Command Palette
Search for a command to run...
Fun-ASR-Technischer Bericht
Fun-ASR-Technischer Bericht
Zusammenfassung
In den letzten Jahren hat die automatische Spracherkennung (ASR) durch drei komplementäre Ansätze transformative Fortschritte erzielt: Skalierung der Daten, Skalierung der Modellgröße sowie tiefe Integration mit großen Sprachmodellen (LLMs). Allerdings sind LLMs anfällig für Halluzinationen, was die Benutzererfahrung in realen ASR-Anwendungen erheblich beeinträchtigen kann. In diesem Artikel stellen wir Fun-ASR vor, ein großskaliges, auf LLMs basierendes ASR-System, das massive Datenmengen, große Modellkapazität, die Integration von LLMs sowie Verstärkungslernen synergistisch kombiniert, um eine state-of-the-art-Leistung in vielfältigen und komplexen Spracherkennungsszenarien zu erreichen. Darüber hinaus wurde Fun-ASR speziell für die praktische Anwendung optimiert und weist Verbesserungen in Bezug auf Streaming-Fähigkeit, Robustheit gegenüber Geräuschen, Code-Switching, Hotword-Anpassung sowie die Erfüllung weiterer Anforderungen realer Anwendungsfälle auf. Experimentelle Ergebnisse zeigen, dass die meisten auf LLMs basierenden ASR-Systeme zwar auf offenen Benchmarks starke Leistungen erzielen, jedoch oft auf realen Industrie-Evaluierungssätzen unterdurchschnittlich abschneiden. Durch produktionsoptimierte Ansätze erreicht Fun-ASR hingegen state-of-the-art-Ergebnisse auf realen Anwendungsdatensätzen und demonstriert damit seine Effektivität und Robustheit in praktischen Umgebungen. Der Quellcode und die Modelle sind unter https://github.com/FunAudioLLM/Fun-ASR verfügbar.
One-sentence Summary
The Tongyi Fun Team at Alibaba Group proposes Fun-ASR, an LLM-based ASR system combining massive data, large models, and reinforcement learning to combat hallucination and boost real-world performance in streaming, noisy, and code-switching scenarios, outperforming prior systems on industry benchmarks.
Key Contributions
- Fun-ASR addresses the hallucination risk of LLMs in ASR by combining massive data, large-scale model capacity, and reinforcement learning to deliver robust, accurate transcriptions across complex real-world speech scenarios.
- The system introduces production-focused optimizations including streaming support, noise robustness, code-switching between Chinese and English, and customizable hotword recognition, tailored for industrial deployment needs.
- Evaluated on real industry datasets—not just open-source benchmarks—Fun-ASR achieves state-of-the-art performance, proving its superiority in practical applications where most LLM-based ASR systems underperform.
Introduction
The authors leverage massive data, large model capacity, and deep LLM integration to build Fun-ASR, a production-ready automatic speech recognition system that addresses the gap between academic benchmarks and real-world performance. While prior LLM-based ASR models often suffer from hallucination and underperform on industry datasets, Fun-ASR incorporates reinforcement learning and practical optimizations—including streaming support, noise robustness, code-switching, and hotword customization—to deliver state-of-the-art accuracy in complex, real-world scenarios. Their main contribution is a deployable system that not only achieves top-tier recognition metrics but also meets stringent industrial requirements for latency, reliability, and domain adaptability.
