Command Palette
Search for a command to run...
HunyuanVideo-Foley: Multimodale Diffusion mit Repräsentationsausrichtung für die Generierung hochwertiger Foley-Audio
HunyuanVideo-Foley: Multimodale Diffusion mit Repräsentationsausrichtung für die Generierung hochwertiger Foley-Audio
Sizhe Shan Qiulin Li Yutao Cui Miles Yang Yuehai Wang Qun Yang Jin Zhou Zhao Zhong
Zusammenfassung
Neuere Fortschritte in der Videogenerierung erzeugen visuell realistische Inhalte, doch die fehlende Synchronisation von Audio beeinträchtigt die Immersion erheblich. Um zentrale Herausforderungen bei der Video-zu-Audio-Generierung anzugehen – insbesondere die Knappheit multimodaler Daten, die Ungleichgewichtigkeit zwischen Modalitäten sowie die begrenzte Audioqualität bestehender Ansätze – stellen wir HunyuanVideo-Foley vor, einen end-to-end-Frame-Text-Video-zu-Audio-Framework, der hochauflösende, präzise mit visuellen Dynamiken und semantischen Kontexten synchronisierte Audioinhalte synthetisiert. Unser Ansatz integriert drei zentrale Innovationen: (1) eine skalierbare Datenpipeline, die über automatisierte Annotation 100.000 Stunden multimodale Datensätze konsolidiert; (2) eine Darstellungsausrichtungsstrategie, die selbstüberwachte Audio-Features nutzt, um den latenten Diffusionsprozess zu leiten und somit die Audioqualität und Stabilität der Generierung effizient zu verbessern; (3) einen neuartigen multimodalen Diffusions-Transformer, der Modalitätenkonkurrenz bewältigt, durch gemeinsame Aufmerksamkeit eine Dual-Stream-Audio-Video-Fusion ermöglicht und über Kreuzaufmerksamkeit semantische Textinformationen integriert. Umfassende Evaluationen zeigen, dass HunyuanVideo-Foley neue Sollwertleistungen in Bezug auf Audio-Fidelität, visuelle-Semantik-Ausrichtung, zeitliche Synchronisation sowie Verteilungsübereinstimmung erzielt. Die Demo-Seite ist unter https://szczesnys.github.io/hunyuanvideo-foley/ verfügbar.
One-sentence Summary
Researchers from Tencent Hunyuan, Zhejiang University, and Nanjing University of Aeronautics and Astronautics propose HunyuanVideo-Foley, an end-to-end text-video-to-audio framework that generates high-fidelity, temporally aligned audio via multimodal diffusion transformers and self-supervised alignment, overcoming data scarcity and modality imbalance to enhance immersive video experiences.
Key Contributions
- We introduce a scalable data pipeline that automatically curates a 100k-hour text-video-audio dataset, addressing multimodal scarcity and enabling robust training for video-to-audio synthesis.
- Our Representation Alignment (REPA) loss leverages self-supervised audio features to guide latent diffusion training, improving audio fidelity and generation stability without requiring manual annotations.
- HunyuanVideo-Foley employs a novel multimodal diffusion transformer with dual-stream fusion and cross-attention injection, resolving modality imbalance and achieving state-of-the-art alignment and quality across audio, visual, and textual semantics.
Introduction
The authors leverage recent advances in video generation to tackle the critical gap in synchronized audio, which limits immersion in synthetic media. Prior work in text-to-audio and video-to-audio generation suffers from limited multimodal data, modality imbalance favoring text over visual cues, and subpar audio fidelity that fails professional standards. HunyuanVideo-Foley introduces three key innovations: a scalable 100k-hour multimodal dataset pipeline, a representation alignment loss using self-supervised audio features to boost quality and stability, and a novel multimodal diffusion transformer that balances video-text-audio interactions via dual-stream fusion and cross-attention. The result is state-of-the-art performance in audio fidelity, temporal precision, and semantic alignment with both visual and textual inputs.
