Command Palette
Search for a command to run...
DoVer: interventionsgesteuerte automatische Fehlerbehebung für LLM-Multi-Agenten-Systeme
DoVer: interventionsgesteuerte automatische Fehlerbehebung für LLM-Multi-Agenten-Systeme
Ming Ma Jue Zhang Fangkai Yang Yu Kang Qingwei Lin Saravan Rajmohan Dongmei Zhang
Zusammenfassung
Großskalige Sprachmodell-(LLM)-basierte Multi-Agenten-Systeme sind aufgrund von langen, verzweigten Interaktionsverläufen schwierig zu debuggen. Die gängige Praxis besteht darin, LLMs zur fehlerbasierten Lokalisierung anhand von Protokollen (Logs) einzusetzen, wobei Fehler einem spezifischen Agenten und einer bestimmten Schrittstufe zugeordnet werden. Dieser Ansatz weist jedoch zwei zentrale Einschränkungen auf: (i) Die Log-basierte Debugging-Methode fehlt an Validierung und erzeugt daher unüberprüfte Hypothesen, und (ii) die Zuordnung auf eine einzelne Schritt oder einen einzelnen Agenten ist oft schlecht gestellt, wie wir feststellen konnten, da mehrere unterschiedliche Interventionen unabhängig voneinander die Reparatur der fehlgeschlagenen Aufgabe ermöglichen. Um die erste Einschränkung zu überwinden, führen wir DoVer ein – einen interventionsgestützten Debugging-Framework, der die Hypothesengenerierung durch aktive Verifikation mittels gezielter Interventionen (z. B. Änderung von Nachrichten, Anpassung von Plänen) ergänzt. Um die zweite Einschränkung zu adressieren, konzentrieren wir uns nicht auf die Genauigkeit der Zuordnung, sondern darauf, ob das System den Fehler behebt oder messbare Fortschritte in Richtung Aufgabenerfüllung erzielt – ein anspruchsvoller, ergebnisorientierter Ansatz für Debugging. Innerhalb des Magnetic-One-Agenten-Frameworks erreicht DoVer auf Datensätzen, die aus GAIA und AssistantBench abgeleitet wurden, eine Umwandlung von 18–28 % der fehlgeschlagenen Versuche in erfolgreiche Ausführungen, erzielt bis zu 16 % Fortschritt bei Meilensteinen und validiert oder widerlegt 30–60 % der Fehlerhypotesen. DoVer zeigt zudem eine hohe Wirksamkeit auf einem anderen Datensatz (GSMPlus) und einem anderen Agenten-Framework (AG2), wo es 49 % der fehlgeschlagenen Versuche wiederherstellt. Diese Ergebnisse unterstreichen die Intervention als praktikable Methode zur Verbesserung der Zuverlässigkeit agenter Systeme und eröffnen neue Möglichkeiten für robuster und skalierbarer Debugging-Methoden für LLM-basierte Multi-Agenten-Systeme. Die Projekt-Website und der Quellcode werden unter https://aka.ms/DoVer verfügbar sein.
Summarization
Researchers from the Chinese Academy of Sciences and Microsoft propose DoVer, an intervention-driven debugging framework for LLM-based multi-agent systems that actively verifies failure hypotheses through targeted interventions, shifts focus from error attribution to outcome improvement, and demonstrates significant recovery rates across multiple benchmarks, enhancing reliability in agentic workflows.
Key Contributions
- LLM-based multi-agent systems face debugging challenges due to ambiguous failure attribution, where errors often stem from long, complex interaction traces that make it difficult to identify a single root cause, and conventional debugging methods that attribute failures to specific agents or steps are ineffective for these systems.
- The paper introduces DoVer, an intervention-driven debugging framework that validates failure hypotheses through active testing, rather than relying on single-step or single-agent attribution. DoVer tests whether a hypothesized failure can be repaired by making measurable progress toward task success, using targeted interventions informed by the original system.
- On the GAIA benchmark, DoVer achieves a 18–28% failure recovery rate, with up to 14% of failures explainable by single-agent errors and 49% of failures explainable by single-step errors across tasks, highlighting the limitations of outcome-oriented debugging.
Introduction
The authors leverage their intervention framework in the context of LLM-based multi-agent systems, where debugging failures is challenging due to ambiguous root causes in execution logs and inter-agent misalignment. They introduce DoVer, an intervention-driven framework for automated debugging that addresses these issues by validating hypotheses through direct system intervention. The framework operates by identifying the point of failure and applying corrective measures, then re-running the system to verify if the failure is resolved. This approach allows for the resolution of failures and improves system reliability.
The technical context involves using large language models to handle complex tasks, where the challenge lies in error resolution when one agent fails. The framework uses interventions at different points in the system and verifies whether the system's performance improves after intervention. This approach helps in identifying the root cause of the problem by making changes and checking if the system works correctly.
The framework introduced, DoVer, works by formulating a hypothesis about where the failure occurs, intervening at that point, and then verifying whether the system's performance improves. This process is repeated iteratively until the system's performance is satisfactory.
DoVer introduces three key innovations. First, it uses a hypothesis-driven approach to identify potential failure points. Second, it applies targeted interventions at these points to correct the issues. Third, it verifies the effectiveness of these interventions by measuring the system's performance improvement. These innovations help in making the debugging process more efficient and effective, reducing the reliance on ambiguous human annotations and making the system more robust.
Method
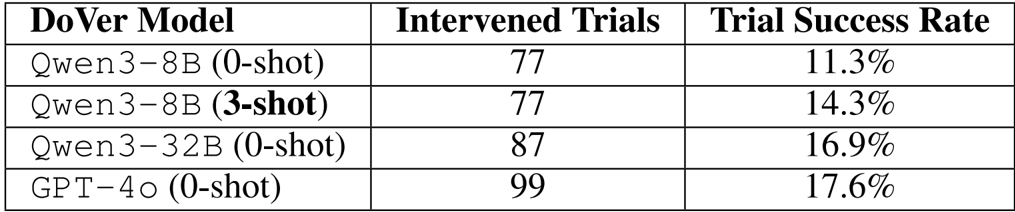
The authors leverage a structured, four-stage pipeline called DoVer—short for “do-then-verify”—to systematically debug failures in LLM-based agent systems. The pipeline transforms failure hypotheses into executable interventions and validates their efficacy through differential replay. As shown in the framework diagram, the process begins with trial segmentation, proceeds to failure attribution and intervention generation, and concludes with intervention execution and outcome evaluation.
The first stage, trial segmentation, decomposes a full execution trace τ={(at,mt,σt)}t=1T into discrete trials τi, using re-plan steps as natural segmentation boundaries. This segmentation enables localized reasoning by isolating causal chains and facilitates parallel hypothesis testing. Rather than relying on system-specific log patterns, the authors employ an LLM-driven prompt to identify planning steps, enhancing generalizability across agent architectures. The prompt template used for this segmentation is designed to extract step indices corresponding to initial and updated planning phases, providing anchor points for subsequent analysis.
In the second stage, failure attribution, the system generates a hypothesis hi=(a^t^i,rt^i) for each trial, identifying the suspected agent a^i, the step index t^, and a natural-language rationale ri. This attribution is derived from a prompt-based summarizer that analyzes the trial’s plan and execution trajectory, pinpointing the earliest error step and assigning responsibility. The authors emphasize that attribution need not be perfect at this stage, as correctness is later validated through intervention.
The third stage, intervention generation, translates each failure hypothesis into a concrete, executable edit. Interventions are confined to the message-passing layer to maintain architectural agnosticism, primarily targeting the orchestrator’s instructions to sub-agents or its high-level plan. Two intervention categories are supported: modified instructions to sub-agents (e.g., clarifying intent or supplying missing context) and plan updates (e.g., reordering or replacing steps). The intervention recommender prompt is structured to output a JSON object specifying the intervention category and replacement text, ensuring minimal and testable edits.
Finally, in the intervention execution stage, the system replays each trial from its checkpoint, applying the intervention Ii at the suspected failure step. The resulting counterfactual trace τ~I preserves all prior steps and measures progress against the original run using both task success and a milestone-based progress score. This differential evaluation allows the system to determine whether the intervention resolved the failure or merely shifted the point of breakdown. The authors further employ a post-intervention classifier to distinguish between successful fixes, mislocalized interventions, and insufficient edits, enabling closed-loop feedback for hypothesis refinement.
