Command Palette
Search for a command to run...
WorldMirror: Universelle 3D-Welt-Rekonstruktion mit beliebigem Prior-Präfix
WorldMirror: Universelle 3D-Welt-Rekonstruktion mit beliebigem Prior-Präfix
Yifan Liu Zhiyuan Min Zhenwei Wang Junta Wu Tengfei Wang Yixuan Yuan Yawei Luo Chunchao Guo
Zusammenfassung
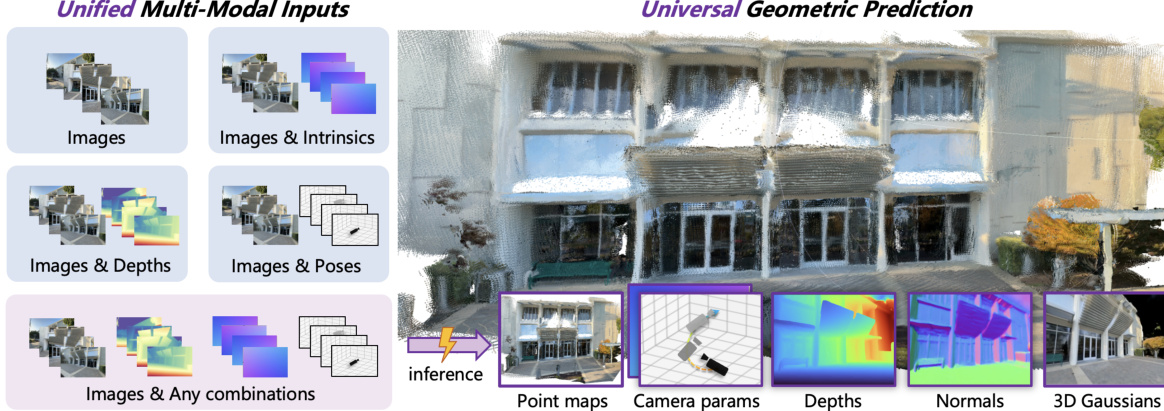
Wir präsentieren WorldMirror, ein all-in-one, feed-forward Modell für vielseitige Aufgaben der 3D-Geometrie-Vorhersage. Im Gegensatz zu bestehenden Methoden, die entweder auf Bild-Eingaben beschränkt sind oder für eine spezifische Aufgabe maßgeschneidert sind, integriert unser Framework flexibel verschiedene geometrische Vorwissen, darunter Kameraposen, Intrinsika und Tiefenkarten, und generiert gleichzeitig mehrere 3D-Repräsentationen: dichte Punktwolken, Multi-View-Tiefenkarten, Kameraparameter, Oberflächen-Normalen sowie 3D-Gauß-Objekte. Diese elegante und einheitliche Architektur nutzt verfügbares Vorwissen, um strukturelle Mehrdeutigkeiten zu lösen und liefert geometrisch konsistente 3D-Ausgaben in einem einzigen Vorwärtsdurchlauf. WorldMirror erreicht state-of-the-art Ergebnisse über eine Vielzahl von Benchmarks – von der Kameraparameter-, Punktwolken-, Tiefen- und Oberflächen-Normalenschätzung bis hin zur Synthese neuer Ansichten – und behält gleichzeitig die Effizienz von feed-forward Inferenz bei. Der Quellcode und die Modelle werden in Kürze öffentlich verfügbar sein.
One-sentence Summary
The authors from Zhejiang University, Chinese University of Hong Kong, and Tencent Hunyuan propose WorldMirror, a feed-forward model that unifies multiple 3D geometric prediction tasks by integrating diverse priors—such as camera poses and depth—into a single architecture, enabling simultaneous generation of point clouds, 3D Gaussians, depth maps, and normals with geometric consistency and state-of-the-art efficiency across benchmarks.
Key Contributions
- WorldMirror introduces a universal feed-forward 3D reconstruction framework that integrates diverse geometric priors—such as calibrated camera intrinsics, poses, and depth maps—into a unified architecture, enabling robust handling of structural ambiguities and improving geometric consistency across tasks.
- The model employs a Multi-Modal Prior Prompting mechanism with specialized tokenization and dynamic prior injection, allowing it to flexibly process arbitrary subsets of available priors while maintaining high performance during inference.
- WorldMirror achieves state-of-the-art results across multiple 3D reconstruction benchmarks, outperforming existing methods in tasks ranging from point map and camera estimation to surface normal prediction and novel view synthesis, all within a single forward pass.