Dataset

The authors use a custom-built TV2A dataset to support multimodal audio generation, addressing the lack of high-quality, large-scale open-source data for text-video-audio tasks. Key details:
-
Dataset Composition & Sources:
Built from raw video databases via a multi-stage filtering pipeline. Final dataset contains ~100k hours of text-video-audio material. -
Subset Details & Filtering Rules:
- Videos without audio streams are removed.
- Remaining videos are segmented into 8-second chunks using scene detection.
- Chunks with >80% silence are discarded.
- Only audio with sampling rates >32 kHz is retained to ensure fidelity.
- Audio quality is assessed via AudioBox-aesthetic-toolkit and SNR metrics; low-quality or noisy segments are filtered out.
- Semantic and temporal audio-video alignment is verified using ImageBind and AV-align.
- Segments are annotated with speech/music labels and audio categories for balanced training.
- Audio captions are generated per segment using GenAU for descriptive grounding.
-
Usage in Model Training:
The filtered, annotated, and captioned segments are used as training data. No explicit mixture ratios are mentioned, but category balancing is enforced via annotations. -
Processing & Metadata:
Cropping is done via 8-second fixed-length chunks. Metadata includes audio category tags, alignment scores, quality metrics, and generated captions—enabling structured training and evaluation.
Method
The authors leverage a hybrid transformer architecture—HunyuanVideo-Foley—to achieve modality-balanced, temporally coherent text-to-video-to-audio (TV2A) generation. The framework is structured into two distinct phases: an initial multimodal stage comprising N1 transformer blocks that jointly process visual, textual, and audio latent representations, followed by N2 unimodal transformer blocks dedicated exclusively to refining the audio stream. This design enables the model to first establish cross-modal alignment and then focus on high-fidelity audio synthesis.
As shown in the figure below, the input modalities are encoded independently: text is processed via a CLAP encoder, video frames through a SigLIP-2 visual encoder, and raw audio via a DAC-VAE encoder that compresses waveforms into continuous latent representations. These latents are perturbed with additive Gaussian noise to support a flow-matching diffusion objective. Synchronization features, extracted from a Synchformer visual encoder, provide frame-level temporal alignment signals that dynamically modulate the transformer blocks.
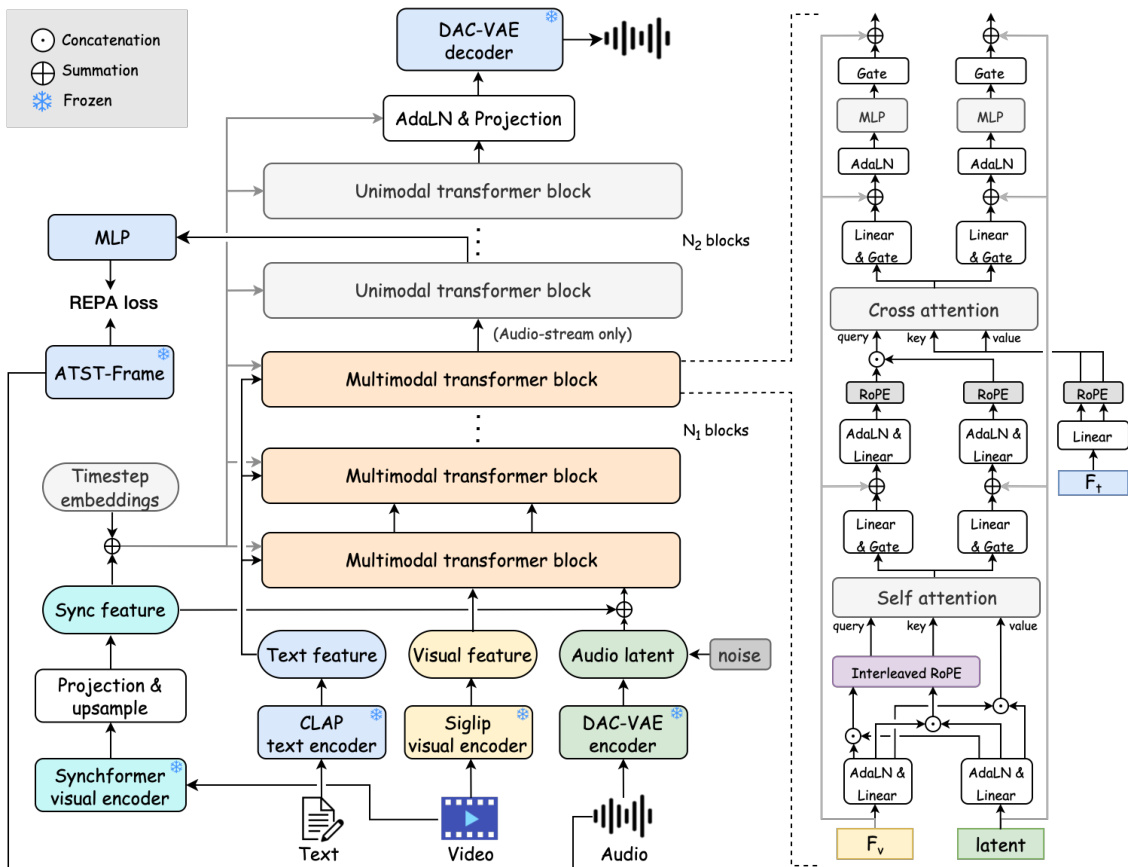
