two specific failure modes: abrupt cuts and physically implausible subject motion. As shown in the figure below, two distinct pipelines generate contrastive preference pairs. Pipeline A uses a trained VLM discriminator to automatically select “best” and “worst” videos from groups generated with the same prompt but different seeds, focusing on cut severity. Pipeline B relies on human annotation to identify problematic subject motions, generating pairs that guide the model toward physically plausible dynamics. The DPO objective directly optimizes the policy πθ against a reference model πref:
LDPO=−E(c,vw,vl)∼D[logσ(βlogπref(vw∣c)πθ(vw∣c)−βlogπref(vl∣c)πθ(vl∣c))]where c denotes the conditioning inputs, and β controls the deviation from the reference policy.
For long-form generation, the authors design a Segment-wise Auto-Regressive (SAR) inference strategy. The target video is partitioned into consecutive segments using a sliding window in the latent space, with user-provided conditions acting as candidate boundaries. Each segment sn is generated conditionally on the tail latents of the previous segment τ(sn−1) and the local conditions Cn:
sn=Gθ(τ(sn−1),Cn)where Cn={cn(1),…,cn(m)} represents the heterogeneous conditions within the current window. This auto-regressive mechanism ensures pixel-level continuity across segment boundaries. Overlapping latents are fused before decoding, yielding a temporally coherent long video. The entire process operates in the latent space, avoiding pixel-level artifacts and leveraging the model’s learned consistency from prior training stages.
Experiment
- Demonstrated arbitrary frame-guided one-shot video generation through qualitative examples, showing coherent narrative transitions across complex scenarios like train-to-cyberpunk shifts and eye-to-meadow sequences without morphing artifacts.
- In multi-keyframe conditioning, achieved 15.79% higher overall preference than Vidu Q2 and 28.95% over Pixverse V5, with significant gains in prompt following (+23.68%) while maintaining competitive motion and visual quality.
- In first-last frame conditioning, surpassed Kling 2.5 by 3.97% in overall preference with consistent improvements in motion effects and prompt following (+4.64% each), matching visual fidelity of top-tier models.
The authors use ablation studies to isolate the impact of key optimizations in DreaMontage, showing that combining SFT with DPO improves motion handling and overall performance, while Shared-RoPE delivers the largest gain in visual quality. Results show that adaptive training alone boosts motion and prompt following without affecting visual fidelity, and Shared-RoPE significantly enhances visual quality over its base variant. The cumulative effect of these optimizations leads to substantial overall performance gains across multiple metrics.