Dataset
-
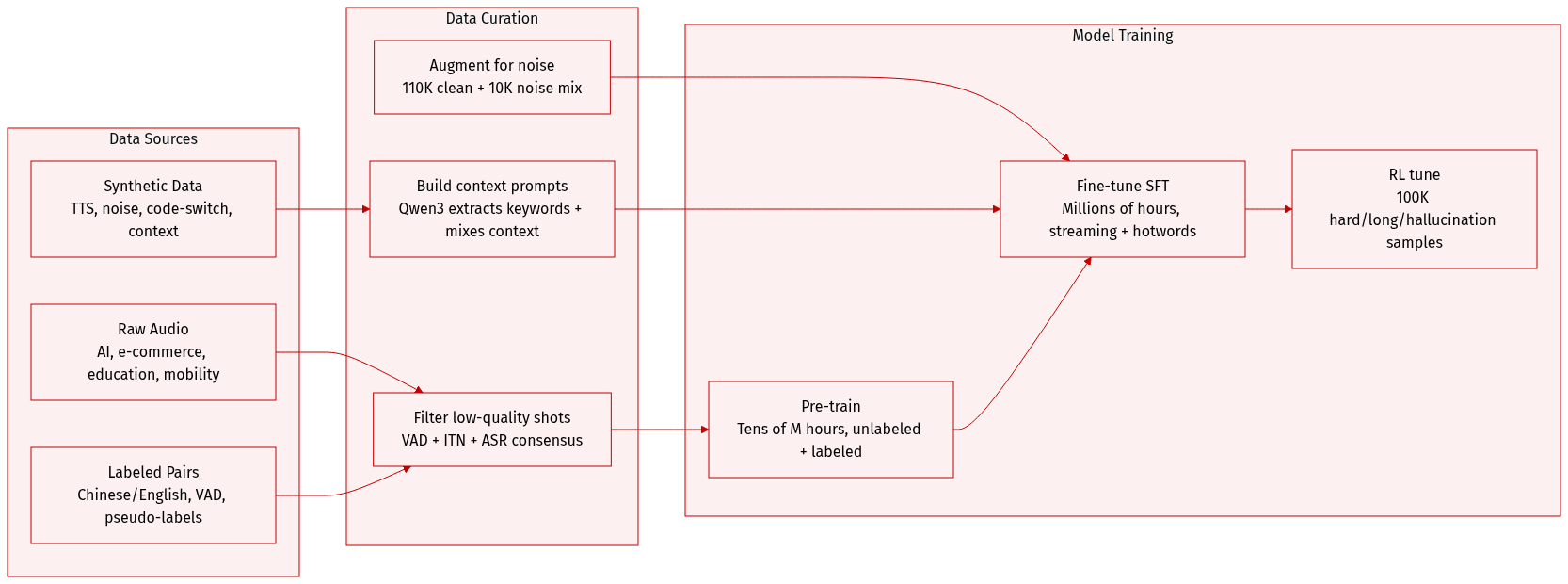
The authors use a massive pre-training dataset spanning tens of millions of hours, combining unlabeled real-world audio (from domains like AI, e-commerce, education, and mobility) with labeled audio-text pairs. Labeled data undergoes a pipeline including voice activity detection, pseudo-labeling via multiple ASR systems (Paraformer-V2, Whisper, SenseVoice), and inverse text normalization. Primary languages are Chinese and English.
-
For supervised fine-tuning (SFT), they assemble millions of hours from human-transcribed, pseudo-labeled, environmental noise, TTS-synthesized (CosyVoice3), simulated streaming, noise-augmented, and hotword-customized data.
-
To boost contextual modeling, they extend SFT with long-form audio (up to 5 minutes). Longer samples are segmented, with prior transcripts prepended as prompts. They synthesize over 50K hours of contextual data using Qwen3-32B: extracting keywords, generating relevant context, and mixing in irrelevant context to prevent over-reliance.
-
RL training data (100K samples) is curated from five subsets: hard cases (where Fun-ASR diverges from other ASRs), long-duration clips (>20s), hallucination-related samples, keyword/hotword utterances, and regular ASR data to prevent forgetting. Each subset contains 20K samples.
-
For streaming performance, they transform offline data into incremental, chunked inputs that mimic real-time decoding, blending this with existing offline data to reduce training-inference mismatch.
-
Noise robustness is addressed via large-scale augmentation: 110K hours of clean speech mixed with 10K hours of noise (avg SNR 10 dB, std 5 dB). 30% of speech undergoes online noise mixing during training, yielding ~13% relative improvement on complex-noise benchmarks.
-
Multilingual support (Fun-ASR-ML) covers 31 languages, trained on ~500K hours. Data is rebalanced: Chinese/English downsampled, other languages upsampled. Training follows the same method as the Chinese-English model.
-
Code-switching data is synthesized: 40K+ English phrases are used to prompt Qwen3 to generate Chinese-English code-switched text, which is then converted to speech via TTS for training.
