Command Palette
Search for a command to run...
AI-Trader: Benchmarking autonome Agenten in Echtzeit-Finanzmärkten
AI-Trader: Benchmarking autonome Agenten in Echtzeit-Finanzmärkten
Tianyu Fan Yuhao Yang Yangqin Jiang Yifei Zhang Yuxuan Chen Chao Huang
Zusammenfassung
Große Sprachmodelle (LLMs) haben ein beachtliches Potenzial als autonome Agenten gezeigt und durch fortgeschrittene Schlussfolgerungskapazitäten sowie die koordinierte Nutzung von Werkzeugen menschlich-expertes Leistungsniveau annähern können. Dennoch bleibt die Entscheidungsfindung in vollständig dynamischen und live betriebenen Umgebungen äußerst herausfordernd, da eine Echtzeit-Integration von Informationen und adaptivere Reaktionen erforderlich sind. Obwohl bestehende Ansätze bereits Mechanismen zur Echtzeit-Bewertung in strukturierten Aufgaben untersucht haben, besteht weiterhin eine kritische Lücke im Bereich systematischer Benchmarking-Verfahren für reale Anwendungen – insbesondere im Finanzbereich, in dem strenge Anforderungen an die Echtzeit-Strategiefähigkeit bestehen. Um diese Lücke zu schließen, stellen wir AI-Trader vor: den ersten vollständig automatisierten, live betriebenen und datenunverfälschten Benchmark für LLM-Agenten im Bereich der Finanzentscheidungsfindung. AI-Trader umfasst drei zentrale Finanzmärkte – US-Aktien, A-Aktien und Kryptowährungen – mit mehreren Handelsgranularitäten, um realistische, live betriebene Finanzumgebungen zu simulieren. Unser Benchmark implementiert eine revolutionäre, vollständig autonome Minimal-Information-Paradigma, bei dem Agenten lediglich essentielle Kontextinformationen erhalten und selbstständig, ohne menschliche Intervention, aktuelle Marktdaten suchen, überprüfen und synthetisieren müssen. Wir evaluieren sechs etablierte LLMs anhand dreier Märkte und mehrerer Handelsfrequenzen. Unsere Analyse ergibt auffällige Erkenntnisse: Allgemeine Intelligenz übersetzt sich nicht automatisch in effektive Handelsfähigkeit; die meisten Agenten erzielen schlechte Renditen und zeigen eine schwache Risikomanagement-Fähigkeit. Wir zeigen, dass die Fähigkeit zum Risikomanagement die Robustheit über Märkte hinweg bestimmt, und dass künstliche Intelligenz-basierte Handelsstrategien in hochliquiden Märkten leichter überdurchschnittliche Renditen erzielen als in politikgetriebenen Umgebungen. Diese Ergebnisse offenbaren kritische Grenzen der derzeitigen autonomen Agenten und liefern klare Anhaltspunkte für zukünftige Verbesserungen.
One-sentence Summary
The authors from the University of Hong Kong propose AI-Trader, a fully automated, live benchmark for evaluating LLM agents in financial decision-making across U.S. stocks, A-shares, and cryptocurrencies, introducing a minimal-information paradigm that forces autonomous real-time data synthesis; their evaluation reveals that general intelligence does not ensure trading success, with risk control emerging as key to cross-market robustness, especially in liquid markets, and underscores the need for improved agent design in dynamic financial environments.
Key Contributions
- We introduce AI-Trader, the first fully autonomous, live, and data-uncontaminated benchmark for evaluating LLM agents in real-world financial decision-making across three major markets: U.S. stocks, A-shares, and cryptocurrencies, with multiple trading granularities to simulate dynamic, real-time market conditions.
- The benchmark enforces a minimal information paradigm where agents receive only essential context and must independently search, verify, and synthesize live market data through autonomous tool use, eliminating human intervention and enabling rigorous assessment of real-time reasoning and adaptability.
- Evaluation of six mainstream LLMs reveals that general intelligence does not ensure trading effectiveness, with most agents showing poor returns and weak risk management, while risk control emerges as a key determinant of cross-market robustness, and excess returns are more achievable in highly liquid markets.
Introduction
Financial markets present a high-stakes, real-time environment where autonomous agents must integrate live information, reason under uncertainty, and make time-critical decisions—challenges that static benchmarks fail to capture. Prior evaluation frameworks often rely on fixed data, pre-defined workflows, or human-in-the-loop interventions, creating a disconnect between lab performance and real-world capability. These limitations hinder meaningful assessment of true autonomous decision-making, especially in dynamic domains like trading.
The authors introduce AI-Trader, the first fully autonomous, live, and data-uncontaminated benchmark for evaluating LLM agents across U.S. stocks, A-shares, and cryptocurrencies. Agents operate with minimal context—only current holdings, real-time prices, and access to tools—requiring them to independently search, verify, and synthesize live market data without any human guidance. This minimal information paradigm enforces rigorous demonstration of long-horizon reasoning, information retrieval, and adaptive strategy execution.
