Command Palette
Search for a command to run...
Konzeptzusammensetzung aus Bildern und Videos mittels Konzept-Prompt-Bindung
Konzeptzusammensetzung aus Bildern und Videos mittels Konzept-Prompt-Bindung
Xianghao Kong Zeyu Zhang Yuwei Guo Zhuoran Zhao Songchun Zhang Anyi Rao
Zusammenfassung
Visuelle Konzeptzusammensetzung, die darauf abzielt, verschiedene Elemente aus Bildern und Videos zu einer einheitlichen, kohärenten visuellen Ausgabe zu integrieren, erreicht nach wie vor nicht ausreichend präzise Extraktion komplexer Konzepte aus visuellen Eingaben und flexible Kombination von Konzepten aus Bildern und Videos. Wir stellen Bind & Compose vor, eine One-Shot-Methode, die flexible visuelle Konzeptzusammensetzung ermöglicht, indem visuelle Konzepte mit entsprechenden Prompt-Token verknüpft und der Ziel-Prompt aus gebundenen Token verschiedener Quellen zusammengesetzt wird. Die Methode nutzt eine hierarchische Bindungsstruktur zur Kreuz-Attention-Conditioning in Diffusion-Transformern, um visuelle Konzepte präzise in entsprechende Prompt-Token zu kodieren, was eine genaue Dekomposition komplexer visueller Konzepte ermöglicht. Um die Genauigkeit der Konzept-Token-Verknüpfung zu verbessern, entwickeln wir eine Diversify-and-Absorb-Mechanismus, der einen zusätzlichen absorbierenden Token verwendet, um den Einfluss konzeptunrelevanter Details zu eliminieren, wenn mit diversifizierten Prompts trainiert wird. Um die Kompatibilität zwischen Bild- und Video-Konzepten zu erhöhen, präsentieren wir eine Temporale Entkoppelungsstrategie, die den Trainingsprozess von Video-Konzepten in zwei Phasen unter Verwendung einer Dual-Branch-Bindungsstruktur zur zeitlichen Modellierung entkoppelt. Evaluierungen zeigen, dass unsere Methode gegenüber bestehenden Ansätzen eine überlegene Konzeptkonsistenz, Prompt-Fidelität und Bewegungsqualität erreicht und somit neue Möglichkeiten für visuelle Kreativität eröffnet.
One-sentence Summary
Researchers from HKUST, CUHK, and HKUST(GZ) propose BiCo, a one-shot visual concept composition method that binds concepts to prompt tokens via a hierarchical binder in Diffusion Transformers. Using a Diversify-and-Absorb Mechanism and Temporal Disentanglement Strategy, BiCo improves binding accuracy and cross-modal compatibility, enabling flexible, high-fidelity composition of image and video elements with superior concept consistency and motion quality.
Key Contributions
- Visual concept composition faces challenges in accurately extracting complex concepts from visual inputs and flexibly combining elements from both images and videos; existing methods struggle with decomposing occluded or non-object concepts and lack support for cross-domain composition.
- The proposed Bind & Compose (BiCo) method introduces a hierarchical binder structure for Diffusion Transformers that binds visual concepts to textual prompt tokens via cross-attention conditioning, enabling precise decomposition and flexible composition without requiring explicit masks.
- To improve binding accuracy and cross-modal compatibility, BiCo designs a Diversify-and-Absorb Mechanism that filters out concept-irrelevant details during training and a Temporal Disentanglement Strategy with a dual-branch binder to align image and video concept learning, demonstrating superior performance in concept consistency, prompt fidelity, and motion quality.
Introduction
The authors leverage recent advances in text-to-video diffusion models to address the challenge of flexible visual concept composition—combining diverse visual elements such as objects, styles, and motions from both images and videos into coherent outputs. Prior methods struggle to accurately extract complex or non-object concepts (e.g., style, lighting) without manual masks or suffer from limited flexibility in combining concepts, especially across modalities (image vs. video). Many rely on LoRA-based adaptations or joint optimization that restrict the number and type of composable inputs, and most only support animating image subjects with video motion, not general attribute mixing.
To overcome these limitations, the authors introduce Bind & Compose (BiCo), a one-shot method that binds visual concepts to corresponding text tokens in the diffusion model’s prompt space, enabling precise decomposition and flexible recombination via simple token selection. Their approach introduces three key innovations: a hierarchical binder structure for accurate concept encoding within Diffusion Transformers, a Diversify-and-Absorb Mechanism to improve binding robustness by filtering out irrelevant details during training, and a Temporal Disentanglement Strategy with a dual-branch binder to align image and video concept learning, ensuring compatibility in cross-modal composition. This design enables seamless integration of spatial and temporal attributes from heterogeneous sources, significantly improving concept consistency, prompt fidelity, and motion quality in generated videos.
