Command Palette
Search for a command to run...
Decoder-Hybrid-Decoder-Architektur für effizientes Schlussfolgern bei langen Generierungen
Decoder-Hybrid-Decoder-Architektur für effizientes Schlussfolgern bei langen Generierungen
Zusammenfassung
Neuere Fortschritte in der Sprachmodellierung haben die Wirksamkeit von State Space Models (SSMs) für eine effiziente Sequenzmodellierung gezeigt. Obwohl hybride Architekturen wie Samba und die Decoder-Decoder-Architektur YOCO gegenüber Transformers vielversprechende Leistungssteigerungen erzielt haben, wurde bislang die Effizienzpotenziale der Repräsentationsteilung zwischen SSM-Schichten nicht untersucht. In diesem Paper führen wir die Gated Memory Unit (GMU) ein – einen einfachen, aber effektiven Mechanismus zur effizienten Speicherteilung über Schichten hinweg. Wir integrieren ihn in die Architektur SambaY, eine Decoder-Hybrid-Decoder-Architektur, die GMUs im Cross-Decoder verwendet, um Leseszustände aus einem Samba-basierten Self-Decoder zu teilen. SambaY steigert die Dekodierungs-Effizienz erheblich, behält die lineare Komplexität während der Vorausfüllphase bei und verbessert die Leistung bei langen Kontexten, wobei explizite Positionscodierungen entfallen. Durch umfangreiche Skalierungsexperimente zeigen wir, dass unser Modell im Vergleich zu einer starken YOCO-Benchmark-Referenz eine signifikant geringere irreduzible Verlustfunktion aufweist, was auf eine überlegene Leistungs-Scalability unter großskaligen Rechenressourcen hindeutet. Unser größtes Modell, das mit Differential Attention ausgestattet ist – Phi4-mini-Flash-Reasoning – erreicht bei Reasoning-Aufgaben wie Math500, AIME24/25 und GPQA Diamond deutlich bessere Ergebnisse als Phi4-mini-Reasoning, ohne jegliche Verstärkungslernverfahren einzusetzen. Gleichzeitig erzielt es unter dem vLLM-Inferenzframework bis zu 10-fach höhere Dekodierdurchsatzraten bei Eingaben mit 2K Länge und einer Generierungslänge von 32K. Wir stellen unseren Trainings-Codebase auf Open-Source-Daten unter https://github.com/microsoft/ArchScale zur Verfügung.
One-sentence Summary
The authors from Microsoft and Stanford University propose SambaY, a decoder-hybrid-decoder architecture that introduces the Gated Memory Unit (GMU) to enable efficient cross-layer memory sharing in State Space Models, achieving superior decoding efficiency and long-context performance without positional encoding, outperforming YOCO and enabling up to 10× higher throughput on long prompts while improving reasoning accuracy on Math500, AIME24/25, and GPQA Diamond.
Key Contributions
-
The paper introduces the Gated Memory Unit (GMU), a novel mechanism for efficient representation sharing across SSM layers, which enables the SambaY architecture—a decoder-hybrid-decoder model that replaces half of the cross-attention layers with GMUs to share inner states from a Samba-based self-decoder, thereby reducing decoding cost while maintaining linear pre-filling complexity and eliminating the need for explicit positional encoding.
-
SambaY demonstrates superior scaling behavior, achieving significantly lower irreducible loss than a Samba+YOCO baseline across up to 3.4B parameters and 600B tokens, and excels on long-context tasks like Phonebook and RULER even with a small sliding window size of 256, indicating strong performance scalability under large-scale compute regimes.
-
The Phi4-mini-Flash-Reasoning variant, built on SambaY with Differential Attention, outperforms Phi4-mini-Reasoning on reasoning benchmarks including Math500, AIME24/25, and GPQA Diamond without reinforcement learning, while delivering up to 10× higher decoding throughput on long prompts under the vLLM inference framework, showcasing practical efficiency gains for long-chain reasoning.
