Command Palette
Search for a command to run...
Skalierung von Zero-Shot-Referenz-zu-Video-Generierung
Skalierung von Zero-Shot-Referenz-zu-Video-Generierung
Zusammenfassung
Die Referenz-zu-Video-(R2V)-Generierung zielt darauf ab, Videos zu synthetisieren, die einem Textprompt entsprechen und gleichzeitig die Subjektidentität aus Referenzbildern bewahren. Derzeitige R2V-Methoden sind jedoch durch ihre Abhängigkeit von expliziten Tripeln aus Referenzbild, Video und Text eingeschränkt, deren Erstellung äußerst kostspielig und schwer skalierbar ist. Wir umgehen diesen Engpass, indem wir Saber vorstellen – einen skalierbaren Zero-Shot-Framework, der keiner expliziten R2V-Daten benötigt. Saber wird ausschließlich auf Video-Text-Paaren trainiert und setzt eine maskierte Trainingsstrategie sowie eine maßgeschneiderte, auf Aufmerksamkeit basierende Modellarchitektur ein, um identitätskonsistente und referenzbewusste Darstellungen zu lernen. Zudem werden Masken-Augmentierungstechniken integriert, um die bei der Referenz-zu-Video-Generierung häufig auftretenden Copy-Paste-Artefakte zu reduzieren. Darüber hinaus zeigt Saber beachtliche Generalisierungsfähigkeiten bei variabler Anzahl von Referenzen und erreicht eine überlegene Leistung auf dem OpenS2V-Eval-Benchmark im Vergleich zu Methoden, die mit R2V-Daten trainiert wurden.
Summarization
Researchers from Meta AI and King's College London propose Saber, a zero-shot reference-to-video generation framework that eliminates the need for costly reference image-video-text triplets. Trained solely on video-text pairs, Saber uses masked training, attention-based modeling, and mask augmentation to achieve strong identity preservation and outperform existing methods on OpenS2V-Eval.
Key Contributions
- Saber introduces a zero-shot framework for reference-to-video generation that eliminates the need for costly, manually constructed reference image-video-text triplet datasets by training exclusively on video-text pairs.
- The method proposes a masked training strategy with attention-based modeling and mask augmentations, enabling the model to learn identity-consistent, reference-aware representations while reducing copy-paste artifacts.
- Saber achieves state-of-the-art performance on the OpenS2V-Eval benchmark, outperforming models trained on explicit R2V data, and demonstrates strong generalization across varying numbers of reference images and diverse subject categories.
Introduction
Reference-to-video (R2V) generation aims to create videos that align with a text prompt while preserving the identity and appearance of subjects from reference images, enabling personalized applications like custom storytelling and virtual avatars. Prior methods rely on costly, manually constructed datasets of image-video-text triplets, which limit scalability and diversity, leading to poor generalization on unseen subjects. The authors leverage a zero-shot framework called Saber that eliminates the need for such specialized data by training exclusively on large-scale video-text pairs, using a masked training strategy to simulate reference conditions.
Key innovations include:
- A masked frame training approach that randomly samples and masks video frames as synthetic reference images, enabling data-efficient, scalable learning without curated R2V datasets
- A guided attention mechanism with attention masks to enhance focus on reference-aware features and suppress background distractions
- Spatial mask augmentations that improve visual fidelity and reduce copy-paste artifacts in generated videos while supporting flexible, multi-reference inputs
Dataset
- The authors use video-text pairs constructed from the ShutterStock Video dataset, where captions are generated for all video clips using Qwen2.5-VL-Instruct.
- The training data consists solely of these synthesized video-text pairs, enabling the use of both text-to-video and image-to-video sources through masked training.
- No additional datasets are used; all training data is derived from ShutterStock Video with automatically generated captions.
- The model is fine-tuned from Wan2.1-14B on this video-text data using a masked training strategy with probabilistic mask sampling.
- For mask generation, the foreground area ratio r is sampled: 10% of the time from [0, 0.1] (minimal reference), 80% from [0.1, 0.5] (typical subjects), and 10% from [0.5, 1.0] (large or background references).
- Mask augmentation includes random rotation (±10°), scaling (0.8–2.0), horizontal flipping (50% probability), and shearing (±10°) to reduce copy-paste artifacts.
- During inference, BiRefNet segments foreground subjects from reference images to generate masks.
- The model is trained with AdamW, a learning rate of 1e−5, and a global batch size of 64, following the denoising objective in the paper.
- Videos are generated with 50 denoising steps and a CFG guidance scale of 5.0, consistent with the Wan2.1 setup.
