Command Palette
Search for a command to run...
LoGoPlanner: Lokalisierungsgestützte Navigationspolitik mit metrikbewusster visueller Geometrie
LoGoPlanner: Lokalisierungsgestützte Navigationspolitik mit metrikbewusster visueller Geometrie
Jiaqi Peng Wenzhe Cai Yuqiang Yang Tai Wang Yuan Shen Jiangmiao Pang
Zusammenfassung
Die Trajektorienplanung in unstrukturierten Umgebungen ist eine grundlegende und herausfordernde Fähigkeit für mobile Roboter. Traditionelle modulare Pipelines leiden unter Latenz und kaskadenartigen Fehlern über die Module der Wahrnehmung, Lokalisierung, Kartenerstellung und Planung hinweg. Kürzlich entwickelte end-to-end-Lernmethoden koppeln rohe visuelle Beobachtungen direkt an Steuerungssignale oder Trajektorien und versprechen eine höhere Leistung und Effizienz in offenen, realen Umgebungen. Allerdings stützen sich die meisten vorherigen end-to-end-Ansätze weiterhin auf getrennte Lokalisationsmodule, die eine präzise Kalibrierung der Sensorextrinsika für die Schätzung des eigenen Zustands erfordern, wodurch die Generalisierbarkeit über verschiedene Roboterformen und Umgebungen eingeschränkt bleibt. Wir stellen LoGoPlanner vor, einen lokalisationsbasierten, end-to-end-Navigationsrahmen, der diese Einschränkungen adressiert durch: (1) das Feintunen eines langfristigen visuell-geometrischen Grundmodells, um die Vorhersagen mit absoluter metrischer Skala zu verankern und somit eine implizite Zustandsschätzung für eine präzise Lokalisierung bereitzustellen; (2) die Rekonstruktion der umgebenden Szenengeometrie aus historischen Beobachtungen, um dichte, feinkörnige Umweltwahrnehmung für zuverlässiges Hindernisvermeidung bereitzustellen; und (3) die Bedingung der Policy auf der impliziten Geometrie, die durch die oben genannten Hilfsaufgaben initialisiert wird, wodurch die Fehlerfortpflanzung reduziert wird. Wir evaluieren LoGoPlanner sowohl in Simulation als auch in realen Umgebungen, wobei der vollständig end-to-end-Entwurf die kumulative Fehlerbildung verringert und die metrikbewusste Geometriememory die Planungskonsistenz und das Hindernisvermeidungsvermögen verbessert, was zu einer Steigerung um mehr als 27,3 % gegenüber Oracle-Lokalisierungs-Baselines sowie einer starken Generalisierbarkeit über verschiedene Roboterformen und Umgebungen führt. Der Quellcode und die Modelle sind öffentlich auf der Projektseite https://steinate.github.io/logoplanner.github.io/ verfügbar.
One-sentence Summary
Peng et al. introduce LoGoPlanner, a fully end-to-end navigation framework that eliminates external localization dependencies through implicit state estimation and metric-aware geometry reconstruction. By finetuning long-horizon visual-geometry backbones with depth-derived scale priors and conditioning diffusion-based trajectory generation on implicit geometric features, it achieves 27.3% better performance than oracle-localization baselines while enabling robust cross-embodiment navigation in unstructured environments.
Key Contributions
- LoGoPlanner addresses the limitation of existing end-to-end navigation methods that still require separate localization modules with precise sensor calibration by introducing implicit state estimation through a fine-tuned long-horizon visual-geometry backbone that grounds predictions in absolute metric scale. This eliminates reliance on external localization while providing accurate self-state awareness.
- The framework reconstructs dense scene geometry from historical visual observations to supply fine-grained environmental context for obstacle avoidance, overcoming the partial or scale-ambiguous geometry reconstruction common in prior single-frame approaches. This enables robust spatial reasoning across occluded and rear-view regions.
- By conditioning the navigation policy directly on this implicit metric-aware geometry, LoGoPlanner reduces error propagation in trajectory planning, achieving over 27.3% improvement over oracle-localization baselines in both simulation and real-world evaluations while demonstrating strong generalization across robot embodiments and environments.
Introduction
Mobile robots navigating unstructured environments require robust trajectory planning, but traditional modular pipelines suffer from latency and cascading errors across perception, localization, and planning stages. While end-to-end learning methods promise efficiency by mapping raw visuals directly to control signals, they still critically depend on external localization modules that require precise sensor calibration, limiting generalization across robots and environments. Monocular visual odometry approaches further struggle with inherent scale ambiguity and drift, often needing additional sensors or scene priors that reduce real-world applicability. The authors overcome these limitations by introducing LoGoPlanner, an end-to-end framework that integrates metric-scale visual geometry estimation directly into navigation. It leverages a finetuned visual-geometry backbone to implicitly estimate absolute scale and state, reconstructs scene geometry from historical observations for obstacle avoidance, and conditions the policy on this bootstrapped geometry to minimize error propagation without external localization inputs.