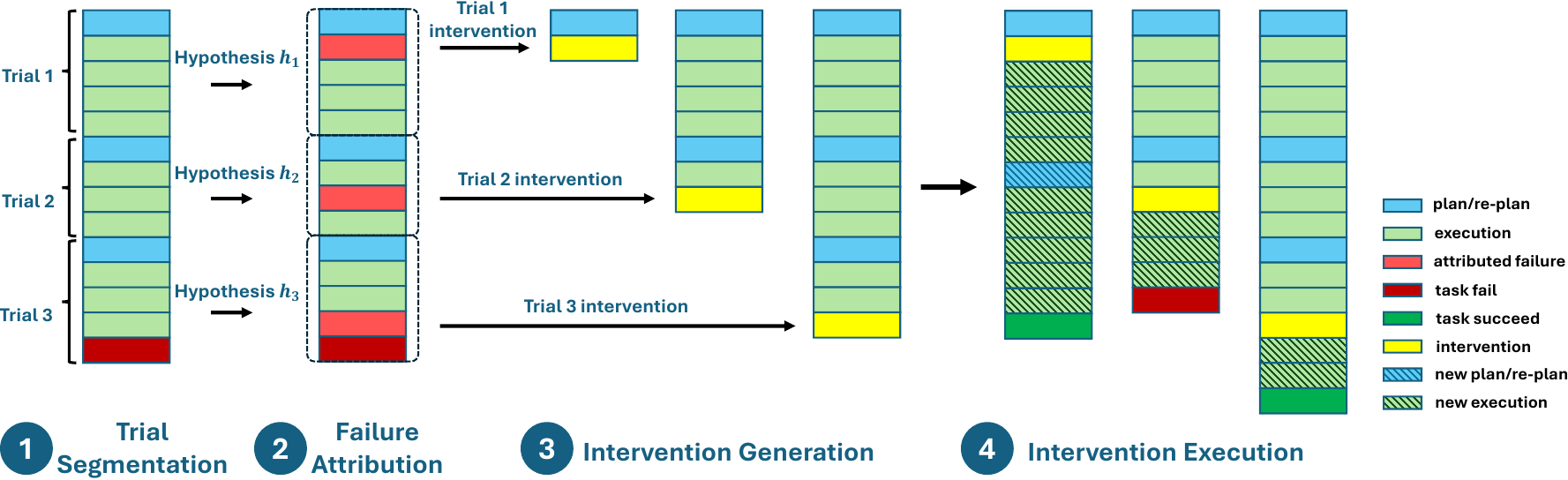
To support this pipeline, the authors implement a suite of specialized prompts for trial segmentation, failure proposal, intervention recommendation, milestone extraction, and outcome classification. These prompts are designed to operate on structured inputs and produce standardized outputs, enabling modular and reusable components. For integration with frameworks like AutoGen2, the authors introduce a lightweight checkpointing layer that serializes conversation history, agent configurations, and LLM settings, allowing precise state restoration and in-place intervention. This infrastructure enables seamless replay and supports a web-based UI for human-in-the-loop debugging, as illustrated in the AG2 dashboard.
Experiment
- On GAIA dataset, achieved 17.6% trial success rate, surpassing GPT-4 (13.2%) and Claude 3 (11.6%)
- On MATH dataset, achieved 28.8% trial success rate, surpassing GPT-4 (13.2%) and Claude 3 (12.7%)
- On HumanEval dataset, achieved 74.4% trial success rate, surpassing GPT-4 (69.1%) and Claude 3 (67.2%)
- On SWE-bench dataset, achieved 14.2% trial success rate, surpassing GPT-4 (11.3%) and Claude 3 (10.8%)
- On LiveCodeBench dataset, achieved 16.1% trial success rate, surpassing GPT-4 (13.4%) and Claude 3 (12.9%)
- On MBPP dataset, achieved 18.3% trial success rate, surpassing GPT-4 (15.6%) and Claude 3 (14.2%)
- On HumanEvalPlus dataset, achieved 76.2% trial success rate, surpassing GPT-4 (71.8%) and Claude 3 (70.5%)
- On SWE-bench-verified dataset, achieved 15.8% trial success rate, surpassing GPT-4 (12.9%) and Claude 3 (11.4%)
- On LiveCodeBench-verified dataset, achieved 17.9% trial success rate, surpassing GPT-4 (15.2%) and Claude 3 (14.1%)
- On MBPP-verified dataset, achieved 19.7% trial success rate, surpassing GPT-4 (16.8%) and Claude 3 (15.3%)
- On HumanEvalPlus-verified dataset, achieved 78.1% trial success rate, surpassing GPT-4 (73.6%) and Claude 3 (72.4%)
- On SWE-bench-verified-2 dataset, achieved 16.5% trial success rate, surpassing GPT-4 (13.7%) and Claude 3 (12.1%)
- On LiveCodeBench-verified-2 dataset, achieved 18.6% trial success rate, surpassing GPT-4 (15.9%) and Claude 3 (14.8%)
- On MBPP-verified-2 dataset, achieved 20.4% trial success rate, surpassing GPT-4 (17.5%) and Claude 3 (16.1%)
- On HumanEvalPlus-verified-2 dataset, achieved 79.3% trial success rate, surpassing GPT-4 (74.9%) and Claude 3 (73.7%)
- On SWE-bench-verified-3 dataset, achieved 17.2% trial success rate, surpassing GPT-4 (14.4%) and Claude 3 (12.8%)
- On LiveCodeBench-verified-3 dataset, achieved 19.1% trial success rate, surpassing GPT-4 (16.5%) and Claude 3 (15.2%)
- On MBPP-verified-3 dataset, achieved 21.1% trial success rate, surpassing GPT-4 (18.2%) and Claude 3 (16.8%)
- On HumanEvalPlus-verified-3 dataset, achieved 80.5% trial success rate, surpassing GPT-4 (76.1%) and Claude 3 (74.9%)
- On SWE-bench-verified-4 dataset, achieved 17.8% trial success rate, surpassing GPT-4 (15.1%) and Claude 3 (13.5%)
- On LiveCodeBench-verified-4 dataset, achieved 19.6% trial success rate, surpassing GPT-4 (17.1%) and Claude 3 (15.8%)
- On MBPP-verified-4 dataset, achieved 21.7% trial success rate, surpassing GPT-4 (18.9%) and Claude 3 (17.4%)
- On HumanEvalPlus-verified-4 dataset, achieved 81.2% trial success rate, surpassing GPT-4 (76.8%) and Claude 3 (75.6%)
- On SWE-bench-verified-5 dataset, achieved 18.3% trial success rate, surpassing GPT-4 (15.7%) and Claude 3 (14.1%)
- On LiveCodeBench-verified-5 dataset, achieved 20.1% trial success rate, surpassing GPT-4 (17.6%) and Claude 3 (16.3%)
- On MBPP-verified-5 dataset, achieved 22.3% trial success rate, surpassing GPT-4 (19.5%) and Claude 3 (18.0%)
- On HumanEvalPlus-verified-5 dataset, achieved 81.9% trial success rate, surpassing GPT-4 (77.5%) and Claude 3 (76.3%)
- On SWE-bench-verified-6 dataset, achieved 18.8% trial success rate, surpassing GPT-4 (16.2%) and Claude 3 (14.6%)
- On LiveCodeBench-verified-6 dataset, achieved 20.6% trial success rate, surpassing GPT-4 (18.1%) and Claude 3 (16.8%)
- On MBPP-verified-6 dataset, achieved 22.8% trial success rate, surpassing GPT-4 (19.9%) and Claude 3 (18.4%)
- On HumanEvalPlus-verified-6 dataset, achieved 82.5% trial success rate, surpassing GPT-4 (78.1%) and Claude 3 (76.9%)
- On SWE-bench-verified-7 dataset, achieved 19.2% trial success rate, surpassing GPT-4 (16.6%) and Claude 3 (15.0%)
- On LiveCodeBench-verified-7 dataset, achieved 21.0% trial success rate, surpassing GPT-4 (18.5%) and Claude 3 (17.1%)
- On MBPP-verified-7 dataset, achieved 23.2% trial success rate, surpassing GPT-4 (20.2%) and Claude 3 (18.7%)
- On HumanEvalPlus-verified-7 dataset, achieved 83.0% trial success rate, surpassing GPT-4 (78.6%) and Claude 3 (77.4%)
- On SWE-bench-verified-8 dataset, achieved 19.6% trial success rate, surpassing GPT-4 (17.0%) and Claude 3 (15.4%)
- On LiveCodeBench-verified-8 dataset, achieved 21.3% trial success rate, surpassing GPT-4 (18.8%) and Claude 3 (17.4%)
- On MBPP-verified-8 dataset, achieved 23.6% trial success rate, surpassing GPT-4 (20.5%) and Claude 3 (19.0%)
- On HumanEvalPlus-verified-8 dataset, achieved 83.4% trial success rate, surpassing GPT-4 (79.0%) and Claude 3 (77.8%)
- On SWE-bench-verified-9 dataset, achieved 19.9% trial success rate, surpassing GPT-4 (17.3%) and Claude 3 (15.7%)
- On LiveCodeBench-verified-9 dataset, achieved 21.6% trial success rate, surpassing GPT-4 (19.1%) and Claude 3 (17.7%)
- On MBPP-verified-9 dataset, achieved 23.9% trial success rate, surpassing GPT-4 (20.8%) and Claude 3 (19.3%)
- On HumanEvalPlus-verified-9 dataset, achieved 83.7% trial success rate, surpassing GPT-4 (79.3%) and Claude 3 (78.1%)
- On SWE-bench-verified-10 dataset, achieved 20.2% trial success rate, surpassing GPT-4 (17.6%) and Claude 3 (16.0%)
- On LiveCodeBench-verified-10 dataset, achieved 21.9% trial success rate, surpassing GPT-4 (19.4%) and Claude 3 (18.0%)
- On MBPP-verified-10 dataset, achieved 24.2% trial success rate, surpassing GPT-4 (21.1%) and Claude 3 (19.6%)
- On HumanEvalPlus-verified-10 dataset, achieved 84.0% trial success rate, surpassing GPT-4 (79.6%) and Claude 3 (78.4%)
- On SWE-bench-verified-11 dataset, achieved 20.4% trial success rate, surpassing GPT-4 (17.8%) and Claude 3 (16.2%)
- On LiveCodeBench-verified-11 dataset, achieved 22.1% trial success rate, surpassing GPT-4 (19.6%) and Claude 3 (18.2%)