A key innovation lies in the dual-phase attention mechanism within the multimodal blocks. In self-attention, audio and visual latents are concatenated into a unified sequence after being interleaved temporally via an interleaved RoPE strategy. This ensures that adjacent audio and visual tokens receive consecutive positional embeddings, thereby enhancing the model’s ability to capture fine-grained temporal correlations. The fused sequence is then split into parallel streams, each processed through linear projections and gated by adaptive layer normalization (adaLN) layers conditioned on synchronization features and timestep embeddings. In cross-attention, the concatenated audio-visual sequence serves as the query, while CLAP-derived text embeddings provide key and value, enabling global semantic guidance without disrupting temporal structure.
The conditioning signal c is derived from the sum of synchronization features csync and timestep embeddings ct. This composite signal is passed through parallel MLPs to generate modulation parameters α, β, and gate g, which are applied to normalize and gate intermediate features. The modulated output is integrated via residual connections, ensuring stable propagation of temporal coherence across layers.
To further enhance audio fidelity, the authors introduce the REPA loss, which aligns intermediate hidden states from the diffusion transformer with frame-level audio representations extracted by a pre-trained ATST-Frame encoder. The alignment is computed via cosine similarity between mapped latents H=MLP(h) and reference features Fr, encouraging the model to preserve semantic and acoustic structure during generation. This loss is computed at multiple layers and backpropagated to refine the audio stream before decoding via the DAC-VAE decoder.
The training pipeline is supported by a scalable data curation system that filters video-audio pairs based on audio-visual alignment (via ImageBind and AV-align) and audio quality (via AudioBox-aesthetic and SNR metrics). Bandwidth tagging is employed to condition the model on sampling rate, appending “high-quality” tags to captions for audio above 16 kHz, which improves high-frequency retention in generated outputs. The model is trained on 100k hours of data using 128 H20 GPUs, with 18 multimodal and 36 unimodal transformer layers, each with 1536 hidden dimensions and 12 attention heads. Classifier-free guidance is applied at a 0.1 dropout rate per modality to enhance controllability.
Experiment
- HunyuanVideo-Foley sets new state-of-the-art in text-video-to-audio generation, excelling in visual-semantic alignment, audio quality, and temporal synchronization across Kling-Audio-Eval, VGGSound-Test, and MovieGen-Audio-Bench.
