Command Palette
Search for a command to run...
PrismAudio: Zerlegtes Chain-of-Thought und mehrdimensionale Belohnungen für die Video-zu-Audio-Generierung
PrismAudio: Zerlegtes Chain-of-Thought und mehrdimensionale Belohnungen für die Video-zu-Audio-Generierung
Huadai Liu Kaicheng Luo Wen Wang Qian Chen Peiwen Sun Rongjie Huang Xiangang Li Jieping Ye Wei Xue
Zusammenfassung
Die Generierung von Video-zu-Audio (V2A) erfordert eine sorgfältige Abwägung von vier kritischen perceptuellen Dimensionen: semantische Konsistenz, audiovisuelle zeitliche Synchronität, ästhetische Qualität und räumliche Genauigkeit. Bestehende Methoden leiden jedoch unter einer objektiven Entanglement, die konkurrierende Ziele in einzelnen Loss-Funktionen vermischt, und weisen zudem eine mangelnde Ausrichtung auf menschliche Präferenzen auf. Wir stellen PrismAudio vor, das erste Framework, das Reinforcement Learning in die V2A-Generierung integriert und dabei spezialisierte Chain-of-Thought (CoT)-Planung einsetzt. Unser Ansatz zerlegt monolithisches Reasoning in vier spezialisierte CoT-Module (Semantic CoT, Temporal CoT, Aesthetic CoT und Spatial CoT), die jeweils mit gezielten Reward-Funktionen gekoppelt sind. Diese Korrespondenz zwischen CoT und Reward ermöglicht eine multidimensionale RL-Optimierung, die das Modell anleitet, über alle Perspektiven hinweg gemeinsam verbessertes Reasoning zu generieren. Damit wird das Problem der objektiven Entanglement gelöst, während die Interpretierbarkeit erhalten bleibt. Um diese Optimierung rechnerisch praktikabel zu gestalten, schlagen wir Fast-GRPO vor, das eine hybride ODE-SDE-Sampling-Methode verwendet und den Trainingsaufwand im Vergleich zu bestehenden GRPO-Implementierungen erheblich reduziert. Zudem führen wir AudioCanvas ein, ein rigoroses Benchmark, das im Vergleich zu bestehenden Datensätzen eine ausgeglichenere Verteilung aufweist und realistischere, vielfältigere sowie anspruchsvollere Szenarien abdeckt; es umfasst 300 Klassen für einzelne Ereignisse sowie 501 Stichproben für mehrere Ereignisse. Experimentelle Ergebnisse zeigen, dass PrismAudio auf dem in-domain VGGSound-Testset sowie auf dem out-of-domain AudioCanvas-Benchmark in allen vier perceptuellen Dimensionen State-of-the-Art-Leistung erzielt.
One-sentence Summary
Researchers from HKUST, Alibaba Group, and CUHK introduce PrismAudio, the first framework to integrate reinforcement learning into video-to-audio generation via specialized chain-of-thought planning that decomposes reasoning into semantic, temporal, aesthetic, and spatial modules paired with targeted rewards to resolve objective entanglement while preserving interpretability, alongside Fast-GRPO for reduced training overhead and the AudioCanvas benchmark with 300 single-event classes and 501 multi-event samples.
Key Contributions
- We introduce PrismAudio, the first framework to integrate Reinforcement Learning into video-to-audio generation with specialized Chain-of-Thought planning. This approach decomposes reasoning into four specialized CoT modules paired with targeted reward functions to address objective entanglement while preserving interpretability.
- To ensure computational practicality, we propose Fast-GRPO, an optimization method employing hybrid ODE-SDE sampling. This technique dramatically reduces training overhead compared to existing GRPO implementations.
- We also introduce AudioCanvas, a rigorous benchmark that is more distributionally balanced and covers more realistically diverse and challenging scenarios than existing datasets. It includes 300 single-event classes and 501 multi-event samples to support evaluation.
