Command Palette
Search for a command to run...
X-VLA: Soft-Prompt-basierter Transformer als skalierbarer cross-Embodiment Vision-Language-Action-Modell
X-VLA: Soft-Prompt-basierter Transformer als skalierbarer cross-Embodiment Vision-Language-Action-Modell
Zusammenfassung
Erfolgreiche allgemeine Vision-Sprache-Aktion (VLA)-Modelle beruhen auf einer effektiven Ausbildung über vielfältige Roboterplattformen hinweg unter Verwendung großer, plattformübergreifender, heterogener Datensätze. Um die Heterogenität in reichhaltigen, vielfältigen Quellen roboterbasierter Daten gezielt zu nutzen und zu fördern, schlagen wir einen neuartigen Soft-Prompt-Ansatz vor, der nur minimale zusätzliche Parameter erfordert. Dabei werden Konzepte des Prompt-Lernens in das plattformübergreifende Roboterverständnis integriert, und für jede unterschiedliche Datensource werden separate, lernbare Embeddings eingeführt. Diese Embeddings fungieren als plattformspezifische Prompts und ermöglichen gemeinsam eine effektive Nutzung der unterschiedlichen plattformübergreifenden Merkmale durch VLA-Modelle. Unser neu entwickeltes X-VLA ist eine elegante, auf Flow-Matching basierende VLA-Architektur, die ausschließlich auf soft-promptierten Standard-Transformer-Encodern beruht und sowohl Skalierbarkeit als auch Einfachheit bietet. Die Evaluierung an sechs Simulationen sowie drei realen Robotern zeigt, dass unsere Instanziierung X-VLA-0.9B (0,9 Milliarden Parameter) gleichzeitig Spitzenleistung über eine Vielzahl von Benchmarks erzielt und herausragende Ergebnisse bei einer breiten Palette von Fähigkeiten erzielt – von flexibler Dexterity bis hin zu schneller Anpassung an unterschiedliche Plattformen, Umgebungen und Aufgaben. Webseite: https://thu-air-dream.github.io/X-VLA/
One-sentence Summary
Researchers from Institute for AI Industry Research (AIR), Tsinghua University and Shanghai AI Lab propose X-VLA-0.9B, a flow-matching-based Vision-Language-Action model that employs embodiment-specific soft prompts (learnable embeddings) to address cross-embodiment heterogeneity beyond just action spaces, achieving state-of-the-art results across six simulation benchmarks and three real-world robots including challenging dexterous cloth folding tasks with minimal parameter tuning.
Key Contributions
- Current Vision-Language-Action models struggle to generalize across heterogeneous robotic platforms due to hardware and action space variations, leading to unstable training and poor cross-domain performance despite leveraging pretrained vision-language models.
- X-VLA introduces a soft-prompt mechanism that absorbs embodiment-specific variability through learnable embeddings per hardware configuration, preserving a shared backbone for embodiment-agnostic reasoning while enabling scalable pretraining on diverse datasets.
- Evaluated across broad benchmarks, X-VLA-0.9B achieves state-of-the-art results with substantial gains in hundreds of setups and demonstrates scalable training trends without saturation at 0.9B parameters, 290K episodes, and 7 data sources.
Introduction
Vision-Language-Action (VLA) models are critical for enabling robots to interpret natural language commands, perceive environments visually, and execute physical actions—yet they struggle with real-world deployment due to hardware and action space heterogeneity across robotic platforms. Prior approaches either manually reshape action spaces or align actions at a semantic level but fail to address embodiment-specific reasoning, leading to unstable training and poor generalization when scaling to diverse data sources. The authors introduce X-VLA, a framework leveraging soft prompts as lightweight, hardware-specific embeddings that absorb embodiment variability while preserving a shared backbone for generalist reasoning. This design enables scalable pretraining across model size, data diversity, and volume—achieving state-of-the-art results with minimal tunable parameters and demonstrating clear potential for further scaling without performance saturation.
Dataset
The authors describe their dataset composition and usage as follows:
-
Composition and sources: The core dataset is Soft-FOLD, a proprietary high-quality cloth folding dataset comprising 1,200 human demonstration episodes. It was created specifically for dexterous manipulation research, not sourced from pre-existing public collections. The paper references broader reliance on peer-reviewed open-sourced robotics datasets (e.g., Bu et al., 2025; Wu et al., 2025) for foundational pretraining, though these are not detailed here.
-
Key subset details (Soft-FOLD):
- Size: 1,200 curated episodes (20–25 episodes per hour of collection, including resets).