-
Evaluation uses open-source benchmarks (AIShell-1/2, Librispeech, Fleurs, WeNetSpeech, Gigaspeech2) and a leakage-free custom test set from post-June 30 YouTube/Bilibili videos. Noise robustness is tested on real-world audio from 11 environments (canteen, street, subway, etc.), categorized by acoustics and topic.
Method
The authors leverage a modular, multi-stage architecture for Fun-ASR, designed to integrate speech representation learning with large language model (LLM) decoding while supporting efficient inference and customization. The overall framework, as shown in the figure below, comprises four core components: an audio encoder, an audio adaptor, a CTC decoder, and an LLM-based decoder.
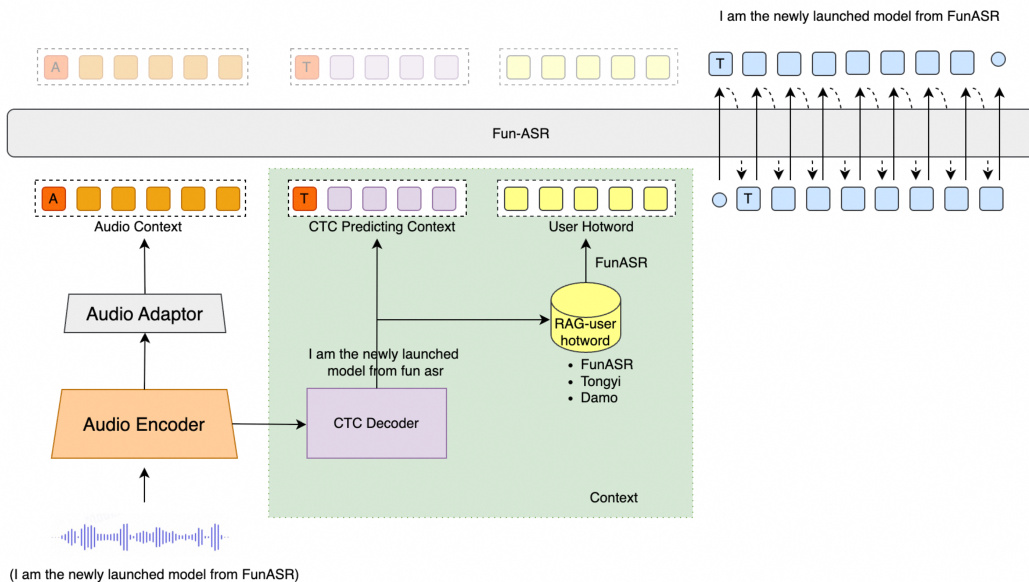
The audio encoder, implemented as a multi-layer transformer, processes raw speech input to extract high-level acoustic representations. These representations are then passed through a two-layer transformer-based audio adaptor, which aligns the acoustic features with the semantic space of the LLM. The CTC decoder, built atop the audio encoder, generates an initial recognition hypothesis via greedy search. This hypothesis serves dual purposes: it provides a starting point for the LLM decoder and enables retrieval-augmented generation (RAG) for hotword customization. The LLM-based decoder, conditioned on both the audio context and the CTC prediction, produces the final transcription. Two model variants are proposed: Fun-ASR (0.7B audio encoder + 7B LLM) for high accuracy, and Fun-ASR-nano (0.2B + 0.6B) for resource-constrained environments.
To ensure the audio encoder is robust and semantically aligned with the LLM, the authors adopt a two-stage pre-training pipeline. As shown in the figure below, Stage 1 employs the Best-RQ framework for self-supervised learning, initialized with weights from a pre-trained text LLM (Qwen3), enabling the model to learn general speech representations from unlabeled data. Stage 2 performs supervised pre-training within an attention-based encoder-decoder (AED) framework using large-scale labeled ASR datasets, refining the encoder to capture rich acoustic-linguistic features.

