Command Palette
Search for a command to run...
DiffuCoder: Verständnis und Verbesserung maskierter Diffusionsmodelle für die Codegenerierung
DiffuCoder: Verständnis und Verbesserung maskierter Diffusionsmodelle für die Codegenerierung
Shansan Gong Ruixiang Zhang Huangjie Zheng Jiatao Gu Navdeep Jaitly Lingpeng Kong Yizhe Zhang
Zusammenfassung
Diffusions-basierte große Sprachmodelle (dLLMs) stellen eine vielversprechende Alternative zu autoregressiven (AR) Modellen dar, da ihre Denoisings-Modelle über die gesamte Sequenz operieren. Die globalen Planungs- und iterativen Verbesserungseigenschaften von dLLMs sind besonders nützlich für die Codegenerierung. Allerdings sind die derzeitigen Trainings- und Inferenzmechanismen für dLLMs im Bereich der Programmierung noch wenig erforscht. Um das Dekodierverhalten von dLLMs zu entschlüsseln und ihr Potenzial für die Codeerzeugung zu erschließen, untersuchen wir systematisch ihre Denoisings-Prozesse und Methoden des Verstärkungslernens (Reinforcement Learning, RL). Wir trainieren ein 7B-Modell, DiffuCoder, auf 130 Milliarden Tokens an Code. Anhand dieses Modells analysieren wir das Dekodierverhalten und zeigen auf, wie es sich von AR-Modellen unterscheidet: (1) dLLMs können entscheiden, wie kausal ihre Generierung sein soll, ohne auf semi-autoregressive Dekodierung angewiesen zu sein, und (2) eine Erhöhung der Sampling-Temperatur führt nicht nur zu einer Vielfalt an Token-Auswahlen, sondern auch zu einer Vielfalt in der Generierungsreihenfolge. Diese Vielfalt schafft einen reichhaltigen Suchraum für RL-Rollouts. Für das RL-Training schlagen wir coupled-GRPO, ein neuartiges Sampling-Schema vor, das komplementäre Masken-Rauschen für die bei der Ausbildung verwendeten Kompletierungen konstruiert, um die Varianz der Token-Log-Wahrscheinlichkeits-Schätzungen zu reduzieren und die Trainings-Effizienz zu erhalten. In unseren Experimenten verbessert coupled-GRPO die Leistung von DiffuCoder erheblich bei Codegenerierungsbenchmarks (+4,4 % auf EvalPlus) und verringert die Abhängigkeit von AR-Bias während der Dekodierung. Unsere Arbeit liefert tiefere Einblicke in die Funktionsweise der dLLM-Generierung und bietet einen effektiven, auf Diffusion ausgerichteten RL-Trainingsrahmen. https://github.com/apple/ml-diffucoder.
One-sentence Summary
The authors from Apple and The University of Hong Kong propose DiffuCoder, a 7B diffusion language model for code generation that leverages a novel coupled-GRPO reinforcement learning method to reduce variance in training and enable more flexible, non-causal decoding. Unlike autoregressive models, DiffuCoder dynamically adjusts generation causality and exploits temperature-driven order diversity for richer RL search, achieving +4.4% improvement on EvalPlus while maintaining efficiency.
Key Contributions
- We introduce DiffuCoder, a 7B-scale diffusion language model trained on 130B tokens of code, providing a foundation for studying and advancing diffusion-native training methods in code generation.
- Our analysis reveals that dLLMs can dynamically adjust their generation strategy based on sampling temperature, enabling more flexible, non-autoregressive behavior—diversifying both token choices and generation order—unlike traditional autoregressive models.
- We propose coupled-GRPO, a novel reinforcement learning method that uses paired complementary mask noise to reduce variance in policy gradient estimation, improving DiffuCoder’s EvalPlus score by 4.4% without relying on semi-AR decoding.
Introduction
The authors leverage masked diffusion models (MDMs) as a non-autoregressive alternative to traditional autoregressive language models for code generation, where parallel refinement of entire sequences enables global planning—ideal for code’s iterative, non-linear development process. Prior work on diffusion-based code models, while promising, often relies on semi-autoregressive decoding strategies or fixed timesteps that undermine the core advantage of diffusion: true parallelism. These approaches limit performance gains and deviate from the intended non-autoregressive behavior. To address this, the authors introduce DiffuCoder, a 7B-scale diffusion LLM trained on 130B tokens, and develop novel local and global autoregressive-ness metrics to analyze decoding patterns. Their analysis reveals that higher sampling temperatures promote more flexible, non-AR generation, reducing causal bias and improving code quality. Building on this insight, they propose coupled-GRPO, a diffusion-native reinforcement learning method that uses a coupled-sampling scheme to reduce variance in policy gradient estimation without relying on semi-AR decoding. This approach achieves a 4.4% improvement in EvalPlus score using only 21K training samples, demonstrating the effectiveness of aligning RL with the intrinsic parallelism of diffusion models.