- Source: Human demonstrations with structured strategy.
- Filtering rules:
- Task decomposed into Stage I (smoothing disordered cloth via repetitive motions until clear keypoints emerge) and Stage II (neat folding of smoothed cloth).
- Random/unstructured Stage I demonstrations were discarded to avoid inconsistent policy learning.
- Failed attempts were excluded during collection.
-
Data usage in the model:
- The full Soft-FOLD dataset trained the finetuned X-VLA-0.9B dexterous manipulation model.
- Employed DAgger-style iterative collection: After every 100 episodes, an ACT model identified failure modes, guiding targeted new demonstrations to address gaps.
- Mixture ratios followed this refinement cycle, prioritizing failure-specific data.
-
Processing details:
- No explicit cropping; segmentation relied on the two-stage task decomposition.
- Metadata implicitly captured key skills (Localization, Pick, Place, Swing) observed during folding progression.
- Human strategy standardization was critical—Stage I required deliberate smoothing to reduce cloth dynamics variability before Stage II folding.
Method
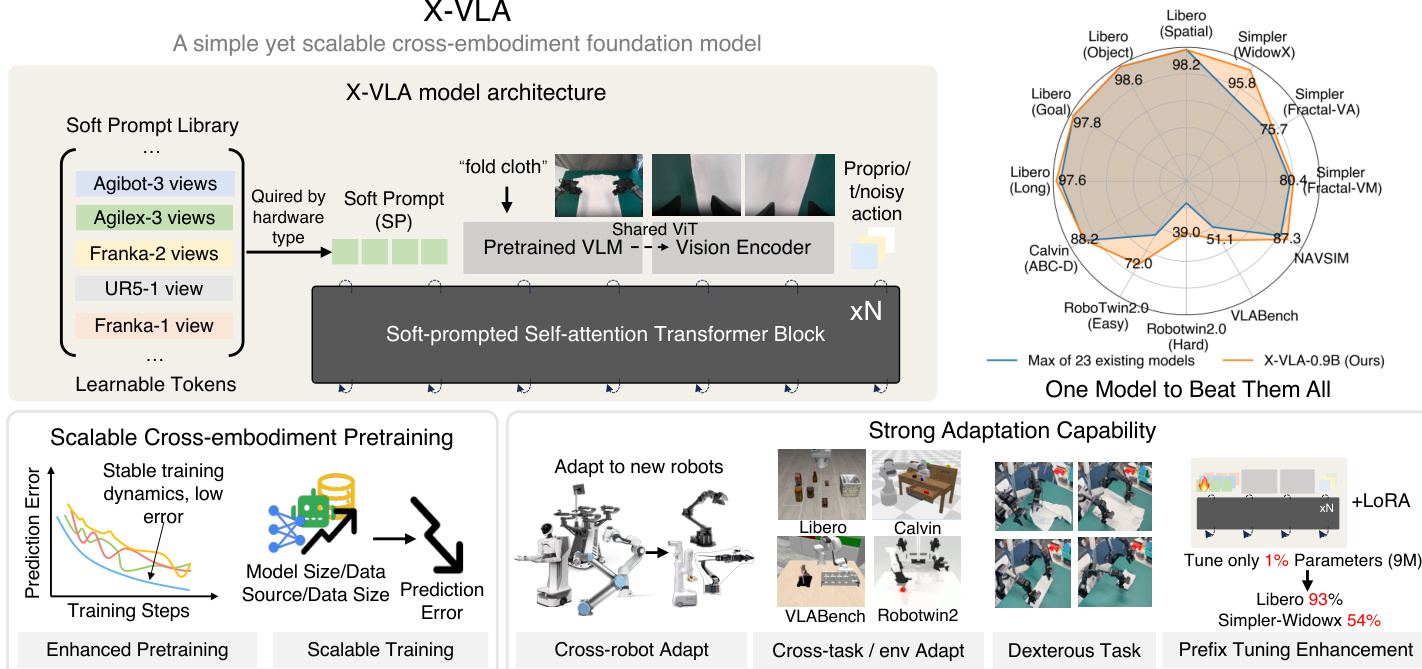
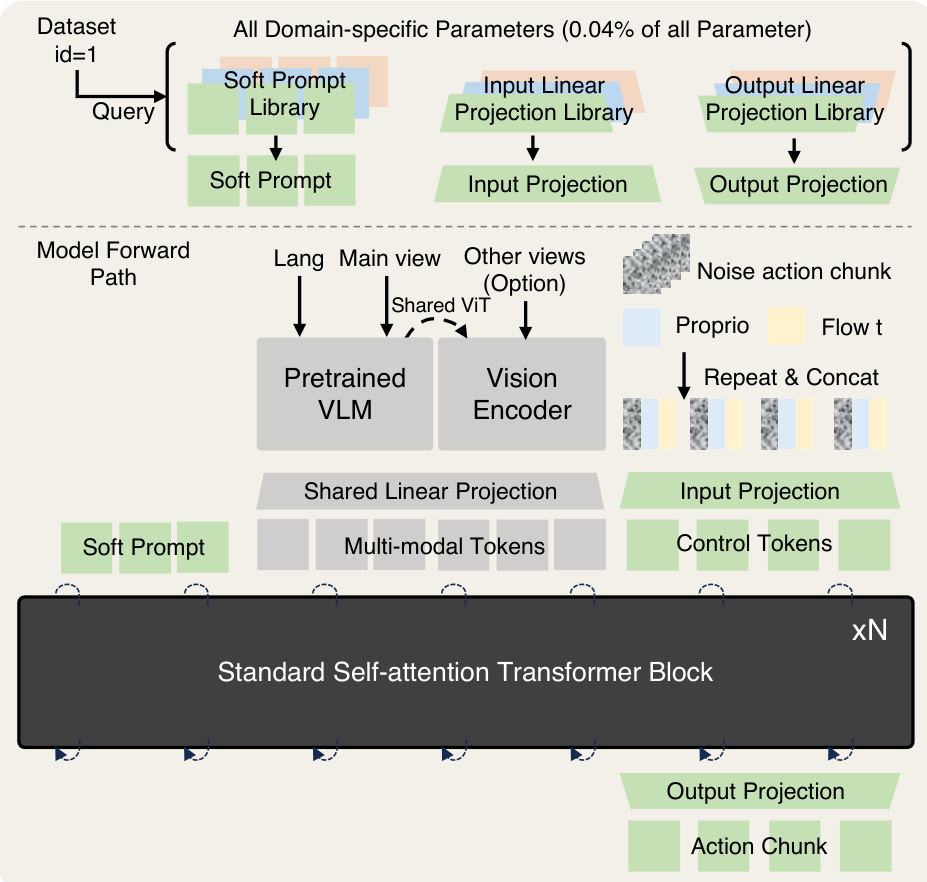
The authors leverage a minimalist yet scalable architecture for cross-embodiment Vision-Language-Action (VLA) modeling, centered around soft-prompted Transformer blocks. The core innovation lies in the introduction of learnable, embodiment-specific soft prompts that are queried by hardware type and injected early into the model pipeline to absorb heterogeneity across diverse robotic datasets. These prompts, initialized randomly and optimized end-to-end, implicitly encode latent hardware configurations without requiring handcrafted textual descriptions or disruptive projection layers. As shown in the framework diagram, the model integrates a pretrained Vision-Language Model (VLM) for high-level task reasoning and a shared Vision Transformer (ViT) for auxiliary views, ensuring semantic alignment while preserving pretrained representations. The multimodal tokens—comprising language, main-view images, and optional wrist-view inputs—are fused with proprioceptive states and noisy action chunks, which are then projected into a unified feature space before being processed by a stack of standard self-attention Transformer blocks. This design enables the model to scale efficiently with data and model size while maintaining stable training dynamics.
