Command Palette
Search for a command to run...
Kleine Modelle, große Ergebnisse: Erreichung überlegener Absichtserkennung durch Zerlegung
Kleine Modelle, große Ergebnisse: Erreichung überlegener Absichtserkennung durch Zerlegung
Danielle Cohen Yoni Halpern Noam Kahlon Joel Oren Omri Berkovitch Sapir Caduri Ido Dagan Anatoly Efros
Zusammenfassung
Die Erkennung von Nutzerabsichten aus Interaktionsverläufen in Benutzeroberflächen bleibt eine herausfordernde, dennoch entscheidende Herausforderung bei der Entwicklung intelligenter Agenten. Während große, datenzentrische, mehrmodale Großmodelle (MLLMs) über eine größere Kapazität verfügen, um die Komplexität solcher Sequenzen zu bewältigen, leiden kleinere Modelle, die lokal auf Geräten laufen und somit eine datenschutzfreundliche, kostengünstige und latenzarme Benutzererfahrung ermöglichen, an einer ungenauen Absichtserkennung. Wir adressieren diese Limitationen durch die Einführung eines neuen, dekomponierten Ansatzes: Zunächst führen wir eine strukturierte Zusammenfassung der Interaktionen durch, um wesentliche Informationen aus jeder Nutzeraktion zu erfassen. Anschließend extrahieren wir die Absicht mittels eines feinabgestimmten Modells, das auf den aggregierten Zusammenfassungen operiert. Dieser Ansatz verbessert die Absichtserkennung in ressourcenbeschränkten Modellen und übertrifft sogar die Basisleistung großer MLLMs.
One-sentence Summary
Researchers from Google and Bar-Ilan University propose a decomposed method—structured summarization followed by intent extraction—that enables small on-device models to outperform large multimodal LLMs in inferring user intent from UI trajectories, enhancing privacy, cost-efficiency, and latency for intelligent agents.
Key Contributions
- We introduce a two-stage decomposition for user intent extraction from UI trajectories, first summarizing each interaction structurally and then aggregating summaries for intent prediction, enabling smaller on-device models to outperform larger MLLMs despite resource constraints.
- Our method leverages both visual screen context and action strings in the summarization stage, and employs fine-tuned models in the intent extraction stage, offering robustness to noisy data and modularity for engineering evaluation and iterative improvement.
- Evaluated on public UI automation datasets using semantic equivalence metrics, our approach consistently surpasses baseline large MLLMs and smaller models across multiple model architectures and input representations, validating its generalizability and effectiveness.
Introduction
The authors leverage a two-stage decomposition to boost intent extraction from UI interaction sequences using small, on-device models—critical for privacy, cost, and latency-sensitive applications like mobile assistants. Prior work either relied on large multi-modal LLMs that can’t run locally or used coarse prompting or fine-tuning that struggled with context length and noisy data. Their approach first summarizes each interaction into structured, screen-aware snippets, then aggregates them for intent generation—outperforming both small models and large MLLMs on semantic metrics while handling noisy inputs and enabling modular engineering.
Dataset

The authors use two UI interaction datasets—Mind2Web and AndroidControl—to train and evaluate intent extraction models. Here’s how they’re composed, processed, and applied:
-
Dataset Sources and Composition
- Mind2Web (CC BY 4.0): 2,350 human trajectories across websites, avg. 7.3 steps each. Each includes screenshots, actions, and a high-level task description. Includes validation step to align trajectories with intent, yielding cleaner labels.
- AndroidControl (Apache 2.0): 15,283 human trajectories on Android apps, avg. 5.5 steps each. Includes screenshots, actions, and goal descriptions. Lacks validation step, leading to noisier labels (e.g., goals like “delete emails from X” when none exist).
-
Key Subset Details
- Mind2Web: Train/test split follows original; test set reduced from 1005 to 681 examples for Gemini experiments due to domain filtering per Google policy.
- AndroidControl: No domain filtering; labels cleaned via Gemini 1.5 Pro prompts to remove irrelevant info (e.g., “I’m hungry, order pizza”), though ~30% still require manual correction.
-
Processing and Metadata Construction
- Screenshots: Mind2Web cropped to 1280×768 around interaction bounding box with random margins, then resized. AndroidControl resized directly (1080×2400) with red bounding box overlay.
- Actions: Mind2Web actions used as-is (e.g., “[element] click”). AndroidControl actions mapped via accessibility tree to element names.