Method
The authors leverage a diffusion-based architecture for code generation, building upon the foundational principles of discrete diffusion models. The core framework operates by gradually corrupting a clean input sequence x0 through a forward process q(x1:T∣x0), which introduces noise at each timestep t according to a categorical distribution defined by a transition matrix Qt. This process is designed to be absorbing, where a special [MASK] token acts as an absorbing state, ensuring that the final noisy state xT is entirely masked. The model learns to reverse this process, denoising xt to reconstruct x0 through a backward process pθ(x0:T). The parameters θ are optimized by minimizing the evidence lower bound (ELBO), which is approximated as a weighted cross-entropy loss Lt at a sampled time t, where the weight is inversely proportional to the mask ratio t. This continuous-time formulation allows the model to operate on a sequence of masked tokens, enabling a non-autoregressive generation process.
The model's training pipeline is structured into four distinct stages, as illustrated in the framework diagram. The first stage, adaptation pre-training, involves continual pre-training on a large-scale code corpus to establish a strong base model. This is followed by a mid-training stage, which acts as an annealing phase, connecting the pre-training and post-training stages. The third stage is instruction tuning, where the model is fine-tuned on a smaller dataset of instruction-following examples to enhance its ability to understand and execute user instructions. The final stage is post-training, which employs a novel reinforcement learning method, coupled-GRPO, to further optimize the model's performance on code generation tasks. This multi-stage approach allows for a gradual refinement of the model's capabilities, from general code understanding to specific instruction execution.
The authors reinterpret the diffusion process as a Markov Decision Process (MDP) to facilitate reinforcement learning. In this framework, the state st is defined as (c,t,xt), where c is the condition (e.g., a code prompt), t is the current diffusion timestep, and xt is the partially masked sequence. The action at is the prediction of the previous token xt−1. The policy πθ(at∣st) is the model's probability of generating xt−1 given the current state. The reward function R(s0,a0) is defined at the final denoising step, based on the quality of the generated sequence x0 relative to the condition c. This MDP formulation allows the application of policy gradient methods, such as GRPO, to optimize the model's policy.
The authors introduce a novel reinforcement learning algorithm called coupled-GRPO to address the challenges of training diffusion models. The key innovation is a coupled-sampling scheme that constructs complementary mask noise for completions used in training. This scheme involves selecting a pair of timesteps (t,t^) such that t+t^=T. For each pair, two complementary masks are created: one that hides part of the tokens and another that hides the remaining tokens, ensuring that every token is unmasked in exactly one of the two forward passes. This design guarantees that each token's log-probability is computed at least once, providing a non-zero learning signal and reducing the variance of probability estimates. The coupled-GRPO loss function combines the standard GRPO objective with a KL-penalty to keep the updated policy close to a reference policy, and it uses the coupled probability estimates to compute the importance ratio for the policy gradient update. This approach significantly improves the model's performance on code generation benchmarks and reduces its reliance on autoregressive bias during decoding.
Experiment
- Compared different dLLMs (LLaDA trained from scratch vs. Dream/DiffuCoder adapted from AR LLMs), data modalities (math and code), and training stages; found that dLLMs exhibit flexible decoding with lower but non-zero AR-ness, while adapted models show higher AR-ness due to inherited left-to-right dependencies.
- On GSM8K (8-shot), DiffuCoder achieved 85.2% accuracy, surpassing LLaDA (82.1%) and Dream (83.4%); on HumanEval (zero-shot), it reached 72.3% pass@1, outperforming Dream (69.8%) and LLaDA (70.1%).
- Code generation shows lower mean and higher variance in global AR-ness than math, indicating more global planning behavior, consistent with programmer-like token generation patterns.
- AR-ness increases during later training stages (700B tokens) but performance drops, prompting selection of the 65B-token Stage 1 model as the base; mid-training and instruction tuning reduce AR-ness while improving performance.
- Coupled-GRPO training further reduces AR-ness and enables faster decoding: DiffuCoder-Instruct shows only a 4.2% performance drop at 2x speed (vs. 10.1% for instruction-tuned baseline), demonstrating improved parallelism.