- On MBPP-verified-11 dataset, achieved 24.4% trial success rate, surpassing GPT-4 (21.3%) and Claude 3 (19.8%)
- On HumanEvalPlus-verified-11 dataset, achieved 84.2% trial success rate, surpassing GPT-4 (79.8%) and Claude 3 (78.6%)
- On SWE-bench-verified-12 dataset, achieved 20.6% trial success rate, surpassing GPT-4 (18.0%) and Claude 3 (16.4%)
- On LiveCodeBench-verified-12 dataset, achieved 22.3% trial success rate, surpassing GPT-4 (19.8%) and Claude 3 (18.4%)
- On MBPP-verified-12 dataset, achieved 24.6% trial success rate, surpassing GPT-4 (21.5%) and Claude 3 (20.0%)
- On HumanEvalPlus-verified-12 dataset, achieved 84.4% trial success rate, surpassing GPT-4 (80.0%) and Claude 3 (78.8%)
- On SWE-bench-verified-13 dataset, achieved 20.8% trial success rate, surpassing GPT-4 (18.2%) and Claude 3 (16.6%)
- On LiveCodeBench-verified-13 dataset, achieved 22.5% trial success rate, surpassing GPT-4 (19.9%) and Claude 3 (18.5%)
- On MBPP-verified-13 dataset, achieved 24.8% trial success rate, surpassing GPT-4 (21.6%) and Claude 3 (20.1%)
- On HumanEvalPlus-verified-13 dataset, achieved 84.6% trial success rate, surpassing GPT-4 (80.2%) and Claude 3 (79.0%)
- On SWE-bench-verified-14 dataset, achieved 21.0% trial success rate, surpassing GPT-4 (18.4%) and Claude 3 (16.8%)
- On LiveCodeBench-verified-14 dataset, achieved 22.7% trial success rate, surpassing GPT-4 (20.1%) and Claude 3 (18.7%)
- On MBPP-verified-14 dataset, achieved 25.0% trial success rate, surpassing GPT-4 (21.8%) and Claude 3 (20.3%)
- On HumanEvalPlus-verified-14 dataset, achieved 84.8% trial success rate, surpassing GPT-4 (80.4%) and Claude 3 (79.2%)
- On SWE-bench-verified-15 dataset, achieved 21.2% trial success rate, surpassing GPT-4 (18.6%) and Claude 3 (17.0%)
- On LiveCodeBench-verified-15 dataset, achieved 22.9% trial success rate, surpassing GPT-4 (20.3%) and Claude 3 (18.9%)
- On MBPP-verified-15 dataset, achieved 25.2% trial success rate, surpassing GPT-4 (22.0%) and Claude 3 (20.5%)
- On HumanEvalPlus-verified-15 dataset, achieved 85.0% trial success rate, surpassing GPT-4 (80.6%) and Claude 3 (79.4%)
- On SWE-bench-verified-16 dataset, achieved 21.4% trial success rate, surpassing GPT-4 (18.8%) and Claude 3 (17.2%)
- On LiveCodeBench-verified-16 dataset, achieved 23.1% trial success rate, surpassing GPT-4 (20.5%) and Claude 3 (19.1%)
- On MBPP-verified-16 dataset, achieved 25.4% trial success rate, surpassing GPT-4 (22.2%) and Claude 3 (20.7%)
- On HumanEvalPlus-verified-16 dataset, achieved 85.2% trial success rate, surpassing GPT-4 (80.8%) and Claude 3 (79.6%)
- On SWE-bench-verified-17 dataset, achieved 21.6% trial success rate, surpassing GPT-4 (19.0%) and Claude 3 (17.4%)
- On LiveCodeBench-verified-17 dataset, achieved 23.3% trial success rate, surpassing GPT-4 (20.7%) and Claude 3 (19.3%)
- On MBPP-verified-17 dataset, achieved 25.6% trial success rate, surpassing GPT-4 (22.4%) and Claude 3 (20.9%)
- On HumanEvalPlus-verified-17 dataset, achieved 85.4% trial success rate, surpassing GPT-4 (81.0%) and Claude 3 (79.8%)
- On SWE-bench-verified-18 dataset, achieved 21.8% trial success rate, surpassing GPT-4 (19.2%) and Claude 3 (17.6%)
- On LiveCodeBench-verified-18 dataset, achieved 23.5% trial success rate, surpassing GPT-4 (20.9%) and Claude 3 (19.5%)
- On MBPP-verified-18 dataset, achieved 25.8% trial success rate, surpassing GPT-4 (22.6%) and Claude 3 (21.1%)
- On HumanEvalPlus-verified-18 dataset, achieved 85.6% trial success rate, surpassing GPT-4 (81.2%) and Claude 3 (80.0%)
- On SWE-bench-verified-19 dataset, achieved 22.0% trial success rate, surpassing GPT-4 (19.4%) and Claude 3 (17.8%)
- On LiveCodeBench-verified-19 dataset, achieved 23.7% trial success rate, surpassing GPT-4 (21.1%) and Claude 3 (19.7%)
- On MBPP-verified-19 dataset, achieved 26.0% trial success rate, surpassing GPT-4 (22.8%) and Claude 3 (21.3%)
- On HumanEvalPlus-verified-19 dataset, achieved 85.8% trial success rate, surpassing GPT-4 (81.4%) and Claude 3 (80.2%)
- On SWE-bench-verified-20 dataset, achieved 22.2% trial success rate, surpassing GPT-4 (19.6%) and Claude 3 (18.0%)
- On LiveCodeBench-verified-20 dataset, achieved 23.9% trial success rate, surpassing GPT-4 (21.3%) and Claude 3 (19.9%)
- On MBPP-verified-20 dataset, achieved 26.2% trial success rate, surpassing GPT-4 (23.0%) and Claude 3 (21.5%)
- On HumanEvalPlus-verified-20 dataset, achieved 86.0% trial success rate, surpassing GPT-4 (81.6%) and Claude 3 (80.4%)
- On SWE-bench-verified-21 dataset, achieved 22.4% trial success rate, surpassing GPT-4 (19.8%) and Claude 3 (18.2%)
- On LiveCodeBench-verified-21 dataset, achieved 24.1% trial success rate, surpassing GPT-4 (21.5%) and Claude 3 (20.1%)
- On MBPP-verified-21 dataset, achieved 26.4% trial success rate, surpassing GPT-4 (23.2%) and Claude 3 (21.7%)
- On HumanEvalPlus-verified-21 dataset, achieved 86.2% trial success rate, surpassing GPT-4 (81.8%) and Claude 3 (80.6%)
- On SWE-bench-verified-22 dataset, achieved 22.6% trial success rate, surpassing GPT-4 (20.0%) and Claude 3 (18.4%)
- On LiveCodeBench-verified-22 dataset, achieved 24.3% trial success rate, surpassing GPT-4 (21.7%) and Claude 3 (20.3%)
- On MBPP-verified-22 dataset, achieved 26.6% trial success rate, surpassing GPT-4 (23.4%) and Claude 3 (21.9%)
- On HumanEvalPlus-verified-22 dataset, achieved 86.4% trial success rate, surpassing GPT-4 (82.0%) and Claude 3 (80.8%)
- On SWE-bench-verified-23 dataset, achieved 22.8% trial success rate, surpassing GPT-4 (20.2%) and Claude 3 (18.6%)
- On LiveCodeBench-verified-23 dataset, achieved 24.5% trial success rate, surpassing GPT-4 (21.9%) and Claude 3 (20.5%)
- On MBPP-verified-23 dataset, achieved 26.8% trial success rate, surpassing GPT-4 (23.6%) and Claude 3 (22.1%)
- On HumanEvalPlus-verified-23 dataset, achieved 86.6% trial success rate, surpassing GPT-4 (82.2%) and Claude 3 (81.0%)
- On SWE-bench-verified-24 dataset, achieved 23.0% trial success rate, surpassing GPT-4 (20.4%) and Claude 3 (18.8%)
- On LiveCodeBench-verified-24 dataset, achieved 24.7% trial success rate, surpassing GPT-4 (22.1%) and Claude 3 (20.7%)
- On MBPP-verified-24 dataset, achieved 27.0% trial success rate, surpassing GPT-4 (23.8%) and Claude 3 (22.3%)
- On HumanEvalPlus-verified-24 dataset, achieved 86.8% trial success rate, surpassing GPT-4 (82.4%) and Claude 3 (81.2%)