Introduction
The authors address the challenge of efficient long-sequence reasoning in large language models, where traditional Transformers suffer from quadratic memory and compute costs during generation. While recent hybrid architectures like YOCO improve efficiency by using a single full attention layer and reusing its key-value cache across subsequent layers, they still incur high I/O costs from cross-attention operations during response generation—especially problematic for long Chain-of-Thought reasoning. To overcome this, the authors introduce the Gated Memory Unit (GMU), a lightweight mechanism that enables efficient representation sharing across SSM layers in a novel decoder-hybrid-decoder architecture called SambaY. By replacing half of the cross-attention layers with GMUs, SambaY reduces expensive attention operations while maintaining linear pre-filling complexity and eliminating the need for positional encodings. The approach demonstrates superior scaling behavior and long-context retrieval performance, achieving up to 10× higher decoding throughput on long prompts under vLLM inference, with strong results on benchmarks like Math500 and GPQA Diamond—without relying on reinforcement learning.
Dataset
- The dataset is composed of partially open-source data, with the authors providing code in a footnote on page one of the paper.
- The paper references existing datasets and codebases under the CC-BY 4.0 license, citing original sources and specifying the versions used.
- For each dataset used, the authors include the license type, a URL where available, and adherence to the source’s terms of service, particularly for scraped data.
- The data is used in the model training process through a mixture of subsets, with specific ratios applied during training to balance diversity and performance.
- No explicit cropping strategy is described, but metadata is constructed to ensure consistency across subsets, including alignment of labels and formatting.
- The authors confirm that all assets are properly licensed and that consent considerations are addressed in the paper’s discussion.
- The dataset and code are made available to support reproducibility, with structured documentation provided to guide replication of the main experimental results.