- Goal Labels: Platform-specific names (e.g., app/website names) separated from core intent via “app-name; intent” format to prevent evaluation bias. Labels cleaned to remove non-inferable details.
-
Model Usage
- Models fine-tuned on train splits; test results reported on original test sets.
- For Qwen2 VL 7B: Trajectories limited to 15 steps; AndroidControl images downsized 4x.
- Gemini 1.5 Pro used for label cleaning; Gemini 1.5 Flash 8B and Qwen2 VL 7B used as fine-tunable baselines.
-
Limitations Noted
- Datasets skewed toward English, U.S.-centric interactions; lack multi-app or adaptive goal behavior. Mind2Web restricted to single websites; AndroidControl lacks real-time goal evolution. Generalizability limited to web/Android platforms.
Method
The authors leverage a decomposed two-stage model to address the limitations of both chain-of-thought (CoT) prompting and fine-tuned small language models when processing full user trajectories. This approach emulates the CoT process by first generating interaction-level summaries and then aggregating them into a session-level intent. The overall framework is illustrated in the figure below, where the first stage processes individual interactions using a prompt-based method, and the second stage employs fine-tuning to synthesize the summaries into a coherent overall intent.

In the first stage, the model summarizes each individual user interaction Ii={Oi,Ai} within a trajectory T=(I1,…,In), using both visual and textual information to extract relevant context and actions. The summarization process is entirely prompt-based, as no labeled training data exists for interaction-level summaries. To enhance the model's ability to resolve ambiguities, the input includes not only the current interaction Ii but also the preceding and succeeding interactions, Ii−1 and Ii+1, respectively. This extended context enables the model to better interpret the user's actions by leveraging visual cues from adjacent screenshots. The output of this stage is a structured summary consisting of two components: (a) a list of salient details from the current screen Oi, and (b) a list of mid-level actions performed by the user. Additionally, a third field labeled "speculative intent" is included to capture the model's interpretations of the user's underlying goals, which are discarded before the next stage. This structured format mitigates the issues observed with alternative prompting strategies, such as overly concise summaries or excessive speculation, thereby improving the quality of the input for the subsequent aggregation stage.
In the second stage, the model aggregates the interaction-level summaries to infer the user's overall intent. This stage is implemented through fine-tuning, where the input consists of the summaries from all interactions in the trajectory, and the target is the corresponding ground truth intent description. The training data is constructed such that the target intents are refined to exclude details not present in the input summaries, ensuring the model learns to infer intents solely from the provided information. This refinement process is performed using a large language model, as detailed in the prompt shown in the figure below. The fine-tuned model is designed to avoid embellishing or hallucinating details, thereby producing more accurate and grounded intent descriptions. A fully prompt-based variation, which does not involve fine-tuning, is also evaluated as part of the ablation study.
Experiment
- Evaluated intent extraction using BiFact (fact-level comparison) and T5 NLI (holistic entailment), finding BiFact more suitable for multi-component intents.
- On Mind2Web, Gemini Flash 8B with decomposed fine-tuning outperformed Gemini 1.5 Pro CoT (BiFact F1), while on AndroidControl, performance was comparable across models.
- Human raters preferred decomposed fine-tuning over CoT in 12 of 20 Mind2Web cases, confirming qualitative advantage.
- Expert annotations revealed dataset label noise; decomposed fine-tuning improved performance against expert labels, unlike E2E-FT which suffered from noisy training data.
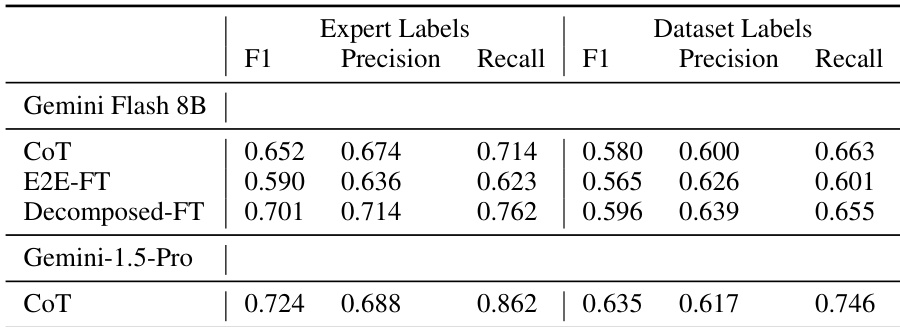
- Ablation studies showed key contributions: context from adjacent interactions (↑ recall), structured summaries (↑ precision/recall), fine-tuning (↑ precision), and label refinement (↑ precision).