Method
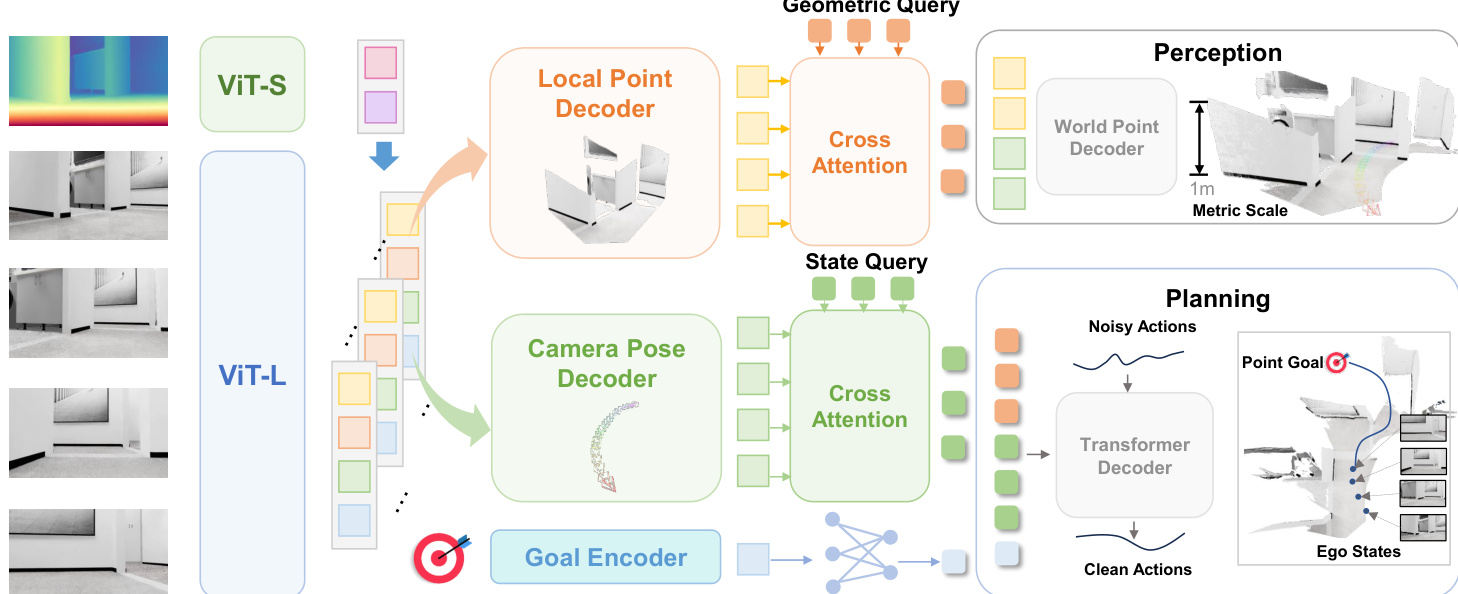
The authors leverage a unified end-to-end architecture—LoGoPlanner—that jointly learns metric-aware perception, implicit localization, and trajectory generation without relying on external modules. The framework is built upon a pretrained video geometry backbone, enhanced with depth-derived scale priors to enable metric-scale scene reconstruction. At its core, the system processes causal sequences of RGB-D observations to extract compact, world-aligned point embeddings that encode both fine-grained geometry and long-term ego-motion.
Refer to the framework diagram, which illustrates the overall pipeline. The architecture begins with a vision transformer (ViT-L) that processes sequential RGB frames into patch tokens. These tokens are fused at the patch level with geometric tokens derived from depth maps using a lightweight ViT-S encoder. The fused tokens are then processed through a transformer decoder augmented with Rotary Position Embedding (RoPE) to produce metric-aware per-frame features:
timetric=Attention(RoPE((tiI,tiD),pos))where pos∈RK×2 encodes 2D spatial coordinates to preserve positional relationships. To improve reconstruction fidelity, auxiliary supervision is applied via two task-specific heads: a local point head and a camera pose head. The local point head maps metric tokens to latent features hip, which are decoded into canonical 3D points in the camera frame:
hip=ϕp(timetric),Pilocal=fp(hip)These are supervised using the pinhole model:
pcam,i(u,v)=Di(u,v)K−1[uv1]⊤In parallel, the camera pose head maps the same metric tokens to features hic, which are decoded into camera-to-world transformations Tc,i, defined relative to the chassis frame of the last time step to ensure planning consistency.
To bridge perception and control without explicit calibration, the authors decouple camera and chassis pose estimation. The chassis pose Tb,i and relative goal gi are predicted from hic:
Tb,i=fb(hic)gi=fq(hic,g)The extrinsic transformation Text—capturing camera height and pitch—is implicitly learned through training data with varying camera configurations, enabling cross-embodiment generalization.
Rather than propagating explicit poses or point clouds, the system employs a query-based design inspired by UniAD. State queries QS and geometric queries QG extract implicit representations via cross-attention:
QS=CrossAttn(Qs,hc)QG=CrossAttn(Qd,hp)These are fused with goal embeddings to form a planning context query QP, which conditions a diffusion policy head. The policy generates trajectory chunks at=(Δxt,Δyt,Δθt) by iteratively denoising noisy action sequences:
αk−1=α(αk−γϵθ(QP,αk,k)+N(0,σ2I))where ϵθ is the noise prediction network, and α,γ are diffusion schedule parameters. This iterative refinement ensures collision-free, feasible trajectories while avoiding error accumulation from explicit intermediate representations.