Method
The authors introduce the Gated Memory Unit (GMU), a mechanism designed to enable efficient memory sharing across layers in sequence models. This unit operates by modulating the token mixing performed in a previous layer using a gating mechanism conditioned on the current layer's input. Formally, the GMU takes as input the current layer's hidden state Xl∈Rn×dm and a mixed representation M(l′)∈Rn×dp from a preceding layer l′, producing an output Yl∈Rn×dm through a learnable gating process. The operation is defined as Yl=(M(l′)⊙σ(XlW1T))W2, where σ is the SiLU activation function, ⊙ denotes element-wise multiplication, and W1,W2 are learnable weight matrices. This gating mechanism effectively reweights the token-mixing operator from the previous layer, allowing for a fine-grained recalibration of the memory. The authors also introduce a normalized version of the GMU (nGMU), which applies RMSNorm after the element-wise multiplication, a design choice they argue is crucial for training stability, particularly when the memory originates from linear attention mechanisms.
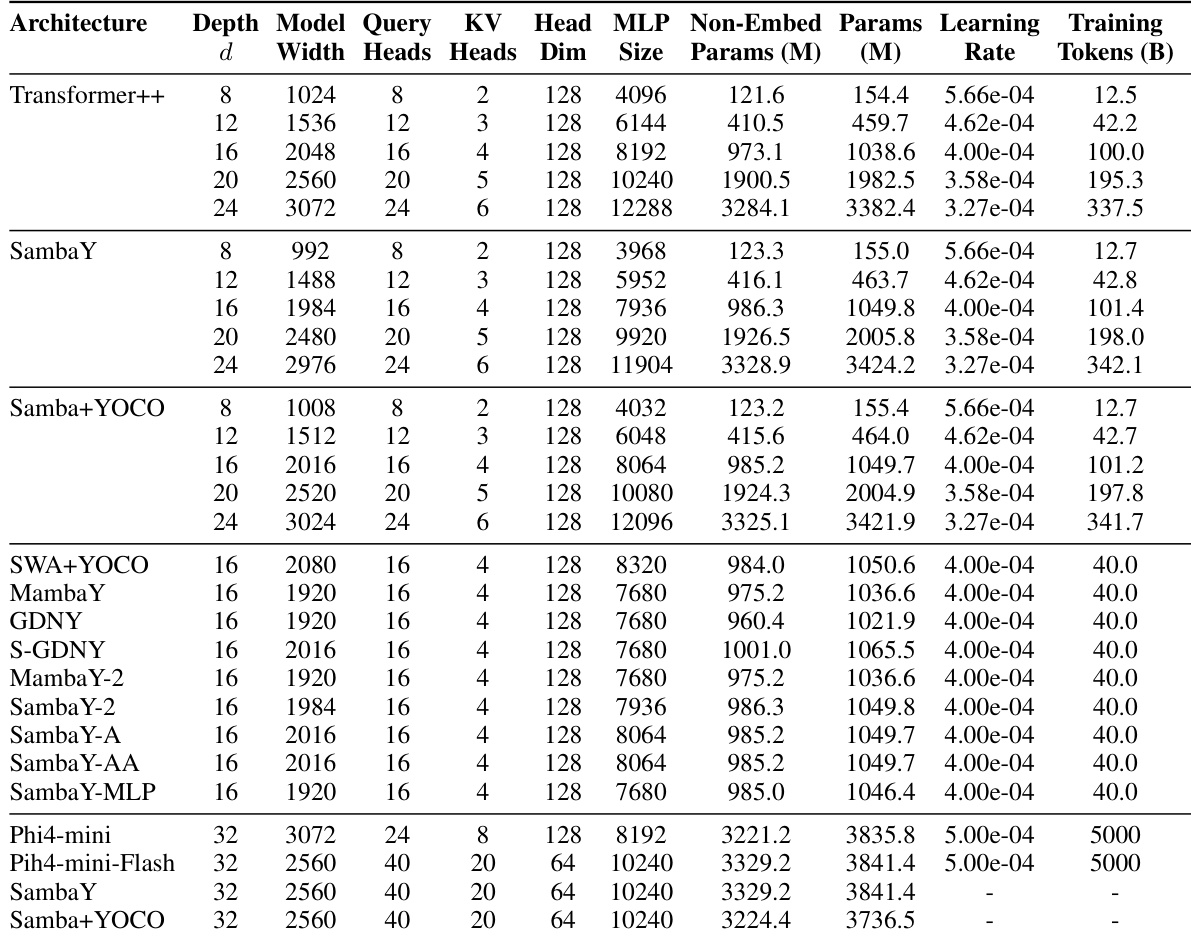
The core of the proposed architecture, SambaY, is a decoder-hybrid-decoder framework that leverages the GMU to enhance efficiency. As shown in the framework diagram, the model is composed of a self-decoder and a cross-decoder. The self-decoder, which processes the input sequence, is built using Samba layers, which are a type of state space model (SSM). This self-decoder includes a final full-attention layer that generates a Key-Value (KV) cache. The cross-decoder, responsible for generating the output, is a hybrid of cross-attention layers and GMUs. The authors replace half of the cross-attention layers in the cross-decoder with GMUs. These GMUs are designed to share the memory readout states from the last SSM layers in the self-decoder, specifically the output state from the final Mamba layer. This design choice allows the model to maintain linear pre-filling time complexity, as the KV cache is only computed once during the prefill stage by the self-decoder's full-attention layer. During decoding, the GMUs significantly reduce the memory I/O complexity for half of the cross-attention layers from O(dkvN) to a constant O(dh), leading to substantial efficiency gains for long sequences.
