Command Palette
Search for a command to run...
LongCat-Video Technischer Bericht
LongCat-Video Technischer Bericht
Zusammenfassung
Die Videoerzeugung ist ein entscheidender Weg zu Weltmodellen, wobei eine effiziente Generierung langer Videos eine zentrale Fähigkeit darstellt. In diesem Zusammenhang stellen wir LongCat-Video vor, ein grundlegendes Videoerzeugungsmodell mit 13,6 Milliarden Parametern, das sich durch herausragende Leistung in mehreren Videoerzeugungsaufgaben auszeichnet. Insbesondere überzeugt es bei der effizienten und hochwertigen Erzeugung langer Videos und markiert damit unseren ersten Schritt hin zu Weltmodellen. Zu den zentralen Merkmalen gehören:Einheitlicher Architekturansatz für mehrere Aufgaben: Aufbauend auf dem Diffusion Transformer (DiT)-Framework unterstützt LongCat-Video mit einem einzigen Modell die Aufgaben Text-zu-Video, Bild-zu-Video sowie Video-Continuation (Fortsetzung von Videos);Erzeugung langer Videos: Durch die Vortrainierung auf Aufgaben der Video-Continuation ist LongCat-Video in der Lage, Videos von mehreren Minuten Länge mit hoher Qualität und zeitlicher Kohärenz zu generieren;Effiziente Inferenz: LongCat-Video erzeugt Videos in 720p und 30 fps innerhalb weniger Minuten, indem es eine grob-zu-fein-Generierungsstrategie entlang sowohl der zeitlichen als auch der räumlichen Achse nutzt. Die Block-Sparse-Attention-Technik erhöht die Effizienz weiter, insbesondere bei hohen Auflösungen;Starke Leistung durch Multi-Reward-RLHF: Die Trainingsmethode mit Multi-Reward-RLHF (Reinforcement Learning with Human Feedback) ermöglicht es LongCat-Video, eine Leistung zu erreichen, die mit den neuesten geschlossenen und führenden offenen Quell-Modellen konkurrieren kann.Der Quellcode und die Modellgewichte sind öffentlich verfügbar, um den Fortschritt in diesem Forschungsfeld zu beschleunigen.
One-sentence Summary
The Meituan LongCat Team proposes LongCat-Video, a 13.6B-parameter diffusion transformer model that unifies text-to-video, image-to-video, and video-continuation tasks, enabling efficient, high-quality generation of minutes-long videos through coarse-to-fine sampling and block sparse attention, with multi-reward RLHF enhancing performance to match leading closed- and open-source models, advancing progress toward scalable world models.
Key Contributions
- LongCat-Video is a 13.6B-parameter foundational model that unifies Text-to-Video, Image-to-Video, and Video-Continuation tasks within a single Diffusion Transformer (DiT) architecture, enabling versatile video generation through conditioning on zero, one, or multiple input frames, respectively.
- The model achieves high-quality, minutes-long video generation by pretraining on Video-Continuation tasks, which enhances temporal coherence and prevents quality degradation over extended sequences, a key requirement for world model applications.
- Efficient inference is enabled through a coarse-to-fine generation strategy and block sparse attention, reducing attention computation to under 10% of dense attention, allowing 720p, 30fps video generation in minutes, with performance matching leading open-source and closed-source models on internal and public benchmarks.
Introduction
The authors leverage diffusion modeling to develop LongCat-Video, a 13.6B-parameter foundational model designed for general-purpose video generation, with a focus on long-form, high-quality output. This work is significant in advancing world models, where video generation serves as a key mechanism for simulating and predicting real-world dynamics, particularly in applications like digital humans, autonomous driving, and embodied AI. Prior approaches struggled with temporal coherence in long videos due to error accumulation and high computational costs from dense attention, while most models were task-specific or required post-hoc fine-tuning for long-video generation. The authors’ main contribution is a unified architecture that natively supports Text-to-Video, Image-to-Video, and Video-Continuation tasks through conditioning on the number of input frames, enabling seamless task switching. Crucially, LongCat-Video is pretrained on Video-Continuation, allowing it to generate minutes-long videos without degradation. To ensure efficiency, the model employs a coarse-to-fine generation strategy and a block sparse attention mechanism that reduces attention computation to under 10% of dense attention. Additionally, multi-reward GRPO-based RLHF enhances alignment with diverse quality metrics, resulting in performance on par with leading commercial and open-source models.
Dataset
- The dataset is built from diverse raw video sources and curated through a two-stage pipeline: Data Preprocessing and Data Annotation.
- In the Preprocessing Stage, videos are acquired from multiple sources, deduplicated using source video IDs and MD5 hashes, segmented into coherent clips using PySceneDetect and an in-house TransNetV2 model, and cropped to remove black borders via FFMPEG.
- Processed clips are compressed and packaged for efficient loading and cleaning during training.
- In the Annotation Stage, each clip is enriched with a comprehensive metadata library including duration, resolution, frame rate, bitrate, aesthetic score, blur score, text coverage, watermark detection, and motion intensity derived from optical flow.
