Command Palette
Search for a command to run...
Umkehrung des Dialogs: Training und Evaluierung von User-Language-Modellen
Umkehrung des Dialogs: Training und Evaluierung von User-Language-Modellen
Tarek Naous Philippe Laban Wei Xu Jennifer Neville
Zusammenfassung
Gespräche mit Sprachmodellen (LMs) umfassen zwei Teilnehmer: einen menschlichen Nutzer, der das Gespräch leitet, und ein LM-Assistenten, der auf die Anfrage des Nutzers reagiert. Um diese spezifische Rolle zu erfüllen, werden LMs nachträglich so trainiert, dass sie hilfreiche Assistenten sind – optimiert, um umfassende und gut strukturierte Antworten zu generieren, frei von Mehrdeutigkeiten und grammatikalischen Fehlern. Im Gegensatz dazu sind menschliche Nutzerausdrücke selten perfekt: Jeder Nutzer formuliert Anfragen auf einzigartige Weise, oft mit unvollständigem Aufwand in jeder Runde und stetiger Verbesserung im Laufe des Gesprächs. Um die Leistung von LMs in realistischen Szenarien zu evaluieren, haben frühere Arbeiten simulierte Nutzer in mehrschrittigen Gesprächen eingesetzt, wobei häufig ein ursprünglich als hilfreicher Assistent trainiertes LLM dazu veranlasst wurde, die Rolle eines Nutzers zu übernehmen. Wir zeigen jedoch, dass Assistent-LMs schlechte Nutzersimulatoren sind, wobei sich die überraschende Erkenntnis ergibt, dass bessere Assistenten schlechtere Simulatoren ergeben. Stattdessen führen wir speziell für die Aufgabe konzipierte Nutzer-Sprachmodelle (User LMs) ein – Modelle, die nachträglich so trainiert wurden, um menschliche Nutzer in mehrschrittigen Gesprächen zu simulieren. Durch verschiedene Evaluationen zeigen wir, dass User LMs eine bessere Übereinstimmung mit menschlichem Verhalten aufweisen und eine höhere Robustheit bei der Simulation erreichen als bestehende Methoden. Wenn User LMs eingesetzt werden, um Programmier- und Mathematikgespräche zu simulieren, sinkt die Leistung eines leistungsstarken Assistenten (GPT-4o) von 74,6 % auf 57,4 %, was bestätigt, dass realistischere Simulationsumgebungen zu größeren Schwierigkeiten für Assistenten führen, da diese die Feinheiten menschlichen Verhaltens in mehrschrittigen Interaktionen nicht adäquat bewältigen können.
One-sentence Summary
The authors, affiliated with Microsoft Research and Georgia Institute of Technology, propose UserLM-8b, a purpose-built User Language Model post-trained to simulate human users in multi-turn conversations, demonstrating superior alignment with real user behavior and greater simulation robustness compared to assistant-based simulators, which fail to capture conversational nuances and thus overestimate assistant performance in realistic settings.
Key Contributions
- Prior work has relied on assistant language models (LMs) to simulate human users in multi-turn conversations, but these models produce overly structured, cooperative, and unrealistic user behavior due to their training to be helpful assistants, leading to inflated performance estimates for assistant LMs.
- The authors introduce User Language Models (User LMs), purpose-built models post-trained to simulate real human users by generating diverse, incremental, and contextually nuanced utterances that reflect how users actually refine their intent over time.
- Evaluations show that User LMs better align with human conversational patterns and lead to more realistic assistant performance degradation—e.g., GPT-4o’s success rate drops from 74.6% to 57.4% on coding tasks—demonstrating their effectiveness in creating robust, human-like simulation environments.
Introduction
The authors address the growing need for realistic user simulation in evaluating conversational assistant language models (LMs), which often perform well on static benchmarks but struggle in dynamic, multi-turn interactions with real users. Prior methods rely on prompting assistant LMs to role-play users, but these models—optimized for clarity and cooperation—produce overly structured, persistent, and unrealistic user behavior, leading to inflated performance estimates. The authors introduce User Language Models (User LMs), purpose-built models post-trained to simulate human users by generating diverse, incremental, and contextually nuanced utterances that reflect real-world conversational patterns. Their key contribution is a framework for training and evaluating User LMs that better align with human behavior, demonstrated through improved simulation robustness, intent decomposition, and dialogue termination. When used to evaluate GPT-4o on coding and math tasks, User LMs reduce performance from 74.6% to 57.4%, revealing critical limitations in assistant models that are masked by idealized simulators.
Dataset
- The dataset is composed of conversations from WildChat, a large-scale dialogue corpus, with additional curation from the PRISM dataset for evaluation and training.
- WildChat was initially reduced from its original size by removing near-duplicate conversations using a 7-gram counter on first-turn user prompts; this process eliminated repetitive prompt templates, resulting in a cleaned dataset of 384,336 unique conversations.
- The authors manually identified high-frequency, non-natural prompt patterns—such as one template appearing in over 81,000 conversations—that were deemed artificial and potentially harmful to model quality.
- The cleaned WildChat data is used as part of the training mixture, combined with other sources like PRISM, with specific mixture ratios optimized to balance diversity and naturalness.
- During training, the authors apply a cropping strategy that focuses on the first few turns of each conversation to maintain coherence and reduce noise, particularly in long or repetitive dialogues.
- Metadata for each conversation is constructed based on intent labels derived from the first user turn, enabling evaluation of alignment between generated responses and user intent.
- The PRISM dataset is used for evaluation, particularly in assessing dialogue termination and n-gram overlap with user intent, where the model’s performance is measured across turns using precision, recall, and F1 scores.
Method
The authors leverage real human-assistant conversations as training data to train a user language model (UserLM) that mimics human behavior in dialogues. The core approach involves "flipping the dialogue" to transform each conversation into training samples that model the conditional distribution of user utterances. At the first turn, the model conditions on a high-level user intent, and in subsequent turns, it conditions on both the intent and the evolving conversation state. This framework is illustrated in the diagram below, which shows how a conversation with K turns is converted into K+1 training samples, each conditioned on the intent and prior dialogue history to generate the next user utterance.