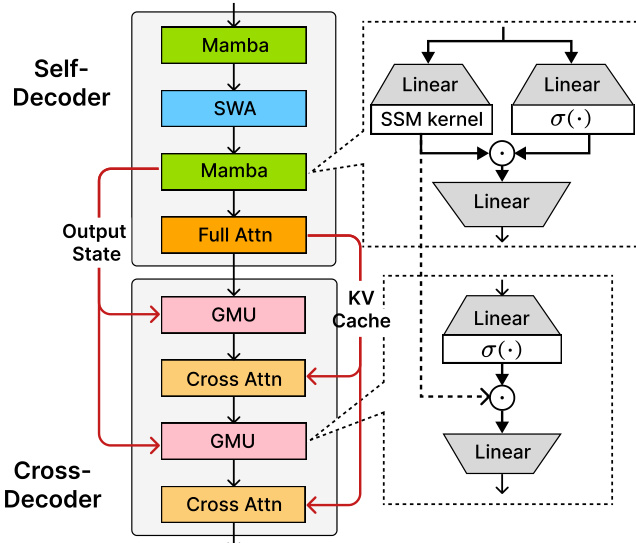
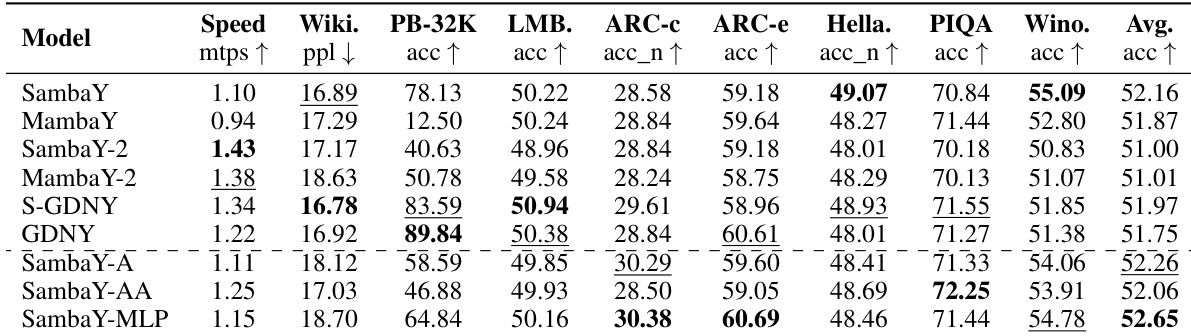
The paper presents several variants of the SambaY architecture, as illustrated in the figure, to explore different design choices. SambaY-A is the base architecture, where the cross-decoder consists of a sequence of GMUs and cross-attention layers. SambaY-AA replaces the standard cross-attention layers with an attention mechanism that uses a linear kernel, aiming to further improve efficiency. SambaY-MLP replaces the cross-attention layers with a multi-layer perceptron (MLP) to explore the impact of different token mixing mechanisms. The GDNY architecture is a more complex variant that uses Gated DeltaNet (GDN) layers in the self-decoder and employs the normalized GMU (nGMU) in the cross-decoder. The figure highlights the key differences in the internal structure of these models, particularly the composition of the self-decoder and the specific type of layers used in the cross-decoder. The authors' primary focus is on the SambaY architecture, which demonstrates a significant improvement in decoding efficiency and long-context performance compared to its baseline, YOCO.
Experiment
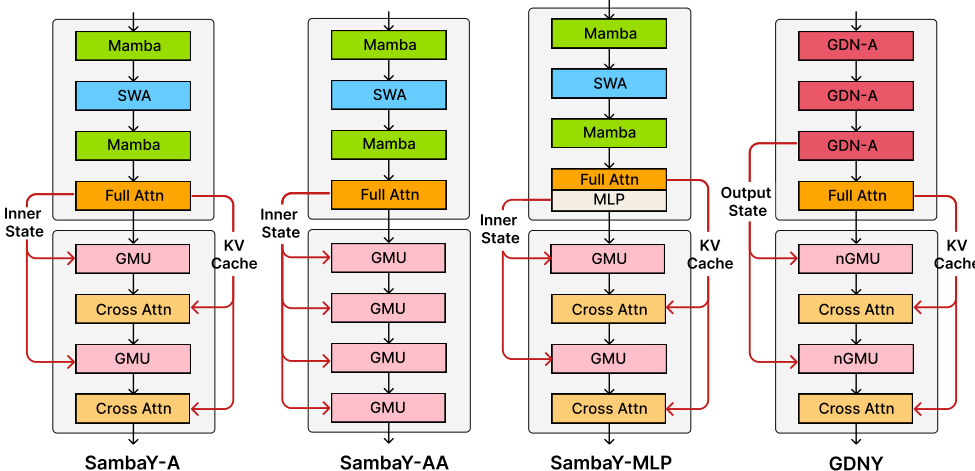
- SambaY and SambaY+DA hybrid models with small sliding window sizes (e.g., 128–512) achieve strong long-context retrieval performance on Phonebook (32K) and RULER benchmarks, outperforming pure Transformer models despite reduced attention scope. On Phonebook, SambaY+DA achieves 83.6% accuracy with a 512 window size, while Samba+YOCO requires 2048 for peak performance, indicating superior efficiency.
- On the RULER benchmark, SambaY variants achieve top results in single-needle (S: 92.1%) and multi-key (MK: 88.4%) retrieval tasks, surpassing Transformer++ and TransformerLS, which show significant performance drops beyond 32K context.
- Phi4-mini-Flash (3.8B) trained on 5T tokens with SambaY+DA architecture outperforms Phi4-mini baseline across 7 out of 8 downstream tasks, including MMLU (+4.2%) and MBPP (+12.3%), while achieving up to 10× higher throughput in long-generation scenarios.