Their evaluation of six mainstream LLMs reveals that general intelligence does not imply trading competence: most agents deliver poor returns and exhibit weak risk management, with performance heavily dependent on market liquidity and structure. The study underscores that risk control is key to cross-market robustness and highlights the need for improved autonomous planning and adaptation in LLM agents. The open-sourced framework enables reproducible, high-fidelity assessment of agent capabilities in real financial environments.
Dataset
- The dataset spans three distinct financial markets: the U.S. stock market, China's A-share market, and the cryptocurrency market, enabling evaluation of agent generalization across different regulatory environments, investor behaviors, and market dynamics.
- Trading frequencies are supported at both hourly and daily intervals to capture diverse market behaviors and test agent responsiveness across time horizons.
- For the U.S. stock market, the dataset includes all 100 constituents of the Nasdaq-100 Index, representing large-cap, non-financial firms in technology, semiconductors, biotech, internet services, and consumer discretionary sectors. Key companies include Apple, Microsoft, NVIDIA, Amazon, Alphabet, Tesla, and Meta.
- The U.S. portfolio includes a cash asset with zero return to allow agents to practice risk-free capital allocation and demonstrate full portfolio management skills.
- The A-share market subset comprises the 50 stocks in the SSE-50 Index, selected from the Shanghai Stock Exchange. These are major blue-chip firms across finance, consumer goods, industrials, IT, energy, and healthcare, including Ping An Insurance, Kweichow Moutai, and China Merchants Bank.
- Both market environments are designed to reflect real-world conditions: the U.S. market emphasizes sensitivity to macroeconomic factors and technological innovation, while the A-share market highlights macro-driven volatility, sector rotation, and non-stationary behavior.
- The authors use the data in a training and evaluation framework where agents are trained on a mixture of market subsets with dynamically adjusted ratios to simulate cross-market adaptability.
- Data is processed to ensure consistent time alignment across markets, with no external data augmentation.
- No cropping is applied; full historical price and volume data are used for each asset.
- Metadata includes asset identifiers, sector classifications, market capitalization tiers, and index membership to support structured analysis and model interpretation.
Method
The authors leverage a modular architecture for AI-Trader, designed to support autonomous, adaptive trading agents within a unified and extensible framework. The system operates as a closed-loop process, where agents continuously observe market conditions, reason about potential actions, and execute trades, all while interacting with a live environment through a standardized toolkit. This architecture is structured around three primary components: the agent's observation and action spaces, the toolkit of available tools, and the live environment that simulates real-world trading constraints.
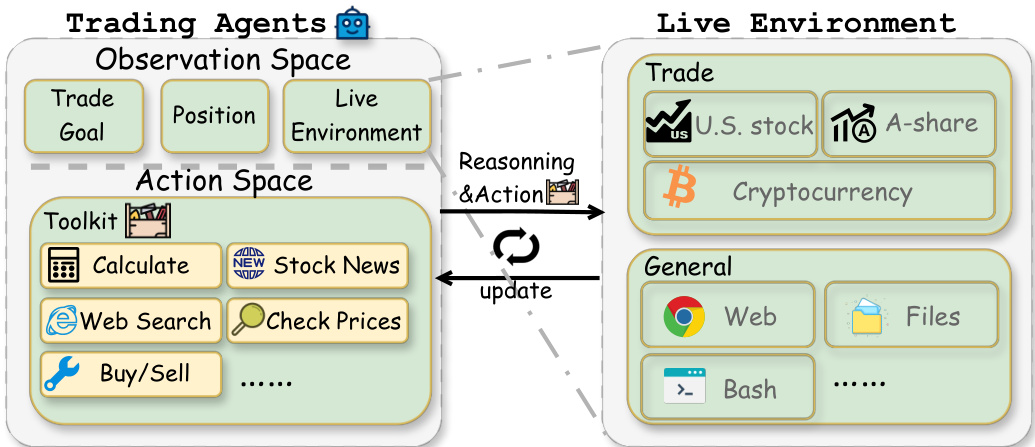
As shown in the figure below, the agent's observation space encompasses key market data such as current asset prices p and the agent's portfolio holdings s, forming the initial observation o0. This base information is augmented dynamically through tool invocations, which provide additional data such as detailed stock indicators πi and general market news i, resulting in a comprehensive observation ot at each time step. The agent's reasoning process, guided by the ReAct paradigm, operates autonomously, generating natural language traces that articulate its decision-making logic. These traces are recorded to ensure transparency and reproducibility, enabling researchers to analyze the agent's behavior in complex financial contexts.
The action space is constrained to three discrete actions per asset: buy, sell, or hold. The agent's policy function at=f(ot,rt) maps the current observation ot and reasoning rt to an executable action, ensuring decisions are both autonomous and compliant with real-world constraints such as liquidity and regulatory rules. If an action would violate these constraints, the system triggers a self-correction mechanism, requiring the agent to re-evaluate and generate a new, feasible decision.
