Command Palette
Search for a command to run...
OpenDataArena: Ein faire und offener Wettbewerbsspielplatz zur Bewertung des Wertes von Post-Training-Datensätzen
OpenDataArena: Ein faire und offener Wettbewerbsspielplatz zur Bewertung des Wertes von Post-Training-Datensätzen
Zusammenfassung
Die rasante Entwicklung von Large Language Models (LLMs) beruht maßgeblich auf der Qualität und Vielfalt der nachtrainierten Datensätze. Dennoch besteht eine kritische Divergenz: Während Modelle rigoros evaluiert werden, bleibt die zugrundeliegende Datenbasis ein schwarzes Kästchen – gekennzeichnet durch undurchsichtige Zusammensetzung, unklare Herkunft und fehlende systematische Bewertung. Diese Transparenzlosigkeit behindert die Reproduzierbarkeit und verschleiert den kausalen Zusammenhang zwischen Datenmerkmalen und Modellverhalten. Um diese Lücke zu schließen, stellen wir OpenDataArena (ODA) vor – eine ganzheitliche und offene Plattform, die darauf abzielt, den intrinsischen Wert nachtrainierter Daten zu benchmarken. ODA etabliert ein umfassendes Ökosystem aus vier zentralen Säulen: (i) einer einheitlichen Trainings-Evaluations-Pipeline, die faire, offene Vergleiche zwischen verschiedenen Modellen (z. B. Llama, Qwen) und Domänen ermöglicht; (ii) einem mehrdimensionalen Bewertungsrahmen, der die Datenqualität entlang mehrerer zehn unterschiedlicher Dimensionen profilieren kann; (iii) einem interaktiven Daten-Herkunftsexplorer zur Visualisierung der Datensatz-Genealogie und zur Analyse der einzelnen Quellen; sowie (iv) einem vollständig opensource-basierten Toolkit für Training, Evaluation und Bewertung, das Forschung zu Daten fördern soll. Umfangreiche Experimente auf ODA – umfassend über 120 Trainingsdatensätze aus mehreren Domänen, bewertet anhand von 22 Benchmarks, validiert durch mehr als 600 Trainingsläufe und 40 Millionen verarbeitete Datensätze – ergeben nicht-triviale Erkenntnisse. Unsere Analyse deckt die inhärenten Kompromisse zwischen Datenkomplexität und Task-Performance auf, identifiziert Redundanzen in gängigen Benchmarks durch Herkunftstracing und kartiert die genetischen Beziehungen zwischen Datensätzen. Wir veröffentlichen sämtliche Ergebnisse, Tools und Konfigurationen, um den Zugang zu qualitativ hochwertiger Datenbewertung zu demokratisieren. ODA zielt nicht darauf ab, lediglich eine Leaderboard zu erweitern, sondern veranschaulicht einen Paradigmenwechsel von der trial-and-error-basierten Datenkuration hin zu einer fundierten Wissenschaft des datenzentrierten KI, und ebnet den Weg für rigorose Untersuchungen zu Datenmischgesetzen und strategischer Zusammensetzung von Grundmodellen.
One-sentence Summary
Researchers from Shanghai Artificial Intelligence Laboratory and OpenDataLab et al. introduce OpenDataArena (ODA), a comprehensive platform that benchmarks post-training data value via a unified evaluation pipeline, multi-dimensional scoring framework, interactive lineage explorer, and open-source toolkit, enabling systematic data evaluation to shift from trial-and-error curation to a principled science of Data-Centric AI.
Key Contributions
- The post-training data for large language models remains a "black box" with opaque composition and uncertain provenance, hindering reproducibility and obscuring how data characteristics influence model behavior. This critical gap prevents systematic evaluation of data quality despite rigorous model benchmarking.
- OpenDataArena introduces a holistic platform featuring a unified training-evaluation pipeline, multi-dimensional scoring framework across tens of quality axes, and an interactive data lineage explorer to transparently benchmark data value and trace dataset genealogy. Its open-source toolkit enables fair comparisons across diverse models and domains while standardizing data-centric evaluation.
- Experiments across 120 datasets on 22 benchmarks, validated by 600+ training runs and 40 million data points, reveal inherent trade-offs between data complexity and task performance while identifying redundancy in popular benchmarks through lineage analysis. These results empirically demonstrate that carefully curated, information-dense datasets can outperform larger unstructured collections and highlight response quality as a stronger predictor of downstream performance than prompt complexity.
Introduction
The authors address the critical gap in Large Language Model development where post-training data quality directly impacts model performance yet remains unmeasured and opaque. Current practices rigorously benchmark models but treat training datasets as black boxes with unclear composition and provenance, hindering reproducibility and obscuring how specific data characteristics influence model behavior. To solve this, they introduce OpenDataArena a holistic open platform featuring a unified training-evaluation pipeline multi-dimensional scoring across dozens of quality axes interactive data lineage tracing and fully open-source tools. Validated across 120 datasets and 22 benchmarks the system enables fair data comparisons revealing non-trivial insights like data complexity trade-offs and benchmark redundancies to transform data curation from trial-and-error into a principled science for Data-Centric AI.