The process begins with the generation of high-level user intents from existing conversations. These intents are defined as abstract, overarching goals that capture the user's objective without including specific details, striking a balance between being too vague and too prescriptive. To generate these intents, the authors use a prompt template with GPT-4o, providing the full conversation history and instructing the model to produce a concise summary of the user's high-level intent. The prompt includes three hand-engineered examples to guide the model, ensuring the generated summaries are consistent and focused on the general purpose of the interaction.
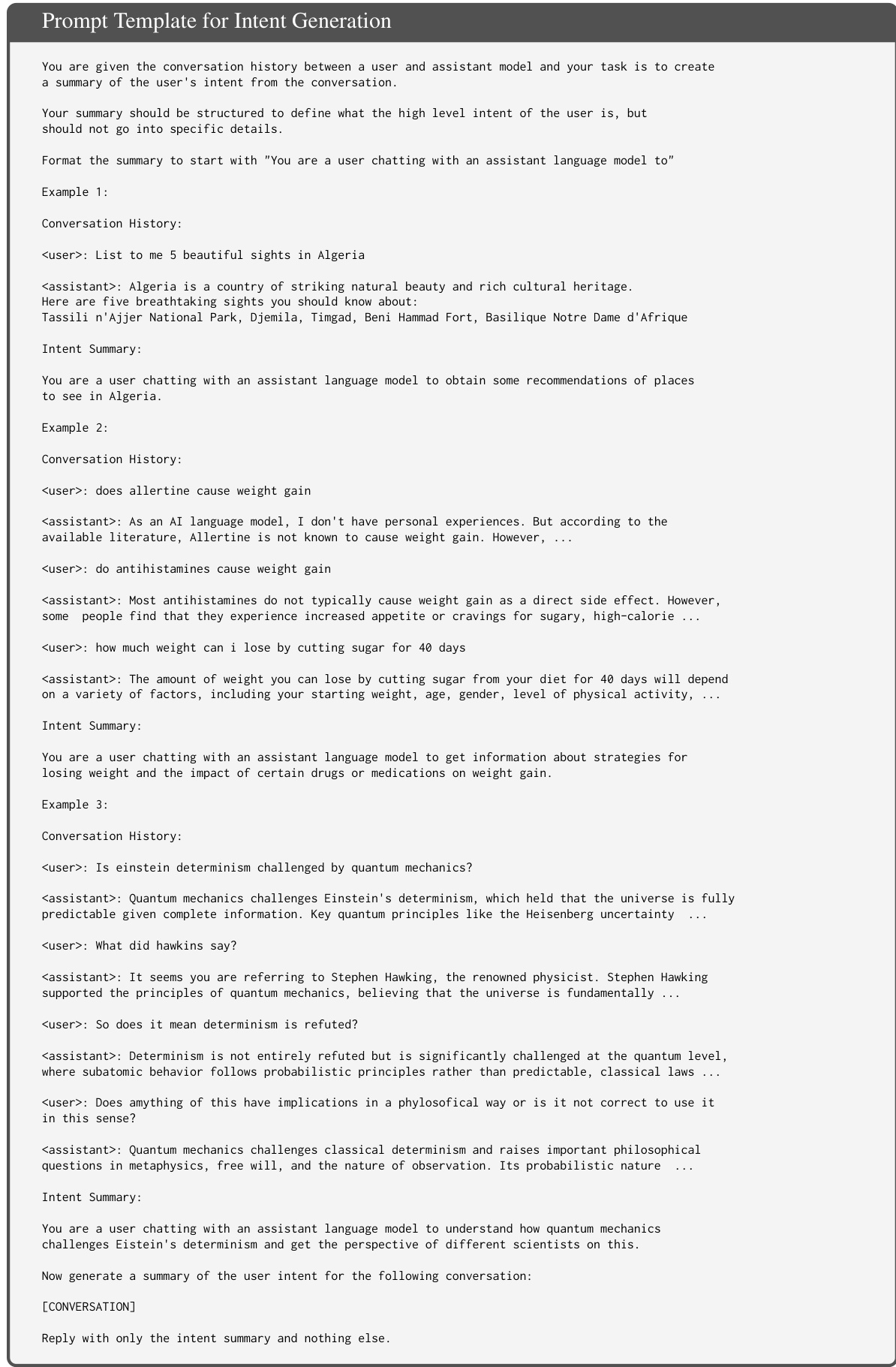
Once the intents are generated, the authors simulate user behavior using assistant language models (LMs) to create training data for the UserLM. This simulation is performed in two stages: the first turn and subsequent turns. For the first turn, a prompt template instructs the assistant LM to generate the initial user utterance based on the provided intent, mimicking a human user's natural start to a conversation. The prompt emphasizes realistic user behavior, such as making typos, using imperfect punctuation, and splitting information across turns, while avoiding overdoing these characteristics.