Introduction
Video-to-Audio generation requires balancing semantic consistency, temporal synchrony, aesthetic quality, and spatial accuracy to synthesize soundscapes from silent videos. Existing methods suffer from objective entanglement where competing goals are conflated in single loss functions, and they lack human preference alignment. Recent Chain-of-Thought approaches further fail due to monolithic planning that cannot address distinct perceptual dimensions independently. The authors introduce PrismAudio, which integrates Reinforcement Learning with specialized Chain-of-Thought modules for each perceptual axis. This decomposition enables multi-dimensional RL optimization to guide reasoning across all perspectives while preserving interpretability. To reduce training overhead, they propose Fast-GRPO using hybrid ODE-SDE sampling. Additionally, the team presents AudioCanvas, a rigorous benchmark for diverse scenarios, achieving state-of-the-art performance across all dimensions.
Dataset
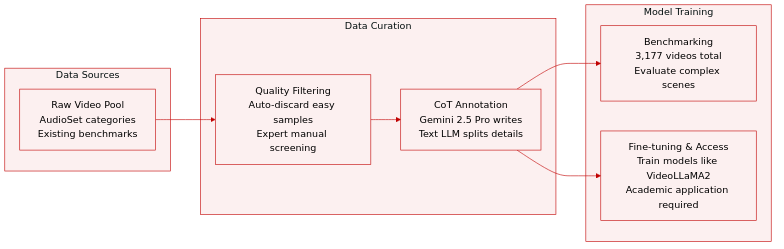
- The authors construct AudioCanvas using 300 distinct categories from the AudioSet ontology, focusing on sound effects and music while excluding human speech and singing.
- The final benchmark comprises 3,177 high-quality videos, including a curated subset of 501 multi-event videos designed to evaluate complex scene interactions.
- Filtering protocols automatically discard samples where existing V2A models achieve near-perfect scores, while professional experts manually screen for diversity and audio-visual correlation.
- Gemini 2.5 Pro generates structured Chain-of-Thought captions covering semantic, temporal, aesthetic, and spatial dimensions, which are subsequently decoupled into separate modules by a text LLM.
- The dataset supports both advanced benchmarking and fine-tuning for models like VideoLLaMA2, with access restricted to academic researchers via a formal application process.
- Privacy and ethical standards are maintained by providing reference links instead of raw video redistribution and using anonymized identifiers for all content.
Method
The proposed method, PrismAudio, operates through a three-stage pipeline comprising a CoT-aware audio foundation model, customized CoT modules for reasoning decomposition, and a GRPO post-training framework. The overall architecture integrates these components to enable high-quality video-to-audio generation with multi-dimensional reasoning capabilities.
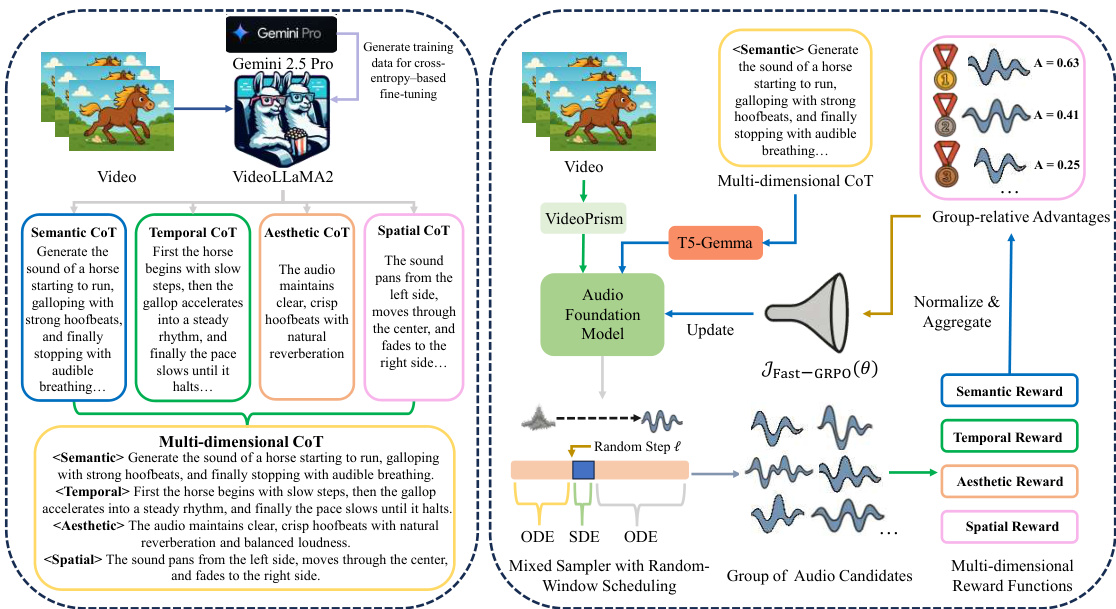
CoT-Aware Audio Foundation Model The core generation model is built upon a diffusion transformer backbone utilizing flow matching. To overcome the limitations of existing models in handling complex video scenarios and structured reasoning text, the authors implement two key architectural enhancements. First, they replace standard CLIP-based encoders with VideoPrism, a state-of-the-art video encoder designed to capture rich semantic representations of objects, actions, and environmental contexts. Second, to effectively condition the model on the structured reasoning patterns required for multi-dimensional CoT, the standard T5 encoder is upgraded to T5-Gemma. This encoder-decoder architecture adapts the reasoning capabilities of decoder-only LLMs, enabling robust comprehension of the analytical text generated by the CoT modules.