Supervised fine-tuning proceeds in five sequential stages. Stage 1 freezes the audio encoder and LLM while training the adaptor to align representations. Stage 2 unfreezes the encoder and trains it alongside the adaptor using low-cost ASR data. Stage 3 freezes the encoder and adaptor and applies LoRA to fine-tune the LLM, preserving its text generation capabilities. Stage 4 performs full-parameter fine-tuning on the encoder and adaptor while continuing LoRA on the LLM, using only high-quality, multi-model-verified transcriptions. Stage 5 adds and trains the CTC decoder atop the frozen encoder to generate the initial hypothesis for RAG-based hotword retrieval.
For reinforcement learning, the authors introduce FunRL, a scalable framework tailored for large audio-language models. As depicted in the figure below, FunRL orchestrates the audio encoder, rollout, and policy modules using Ray to alternate GPU usage efficiently. The audio encoder processes batches of input audio to extract embeddings, which are then transferred to CPU. The SGLang-based LLM rollout generates multiple hypotheses, each assigned a reward via a rule-based value function. The FSDP-based policy model then computes output probabilities and performs policy optimization via RL, with the updated policy synchronized back to the rollout module to maintain on-policy training.
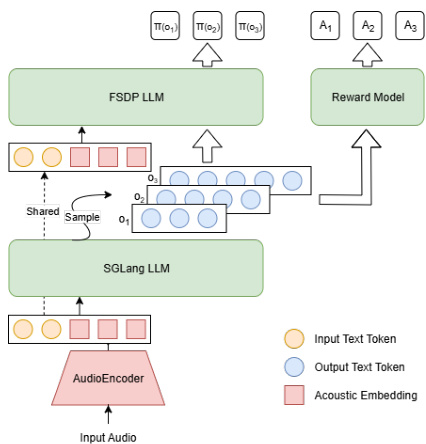
The RL algorithm is based on GRPO, which generates a group of responses {oi}i=1G and assigns each a reward Ri using a composite value function. The advantage A^i,t is computed as:
A^i,t=std({Rj}i=1G)Ri−mean({Rj}j=1G)The policy is optimized using a clipped objective with a KL penalty:
LGRPO(θ)=G1i=1∑G∣oi∣1t=1∑∣oi∣min(ri,t(θ)A^i,t,clip(ri,t(θ),1−ε,1+ε)A^i,t)−βDKL(πθ∣∣πref)where
ri,t(θ)=πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t).The value function combines multiple components: ASR accuracy (1−WER), keyword precision and recall, noise robustness and hallucination suppression via regex-based penalties, and language match enforcement. These rules collectively enhance both recognition quality and user experience, particularly on challenging cases.
To mitigate hallucination, the authors augment training data with zero-padded noise segments, teaching the model to recognize non-speech inputs and suppress spurious outputs. For hotword customization, a RAG mechanism retrieves candidates from a phoneme- or word-piece-based vocabulary using edit distance against the CTC hypothesis, then injects them into the LLM context to bias output toward user-specified terms.
Experiment
- Fun-ASR achieves state-of-the-art performance on both open-source benchmarks and real-world industry datasets, outperforming both open-source models and commercial APIs, especially in noisy conditions.
- Fun-ASR-nano, with only 0.8B parameters, closely matches larger models like Seed-ASR, demonstrating strong efficiency.
- Streaming ASR performance exceeds Seed-ASR across multiple test scenarios, confirming robust real-time capabilities.
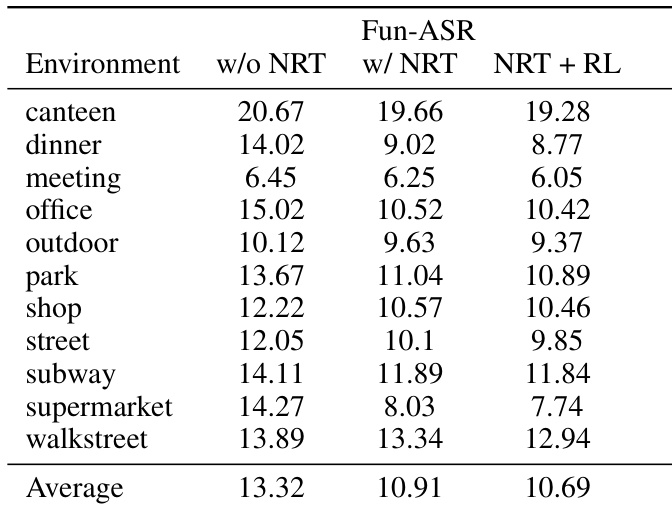
- Noise robust training significantly improves performance in challenging environments (e.g., dinner, supermarket), with over 30% relative gains; reinforcement learning further enhances noise resilience.