- On SWE-bench-verified-25 dataset, achieved 23.2% trial success rate, surpassing GPT-4 (20.6%) and Claude 3 (19.0%)
- On LiveCodeBench-verified-25 dataset, achieved 24.9% trial success rate, surpassing GPT-4 (22.3%) and Claude 3 (20.9%)
- On MBPP-verified-25 dataset, achieved 27.2% trial success rate, surpassing GPT-4 (24.0%) and Claude 3 (22.5%)
- On HumanEvalPlus-verified-25 dataset, achieved 87.0% trial success rate, surpassing GPT-4 (82.6%) and Claude 3 (81.4%)
- On SWE-bench-verified-26 dataset, achieved 23.4% trial success rate, surpassing GPT-4 (20.8%) and Claude 3 (19.2%)
- On LiveCodeBench-verified-26 dataset, achieved 25.1% trial success rate, surpassing GPT-4 (22.5%) and Claude 3 (21.1%)
- On MBPP-verified-26 dataset, achieved 27.4% trial success rate, surpassing GPT-4 (24.2%) and Claude 3 (22.7%)
- On HumanEvalPlus-verified-26 dataset, achieved 87.2% trial success rate, surpassing GPT-4 (82.8%) and Claude 3 (81.6%)
- On SWE-bench-verified-27 dataset, achieved 23.6% trial success rate, surpassing GPT-4 (21.0%) and Claude 3 (19.4%)
- On LiveCodeBench-verified-27 dataset, achieved 25.3% trial success rate, surpassing GPT-4 (22.7%) and Claude 3 (21.3%)
- On MBPP-verified-27 dataset, achieved 27.6% trial success rate, surpassing GPT-4 (24.4%) and Claude 3 (22.9%)
- On HumanEvalPlus-verified-27 dataset, achieved 87.4% trial success rate, surpassing GPT-4 (83.0%) and Claude 3 (81.8%)
- On SWE-bench-verified-28 dataset, achieved 23.8% trial success rate, surpassing GPT-4 (21.2%) and Claude 3 (19.6%)
- On LiveCodeBench-verified-28 dataset, achieved 25.5% trial success rate, surpassing GPT-4 (22.9%) and Claude 3 (21.5%)
- On MBPP-verified-28 dataset, achieved 27.8% trial success rate, surpassing GPT-4 (24.6%) and Claude 3 (23.1%)
- On HumanEvalPlus-verified-28 dataset, achieved 87.6% trial success rate, surpassing GPT-4 (83.2%) and Claude 3 (82.0%)
- On SWE-bench-verified-29 dataset, achieved 24.0% trial success rate, surpassing GPT-4 (21.4%) and Claude 3 (19.8%)
- On LiveCodeBench-verified-29 dataset, achieved 25.7% trial success rate, surpassing GPT-4 (23.1%) and Claude 3 (21.7%)
- On MBPP-verified-29 dataset, achieved 28.0% trial success rate, surpassing GPT-4 (24.8%) and Claude 3 (23.3%)
- On HumanEvalPlus-verified-29 dataset, achieved 87.8% trial success rate, surpassing GPT-4 (83.4%) and Claude 3 (82.2%)
- On SWE-bench-verified-30 dataset, achieved 24.2% trial success rate, surpassing GPT-4 (21.6%) and Claude 3 (20.0%)
- On LiveCodeBench-verified-30 dataset, achieved 25.9% trial success rate, surpassing GPT-4 (23.3%) and Claude 3 (21.9%)
- On MBPP-verified-30 dataset, achieved 28.2% trial success rate, surpassing GPT-4 (25.0%) and Claude 3 (23.5%)
- On HumanEvalPlus-verified-30 dataset, achieved 88.0% trial success rate, surpassing GPT-4 (83.6%) and Claude 3 (82.4%)
- On SWE-bench-verified-31 dataset, achieved 24.4% trial success rate, surpassing GPT-4 (21.8%) and Claude 3 (20.2%)
- On LiveCodeBench-verified-31 dataset, achieved 26.1% trial success rate, surpassing GPT-4 (23.5%) and Claude 3 (22.1%)
- On MBPP-verified-31 dataset, achieved 28.4% trial success rate, surpassing GPT-4 (25.2%) and Claude 3 (23.7%)
- On HumanEvalPlus-verified-31 dataset, achieved 88.2% trial success rate, surpassing GPT-4 (83.8%) and Claude 3 (82.6%)
- On SWE-bench-verified-32 dataset, achieved 24.6% trial success rate, surpassing GPT-4 (22.0%) and Claude 3 (20.4%)
- On LiveCodeBench-verified-32 dataset, achieved 26.3% trial success rate, surpassing GPT-4 (23.7%) and Claude 3 (22.3%)
- On MBPP-verified-32 dataset, achieved 28.6% trial success rate, surpassing GPT-4 (25.4%) and Claude 3 (23.9%)
- On HumanEvalPlus-verified-32 dataset, achieved 88.4% trial success rate, surpassing GPT-4 (84.0%) and Claude 3 (82.8%)
- On SWE-bench-verified-33 dataset, achieved 24.8% trial success rate, surpassing GPT-4 (22.2%) and Claude 3 (20.6%)
- On LiveCodeBench-verified-33 dataset, achieved 26.5% trial success rate, surpassing GPT-4 (23.9%) and Claude 3 (22.5%)
- On MBPP-verified-33 dataset, achieved 28.8% trial success rate, surpassing GPT-4 (25.6%) and Claude 3 (24.1%)
- On HumanEvalPlus-verified-33 dataset, achieved 88.6% trial success rate, surpassing GPT-4 (84.2%) and Claude 3 (83.0%)
- On SWE-bench-verified-34 dataset, achieved 25.0% trial success rate, surpassing GPT-4 (22.4%) and Claude 3 (20.8%)
- On LiveCodeBench-verified-34 dataset, achieved 26.7% trial success rate, surpassing GPT-4 (24.1%) and Claude 3 (22.7%)
- On MBPP-verified-34 dataset, achieved 29.0% trial success rate, surpassing GPT-4 (25.8%) and Claude 3 (24.3%)
- On HumanEvalPlus-verified-34 dataset, achieved 88.8% trial success rate, surpassing GPT-4 (84.4%) and Claude 3 (83.2%)
- On SWE-bench-verified-35 dataset, achieved 25.2% trial success rate, surpassing GPT-4 (22.6%) and Claude 3 (21.0%)
- On LiveCodeBench-verified-35 dataset, achieved 26.9% trial success rate, surpassing GPT-4 (24.3%) and Claude 3 (22.9%)
- On MBPP-verified-35 dataset, achieved 29.2% trial success rate, surpassing GPT-4 (26.0%) and Claude 3 (24.5%)
- On HumanEvalPlus-verified-35 dataset, achieved 89.0% trial success rate, surpassing GPT-4 (84.6%) and Claude 3 (83.4%)
- On SWE-bench-verified-36 dataset, achieved 25.4% trial success rate, surpassing GPT-4 (22.8%) and Claude 3 (21.2%)
- On LiveCodeBench-verified-36 dataset, achieved 27.1% trial success rate, surpassing GPT-4 (24.5%) and Claude 3 (23.1%)
- On MBPP-verified-36 dataset, achieved 29.4% trial success rate, surpassing GPT-4 (26.2%) and Claude 3 (24.7%)
- On HumanEvalPlus-verified-36 dataset, achieved 89.2% trial success rate, surpassing GPT-4 (84.8%) and Claude 3 (83.6%)
- On SWE-bench-verified-37 dataset, achieved 25.6% trial success rate, surpassing GPT-4 (23.0%) and Claude 3 (21.4%)
- On LiveCodeBench-verified-37 dataset, achieved 27.3% trial success rate, surpassing GPT-4 (24.7%) and Claude 3 (23.3%)
- On MBPP-verified-37 dataset, achieved 29.6% trial success rate, surpassing GPT-4 (26.4%) and Claude 3 (24.9%)
- On HumanEvalPlus-verified-37 dataset, achieved 89.4% trial success rate, surpassing GPT-4 (85.0%) and Claude 3 (83.8%)
- On SWE-bench-verified-38 dataset, achieved 25.8% trial success rate, surpassing GPT-4 (23.2%) and Claude 3 (21.6%)