Introduction
Visual geometry learning is central to applications like augmented reality, robotics, and autonomous navigation, where accurate 3D reconstruction from images is essential. While recent feed-forward neural models have replaced traditional iterative methods like SfM and MVS, they typically operate only on raw images and lack the ability to incorporate valuable geometric priors—such as calibrated intrinsics, camera poses, or depth from LIDAR/RGB-D sensors—limiting their robustness in challenging scenarios. Additionally, most existing models are task-specific, addressing only one or a few geometric tasks, which hinders their versatility and integration into broader pipelines.
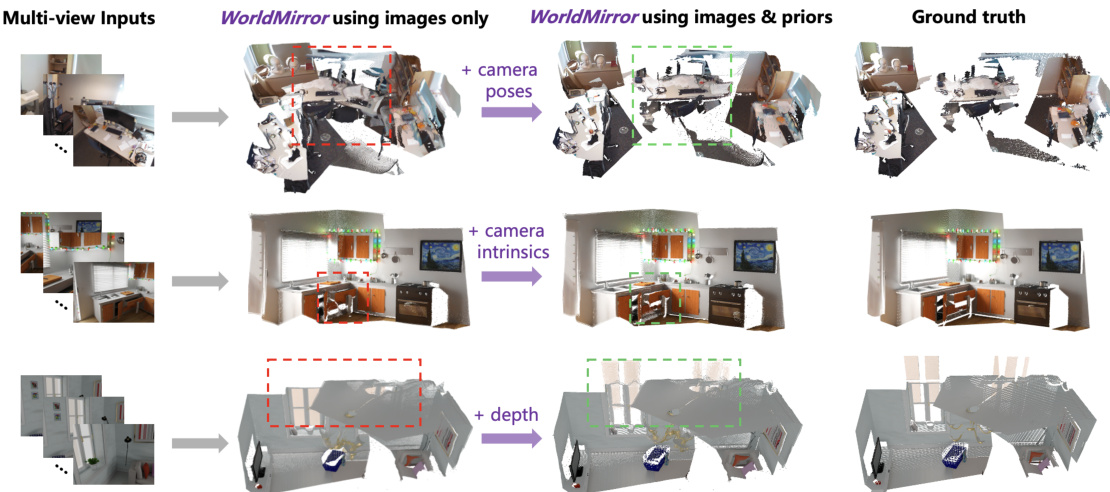
To overcome these limitations, the authors introduce WorldMirror, a universal 3D reconstruction framework that leverages any available geometric prior through a novel Multi-Modal Prior Prompting mechanism. This approach uses specialized, lightweight encoders to convert different priors—compact ones like poses and intrinsics into single tokens, and dense ones like depth maps into spatially aligned tokens—enabling flexible, unified input handling. A dynamic prior injection scheme during training ensures robustness to arbitrary prior availability at inference. The model further unifies diverse 3D tasks—including point map regression, camera and depth estimation, surface normal prediction, and novel view synthesis—within a single transformer-based architecture, supported by a systematic curriculum learning strategy to manage complex multi-task training. Experiments show WorldMirror achieves state-of-the-art performance across benchmarks, outperforming prior methods in both accuracy and task coverage.
Method
The authors leverage a unified feed-forward architecture to address diverse 3D geometric prediction tasks, enabling the simultaneous generation of multiple 3D representations from multi-view images. The framework, named WorldMirror, is designed to flexibly integrate various geometric priors—such as camera poses, intrinsics, and depth maps—when available, while maintaining robust performance in their absence. The overall architecture consists of a multi-modal prior prompting mechanism and a universal geometric prediction module, which together form a cohesive system for end-to-end geometric understanding.