Dataset
The authors compile OpenDataArena (ODA), a repository of 120 publicly available supervised fine-tuning (SFT) datasets totaling over 40 million samples. These originate from community sources like Hugging Face, prioritized by demonstrated impact (minimum downloads/likes), recency (post-2023), domain relevance, and size constraints for computational feasibility. All undergo safety review and format standardization.
Key subsets include:
- Training data: Spans general dialog (20.8%), math (34.3%), code (30.6%), and science (14.4%). Sizes range from thousands to 100k+ samples per dataset (e.g., 0penThoughts3, LIM0, Tulu3-SFT).
- Benchmarks: 22+ evaluation suites covering:
- General: DROP, MMLU-PRO
- Math: GSM8K, OlympiadBenchMath
- Code: HumanEval+, LiveCodeBench
- Reasoning: ARC_c, GPQA diamond
The paper uses these datasets exclusively for evaluation—not training—to holistically assess model capabilities across domains. No mixture ratios or training splits apply. Processing involves:
- Standardizing instruction-response formats
- Conducting "Data Lineage" analysis to map dataset derivations and redundancies
- Applying multi-dimensional quality scoring (e.g., safety, coherence) to instructions (Q) and full pairs (QA)
- Visualizing relationships via interactive lineage graphs and comparative scoring interfaces.
Method
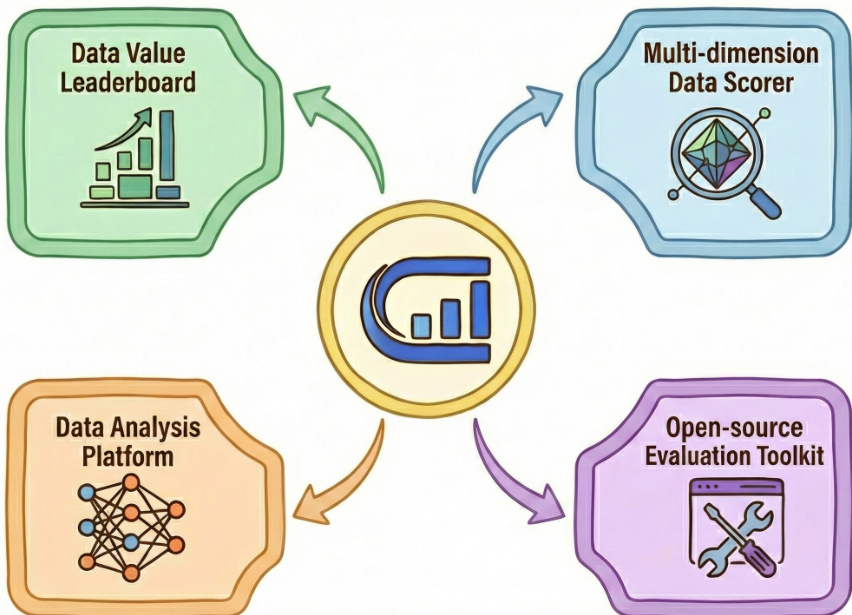
The authors leverage OpenDataArena (ODA) as a unified, data-centric evaluation infrastructure to systematically benchmark the intrinsic value of post-training datasets for large language models. The platform’s architecture is designed around four core components that collectively enable fair, reproducible, and multidimensional assessment. Refer to the framework diagram, which illustrates how these components—Data Value Leaderboard, Multi-dimension Data Scorer, Data Analysis Platform, and Open-source Evaluation Toolkit—interact around a central evaluation engine to form a cohesive system for dataset evaluation.
At the operational level, ODA implements a four-stage evaluation pipeline that begins with the Data Input Layer. Here, datasets are collected from diverse sources, normalized into a consistent format, and classified by domain to ensure uniformity before processing. The pipeline then advances to the Data Evaluation Layer, which serves as the computational core. In this stage, each dataset is used to fine-tune a fixed base model—such as Qwen or Llama—under standardized hyperparameters and training protocols. The resulting model is evaluated across a diverse suite of downstream benchmarks, including general chat, scientific reasoning, and code generation. This standardized train-evaluate loop isolates dataset quality as the sole variable, enabling direct, apples-to-apples comparisons.
As shown in the figure below, the Data Evaluation Layer also integrates the multi-dimensional scoring system, which assesses datasets along tens of axes—separately evaluating instructions (Q) and instruction-response pairs (Q&A). This scoring framework employs three methodological categories: model-based evaluation (e.g., predicting instruction difficulty), LLM-as-Judge (e.g., GPT-4 for qualitative coherence assessment), and heuristic rules (e.g., token length or response clarity). These metrics collectively generate a diagnostic “fingerprint” for each dataset, capturing dimensions such as complexity, correctness, and linguistic quality.