Method
The authors leverage a training paradigm that simulates reference-to-video generation without requiring explicit reference-image-video-text triplets. Instead, they dynamically generate masked frames from video frames during training, which serve as synthetic reference inputs. This approach enables the model to learn identity and appearance preservation from diverse, in-the-wild video content, circumventing the limitations of curated R2V datasets.
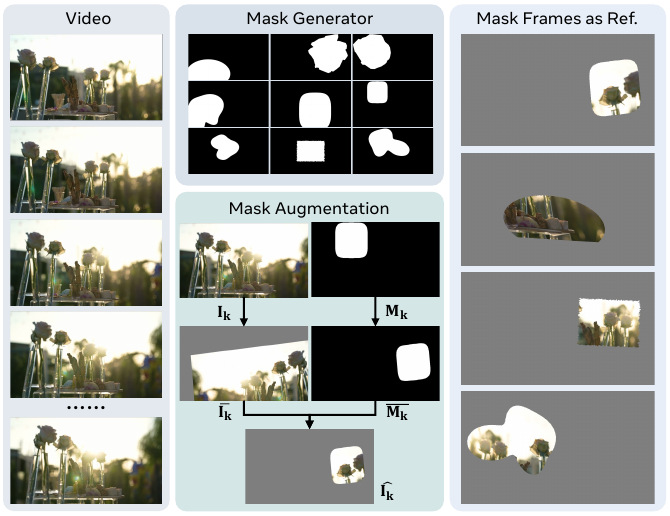
Refer to the framework diagram illustrating masked reference generation. For each randomly sampled frame Ik from a video, a mask generator produces a binary mask Mk with controllable foreground area ratio r∈[rmin,rmax]. The mask generator selects from predefined shape categories—such as ellipses, Fourier blobs, or convex/concave polygons—and employs a bisection search over a continuous scale parameter to meet the target area ratio. Topology-preserving adjustments (growth or shrinkage) are applied if pixel discretization prevents exact matching. The resulting mask is then paired with the frame and subjected to identical spatial augmentations—including rotation, scaling, shear, translation, and optional horizontal flip—to disrupt spatial correspondence and mitigate copy-paste artifacts. The augmented mask Mˉk is applied to the augmented frame Iˉk to produce the masked frame I^k=Iˉk⊙Mˉk. This process is repeated to generate a set of K masked frames {I^k}k=1K that serve as the reference condition during training.
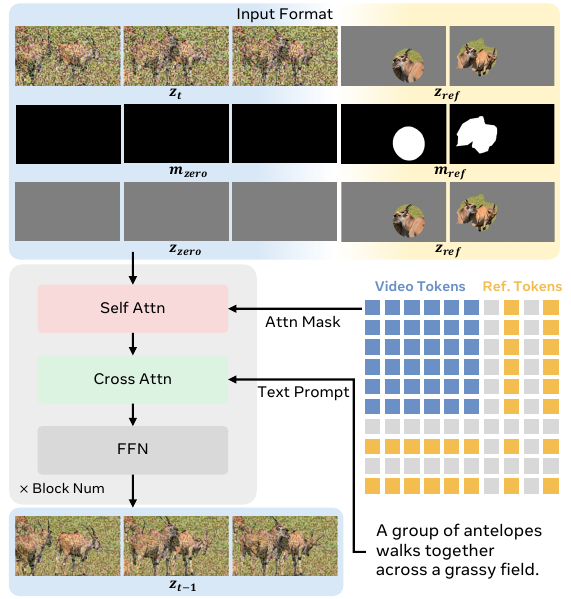
The model architecture builds upon the Wan2.1-14B framework, which includes a VAE, a transformer backbone, and a text encoder. The VAE encodes both the target video and the masked reference frames into latent space, producing z0 and zref, respectively. The input to the transformer is constructed by concatenating the noisy video latent zt, the reference latents zref, and corresponding mask latents mref along the temporal dimension. The mask latents are derived by resizing the binary masks Mk to latent resolution and are concatenated with zero masks mzero to match the temporal length of the video part. The full input zin is formed by channel-wise concatenation of three components: the concatenated latents, the concatenated masks, and the concatenated zero latents (to preserve conditioning fidelity). This input format is defined as:
zin=catcat[ztcat[mzerocat[zzerozref]temporalmref]temporalzref]temporalchannelAs shown in the figure below, the transformer processes this input through a sequence of blocks, each comprising self-attention, cross-attention, and feed-forward modules. In self-attention, video and reference tokens interact under an attention mask derived from the resized masks Mk, ensuring that only valid reference regions are attended. Cross-attention then integrates text features zP, guiding video tokens with the text prompt while aligning reference tokens semantically. The time step t is injected into the latents to modulate the diffusion process. The output of the transformer is the predicted latent zt−1, which is decoded by the VAE to generate the next video frame.