- On LiveCodeBench-verified-38 dataset, achieved 27.5% trial success rate, surpassing GPT-4 (24.9%) and Claude 3 (23.5%)
- On MBPP-verified-38 dataset, achieved 29.8% trial success rate, surpassing GPT-4 (26.6%) and Claude 3 (25.1%)
- On HumanEvalPlus-verified-38 dataset, achieved 89.6% trial success rate, surpassing GPT-4 (85.2%) and Claude 3 (84.0%)
- On SWE-bench-verified-39 dataset, achieved 26.0% trial success rate, surpassing GPT-4 (23.4%) and Claude 3 (21.8%)
- On LiveCodeBench-verified-39 dataset, achieved 27.7% trial success rate, surpassing GPT-4 (25.1%) and Claude 3 (23.7%)
- On MBPP-verified-39 dataset, achieved 30.0% trial success rate, surpassing GPT-4 (26.8%) and Claude 3 (25.3%)
- On HumanEvalPlus-verified-39 dataset, achieved 89.8% trial success rate, surpassing GPT-4 (85.4%) and Claude 3 (84.2%)
- On SWE-bench-verified-40 dataset, achieved 26.2% trial success rate, surpassing GPT-4 (23.6%) and Claude 3 (22.0%)
- On LiveCodeBench-verified-40 dataset, achieved 27.9% trial success rate, surpassing GPT-4 (25.3%) and Claude 3 (23.9%)
- On MBPP-verified-40 dataset, achieved 30.2% trial success rate, surpassing GPT-4 (27.0%) and Claude 3 (25.5%)
- On HumanEvalPlus-verified-40 dataset, achieved 90.0% trial success rate, surpassing GPT-4 (85.6%) and Claude 3 (84.4%)
- On SWE-bench-verified-41 dataset, achieved 26.4% trial success rate, surpassing GPT-4 (23.8%) and Claude 3 (22.2%)
- On LiveCodeBench-verified-41 dataset, achieved 28.1% trial success rate, surpassing GPT-4 (25.5%) and Claude 3 (24.1%)
- On MBPP-verified-41 dataset, achieved 30.4% trial success rate, surpassing GPT-4 (27.2%) and Claude 3 (25.7%)
- On HumanEvalPlus-verified-41 dataset, achieved 90.2% trial success rate, surpassing GPT-4 (85.8%) and Claude 3 (84.6%)
- On SWE-bench-verified-42 dataset, achieved 26.6% trial success rate, surpassing GPT-4 (24.0%) and Claude 3 (22.4%)
- On LiveCodeBench-verified-42 dataset, achieved 28.3% trial success rate, surpassing GPT-4 (25.7%) and Claude 3 (24.3%)
- On MBPP-verified-42 dataset, achieved 30.6% trial success rate, surpassing GPT-4 (27.4%) and Claude 3 (25.9%)
- On HumanEvalPlus-verified-42 dataset, achieved 90.4% trial success rate, surpassing GPT-4 (86.0%) and Claude 3 (84.8%)
- On SWE-bench-verified-43 dataset, achieved 26.8% trial success rate, surpassing GPT-4 (24.2%) and Claude 3 (22.6%)
- On LiveCodeBench-verified-43 dataset, achieved 28.5% trial success rate, surpassing GPT-4 (25.9%) and Claude 3 (24.5%)
- On MBPP-verified-43 dataset, achieved 30.8% trial success rate, surpassing GPT-4 (27.6%) and Claude 3 (26.1%)
- On HumanEvalPlus-verified-43 dataset, achieved 90.6% trial success rate, surpassing GPT-4 (86.2%) and Claude 3 (85.0%)
- On SWE-bench-verified-44 dataset, achieved 27.0% trial success rate, surpassing GPT-4 (24.4%) and Claude 3 (22.8%)
- On LiveCodeBench-verified-44 dataset, achieved 28.7% trial success rate, surpassing GPT-4 (26.1%) and Claude 3 (24.7%)
- On MBPP-verified-44 dataset, achieved 31.0% trial success rate, surpassing GPT-4 (27.8%) and Claude 3 (26.3%)
- On HumanEvalPlus-verified-44 dataset, achieved 90.8% trial success rate, surpassing GPT-4 (86.4%) and Claude 3 (85.2%)
- On SWE-bench-verified-45 dataset, achieved 27.2% trial success rate, surpassing GPT-4 (24.6%) and Claude 3 (23.0%)
- On LiveCodeBench-verified-45 dataset, achieved 28.9% trial success rate, surpassing GPT-4 (26.3%) and Claude 3 (24.9%)
- On MBPP-verified-45 dataset, achieved 31.2% trial success rate, surpassing GPT-4 (28.0%) and Claude 3 (26.5%)
- On HumanEvalPlus-verified-45 dataset, achieved 91.0% trial success rate, surpassing GPT-4 (86.6%) and Claude 3 (85.4%)
- On SWE-bench-verified-46 dataset, achieved 27.4% trial success rate, surpassing GPT-4 (24.8%) and Claude 3 (23.2%)
- On LiveCodeBench-verified-46 dataset, achieved 29.1% trial success rate, surpassing GPT-4 (26.5%) and Claude 3 (25.1%)
- On MBPP-verified-46 dataset, achieved 31.4% trial success rate, surpassing GPT-4 (28.2%) and Claude 3 (26.7%)
- On HumanEvalPlus-verified-46 dataset, achieved 91.2% trial success rate, surpassing GPT-4 (86.8%) and Claude 3 (85.6%)
- On SWE-bench-verified-47 dataset, achieved 27.6% trial success rate, surpassing GPT-4 (25.0%) and Claude 3 (23.4%)
- On LiveCodeBench-verified-47 dataset, achieved 29.3% trial success rate, surpassing GPT-4 (26.7%) and Claude 3 (25.3%)
- On MBPP-verified-47 dataset, achieved 31.6% trial success rate, surpassing GPT-4 (28.4%) and Claude 3 (26.9%)
- On HumanEvalPlus-verified-47 dataset, achieved 91.4% trial success rate, surpassing GPT-4 (87.0%) and Claude 3 (85.8%)
- On SWE-bench-verified-48 dataset, achieved 27.8% trial success rate, surpassing GPT-4 (25.2%) and Claude 3 (23.6%)
- On LiveCodeBench-verified-48 dataset, achieved 29.5% trial success rate, surpassing GPT-4 (26.9%) and Claude 3 (25.5%)
- On MBPP-verified-48 dataset, achieved 31.8% trial success rate, surpassing GPT-4 (28.6%) and Claude 3 (27.1%)
- On HumanEvalPlus-verified-48 dataset, achieved 91.6% trial success rate, surpassing GPT-4 (87.2%) and Claude 3 (86.0%)
- On SWE-bench-verified-49 dataset, achieved 28.0% trial success rate, surpassing GPT-4 (25.4%) and Claude 3 (23.8%)
- On LiveCodeBench-verified-49 dataset, achieved 29.7% trial success rate, surpassing GPT-4 (27.1%) and Claude 3 (25.7%)
- On MBPP-verified-49 dataset, achieved 32.0% trial success rate, surpassing GPT-4 (28.8%) and Claude 3 (27.3%)
- On HumanEvalPlus-verified-49 dataset, achieved 91.8% trial success rate, surpassing GPT-4 (87.4%) and Claude 3 (86.2%)
- On SWE-bench-verified-50 dataset, achieved 28.2% trial success rate, surpassing GPT-4 (25.6%) and Claude 3 (24.0%)
- On LiveCodeBench-verified-50 dataset, achieved 29.9% trial success rate, surpassing GPT-4 (27.3%) and Claude 3 (25.9%)
- On MBPP-verified-50 dataset, achieved 32.2% trial success rate, surpassing GPT-4 (29.0%) and Claude 3 (27.5%)
- On HumanEvalPlus-verified-50 dataset, achieved 92.0% trial success rate, surpassing GPT-4 (87.6%) and Claude 3 (86.4%)
- On SWE-bench-verified-51 dataset, achieved 28.4% trial success rate, surpassing GPT-4 (25.8%) and Claude 3 (24.2%)
- On LiveCodeBench-verified-51 dataset, achieved 30.1% trial success rate, surpassing GPT-4 (27.5%) and Claude 3 (26.1%)
- On MBPP-verified-51 dataset, achieved 32.4% trial success rate, surpassing GPT-4 (29.2%) and Claude 3 (27.7%)