The toolkit, which includes tools for checking prices, performing web searches, retrieving stock news, executing trades, and performing calculations, is designed to be modular and extensible. Each tool is built upon the Model Context Protocol (MCP), enabling seamless integration and adaptation across different asset classes and trading frequencies. The Trade tool, for instance, enforces market-specific rules such as lot-size requirements and updates portfolio holdings and cash balances in real time, ensuring accurate and auditable trade execution. The interaction between the agent and the live environment is bidirectional: the agent receives updated observations from the environment after each action, and the environment is updated with the agent's decisions, maintaining the integrity of the closed-loop system.
Experiment
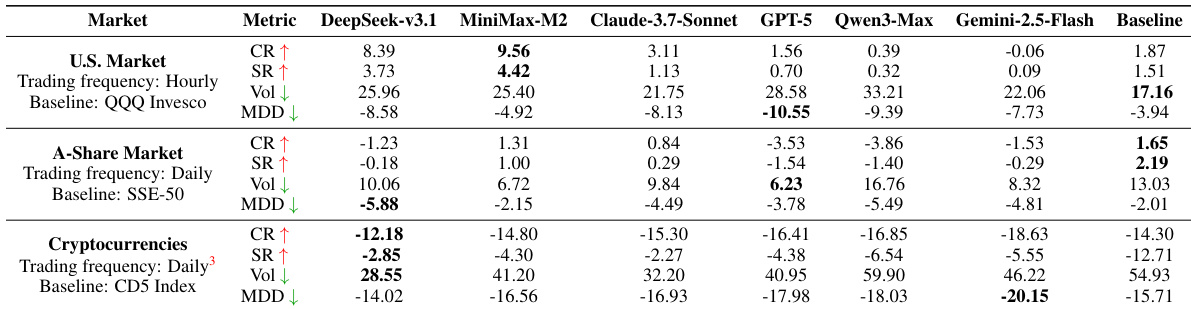
- Evaluated AI trading agents across U.S. equities, A-shares, and cryptocurrencies using daily (A-shares, crypto) and hourly (U.S. equities) strategies, assessing performance on cumulative return, Sortino ratio, volatility, and maximum drawdown.
- MiniMax-M2 achieved the highest cumulative return of 9.56% in the U.S. market (vs. QQQ’s 1.87%) with a Sortino ratio of 4.42 and maximum drawdown of -4.92%, demonstrating superior risk control and robustness across markets.
- DeepSeek-v3.1 outperformed the CD5 Index in the crypto market (-12.18% vs. -14.30%) by maintaining a high cash position (up to 41%) and executing strategic buy-the-dip trades, highlighting its adaptability in high-volatility environments.
- GPT-5, Qwen3-Max, and Gemini-2.5-Flash underperformed across all markets, with GPT-5 recording a cumulative return of 1.56% in the U.S. market and -16.41% in crypto, underscoring the gap between general language capabilities and effective trading.
- Model generalization is limited: DeepSeek-v3.1 excelled in the U.S. market (8.39% CR) but failed in A-shares (-1.23% CR), while MiniMax-M2 maintained consistent performance across all markets, indicating context-aware adaptability is critical.
- Case studies revealed that agents can emulate human-like behavior—DeepSeek-v3.1 successfully avoided a major U.S. market crash by diversifying into defensive sectors and increasing cash, but later underperformed due to unverified news, exposing weaknesses in information verification.
The authors use a multi-market, multi-frequency experimental design to evaluate AI trading agents across U.S. equities, A-shares, and cryptocurrencies, with performance measured using cumulative return, Sortino ratio, volatility, and maximum drawdown. Results show that MiniMax-M2 achieves the highest cumulative return and Sortino ratio in the U.S. market and remains the only consistently profitable agent in the A-share market, while DeepSeek-v3.1 outperforms the baseline in cryptocurrencies due to effective cash management and strategic trading during downturns.
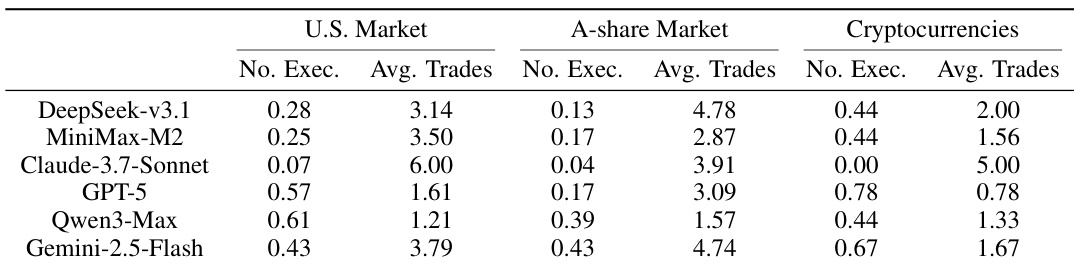
The authors use the table to compare the trading behavior of different AI models across three markets, showing that MiniMax-M2 executes trades less frequently than most other models, with the lowest proportion of no-trade executions in the U.S. and A-share markets. DeepSeek-v3.1 and Claude-3.7-Sonnet exhibit higher average trade counts in the U.S. and A-share markets, indicating more active trading strategies, while Gemini-2.5-Flash shows the highest average trades in cryptocurrencies, reflecting its more aggressive approach in that volatile environment.