- Error analysis identified main failures in interaction summarization (omissions, hallucinations, screen misinterpretation) and intent extraction omissions.
- Error propagation analysis: each stage (summarization, intent extraction) contributed ~16–18% recall loss; hallucinations were low (8%) due to label refinement.
- Decomposed FT incurred 2–3x cost over small-model baselines but remained cheaper than large models (e.g., Gemini 1.5 Pro); a latency-optimized variant avoided extra calls without quality loss.
- Decomposed FT generalized better than CoT or E2E-FT on unseen domains, tasks, and websites, surpassing even Gemini 1.5 Pro CoT in most generalization categories.
- Results were robust across evaluation LLMs (Gemini Pro vs. Flash used in BiFact), confirming validity of conclusions.
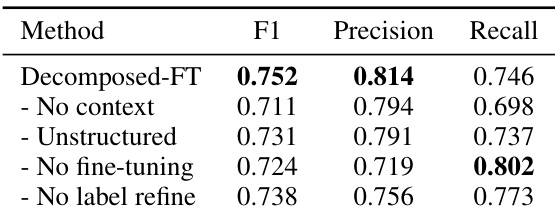
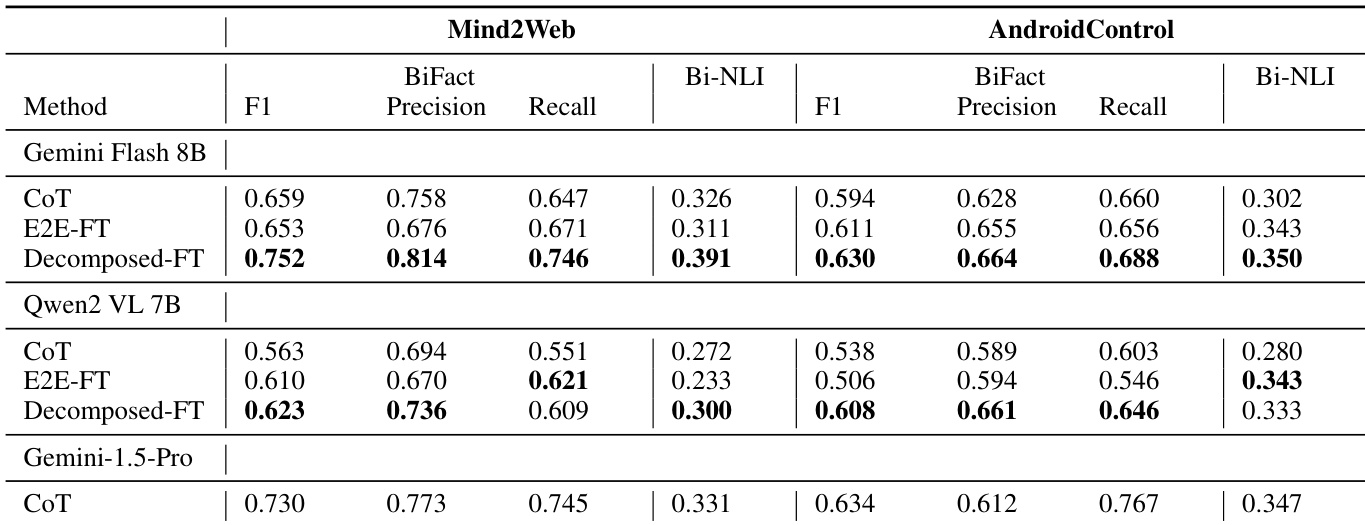
The authors use BiFact and Bi-NLI metrics to evaluate intent extraction performance on Mind2Web and AndroidControl datasets. Results show that the Decomposed-FT method achieves the highest BiFact F1 and recall scores on both datasets, outperforming CoT and E2E-FT baselines, with the best performance observed on Mind2Web.
The authors use BiFact and Bi-NLI metrics to evaluate intent extraction performance on Mind2Web and AndroidControl datasets. Results show that the decomposed approach with fine-tuning (Decomposed-FT) outperforms both CoT and non-finetuned variants, achieving higher F1 and recall scores across models and datasets, with the Gemini Flash 8B model achieving the best results on Mind2Web and the Gemini-1.5-Pro model excelling on AndroidControl.