Method
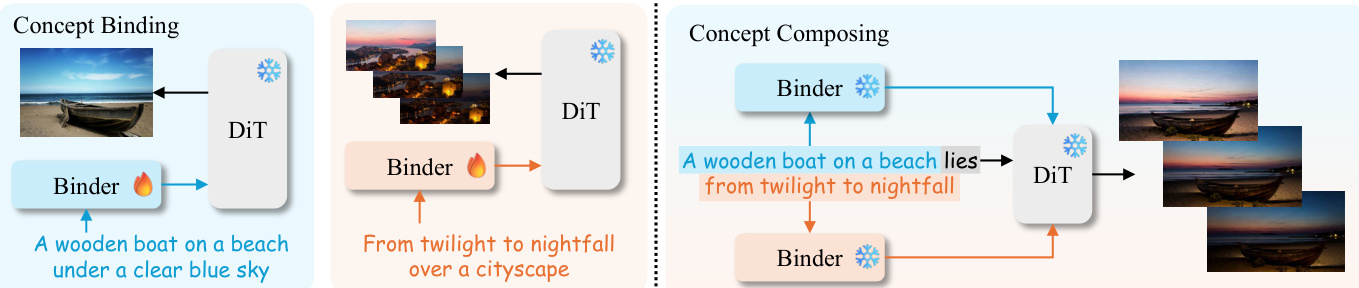
The authors leverage a modular, two-phase framework—concept binding followed by concept composing—to enable one-shot visual concept composition from heterogeneous sources such as images and videos. The core architecture is built upon a DiT-based text-to-video (T2V) model, augmented with lightweight, learnable binder modules that encode visual-text associations at multiple levels of granularity. The overall workflow begins with binding each source visual input to its corresponding textual prompt, followed by recomposing a new prompt from concept-specific token subsets to drive the generation of a coherent, synthesized output.
In the concept binding phase, each visual input—whether an image or video—is paired with its textual description. A binder module, attached to the DiT’s cross-attention conditioning layers, transforms the prompt tokens to encode the visual appearance or motion observed in the input. This binding is performed in a one-shot manner, requiring only a single forward-backward pass per source. The resulting updated prompt tokens are then used as key-value inputs in the DiT’s cross-attention layers during denoising. As shown in the framework diagram, this process enables the model to internalize the visual semantics of each concept independently before composition.
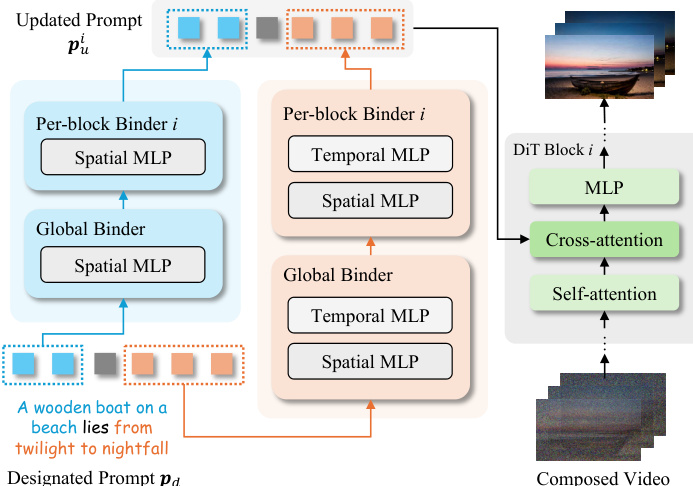
To support fine-grained control over concept decomposition, the authors introduce a hierarchical binder structure. This design comprises a global binder that performs an initial, coarse update of the entire prompt, followed by per-block binders that refine the prompt tokens specifically for each DiT block. Each binder is implemented as an MLP with a zero-initialized learnable scaling factor γ in a residual configuration:
f(p)=p+γ⋅MLP(p).For video inputs, the binder is extended into a dual-branch architecture with separate spatial and temporal MLPs, allowing the model to disentangle and independently optimize spatial and temporal concept representations. During inference, the designated prompt pd is decomposed into concept-specific segments, each routed through its corresponding binder. The outputs are then composed into a unified updated prompt pui for each DiT block, enabling flexible concept manipulation.
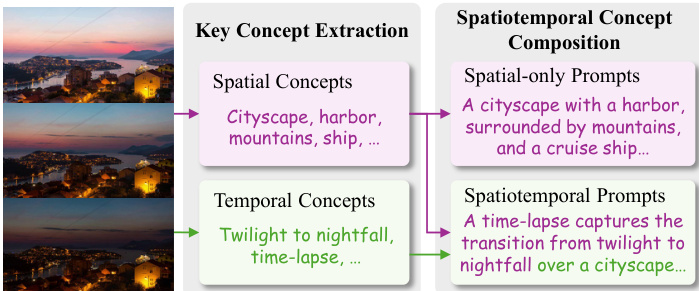
To enhance the fidelity of concept-token binding, especially under one-shot constraints, the authors introduce the Diversify-and-Absorb Mechanism (DAM). This mechanism leverages a Vision-Language Model (VLM) to extract key spatial and temporal concepts from the visual input and generate multiple diverse prompts that preserve the core semantic elements. The VLM first identifies critical concepts—such as “cityscape,” “twilight to nightfall,” or “harbor”—and then composes them into varied prompt formulations, including spatial-only and spatiotemporal variants. To mitigate interference from irrelevant visual details, a learnable absorbent token is appended to the prompt during training and later discarded during inference, effectively filtering out noise and improving binding accuracy.