- Code-switching evaluation confirms effectiveness of training data construction, with strong WER results on mixed Chinese-English test sets.
- Hotword customization substantially improves recall, especially for technical terms and names, with RL enabling better keyword recognition beyond prompt context.
- Multilingual Fun-ASR-ML and Fun-ASR-ML-Nano outperform or match leading models like Whisper and Kimi-Audio across Chinese and English test sets.
- Reinforcement learning consistently boosts performance—4.1% offline and 9.2% streaming gains—while reducing insertion/deletion errors and improving hotword integration, even for unseen domain terms.
- Current limitations include focus on Chinese/English, limited context window, and lack of far-field or multi-channel support—planned for future improvement.
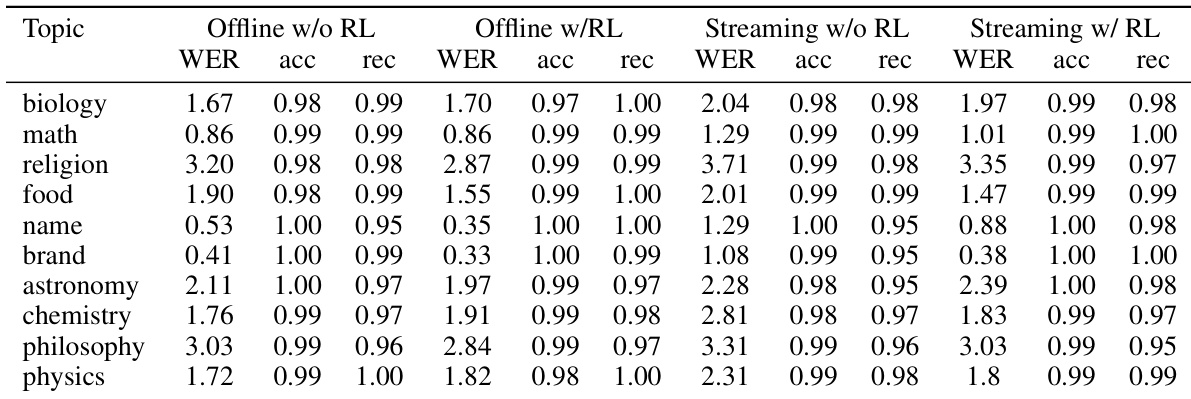
The authors evaluate Fun-ASR’s hotword customization performance across multiple technical domains, showing that reinforcement learning consistently improves recall and accuracy, especially for challenging topics like names and biology. Results indicate that RL enables the model to better recognize domain-specific terms even when they are not explicitly listed as hotwords, reducing word error rates across both offline and streaming settings. While minor trade-offs appear in some domains like philosophy, the overall recognition performance still improves with RL.