- Video content is described using a fine-tuned LLaVA-Video model, enhanced with synthetic video-text pairs and Tarsier2 data to improve temporal action understanding.
- Cinematography elements—such as camera movements (pan, tilt, zoom, shark), shot sizes, and lens types—are annotated using a custom classifier and the Qwen2.5VL model.
- Visual style attributes—including realism, 2D anime, 3D cartoon, and color tones—are also extracted using Qwen2.5VL for rich semantic representation.
- Caption augmentation boosts diversity by translating between Chinese and English, generating concise summaries, and randomly combining caption elements with cinematography and style attributes.
- Clustering analysis is applied to text embeddings of captions, enabling unsupervised categorization into content types like personal interactions, artistic performances, and natural landscapes.
- The resulting cluster tags guide data balancing and supplementation to ensure uniform distribution across categories.
- The final dataset is used in training with flexible mixture ratios across subsets, tailored to different training objectives, and processed with targeted filtering based on metadata to ensure high quality and diversity.
Method
The authors leverage a Diffusion Transformer (DiT) architecture as the core framework for LongCat-Video, a 13.6B parameter model designed for efficient long video generation. The model employs a standard DiT structure with single-stream transformer blocks, each containing a 3D self-attention layer, a cross-attention layer for text conditioning, and a Feed-Forward Network (FFN) with SwiGLU activation. For modulation, AdaLN-Zero is used, incorporating a dedicated modulation MLP within each block. To enhance training stability, RMSNorm is applied as QKNorm within both self-attention and cross-attention modules. Positional encoding for visual tokens is achieved using 3D RoPE. The model processes latent representations generated by a WAN2.1 VAE, which compresses video pixels into latents with a total ratio of 4×16×16 after initial patchify operations. Text conditioning is handled by the umT5 multilingual text encoder.
The model is designed as a unified framework supporting Text-to-Video, Image-to-Video, and Video-Continuation tasks. This is achieved by defining all tasks as video continuation, where the model predicts future frames conditioned on a set of preceding frames. The input consists of two sequences: a noise-free condition sequence Xcond and a noisy sequence Xnoisy, which are concatenated along the temporal axis. The timesteps are similarly partitioned, with tcond set to 0 to inject clear information and tnoisy sampled from [0, 1]. This configuration allows the model to distinguish between tasks based on input patterns. A specialized block attention mechanism is employed, where condition tokens are processed independently of noisy tokens in self-attention, and condition tokens do not participate in cross-attention. This design enables the caching of key-value (KV) features for condition tokens, which is crucial for efficient long video generation during inference.
The training process is structured into three main components: base model training, RLHF training, and acceleration training. Base model training begins with progressive pre-training, starting on low-resolution images to learn visual representations, then transitioning to video training to capture motion dynamics, and finally optimizing multiple tasks jointly. This is followed by supervised fine-tuning (SFT) on a high-quality, curated dataset. The model is trained using a flow matching framework, where the network predicts the velocity field vt of the diffusion process. The loss is the mean squared error between the predicted and ground truth velocity. The training employs a logit-normal-like loss weighting scheme and adapts the timestep shift based on noise token volume.
For RLHF training, the authors employ Group Relative Policy Optimization (GRPO) for flow matching models. To address challenges like slow convergence and complex reward optimization, they introduce several techniques. A key innovation is fixing the stochastic timestep in SDE sampling, where a single critical timestep t′ is randomly selected per prompt, and SDE sampling with noise injection is applied only at t′, while other timesteps use deterministic ODE sampling. This enables precise credit assignment. They also use a truncated noise schedule with a threshold-based clipping mechanism to stabilize sampling at high noise levels. Furthermore, policy and KL loss reweighting is applied to normalize gradient magnitudes, eliminating temporal and step-size dependencies. The relative advantage is computed using the maximum standard deviation observed across all groups to improve training stability. The final training objective is a reweighted sum of the policy loss and KL divergence.
To achieve efficient inference, the model utilizes a coarse-to-fine generation strategy. The base model first generates a low-resolution (480p), low-frame-rate (15fps) video. This video is then upsampled to 720p, 30fps using trilinear interpolation and refined by a LoRA-fine-tuned refinement expert. The refinement expert is trained to learn the transformation between the upsampled video and the target high-resolution video using flow matching. The training input for the refinement stage is a noisy version of the upsampled video, with the ground truth being the velocity field towards the target video. This approach significantly improves efficiency and quality. The refinement process is also extended to Image-to-Video and Video-Continuation tasks by incorporating high-resolution condition frames into the refinement input.
To further accelerate both training and inference, the authors implement a trainable 3D block sparse attention (BSA) mechanism. This operator partitions the video latent into non-overlapping 3D blocks and computes attention only between a query block and a select number of key blocks with the highest similarity scores, based on their average values. This reduces computational load to less than 10% of the original while maintaining near-lossless quality. The BSA operator is implemented in Triton and supports context parallelism through ring attention, enabling efficient training of large-scale models. The top-k block selection pattern is used for its simplicity and effectiveness.