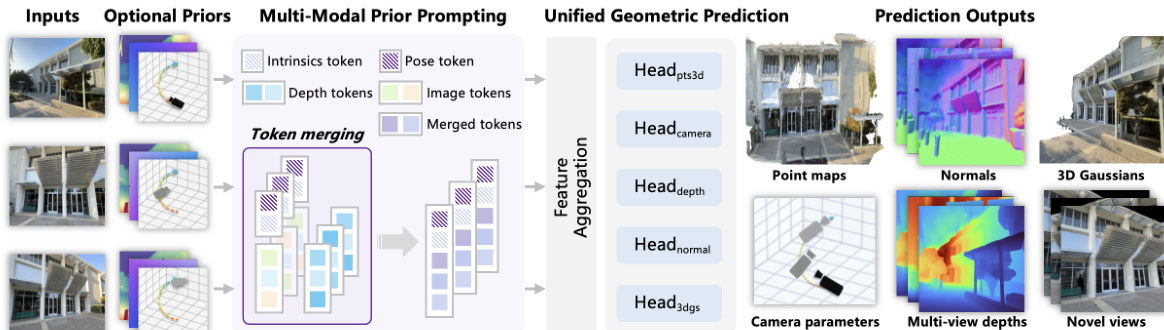
As shown in the figure below, the framework begins with multi-view image inputs, which are processed alongside optional prior information. The model employs a multi-modal prior prompting strategy to embed diverse prior modalities into the visual representation. For camera poses, each pose [boldsymbolRi∣boldsymbolti] is normalized to a unit cube and encoded into a 7-dimensional vector by converting the rotation matrix to a quaternion and combining it with the normalized translation vector. This vector is then projected to a token of dimension D using a two-layer MLP, resulting in a camera pose token mathbfTicam. Similarly, calibrated intrinsics are extracted as focal lengths and principal points, normalized by image resolution, and projected to an intrinsic token mathbfTiintr using a two-layer MLP. Depth maps, being dense spatial signals, are normalized to [0,1] and embedded via a convolutional layer that matches the patch size of the visual tokens, producing depth tokens mathbfTidepth that are spatially aligned and added to the image tokens. These prior tokens are then concatenated with the image tokens mathbfTiimg to form a unified prompted token set mathbfTiprompt, enabling the model to adapt to arbitrary combinations of available priors.
The composite token set is processed by a visual transformer backbone, which performs feature aggregation across views to generate consolidated representations. These representations are then passed to a set of multi-task heads for universal geometric prediction. The framework predicts a range of geometric attributes, including 3D point maps, multi-view depth maps, camera parameters, surface normals, and 3D Gaussians. For point map, depth, and camera parameter estimation, the model uses DPT heads to regress dense outputs from the image tokens, while camera parameters are predicted from the camera pose tokens using transformer layers. Surface normal estimation is performed using a DPT head followed by L2 normalization to ensure unit vector outputs, with a hybrid supervision approach that combines annotated data and pseudo normals derived from ground-truth depth maps to address annotation scarcity.

For novel view synthesis, the model predicts 3D Gaussian Splatting (3DGS) by regressing pixel-wise Gaussian depth maps and feature maps using a DPT head. These depth predictions are back-projected using ground-truth camera poses and intrinsics to obtain Gaussian centers, while the remaining attributes—opacity, orientation, scale, residual spherical-harmonic color coefficients, and fusion weight—are inferred by combining the feature maps with appearance features from a convolution network. To reduce redundancy from overlapping regions, per-pixel Gaussians are clustered and pruned via voxelization. During training, input images are split into context and target sets, with 3D Gaussians built from context views and rendered to supervise both target and original context viewpoints via a differentiable rasterizer, ensuring consistency across views.
The model is trained end-to-end by minimizing a composite loss function that integrates supervision for all prediction tasks. This includes losses for point maps, depth, camera parameters, surface normals, and 3DGS, with the 3DGS loss further incorporating RGB rendering, depth consistency, and gradient consistency terms to enhance robustness and reduce floating points in the predicted Gaussians. The framework's ability to leverage available priors enables robust reconstruction in challenging scenarios, while its multi-task design ensures geometric consistency across different outputs.
Experiment
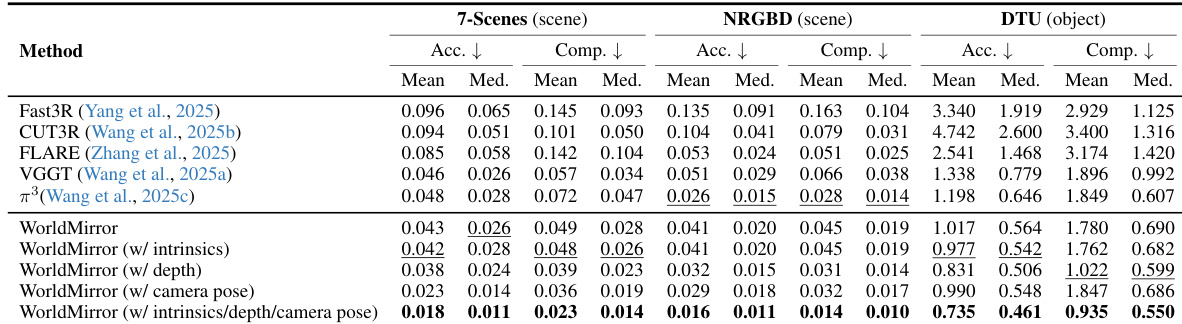
- Point map reconstruction on 7-Scenes, NRGBD, and DTU: Achieved 10.4% and 17.8% mean accuracy gains over VGGT and π3, respectively, with 58.1% and 53.1% improvements using all priors compared to the no-prior baseline.