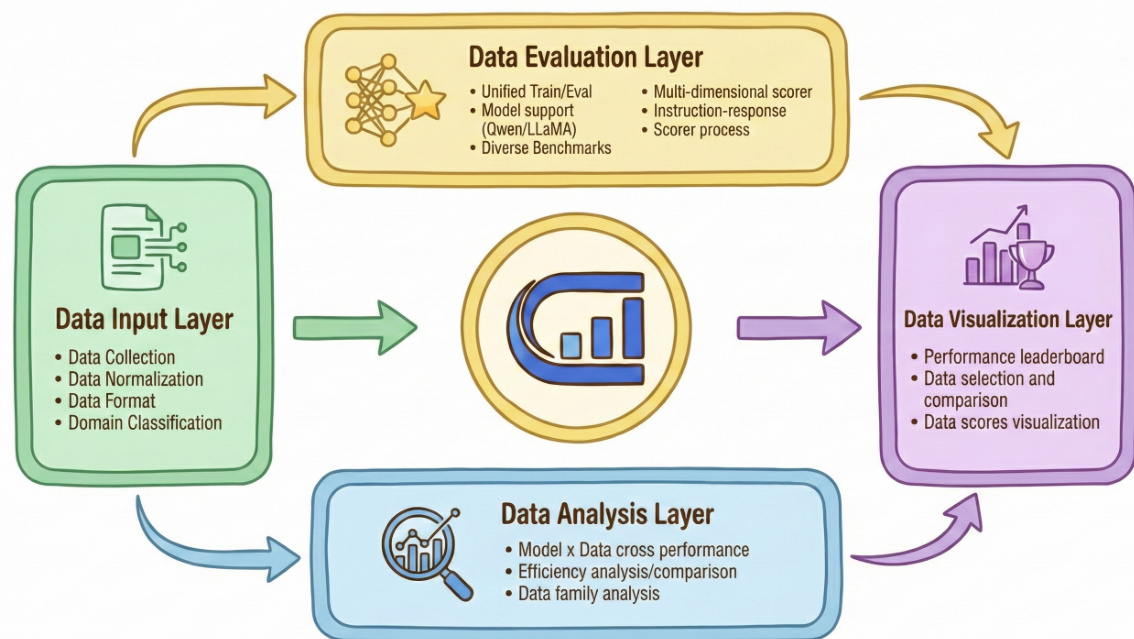
The Data Analysis Layer synthesizes the outputs from the evaluation stage to perform cross-model and cross-domain performance comparisons, efficiency analyses, and data family relationship mapping. This layer enables researchers to identify high-yield datasets and understand domain-specific or model-specific preferences. Finally, the Data Visualization Layer renders these insights into interactive leaderboards and comparative charts, allowing users to intuitively explore dataset rankings and quality profiles. The entire pipeline is supported by an open-source toolkit that provides all configurations, scripts, and raw results, ensuring full reproducibility and community extensibility.
To further enhance transparency, ODA incorporates an automated data lineage framework that models dataset dependencies as a directed graph G=(V,E), where nodes represent datasets and edges encode derivation relationships. This framework employs a multi-agent collaborative pipeline to recursively trace upstream sources from documentation across Hugging Face, GitHub, and academic papers. Through semantic inference, confidence scoring, and human-in-the-loop verification, the system constructs a factually grounded lineage graph that reveals redundancy, provenance, and compositional evolution across the dataset ecosystem.
Experiment
- Standardized pipeline validation across 600+ training runs confirmed data as the sole performance variable, using consistent Llama3.1-8B/Qwen models and OpenCompass evaluation.
- Lineage analysis of 70 seed datasets revealed a 941-edge global graph; AM-Thinking-v1-Distilled achieved +58.5 Math gain on Llama3.1-8B, while benchmark contamination propagated via datasets like SynthLabsAI/Big-Math-RL-Verified.
- Temporal analysis showed Math dataset quality surged from 35 to 56 (Qwen2.5, 2023-2025Q3), whereas Code domain performance remained volatile and General domain saturated.
- Math dataset rankings exhibited high consistency across Qwen models (Spearman 0.902), while General domain rankings reversed (-0.323 correlation).
- Response length strongly correlated with Math performance (0.81), but Code domain showed inverse trends (e.g., -0.29 for response length).
The authors use Spearman rank correlation to measure consistency in dataset rankings between Qwen2.5 and Qwen3 models across domains. Results show Math datasets exhibit strong consistency (0.902), while General datasets show negative correlation (-0.323), indicating saturation effects in general instruction following as models advance. Science and Code domains show weak positive correlations, suggesting their specialized knowledge remains valuable but less stable across model generations.
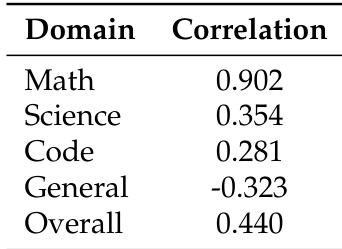
The authors use standardized fine-tuning and evaluation protocols across Qwen2.5 and Qwen3 models to compare dataset performance rankings. Results show high consistency in Math domain rankings between models (Spearman correlation 0.902), while General domain rankings exhibit negative correlation (-0.323), suggesting saturation in instruction-following tasks for stronger models. Code and Science domains show weak positive correlations, indicating evolving dataset value as base model capabilities advance.