Decomposing Multi-dimensional CoT Reasoning To address the limitations of monolithic reasoning paths, the method decomposes video-to-audio reasoning into four specialized dimensions: Semantic, Temporal, Aesthetic, and Spatial. The Semantic CoT identifies audio events and characteristics, while the Temporal CoT determines the sequential ordering of these events. The Aesthetic CoT focuses on quality aspects like naturalness and fidelity, and the Spatial CoT analyzes sound positioning and distance. High-quality training data for these dimensions is constructed using Gemini 2.5 Pro. This data is then used to fine-tune VideoLLaMA2, enabling it to generate the four specialized CoTs. These distinct reasoning texts are concatenated to form a multi-dimensional CoT, which serves as enhanced structured text conditioning for the audio foundation model.
Fast-GRPO Post-Training Framework The final stage aligns the audio foundation model with multi-dimensional human preferences using a Fast-GRPO framework. This process involves four specialized reward functions corresponding to the CoT dimensions: Semantic Reward (measured by MS-CLAP), Temporal Reward (assessed via Synchformer), Aesthetic Reward (using Meta Audiobox Aesthetics), and Spatial Reward (employing StereoCRW). To optimize efficiently across these objectives, the authors introduce a mixed sampler with random-window scheduling. While the flow matching generation is inherently deterministic (an ODE), it is reformulated as a stochastic process (an SDE) to enable RL-based optimization. The Fast-GRPO algorithm strategically confines stochasticity to a small, randomly placed window of timesteps within the generation trajectory. For each training iteration, a starting position ℓ is sampled to define an optimization window W(ℓ) with width w≪T:
W(ℓ)={ℓ,ℓ+1,…,ℓ+w−1}.The generation process interleaves deterministic ODE steps and stochastic SDE steps based on this window. For a step size Δt, the update rule is:
xt+1={xt+vθ(xt,t,c)Δt,xt+μSDE(xt,t,c)Δt+σtΔtεt,if t∈/W(ℓ)(ODE step)if t∈W(ℓ)(SDE step)where εt∼N(0,I) and vθ is the model's predicted velocity. This hybrid approach allows for tractable policy ratio computation and reduces the Number of Function Evaluations (NFE) per sample, enabling near-linear complexity training. The policy model is optimized by maximizing the following objective, derived from the Fast-GRPO formulation restricted to the selected SDE steps:
JFast−GRPO(θ) = Ec,ℓ,{xi}∼πθoldN1i=1∑Nw1t∈W(ℓ)∑min(rti(θ)Ai,clip(rti(θ),1−ε,1+ε)Ai).where Ai is the group-normalized advantage computed from the weighted sum of the multi-dimensional rewards.