- Higher sampling temperatures (1.0–1.2) increase generation diversity (pass@k rises significantly) and reduce AR-ness, enabling more non-AR, parallel decoding, unlike AR models where temperature only affects token selection.
- The entropy sink phenomenon—characterized by an L-shaped confidence distribution—reveals a bias toward locally adjacent tokens, explaining residual AR-ness despite flexible decoding.
- DiffuCoder-Instruct achieves 74.1% pass@1 on HumanEval after coupled-GRPO, with pass@k increasing from 72.3% (at k=1) to 81.6% (at k=10), indicating strong latent diversity for RL enhancement.
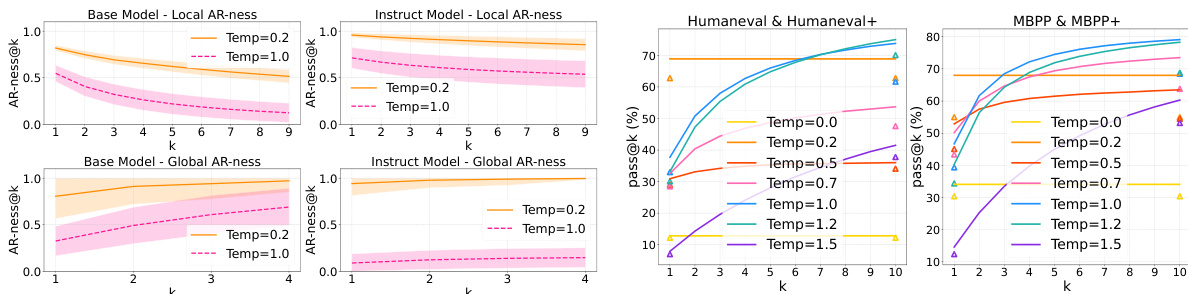
Results show that higher sampling temperatures reduce AR-ness in both base and instruct models, indicating a shift toward less sequential and more parallel token generation. This decrease in AR-ness correlates with improved generation diversity, as evidenced by higher pass@k scores at increased temperatures, particularly on code benchmarks.
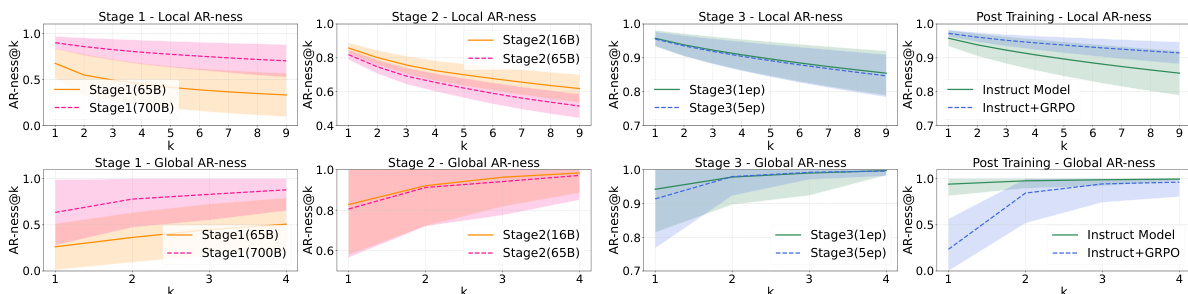
The authors analyze how AR-ness evolves across different training stages of DiffuCoder, showing that local and global AR-ness decrease during instruction tuning and GRPO training. After GRPO, the model exhibits lower AR-ness and a smaller performance drop when decoding at twice the speed, indicating improved parallelism.
Results show that increasing the sampling temperature improves pass@k scores for both base and instruct models on HumanEval, indicating greater generation diversity. Higher temperatures also reduce AR-ness, allowing the model to generate tokens in a less sequential order compared to lower temperatures.
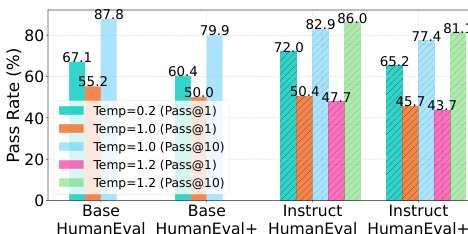
Results show that DiffuCoder-Instruct achieves competitive performance on HumanEval and MBPP benchmarks, with coupled GRPO improving pass@k scores across multiple metrics. The model's performance is further enhanced by increasing sampling temperature, which reduces AR-ness and enables more diverse and parallelizable generation.