To address the challenge of cross-embodiment heterogeneity, the authors empirically evaluate four distinct strategies, as illustrated in the comparative diagram. The first, domain-specific action projection, applies separate output heads per dataset but fails to influence early-stage reasoning. The second, HPT-style projection, maps domain-specific observations into a shared space via cross-attention resamplers, yet risks corrupting pretrained VLM features. The third, language prompts, injects textual robot descriptions into the VLM encoder, but suffers from scalability and annotation dependency. In contrast, the proposed soft prompt method—depicted in the rightmost panel—injects learnable tokens directly into the Transformer input, queried by dataset ID, enabling embodiment-aware reasoning without altering the backbone’s pretrained structure. This approach achieves superior training stability and generalization, as confirmed by empirical results.

The full forward pass of X-VLA begins with querying a soft prompt from a library based on the dataset identifier, which is then concatenated with multimodal tokens derived from language, main-view images (processed by a pretrained VLM), and optional auxiliary views (encoded via a shared ViT). Proprioceptive states and noisy action chunks are fused with time embeddings and projected into the same token space. All tokens are then fed into a standard Transformer backbone, which generates an action chunk through a flow-matching policy. The model’s parameter efficiency is notable: domain-specific components—including the soft prompt library, input projection, and output projection—constitute only 0.04% of total parameters. During adaptation to new robots, the authors employ a two-stage procedure: first, warming up new prompts while freezing the backbone, then jointly fine-tuning both components. This strategy ensures rapid specialization with minimal parameter updates, as demonstrated in the adaptation experiments.