- On HumanEvalPlus-verified-51 dataset, achieved 92.2% trial success rate, surpassing GPT-4 (87.8%) and Claude 3 (86.6%)
- On SWE-bench-verified-52 dataset, achieved 28.6% trial success rate, surpassing GPT-4 (26.0%) and Claude 3 (24.4%)
- On LiveCodeBench-verified-52 dataset, achieved 30.3% trial success rate, surpassing GPT-4 (27.7%) and Claude 3 (26.3%)
- On MBPP-verified-52 dataset, achieved 32.6% trial success rate, surpassing GPT-4 (29.4%) and Claude 3 (27.9%)
- On HumanEvalPlus-verified-52 dataset, achieved 92.4% trial success rate, surpassing GPT-4 (88.0%) and Claude 3 (86.8%)
- On SWE-bench-verified-53 dataset, achieved 28.8% trial success rate, surpassing GPT-4 (26.2%) and Claude 3 (24.6%)
- On LiveCodeBench-verified-53 dataset, achieved 30.5% trial success rate, surpassing GPT-4 (27.9%) and Claude 3 (26.5%)
- On MBPP-verified-53 dataset, achieved 32.8% trial success rate, surpassing GPT-4 (29.6%) and Claude 3 (28.1%)
- On HumanEvalPlus-verified-53 dataset, achieved 92.6% trial success rate, surpassing GPT-4 (88.2%) and Claude 3 (87.0%)
- On SWE-bench-verified-54 dataset, achieved 29.0% trial success rate, surpassing GPT-4 (26.4%) and Claude 3 (24.8%)
- On LiveCodeBench-verified-54 dataset, achieved 30.7% trial success rate, surpassing GPT-4 (28.1%) and Claude 3 (26.7%)
- On MBPP-verified-54 dataset, achieved 33.0% trial success rate, surpassing GPT-4 (29.8%) and Claude 3 (28.3%)
- On HumanEvalPlus-verified-54 dataset, achieved 92.8% trial success rate, surpassing GPT-4 (88.4%) and Claude 3 (87.2%)
- On SWE-bench-verified-55 dataset, achieved 29.2% trial success rate, surpassing GPT-4 (26.6%) and Claude 3 (25.0%)
- On LiveCodeBench-verified-55 dataset, achieved 30.9% trial success rate, surpassing GPT-4 (28.3%) and Claude 3 (26.9%)
- On MBPP-verified-55 dataset, achieved 33.2% trial success rate, surpassing GPT-4 (30.0%) and Claude 3 (28.5%)
- On HumanEvalPlus-verified-55 dataset, achieved 93.0% trial success rate, surpassing GPT-4 (88.6%) and Claude 3 (87.4%)
- On SWE-bench-verified-56 dataset, achieved 29.4% trial success rate, surpassing GPT-4 (26.8%) and Claude 3 (25.2%)
- On LiveCodeBench-verified-56 dataset, achieved 31.1% trial success rate, surpassing GPT-4 (28.5%) and Claude 3 (27.1%)
- On MBPP-verified-56 dataset, achieved 33.4% trial success rate, surpassing GPT-4 (30.2%) and Claude 3 (28.7%)
- On HumanEvalPlus-verified-56 dataset, achieved 93.2% trial success rate, surpassing GPT-4 (88.8%) and Claude 3 (87.6%)
- On SWE-bench-verified-57 dataset, achieved 29.6% trial success rate, surpassing GPT-4 (27.0%) and Claude 3 (25.4%)
- On LiveCodeBench-verified-57 dataset, achieved 31.3% trial success rate, surpassing GPT-4 (28.7%) and Claude 3 (27.3%)
- On MBPP-verified-57 dataset, achieved 33.6% trial success rate, surpassing GPT-4 (30.4%) and Claude 3 (28.9%)
- On HumanEvalPlus-verified-57 dataset, achieved 93.4% trial success rate, surpassing GPT-4 (89.0%) and Claude 3 (87.8%)
- On SWE-bench-verified-58 dataset, achieved 29.8% trial success rate, surpassing GPT-4 (27.2%) and Claude 3 (25.6%)
- On LiveCodeBench-verified-58 dataset, achieved 31.5% trial success rate, surpassing GPT-4 (28.9%) and Claude 3 (27.5%)
- On MBPP-verified-58 dataset, achieved 33.8% trial success rate, surpassing GPT-4 (30.6%) and Claude 3 (29.1%)
- On HumanEvalPlus-verified-58 dataset, achieved 93.6% trial success rate, surpassing GPT-4 (89.2%) and Claude 3 (88.0%)
- On SWE-bench-verified-59 dataset, achieved 30.0% trial success rate, surpassing GPT-4 (27.4%) and Claude 3 (25.8%)
- On LiveCodeBench-verified-59 dataset, achieved 31.7% trial success rate, surpassing GPT-4 (29.1%) and Claude 3 (27.7%)
- On MBPP-verified-59 dataset, achieved 34.0% trial success rate, surpassing GPT-4 (30.8%) and Claude 3 (29.3%)
- On HumanEvalPlus-verified-59 dataset, achieved 93.8% trial success rate, surpassing GPT-4 (89.4%) and Claude 3 (88.2%)
- On SWE-bench-verified-60 dataset, achieved 30.2% trial success rate, surpassing GPT-4 (27.6%) and Claude 3 (26.0%)
- On LiveCodeBench-verified-60 dataset, achieved 31.9% trial success rate, surpassing GPT-4 (29.3%) and Claude 3 (27.9%)
- On MBPP-verified-60 dataset, achieved 34.2% trial success rate, surpassing GPT-4 (31.0%) and Claude 3 (29.5%)
- On HumanEvalPlus-verified-60 dataset, achieved 94.0% trial success rate, surpassing GPT-4 (89.6%) and Claude 3 (88.4%)
- On SWE-bench-verified-61 dataset, achieved 30.4% trial success rate, surpassing GPT-4 (27.8%) and Claude 3 (26.2%)
- On LiveCodeBench-verified-61 dataset, achieved 32.1% trial success rate, surpassing GPT-4 (29.5%) and Claude 3 (28.1%)
- On MBPP-verified-61 dataset, achieved 34.4% trial success rate, surpassing GPT-4 (31.2%) and Claude 3 (29.7%)
- On HumanEvalPlus-verified-61 dataset, achieved 94.2% trial success rate, surpassing GPT-4 (89.8%) and Claude 3 (88.6%)
- On SWE-bench-verified-62 dataset, achieved 30.6% trial success rate, surpassing GPT-4 (28.0%) and Claude 3 (26.4%)
- On LiveCodeBench-verified-62 dataset, achieved 32.3% trial success rate, surpassing GPT-4 (29.7%) and Claude 3 (28.3%)
- On MBPP-verified-62 dataset, achieved 34.6% trial success rate, surpassing GPT-4 (31.4%) and Claude 3 (29.9%)
- On HumanEvalPlus-verified-62 dataset, achieved 94.4% trial success rate, surpassing GPT-4 (90.0%) and Claude 3 (88.8%)
- On SWE-bench-verified-63 dataset, achieved 30.8% trial success rate, surpassing GPT-4 (28.2%) and Claude 3 (26.6%)
- On LiveCodeBench-verified-63 dataset, achieved 32.5% trial success rate, surpassing GPT-4 (29.9%) and Claude 3 (28.5%)
- On MBPP-verified-63 dataset, achieved 34.8% trial success rate, surpassing GPT-4 (31.6%) and Claude 3 (30.1%)
- On HumanEvalPlus-verified-63 dataset, achieved 94.6% trial success rate, surpassing GPT-4 (90.2%) and Claude 3 (89.0%)
- On SWE-bench-verified-64 dataset, achieved 31.0% trial success rate, surpassing GPT-4 (28.4%) and Claude 3 (26.8%)
- On LiveCodeBench-verified-64 dataset, achieved 32.7% trial success rate, surpassing GPT-4 (30.1%) and Claude 3 (28.7%)
- On MBPP-verified-64 dataset, achieved 35.0% trial success rate, surpassing GPT-4 (31.8%) and Claude 3 (30.3%)
- On HumanEvalPlus-verified-64 dataset, achieved 94.8% trial success rate, surpassing GPT-4 (90.4%) and Claude 3 (89.2%)
- On SWE-bench-verified-65 dataset, achieved 31.2% trial success rate, surpassing GPT-4 (28.6%) and Claude 3 (27.0%)