To address the temporal heterogeneity between static images and dynamic videos, the authors propose the Temporal Disentanglement Strategy (TDS). This strategy decouples video concept training into two stages: first, training on individual frames using only spatial prompts to align with image-based binding; second, training on full videos with spatiotemporal prompts using a dual-branch binder. The temporal MLP branch is initialized with weights inherited from the spatial branch and fused via a learnable gating function g(⋅), which is zero-initialized to ensure a stable optimization trajectory:
MLP(p)←(1−g(p))⋅MLPs(p)+g(p)⋅MLPt(p).This staged, disentangled approach enables seamless composition of concepts from both image and video sources while preserving temporal coherence in the generated output.
Experiment
- BiCo is evaluated on visual concept composition using the Wan2.1-T2V-1.3B model, with binders trained for 2400 iterations per stage on NVIDIA RTX 4090 GPUs.
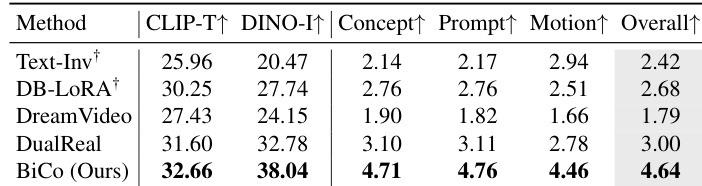
- On a test set of 40 cases from DAVIS and the Internet, BiCo achieves state-of-the-art performance: 32.66 CLIP-T and 38.04 DINO-I, outperforming DualReal [55] by +54.67% in Overall Quality (4.64 vs 3.00) in human evaluations.
- Qualitative results show BiCo excels in motion transfer and style composition tasks where Text-Inv, DB-LoRA, DreamVideo, and DualReal fail or exhibit concept drift, leakage, or static outputs.
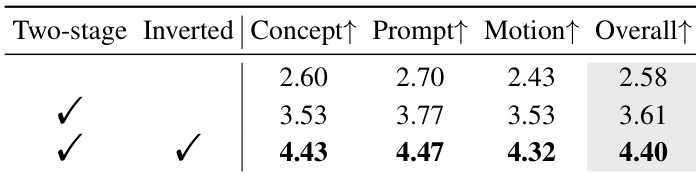
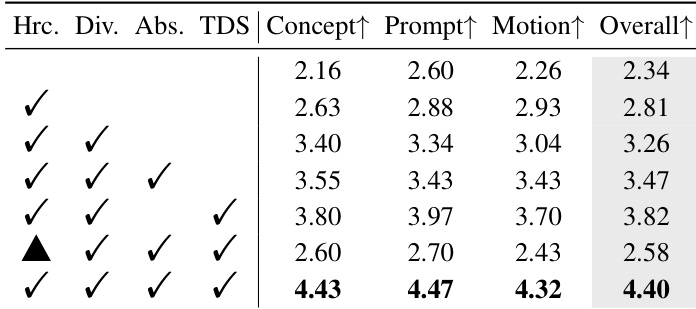
- Ablation studies confirm the importance of hierarchical binders, prompt diversification, absorbent tokens, and the two-stage inverted training strategy, with the full model achieving 4.40 Overall Quality versus 2.58 without two-stage training.
- BiCo enables flexible applications including concept decoupling (e.g., isolating dogs from a mixed scene) and text-guided editing by manipulating prompt tokens via trained binders.
- Limitations include unequal token importance handling and lack of common sense reasoning, leading to failures in complex concept reproduction (e.g., unusual hats) and anatomically incorrect outputs (e.g., five-legged dog).
The authors evaluate BiCo’s component contributions through ablation studies, showing that combining hierarchical binders, prompt diversification, absorbent tokens, and the TDS strategy yields the highest human evaluation scores across concept preservation, prompt fidelity, motion quality, and overall performance. Removing the two-stage inverted training strategy significantly degrades all metrics, confirming its critical role in stabilizing optimization. Results demonstrate that each component incrementally improves composition quality, with the full configuration achieving the best scores.
The authors use BiCo to outperform prior visual concept composition methods across both automatic metrics and human evaluations, achieving the highest scores in CLIP-T, DINO-I, and all human-rated dimensions including Concept, Prompt, Motion, and Overall Quality. Results show BiCo improves Overall Quality by 54.67% over the prior best method, DualReal, while supporting flexible concept composition and non-object concept extraction.
The authors evaluate the impact of their two-stage inverted training strategy on BiCo’s performance, showing that both the two-stage and inverted components are essential. Results indicate that using both techniques together yields the highest scores across all human evaluation metrics, including Concept, Prompt, Motion, and Overall Quality. Without this strategy, performance drops significantly, confirming its role in stabilizing training and improving concept binding.