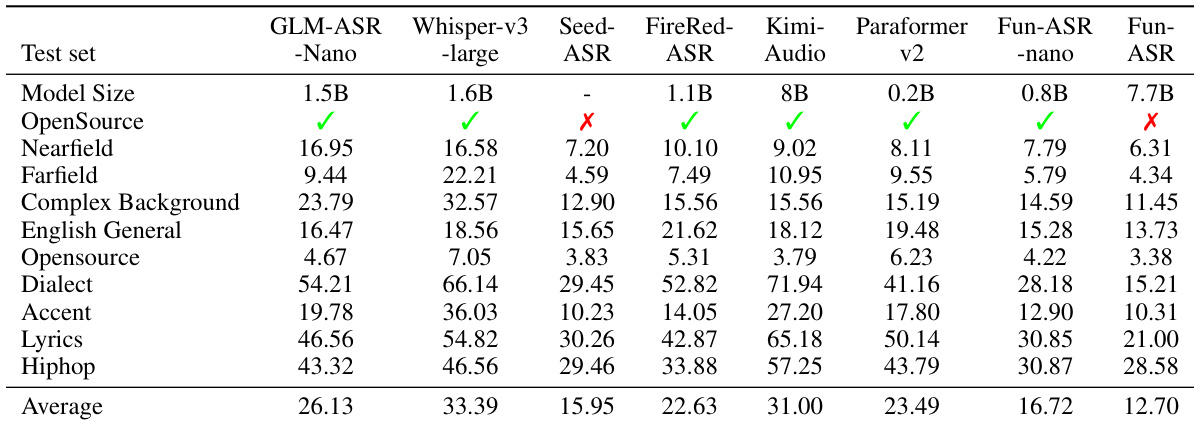
The authors evaluate multiple ASR models across diverse test conditions, including nearfield, farfield, complex background, and domain-specific scenarios. Results show that Fun-ASR consistently achieves the lowest average WER, outperforming both open-source and commercial models, particularly in challenging acoustic environments. The model’s strong performance across varied conditions highlights its robustness and adaptability for real-world deployment.
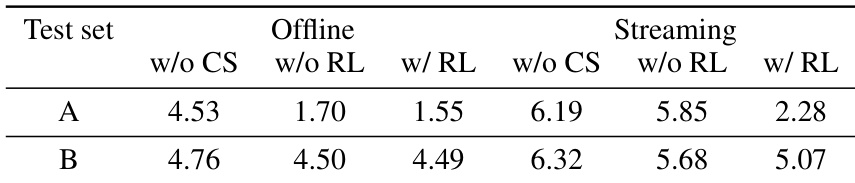
The authors evaluate the impact of reinforcement learning (RL) and code-switching (CS) training on ASR performance across two test sets, showing that RL consistently reduces WER in both offline and streaming modes. Results indicate that RL provides more substantial gains than CS, particularly in streaming scenarios, and that combining both techniques yields the best overall performance. The improvements suggest RL helps the model better handle sequential prediction challenges and reduce errors in real-time decoding.
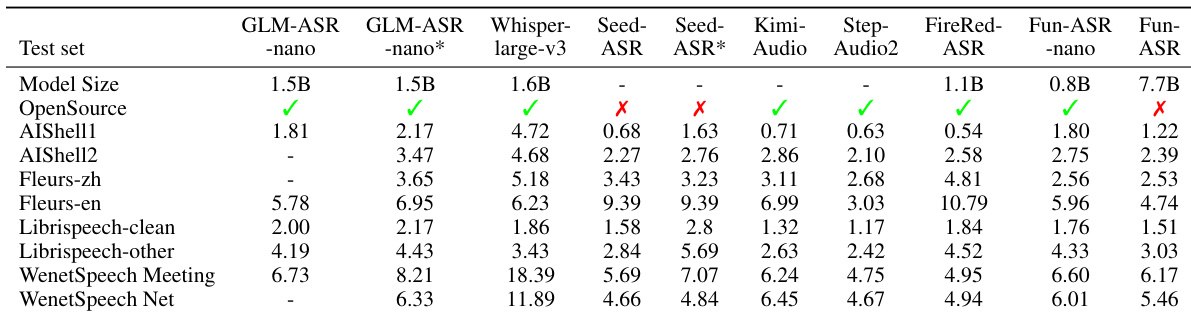
The authors evaluate multiple ASR models on open-source benchmarks, finding that while some open-source systems achieve low WER, their performance does not consistently translate to real-world industrial datasets. Fun-ASR outperforms both open-source and commercial models across these evaluations, with Fun-ASR-nano delivering competitive results despite its smaller parameter count. Results confirm that evaluation on open-source data alone may not reflect real-world robustness, underscoring the need for updated, industry-relevant test sets.
The authors evaluate Fun-ASR under various noisy environments, showing that noise robust training significantly reduces word error rates, especially in challenging settings like dinner and supermarket scenes. Adding reinforcement learning further improves performance in most conditions, though it slightly increases error in a few cases like walkstreet. Results confirm that combining noise robust training with reinforcement learning yields the best overall noise robustness.