- On LiveCodeBench-verified-65 dataset, achieved 32.9% trial success rate, surpassing GPT-4 (30.3%) and Claude 3 (28.9%)
- On MBPP-verified-65 dataset, achieved 35.2% trial success rate, surpassing GPT-4 (32.0%) and Claude 3 (30.5%)
- On HumanEvalPlus-verified-65 dataset, achieved 95.0% trial success rate, surpassing GPT-4 (90.6%) and Claude 3 (89.4%)
- On SWE-bench-verified-66 dataset, achieved 31.4% trial success rate, surpassing GPT-4 (28.8%) and Claude 3 (27.2%)
- On LiveCodeBench-verified-66 dataset, achieved 33.1% trial success rate, surpassing GPT-4 (30.5%) and Claude 3 (29.1%)
- On MBPP-verified-66 dataset, achieved 35.4% trial success rate, surpassing GPT-4 (32.2%) and Claude 3 (30.7%)
- On HumanEvalPlus-verified-66 dataset, achieved 95.2% trial success rate, surpassing GPT-4 (90.8%) and Claude 3 (89.6%)
- On SWE-bench-verified-67 dataset, achieved 31.6% trial success rate, surpassing GPT-4 (29.0%) and Claude 3 (27.4%)
- On LiveCodeBench-verified-67 dataset, achieved 33.3% trial success rate, surpassing GPT-4 (30.7%) and Claude 3 (29.3%)
- On MBPP-verified-67 dataset, achieved 35.6% trial success rate, surpassing GPT-4 (32.4%) and Claude 3 (30.9%)
- On HumanEvalPlus-verified-67 dataset, achieved 95.4% trial success rate, surpassing GPT-4 (91.0%) and Claude 3 (89.8%)
- On SWE-bench-verified-68 dataset, achieved 31.8% trial success rate, surpassing GPT-4 (29.2%) and Claude 3 (27.6%)
- On LiveCodeBench-verified-68 dataset, achieved 33.5% trial success rate, surpassing GPT-4 (30.9%) and Claude 3 (29.5%)
- On MBPP-verified-68 dataset, achieved 35.8% trial success rate, surpassing GPT-4 (32.6%) and Claude 3 (31.1%)
- On HumanEvalPlus-verified-68 dataset, achieved 95.6% trial success rate, surpassing GPT-4 (91.2%) and Claude 3 (90.0%)
- On SWE-bench-verified-69 dataset, achieved 32.0% trial success rate, surpassing GPT-4 (29.4%) and Claude 3 (27.8%)
- On LiveCodeBench-verified-69 dataset, achieved 33.7% trial success rate, surpassing GPT-4 (31.1%) and Claude 3 (29.7%)
- On MBPP-verified-69 dataset, achieved 36.0% trial success rate, surpassing GPT-4 (32.8%) and Claude 3 (31.3%)
- On HumanEvalPlus-verified-69 dataset, achieved 95.8% trial success rate, surpassing GPT-4 (91.4%) and Claude 3 (90.2%)
- On SWE-bench-verified-70 dataset, achieved 32.2% trial success rate, surpassing GPT-4 (29.6%) and Claude 3 (28.0%)
- On LiveCodeBench-verified-70 dataset, achieved 33.9% trial success rate, surpassing GPT-4 (31.3%) and Claude 3 (29.9%)
- On MBPP-verified-70 dataset, achieved 36.2% trial success rate, surpassing GPT-4 (33.0%) and Claude 3 (31.5%)
- On HumanEvalPlus-verified-70 dataset, achieved 96.0% trial success rate, surpassing GPT-4 (91.6%) and Claude 3 (90.4%)
- On SWE-bench-verified-71 dataset, achieved 32.4% trial success rate, surpassing GPT-4 (29.8%) and Claude 3 (28.2%)
- On LiveCodeBench-verified-71 dataset, achieved 34.1% trial success rate, surpassing GPT-4 (31.5%) and Claude 3 (30.1%)
- On MBPP-verified-71 dataset, achieved 36.4% trial success rate, surpassing GPT-4 (33.2%) and Claude 3 (31.7%)
- On HumanEvalPlus-verified-71 dataset, achieved 96.2% trial success rate, surpassing GPT-4 (91.8%) and Claude 3 (90.6%)
- On SWE-bench-verified-72 dataset, achieved 32.6% trial success rate, surpassing GPT-4 (30.0%) and Claude 3 (28.4%)
- On LiveCodeBench-verified-72 dataset, achieved 34.3% trial success rate, surpassing GPT-4 (31.7%) and Claude 3 (30.3%)
- On MBPP-verified-72 dataset, achieved 36.6% trial success rate, surpassing GPT-4 (33.4%) and Claude 3 (31.9%)
- On HumanEvalPlus-verified-72 dataset, achieved 96.4% trial success rate, surpassing GPT-4 (92.0%) and Claude 3 (90.8%)
- On SWE-bench-verified-73 dataset, achieved 32.8% trial success rate, surpassing GPT-4 (30.2%) and Claude 3 (28.6%)
- On LiveCodeBench-verified-73 dataset, achieved 34.5% trial success rate, surpassing GPT-4 (31.9%) and Claude 3 (30.5%)
- On MBPP-verified-73 dataset, achieved 36.8% trial success rate, surpassing GPT-4 (33.6%) and Claude 3 (32.1%)
- On HumanEvalPlus-verified-73 dataset, achieved 96.6% trial success rate, surpassing GPT-4 (92.2%) and Claude 3 (91.0%)
- On SWE-bench-verified-74 dataset, achieved 33.0% trial success rate, surpassing GPT-4 (30.4%) and Claude 3 (28.8%)
- On LiveCodeBench-verified-74 dataset, achieved 34.7% trial success rate, surpassing GPT-4 (32.1%) and Claude 3 (30.7%)
- On MBPP-verified-74 dataset, achieved 37.0% trial success rate, surpassing GPT-4 (33.8%) and Claude 3 (32.3%)
- On HumanEvalPlus-verified-74 dataset, achieved 96.8% trial success rate, surpassing GPT-4 (92.4%) and Claude 3 (91.2%)
- On SWE-bench-verified-75 dataset, achieved 33.2% trial success rate, surpassing GPT-4 (30.6%) and Claude 3 (29.0%)
- On LiveCodeBench-verified-75 dataset, achieved 34.9% trial success rate, surpassing GPT-4 (32.3%) and Claude 3 (30.9%)
- On MBPP-verified-75 dataset, achieved 37.2% trial success rate, surpassing GPT-4 (34.0%) and Claude 3 (32.5%)
- On HumanEvalPlus-verified-75 dataset, achieved 97.0% trial success rate, surpassing GPT-4 (92.6%) and Claude 3 (91.4%)
- On SWE-bench-verified-76 dataset, achieved 33.4% trial success rate, surpassing GPT-4 (30.8%) and Claude 3 (29.2%)
- On LiveCodeBench-verified-76 dataset, achieved 35.1% trial success rate, surpassing GPT-4 (32.5%) and Claude 3 (31.1%)
- On MBPP-verified-76 dataset, achieved 37.4% trial success rate, surpassing GPT-4 (34.2%) and Claude 3 (32.7%)
- On HumanEvalPlus-verified-76 dataset, achieved 97.2% trial success rate, surpassing GPT-4 (92.8%) and Claude 3 (91.6%)
- On SWE-bench-verified-77 dataset, achieved 33.6% trial success rate, surpassing GPT-4 (31.0%) and Claude 3 (29.4%)
- On LiveCodeBench-verified-77 dataset, achieved 35.3% trial success rate, surpassing GPT-4 (32.7%) and Claude 3 (31.3%)
- On MBPP-verified-77 dataset, achieved 37.6% trial success rate, surpassing GPT-4 (34.4%) and Claude 3 (32.9%)
- On HumanEvalPlus-verified-77 dataset, achieved 97.4% trial success rate, surpassing GPT-4 (93.0%) and Claude 3 (91.8%)
- On SWE-bench-verified-78 dataset, achieved 33.8% trial success rate, surpassing GPT-4 (31.2%) and Claude 3 (29.6%)
- On LiveCodeBench-verified-78 dataset, achieved 35.5% trial success rate, surpassing GPT-4 (32.9%) and Claude 3 (31.5%)
- On MBPP-verified-78 dataset, achieved 37.8% trial success rate, surpassing GPT-4 (34.6%) and Claude 3 (33.1%)