Experiment
- Multi-reward training with HPSv3-based visual quality, VideoAlign-based motion quality, and text-video alignment rewards effectively prevents reward hacking and enables balanced optimization across video generation aspects, as shown in Figure 8 and validated by improved generalization and reduced overfitting.
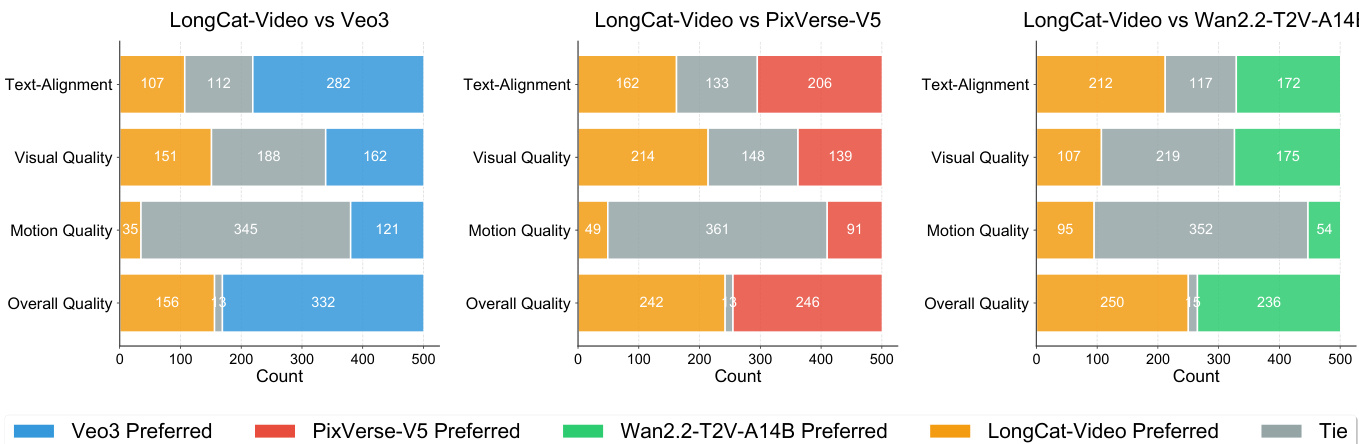
- On the internal Text-to-Video benchmark, LongCat-Video achieves top-tier overall quality, surpassing Wan 2.2-T2V-A14B and PixVerse-V5, with strong visual quality (nearly matching Wan 2.2) and competitive text-alignment, outperforming open-source models in user preference (GSB) and MOS evaluations.
- On the internal Image-to-Video benchmark, LongCat-Video achieves the highest visual quality score (3.27) but lags in image-alignment and motion quality compared to Hailuo-2 and Wan2.2-I2V-A14B, indicating room for improvement in temporal consistency and reference image fidelity.
- On the public VBench 2.0 benchmark, LongCat-Video ranks second overall, leading in the Commonsense dimension, demonstrating superior motion rationality and adherence to physical laws, a key strength for long-video and world-model development.
- Coarse-to-fine generation and block sparse attention reduce inference time by over 10× on a single H800 GPU, enabling 720p, 30fps video generation in minutes while improving visual details, as shown in Figure 10.
The authors present a model configuration with 48 layers, a model hidden size of 4096, an FFN hidden size of 16384, 32 attention heads, and an AdaLN embedding size of 512. This setup supports the architecture used in LongCat-Video for high-quality video generation.

The authors compare full attention and sparse attention training stages, finding that both use the same learning rate, iteration count, and frame size bucket, but sparse attention achieves 93.75% sparsity while maintaining the same threshold and training duration. This indicates that sparse attention significantly reduces computational complexity without altering other key training parameters.

The authors use a Good-Same-Bad (GSB) evaluation to compare LongCat-Video against Veo3, PixVerse-V5, and Wan2.2-T2V-A14B, showing that LongCat-Video is preferred over Wan2.2-T2V-A14B in overall quality, driven by stronger text-alignment and motion quality, while being nearly tied with PixVerse-V5. In comparison with Veo3, LongCat-Video is preferred less frequently, particularly in text-alignment and overall quality, where Veo3 leads.
The authors use a multi-stage training approach with varying task combinations, size buckets, learning rates, and iterations to optimize LongCat-Video. The training configurations show a progression from simpler tasks with larger batch sizes and higher learning rates to more complex multi-task setups with smaller learning rates and reduced iterations, indicating a strategy to balance efficiency and model performance.

The authors use a comprehensive internal benchmark to evaluate LongCat-Video against several leading models in image-to-video generation. Results show that LongCat-Video achieves the highest score in Visual Quality but scores lower in Image-Alignment and Motion Quality compared to other models, indicating strong visual fidelity but room for improvement in alignment and motion consistency.