Experiment
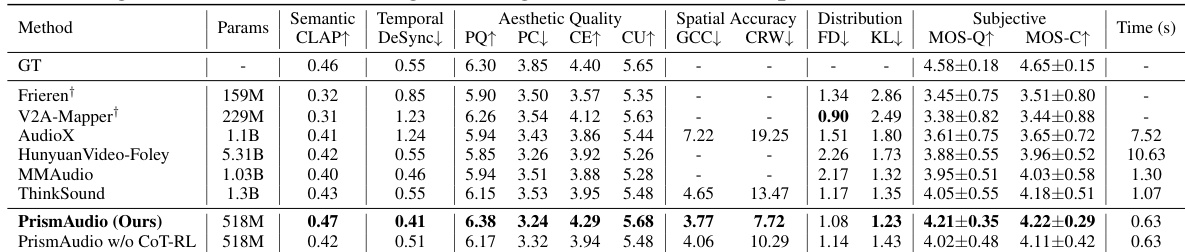
The study evaluates performance on the VGGSound test set and the newly introduced AudioCanvas benchmark using comprehensive objective metrics and subjective Mean Opinion Scores to assess semantic, temporal, spatial, and aesthetic dimensions. Results demonstrate that PrismAudio achieves state-of-the-art performance by employing a multi-dimensional Chain-of-Thought reinforcement learning framework that effectively balances competing perceptual objectives, while ablation analyses confirm that structured decomposed reasoning is essential for maintaining robustness in complex scenarios. Qualitative comparisons further highlight the model's superior ability to preserve high-frequency details and accurate transient responses compared to existing methods.
The the the table compares various Chain-of-Thought reasoning strategies, ranging from a baseline without reasoning to the proposed multi-dimensional approach. Results demonstrate that structured, decomposed reasoning significantly improves performance across semantic, temporal, and aesthetic metrics compared to unstructured or single-block methods. The MultiCoT method achieves the best overall scores, validating the necessity of logical planning for high-quality generation. MultiCoT achieves the highest semantic alignment and temporal synchrony scores Structured reasoning strategies outperform random or unstructured approaches Decomposed reasoning yields better aesthetic quality than monolithic methods

The authors evaluate the proposed method against competitive baselines on the VGGSound test set. Results show that PrismAudio achieves superior performance across semantic, temporal, and aesthetic dimensions compared to prior models. The ablation study further indicates that the CoT-RL framework provides substantial improvements over the foundation model. PrismAudio secures the highest subjective scores for audio quality and consistency. The proposed method outperforms baselines in spatial accuracy and temporal synchrony. CoT-RL optimization delivers significant performance gains over the base foundation model.
The experiment evaluates the impact of different Chain-of-Thought reasoning structures on audio generation quality. Results demonstrate that structured, decomposed reasoning significantly outperforms unstructured or monolithic approaches across semantic, temporal, and aesthetic dimensions. MultiCoT outperforms monolithic CoT in semantic understanding and aesthetic quality Baseline models without CoT reasoning perform poorly across all evaluation metrics Structured logical plans are essential for high-quality generation compared to random keyword ordering

The authors evaluate video encoders on a retrieval task using the AudioCanvas benchmark. VideoPrism achieves significantly higher recall scores compared to CLIP and X-CLIP across all scene complexities. The performance gap is particularly large in multi-event scenarios, highlighting VideoPrism's robustness. VideoPrism achieves the highest recall scores across all scene categories Performance advantage is most significant in complex multi-event scenes VideoPrism maintains robust retrieval accuracy while baselines degrade

The authors compare text encoders to validate their ability to handle structured reasoning. T5-Gemma consistently achieves better results than T5-Base and T5-Large across sequential understanding and causal logic metrics. These findings support the selection of instruction-tuned models for processing complex Chain-of-Thought descriptions. T5-Gemma achieves the highest scores in sequential understanding tasks. Causal reasoning capabilities are significantly stronger with T5-Gemma. Multi-step reasoning accuracy remains high for T5-Gemma compared to baselines.

The experiments validate the proposed framework by comparing it against baselines across audio generation, video retrieval, and text encoding tasks. Results indicate that structured, multi-dimensional Chain-of-Thought reasoning and CoT-RL optimization significantly enhance semantic alignment and temporal synchrony compared to unstructured approaches. Additionally, components like VideoPrism and T5-Gemma demonstrate superior robustness in complex scene retrieval and causal logic, confirming the necessity of instruction-tuned models for high-quality generation.