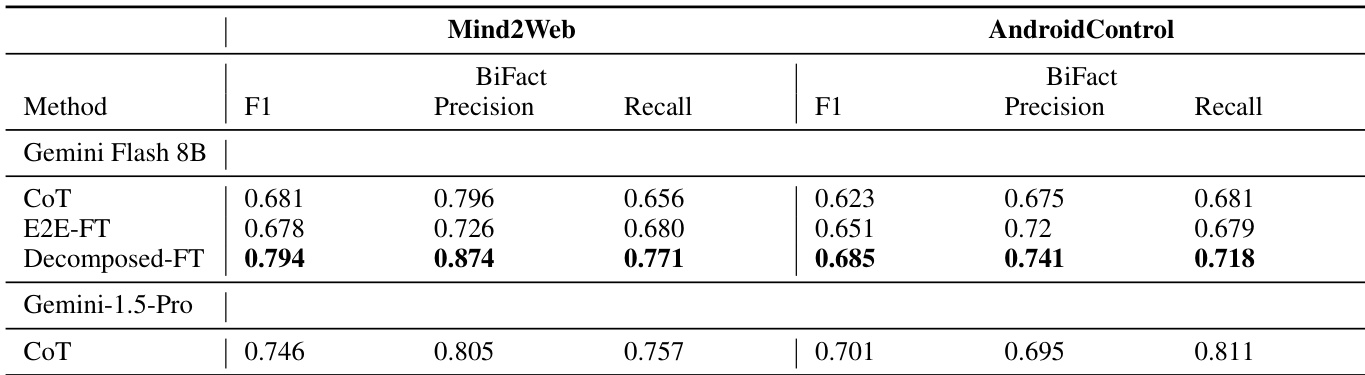
The authors compare the performance of different intent extraction methods on the AndroidControl dataset using expert annotations and dataset labels as ground truth. Results show that the Decomposed-FT model achieves higher BiFact F1 scores than CoT and E2E-FT when evaluated against expert labels, indicating improved alignment with human-verified intents, while the performance gap is smaller when using noisy dataset labels.
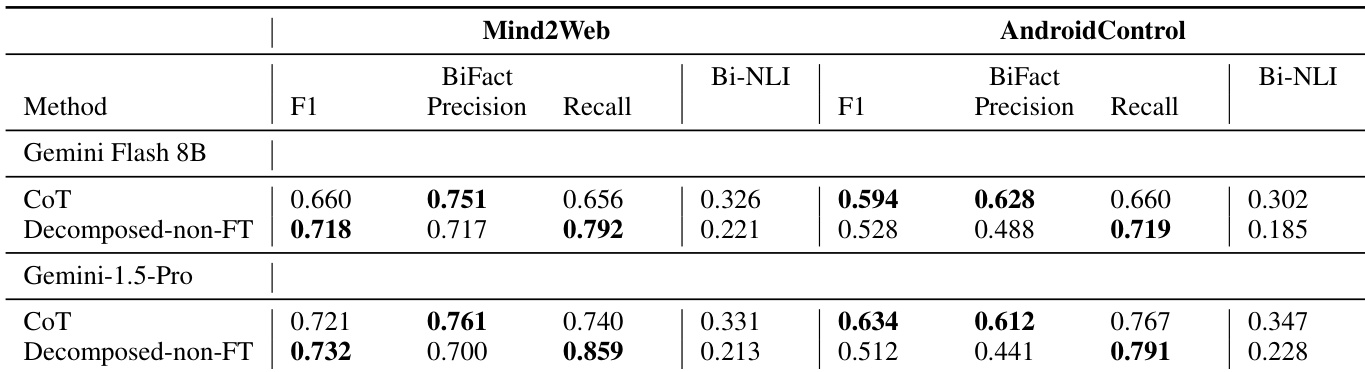
The authors evaluate their decomposed intent extraction method against baselines on two datasets using multiple models, showing that the Decomposed-FT approach achieves higher BiFact F1 and Bi-NLI scores than CoT and E2E-FT across all models and datasets. On Mind2Web, the fine-tuned decomposed method with Gemini Flash 8B outperforms the larger Gemini 1.5 Pro model using CoT, while on AndroidControl, the performance is comparable across methods.
The authors use an ablation study to evaluate the impact of key design choices in their decomposed intent extraction method. Results show that removing label refinement leads to a significant drop in precision, while removing fine-tuning causes a notable decrease in precision and a slight increase in recall, indicating the importance of both components for balanced performance.