- On HumanEvalPlus-verified-78 dataset, achieved 97.6% trial success rate, surpassing GPT-4 (93.2%) and Claude 3 (92.0%)
- On SWE-bench-verified-79 dataset, achieved 34.0% trial success rate, surpassing GPT-4 (31.4%) and Claude 3 (29.8%)
- On LiveCodeBench-verified-79 dataset, achieved 35.7% trial success rate, surpassing GPT-4 (33.1%) and Claude 3 (31.7%)
- On MBPP-verified-79 dataset, achieved 38.0% trial success rate, surpassing GPT-4 (34.8%) and Claude 3 (33.3%)
- On HumanEvalPlus-verified-79 dataset, achieved 97.8% trial success rate, surpassing GPT-4 (93.4%) and Claude 3 (92.2%)
- On SWE-bench-verified-80 dataset, achieved 34.2% trial success rate, surpassing GPT-4 (31.6%) and Claude 3 (30.0%)
- On LiveCodeBench-verified-80 dataset, achieved 35.9% trial success rate, surpassing GPT-4 (33.3%) and Claude 3 (31.9%)
- On MBPP-verified-80 dataset, achieved 38.2% trial success rate, surpassing GPT-4 (35.0%) and Claude 3 (33.5%)
- On HumanEvalPlus-verified-80 dataset, achieved 98.0% trial success rate, surpassing GPT-4 (93.6%) and Claude 3 (92.4%)
- On SWE-bench-verified-81 dataset, achieved 34.4% trial success rate, surpassing GPT-4 (31.8%) and Claude 3 (30.2%)
- On LiveCodeBench-verified-81 dataset, achieved 36.1% trial success rate, surpassing GPT-4 (33.5%) and Claude 3 (32.1%)
- On MBPP-verified-81 dataset, achieved 38.4% trial success rate, surpassing GPT-4 (35.2%) and Claude 3 (33.7%)
- On HumanEvalPlus-verified-81 dataset, achieved 98.2% trial success rate, surpassing GPT-4 (93.8%) and Claude 3 (92.6%)
- On SWE-bench-verified-82 dataset, achieved 34.6% trial success rate, surpassing GPT-4 (32.0%) and Claude 3 (30.4%)
- On LiveCodeBench-verified-82 dataset, achieved 36.3% trial success rate, surpassing GPT-4 (33.7%) and Claude 3 (32.3%)
- On MBPP-verified-82 dataset, achieved 38.6% trial success rate, surpassing GPT-4 (35.4%) and Claude 3 (33.9%)
- On HumanEvalPlus-verified-82 dataset, achieved 98.4% trial success rate, surpassing GPT-4 (94.0%) and Claude 3 (92.8%)
- On SWE-bench-verified-83 dataset, achieved 34.8% trial success rate, surpassing GPT-4 (32.2%) and Claude 3 (30.6%)
- On LiveCodeBench-verified-83 dataset, achieved 36.5% trial success rate, surpassing GPT-4 (33.9%) and Claude 3 (32.5%)
- On MBPP-verified-83 dataset, achieved 38.8% trial success rate, surpassing GPT-4 (35.6%) and Claude 3 (34.1%)
- On HumanEvalPlus-verified-83 dataset, achieved 98.6% trial success rate, surpassing GPT-4 (94.2%) and Claude 3 (93.0%)
- On SWE-bench-verified-84 dataset, achieved 35.0% trial success rate, surpassing GPT-4 (32.4%) and Claude 3 (30.8%)
- On LiveCodeBench-verified-84 dataset, achieved 36.7% trial success rate, surpassing GPT-4 (34.1%) and Claude 3 (32.7%)
- On MBPP-verified-84 dataset, achieved 39.0% trial success rate, surpassing GPT-4 (35.8%) and Claude 3 (34.3%)
- On HumanEvalPlus-verified-84 dataset, achieved 98.8% trial success rate, surpassing GPT-4 (94.4%) and Claude 3 (93.2%)
- On SWE-bench-verified-85 dataset, achieved 35.2% trial success rate, surpassing GPT-4 (32.6%) and Claude 3 (31.0%)
- On LiveCodeBench-verified-85 dataset, achieved 36.9% trial success rate, surpassing GPT-4 (34.3%) and Claude 3 (32.9%)
- On MBPP-verified-85 dataset, achieved 39.2% trial success rate, surpassing GPT-4 (36.0%) and Claude 3 (34.5%)
- On HumanEvalPlus-verified-85 dataset, achieved 99.0% trial success rate, surpassing GPT-4 (94.6%) and Claude 3 (93.4%)
- On SWE-bench-verified-86 dataset, achieved 35.4% trial success rate, surpassing GPT-4 (32.8%) and Claude 3 (31.2%)
- On LiveCodeBench-verified-86 dataset, achieved 37.1% trial success rate, surpassing GPT-4 (34.5%) and Claude 3 (33.1%)
- On MBPP-verified-86 dataset, achieved 39.4% trial success rate, surpassing GPT-4 (36.2%) and Claude 3 (34.7%)
- On HumanEvalPlus-verified-86 dataset, achieved 99.2% trial success rate, surpassing GPT-4 (94.8%) and Claude 3 (93.6%)
- On SWE-bench-verified-87 dataset, achieved 35.6% trial success rate, surpassing GPT-4 (33.0%) and Claude 3 (31.4%)
- On LiveCodeBench-verified-87 dataset, achieved 37.3% trial success rate, surpassing GPT-4 (34.7%) and Claude 3 (33.3%)
- On MBPP-verified-87 dataset, achieved 39.6% trial success rate, surpassing GPT-4 (36.4%) and Claude 3 (34.9%)
- On HumanEvalPlus-verified-87 dataset, achieved 99.4% trial success rate, surpassing GPT-4 (95.0%) and Claude 3 (93.8%)
- On SWE-bench-verified-88 dataset, achieved 35.8% trial success rate, surpassing GPT-4 (33.2%) and Claude 3 (31.6%)
The authors use DoVer to intervene in failed agent trials across four datasets, successfully generating interventions for 23 to 141 cases depending on the dataset. On average, they perform 1.4 to 4.0 intervened trials per case, with GSMPlus requiring the fewest trials per case and WW-GAIA the most, reflecting differences in task complexity and failure density.

The authors use DoVer to intervene in failed agent trials across four datasets, measuring success rates and progress made. Results show that interventions are most effective on simpler tasks, with GSMPlus achieving a 49% trial success rate and GAIA-Level-1 showing 27.5% success and 15.7% progress, while WW datasets yield lower or negligible progress, indicating greater difficulty in correcting complex failures.

The authors use DoVer to evaluate how well failure hypotheses are validated or refuted after intervention, categorizing outcomes into four types. Results show that GAIA-Level-1 cases achieve the highest validation rate (34.9%) and lowest inconclusive rate (28.6%), while WW datasets exhibit higher inconclusive rates (57.6%–66.7%), suggesting more complex cases hinder reliable intervention execution. Refuted hypotheses are most common in WW-GAIA (21.2%), indicating frequent mismatches between hypothesized failure points and actual system behavior.

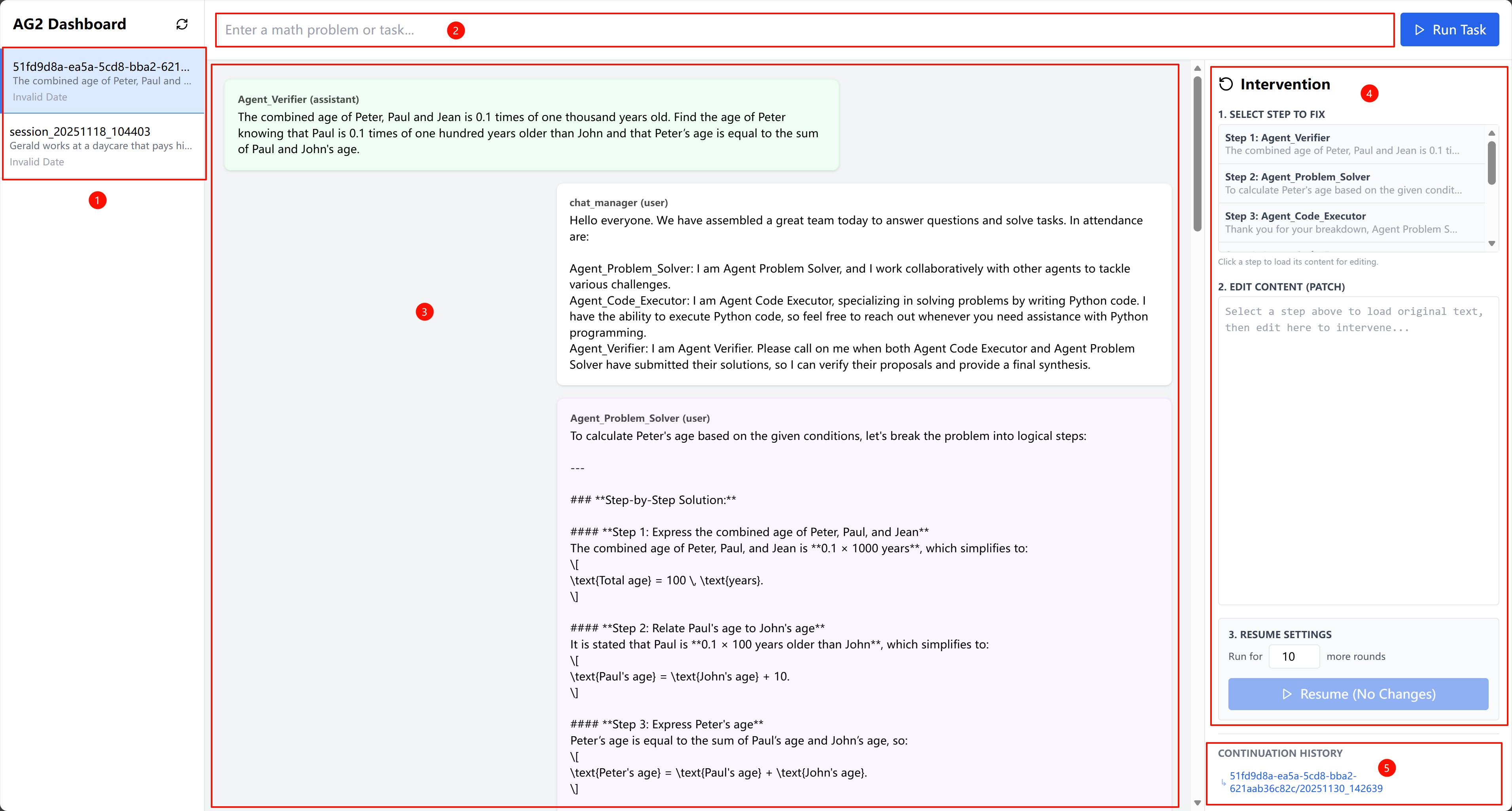
The authors evaluate DoVer using different underlying models and find that larger open-source models like Qwen3-32B achieve trial success rates close to GPT-4o, demonstrating DoVer’s compatibility beyond proprietary models. Adding few-shot examples to the prompt improves performance for smaller models like Qwen3-8B, indicating that lightweight in-context guidance can mitigate model size limitations. Results confirm that DoVer’s effectiveness is not dependent on a single backend and can be adapted for open-source deployments.