- Phi4-mini-Flash-Reasoning, distilled from Phi4-mini-Flash, achieves state-of-the-art Pass@1 performance on AIME24/25 (68.8%), Math500 (72.1%), and GPQA Diamond (54.3%), exceeding Phi4-mini-Reasoning despite using a more efficient SambaY-based architecture and 4.9× faster long-context processing.
- Ablation studies confirm that nGMU with post-gating normalization is critical for long-context retrieval, with performance dropping by up to 56.3 points on Phonebook when replaced with standard GMU or repositioned normalization.
- The use of ProLong-64K dataset and variable-length training significantly improves long-context performance over SlimPajama, especially for SSM-based models, with SambaY+DA achieving competitive results at smaller window sizes.
- SambaY-based models demonstrate strong zero-shot performance on short-context tasks (e.g., WikiText-103: 14.2 perplexity, ARC-Easy: 85.1%), maintaining high efficiency with 1.0B models trained at 128 MTPS on 64 A100-80GB GPUs.
- All experiments are reproducible with full disclosure of hyperparameters, training details, and compute resources, and statistical significance is supported by error bars across multiple runs.
The authors use the Phonebook benchmark to evaluate long-context retrieval performance across different models and sliding window attention (SWA) sizes. Results show that SambaY and SambaY+DA achieve the highest accuracy at 32K context length, with SambaY+DA further improving performance, while models with larger SWA sizes like Samba+YOCO show diminishing returns and lower accuracy at longer contexts.
The authors use a hybrid architecture combining Mamba and Transformer components to evaluate long-context retrieval and downstream performance. Results show that SambaY and SambaY+DA achieve strong performance on long-context tasks like Phonebook and RULER benchmarks, with SambaY+DA outperforming other models on multi-query and multi-key retrieval. The models also maintain competitive short-context performance, with SambaY variants demonstrating higher training speed and efficiency compared to Transformer-based models.
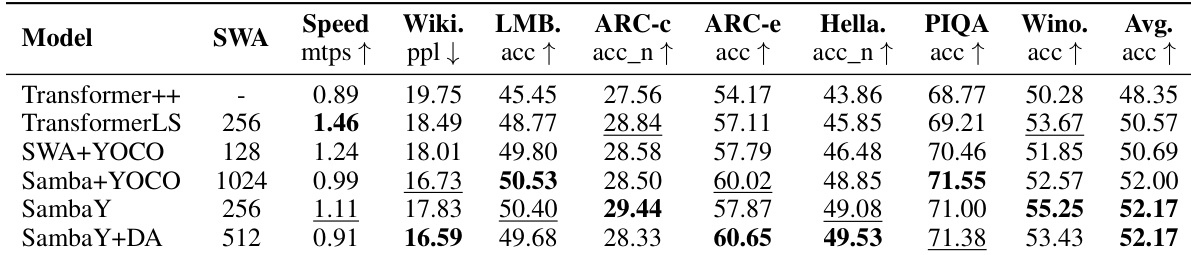
The authors use a 1.0B-parameter model to evaluate the performance of various hybrid architectures on long-context retrieval and downstream tasks. Results show that SambaY and its variants achieve the highest retrieval accuracy on the Phonebook benchmark, with SambaY-2 and SambaY-MLP demonstrating strong performance across multiple short-context tasks, while SambaY-A and SambaY-AA show significant degradation on long-context retrieval, indicating the importance of cross-attention and the specific memory source in the hybrid architecture.
The authors use Table 6 to compare the key differences between Standard Parameterization (SP), μP, and μP++. Results show that μP++ applies scaling laws to output logits and learning rates proportional to 1/w, uses zero weight decay for scalar or vector-like parameters, and divides the output of each layer by √(2d), which enhances training stability and performance compared to SP and μP.

The authors use a range of model architectures, including Transformer++, SambaY, and Samba+YOCO, to evaluate the impact of different design choices on long-context retrieval and downstream performance. Results show that hybrid models with SSMs consistently outperform pure Transformer architectures, with SambaY variants demonstrating strong performance in long-context retrieval while maintaining competitive results on short-context tasks.