Experiment
- Scaling experiments validated X-VLA's performance growth across model size (up to 0.9B parameters), data diversity (7 sources), and volume (290K episodes), showing no saturation in trends and strong correlation between pretraining ℓ₁ validation error and downstream success.
- Adaptation experiments achieved state-of-the-art results on 5 simulation benchmarks, including 98% success on Libero and 96% on Simpler-WidowX, while surpassing baselines on real-world platforms (WidowX, AgileX, AIRBOT) with 100% success in dexterous cloth-folding and 93% on Libero using parameter-efficient finetuning (LoRA) with only 1% tunable parameters.
- Interpretability analysis confirmed soft prompts capture embodiment-specific features via T-SNE clustering aligned with hardware configurations and enabled efficient cross-embodiment transfer, with pretrained prompts accelerating adaptation by 30% in early training stages.
- Data efficiency tests demonstrated robust performance under limited supervision, maintaining 91.1% success on Libero with only 10 demonstrations.
- Joint adaptation across multiple embodiments (Libero, BridgeData, Calvin-ABC) preserved or improved single-domain performance, indicating positive cross-domain knowledge transfer.
The authors evaluate X-VLA-0.9B across multiple simulation benchmarks, reporting high success rates such as 98.1% average on Libero and 4.43 average on Calvin (ABC→D). Results on VLAbench show varied performance across categories, with semantic instruction achieving 63.1 and cross-category scoring lowest at 25.1, indicating stronger performance on in-distribution and instruction-aligned tasks. These outcomes highlight the model’s strong generalization on standard benchmarks while revealing challenges in cross-category transfer.

The authors compare X-VLA against alternative backbone architectures, including DiT, MM-DiT, and π₀-Style, using validation error as the metric. Results show X-VLA achieves the lowest validation error of 0.041, outperforming all baselines and demonstrating superior stability and performance on heterogeneous datasets.
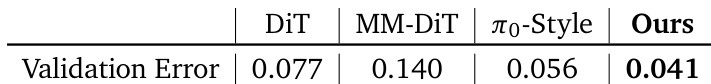
The authors evaluate X-VLA-0.9B’s data efficiency using PEFT on Libero benchmarks with limited demonstrations. Results show the model maintains strong performance even with only 10 demonstrations, achieving 91.1% average success rate compared to 92.8% with 50 demonstrations, highlighting its ability to adapt effectively under extreme data scarcity.

The authors evaluate X-VLA-0.9B on the Simpler benchmark across multiple robot platforms and task types, reporting success rates for specific object manipulation tasks and their averages. Results show the model achieves high performance on WidowX Robot tasks, with an average success rate of 95.8%, outperforming its performance on Google Robot tasks under both Visual Matching (80.4%) and Visual Aggregation (75.7%) settings. This indicates stronger adaptation to the WidowX embodiment, consistent with the paper’s emphasis on embodiment-specific tuning via soft prompts.

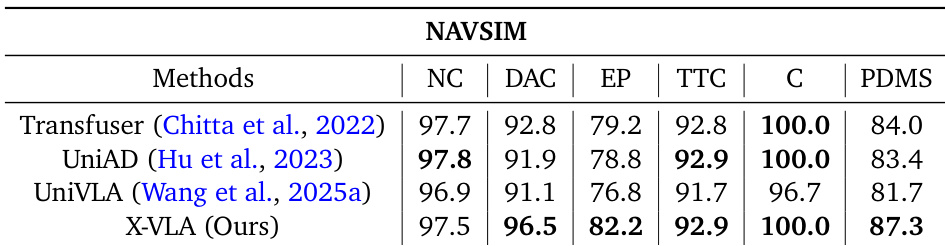
The authors evaluate X-VLA on the NAVSIM autonomous driving benchmark using closed-loop simulation, reporting performance across five metrics aggregated into a PDM score. X-VLA achieves the highest PDM score of 87.3, outperforming prior methods including Transfuser, UniAD, and UniVLA, while matching or exceeding them on individual metrics such as drivable area compliance (96.5) and collision avoidance (100.0). Results indicate that X-VLA’s end-to-end vision-language-action architecture generalizes effectively to complex real-world driving scenarios despite being pretrained on heterogeneous robotic data.