Experiment
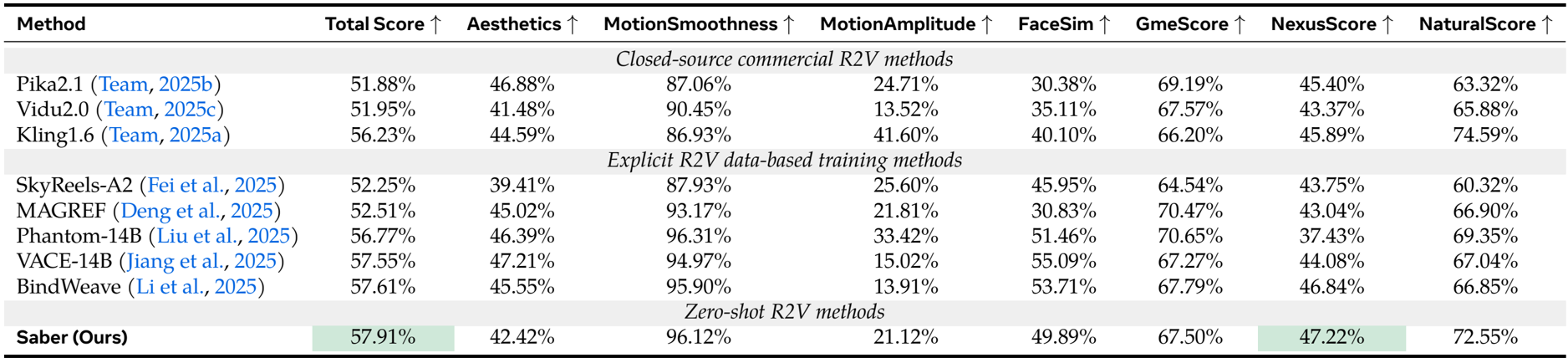
- Evaluated on OpenS2V-Eval benchmark, Saber achieves 57.91% total score in a zero-shot setting, surpassing closed-source methods like Kling1.6 (+1.68%) and explicitly trained R2V models including Phantom-14B (+1.14%), VACE-14B (+0.36%), and BindWeave (+0.30%).
- Saber attains the highest NexusScore (47.22%), outperforming Phantom by 9.79%, VACE by 3.14%, and BindWeave by 0.36%, demonstrating superior subject consistency without using dedicated R2V training data.
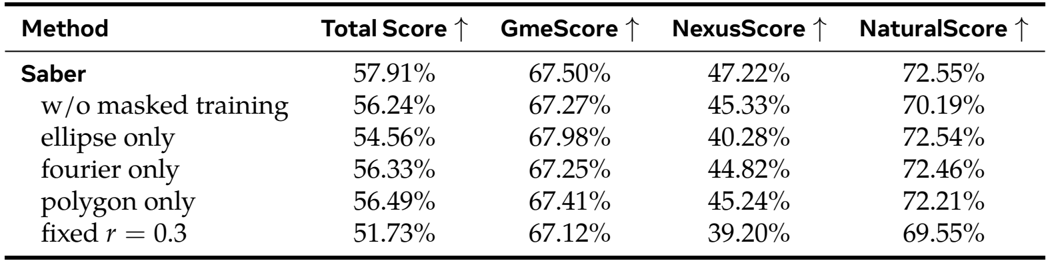
- Ablation studies show masked training improves total score by +1.67%, while diverse mask generation and augmentation are critical for generalization and natural composition, reducing copy-paste artifacts.
- The attention mask effectively prevents visual artifacts and enhances subject separation and blending by constraining reference-video token interactions.
- Qualitative results confirm Saber accurately generates videos with consistent identities across single and multiple human/object references, outperforming Kling1.6, Phantom, and VACE in identity preservation and coherence.
- Emergent abilities include handling multiple views of a single subject and robust cross-modal alignment between reference images and text prompts, enabling accurate attribute and positional control.
The authors use a zero-shot approach trained on video-text pairs to achieve the highest total score and NexusScore on the OpenS2V-Eval benchmark, outperforming both closed-source and explicitly trained R2V methods. Results show Saber excels in subject consistency and maintains competitive performance on text-video alignment and naturalness, validating its effectiveness without relying on dedicated R2V datasets.
The authors evaluate Saber’s ablation components on the OpenS2V-Eval benchmark, showing that removing masked training reduces the total score by 1.67% and significantly lowers NexusScore, indicating weaker subject consistency. Using only one mask type or fixing the foreground ratio degrades performance, confirming that mask diversity and adaptive masking are critical for generalization and video quality.