For subsequent turns, a different prompt template is used, which provides the conversation history up to the current point. The assistant LM is then instructed to generate the next user utterance, conditioned on the intent and the dialogue state. The prompt includes a specific instruction to respond with a special <|endconversation|> token if the conversation goal has been achieved, allowing the model to learn when to terminate the dialogue naturally.

To evaluate the model's adherence to its intended goal, the authors employ an LM-as-Judge approach. A prompt template is used to classify whether a user simulator's response in a conversation adheres to its original intent. The prompt provides the conversation history, including the user's initial question, the AI's refusal, and the user's reply, and instructs the judge model to classify the response as either "REFUSED" if it repeats the original question or "ACCEPTED" if it follows the AI's suggestion. This evaluation ensures that the UserLM maintains focus on its intended objective throughout the conversation.
Experiment
- UserLM-8b achieves the lowest perplexity (PPL) on both WildChat and PRISM datasets, with up to 60–70% lower PPL than baselines, demonstrating superior distributional alignment with human user language.
- Intent conditioning at test time improves PPL across all models, but training with intent leads to greater sensitivity and better performance, confirming the benefit of intent-conditioned training.
- UserLM-8b outperforms prompted assistants in multi-turn interaction: it generates more diverse first turns (94.55% unique 1-grams, near human level), decomposes intent more effectively (2.69% 1-gram overlap with intent), and achieves an F1 score of 63.54 in dialogue termination, compared to 3–15 for assistants.
- User LMs produce more natural utterances, with Pangram detecting 77–81% of their outputs as human-written (vs. 0–3% for prompted assistants), indicating a distinct, user-like text distribution.
- User LMs show high robustness in role and intent adherence (91–98% and 93–97%, respectively), while prompted assistants frequently revert to assistant behavior, especially under ambiguity.
- Scaling UserLM from 1b to 8b improves performance across all metrics, whereas scaling assistant LMs (e.g., Llama3-8b vs. 1b, GPT-4o vs. GPT-4o-mini) yields no consistent gains.
- In extrinsic simulations, UserLM-8b achieves higher intent coverage (76–86%), greater information and lexical diversity, and more variable conversational pace (2.1–6.7 turns), leading to a 17% drop in assistant task performance, indicating a more challenging and realistic evaluation environment.
The authors use perplexity (PPL) to evaluate how well models align with human language distributions in user utterances. Results show that UserLM-8b achieves the lowest PPL on both the WildChat and PRISM datasets, significantly outperforming all baseline models, especially in the out-of-domain PRISM set. This indicates that UserLM-8b is more effective at modeling user language and leveraging generic intents compared to base or instruction-tuned models.

The authors use UserLM-8b to simulate conversations with an assistant, demonstrating that it produces more diverse and realistic interactions compared to prompted assistant models. Results show that UserLM-8b achieves higher lexical diversity, greater turn variance, and more natural user behavior, leading to a 17% drop in assistant performance due to the more challenging simulation environment.

The authors use UserLM-8b trained from a base checkpoint to achieve the best performance across multiple metrics, outperforming both smaller models and models initialized from instruction-tuned checkpoints. Results show that UserLM-8b achieves the highest scores in multi-turn interaction and simulation robustness, particularly in intent decomposition, dialogue termination, and role adherence, indicating superior alignment with human user behavior.

Results show that UserLM-8b achieves lower intent coverage compared to GPT-4o and 4o-mini in both math and code tasks, but it exhibits significantly higher information diversity, pace diversity, and lexical diversity. UserLM-8b also leads to lower assistant performance, indicating that its more realistic and varied user behavior creates a more challenging environment for the assistant.

The authors use perplexity (PPL) to evaluate how well models align with human language distributions in user utterances. Results show that UserLM-8b achieves significantly lower PPL than other models, especially when both train-time and test-time intent conditioning are applied, indicating superior distributional alignment. Additionally, models trained from base checkpoints consistently outperform those trained from instruction-tuned checkpoints, with UserLM-8b trained from a base model achieving the lowest PPL of 7.42.