- Camera pose estimation on RealEstate10K, Sintel, and TUM-dynamics: Achieved superior zero-shot performance on RealEstate10K and TUM-dynamics, with competitive results on Sintel despite limited training data for dynamic scenes.
- Surface normal estimation on iBims-1, NYUv2, and ScanNet: Demonstrated substantial improvements over regression-based and diffusion-based methods, with consistent gains across datasets.
- Novel view synthesis on RealEstate10K, DL3DV, and VR-NeRF: Outperformed feed-forward 3DGS baselines including AnySplat across all metrics in both sparse- and dense-view settings, showing strong generalization and rendering quality.
- Prior-guidance evaluation: Incorporating single or multiple geometric priors (camera poses, intrinsics, depth) enhanced performance across tasks, with camera poses enabling global geometry, intrinsics resolving scale ambiguity, and depth providing pixel-level constraints.
- Ablation study: Single token prior embedding outperformed dense per-pixel conditioning; removing any component in the 3DGS prediction framework or training strategy degraded novel view synthesis performance.
- Post-optimization with 3DGS: Initialization using predicted point clouds or 3DGS primitives significantly accelerated convergence and improved rendering quality, surpassing feed-forward baselines.
Results show that WorldMirror achieves state-of-the-art performance on camera pose estimation across all three datasets, outperforming previous methods in most metrics. On RealEstate10K and TUM-dynamics, it surpasses all baselines in relative rotation and translation accuracy, while on Sintel it maintains competitive results despite the limited outdoor dynamic scenes in its training data.

Results show that the proposed method achieves competitive performance across all three datasets, with the highest PSNR and SSIM values on RealEstate10K and VR-NeRF, and a significant improvement in LPIPS on DL3DV compared to the baseline methods. The model maintains strong results across different view counts, demonstrating robustness and generalization in novel view synthesis.

The authors use WorldMirror to evaluate point map reconstruction on 7-Scenes, NRGBD, and DTU datasets, reporting accuracy and completion metrics. Results show that WorldMirror without any priors outperforms previous state-of-the-art methods, with significant improvements in mean accuracy, and further gains when combining all priors, achieving the best results across all datasets.
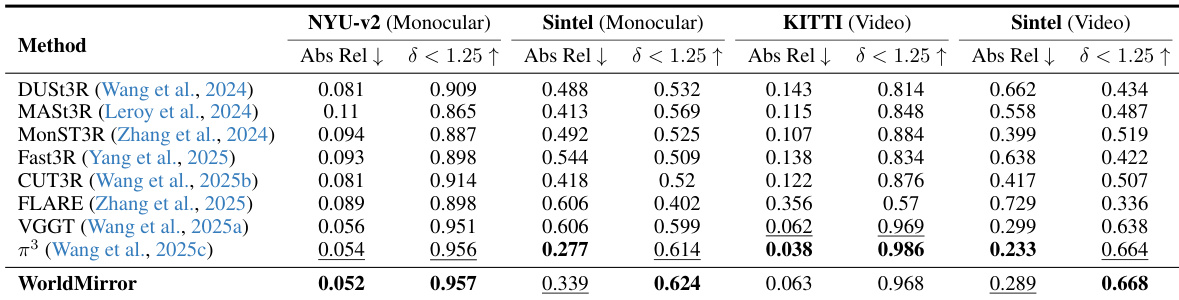
The authors use WorldMirror to evaluate monocular and video depth estimation on NYUv2, Sintel, and KITTI datasets, reporting absolute relative error and the percentage of predictions within a 1.25 threshold. Results show that WorldMirror achieves competitive performance across all benchmarks, matching or exceeding state-of-the-art methods in most cases, with particularly strong results on Sintel and KITTI, though it shows a modest gap on KITTI compared to π³, which the authors attribute to the limited representation of urban driving scenes in the training data.
Results show that WorldMirror achieves superior performance in novel view synthesis across both RealEstate10K and DL3DV datasets, with significant improvements over baselines like FLARE and AnySplat in PSNR, SSIM, and LPIPS metrics. The inclusion of camera and intrinsic priors further enhances reconstruction quality, particularly in the dense-view setting, demonstrating the effectiveness of the proposed unified geometric representation.