Experiment
- Simulation on 40 InternScenes unseen environments: LoGoPlanner improved Home Success Rate by 27.3 percentage points and Success weighted by Path Length by 21.3% over ViPlanner, validating robust collision-free navigation without external localization.
- Real-world tests on TurtleBot, Unitree Go2, and G1 platforms: Achieved 90.0% Success Rate and 82.0% Success weighted by Path Length on Unitree Go2 in cluttered home scenes, demonstrating cross-platform generalization without SLAM or visual odometry.
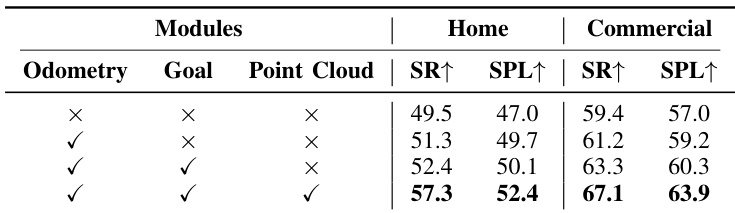
- Ablation studies: Confirmed Point Cloud supervision is critical for obstacle avoidance, and scale-injected geometric backbone reduces navigation error while improving planning accuracy.
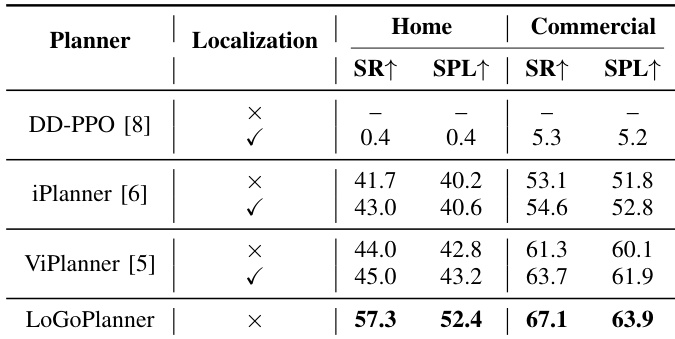
The authors evaluate navigation performance in simulation across home and commercial scenes, measuring success rate (SR) and success weighted by path length (SPL). LoGoPlanner, which performs implicit state estimation without external localization, outperforms all baselines, achieving 57.3 SR and 52.4 SPL in home scenes and 67.1 SR and 63.9 SPL in commercial scenes. Results show LoGoPlanner improves home scene performance by 27.3 percentage points in SR and 21.3% in SPL over ViPlanner, highlighting the benefit of integrating self-localization with geometry-aware planning.
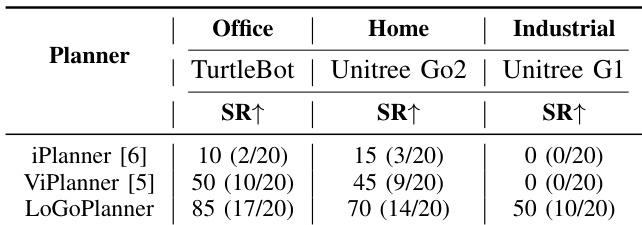
The authors evaluate LoGoPlanner against iPlanner and ViPlanner in real-world settings across three robotic platforms and environment types. LoGoPlanner achieves the highest success rates in all scenarios, notably 85% on TurtleBot in office environments, 70% on Unitree Go2 in home settings, and 50% on Unitree G1 in industrial scenes, outperforming both baselines. Results show LoGoPlanner’s ability to operate without external localization and maintain robust performance despite platform-induced camera jitter and complex obstacle configurations.
The authors evaluate ablation variants of their model by removing auxiliary tasks—Odometry, Goal, and Point Cloud—and measure performance in home and commercial scenes using Success Rate (SR) and Success weighted by Path Length (SPL). Results show that including all three modules yields the highest performance, with SR reaching 57.3 in home scenes and 67.1 in commercial scenes, indicating that joint supervision improves trajectory consistency and spatial perception. Omitting any module degrades performance, confirming that each contributes meaningfully to robust navigation.
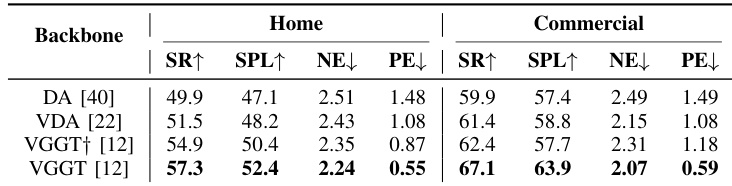
The authors evaluate different video geometry backbones for navigation performance, finding that VGGT with scale injection achieves the highest success rate and SPL in both home and commercial scenes while reducing navigation and planning errors. Results show that incorporating metric-scale supervision improves trajectory accuracy and planning consistency compared to single-frame or unscaled multi-frame models.