- It outperforms baselines in most objective and subjective metrics, especially in IB, PQ, and DeSync, while maintaining competitive CLAP scores despite minor trade-offs in IS and CE on some datasets.
- On VGGSound-Test, it lags slightly in distribution matching due to domain mismatch but leads in audio quality and maintains top IB performance.
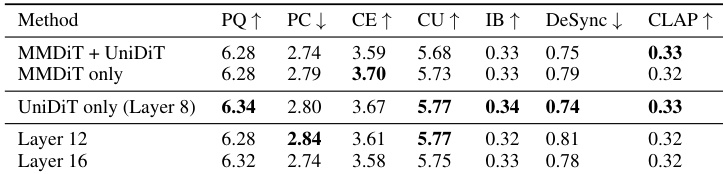
- Ablation studies confirm the superiority of its multimodal transformer design, particularly joint attention followed by cross-attention, and validate the effectiveness of interleaved RoPE and unimodal DiT.
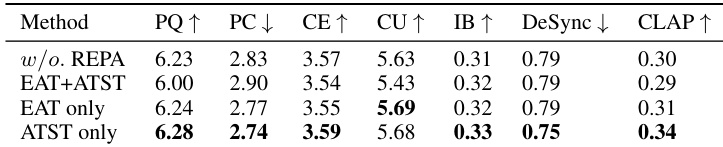
- Representation alignment with ATST yields optimal results; combining ATST and EAT degrades performance due to feature distribution conflicts.
- REPA applied in unimodal DiT, especially in shallower layers, boosts alignment effectiveness.
- DAC-VAE demonstrates robust audio reconstruction across diverse domains (speech, music, general sounds), outperforming prior methods in all evaluation metrics.
- Spectrogram visualizations confirm precise temporal alignment and preservation of high-frequency content across dynamic scenarios.
The authors evaluate different configurations of their multimodal transformer architecture, finding that using a unimodal DiT at Layer 8 yields the best overall performance, particularly in production quality and content usefulness. While alternative layer depths maintain competitive scores, they show trade-offs in temporal alignment and audio quality. The results confirm that architectural choices significantly influence specific aspects of audio generation, with Layer 8 providing the most balanced outcomes.
The authors use HunyuanVideo-Foley to generate audio from text and video inputs, achieving strong performance across multiple evaluation metrics including audio quality, visual-semantic alignment, and temporal synchronization. While it underperforms slightly on some text-semantic alignment and distribution matching scores compared to MMAudio, it significantly improves in key areas like distribution match and visual alignment. Results show consistent advantages over baselines across diverse datasets, establishing new state-of-the-art performance in text-video-to-audio generation.

The authors evaluate different representation alignment strategies using EAT and ATST models, finding that ATST alone yields the best overall performance across audio quality, temporal alignment, and text-semantic consistency. Combining EAT and ATST degrades results, likely due to conflicting feature distributions. The optimal configuration uses ATST in unimodal DiT layers, particularly in shallower blocks, to enhance alignment without introducing noise or misalignment.
The authors use HunyuanVideo-Foley to generate audio from text and video inputs, achieving state-of-the-art performance across multiple datasets. Results show consistent improvements in visual-semantic alignment, audio quality, and temporal synchronization compared to baselines, with notable gains in distribution matching on the Kling-Audio-Eval dataset. While slightly trailing in some text-semantic metrics, the model demonstrates robust overall performance and superior reconstruction capabilities across diverse audio domains.

The authors evaluate HunyuanVideo-Foley against multiple baselines on objective and subjective metrics, showing consistent improvements in audio production quality, visual-semantic alignment, and temporal synchronization. While some baselines score higher on specific metrics like CLAP or content enjoyment, HunyuanVideo-Foley achieves the best overall subjective ratings across audio naturalness, scene matching, and timing accuracy. Results confirm its state-of-the-art performance in text-video-to-audio generation across diverse evaluation dimensions.