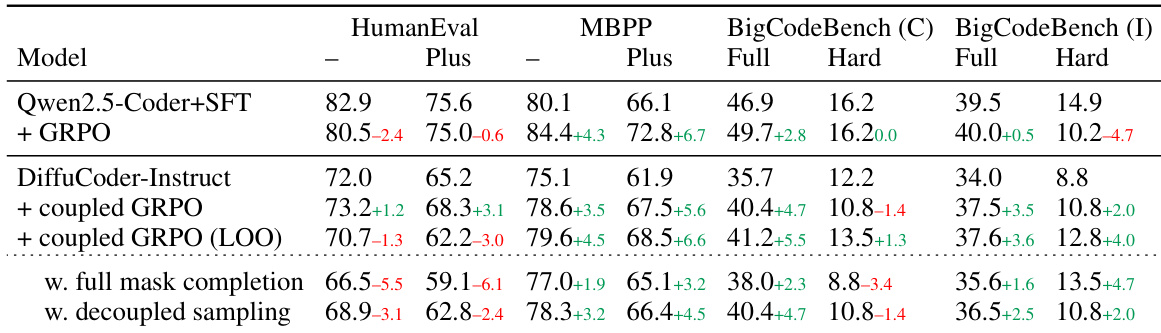
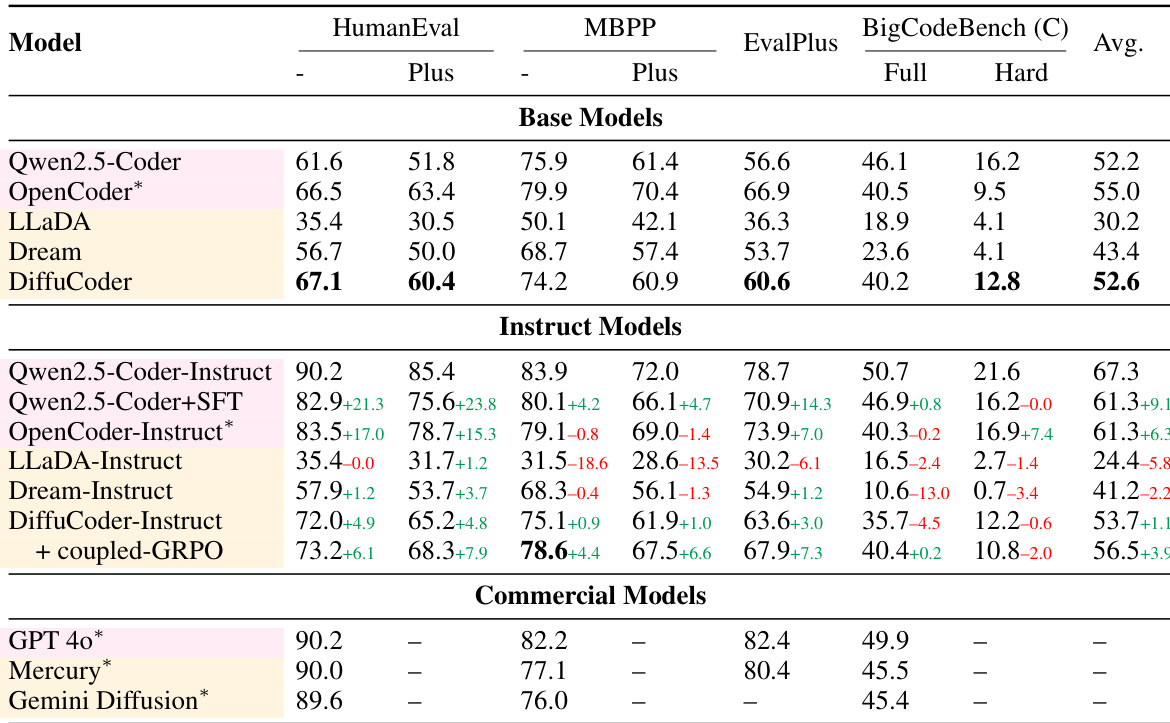
The authors use a table to compare the performance of various diffusion-based language models (dLLMs) and autoregressive (AR) models on coding benchmarks. Results show that DiffuCoder achieves the highest average score among base models, with a significant improvement over LLaDA and Dream, and that instruction tuning further boosts performance, particularly for DiffuCoder-Instruct, which outperforms other models on most tasks. The table also indicates that coupling GRPO training with instruction tuning leads to the best overall results, with DiffuCoder-Instruct + coupled-GRPO achieving the highest scores on HumanEval, MBPP, and BigCodeBench.